分散型 Always On 可用性グループの構成
適用対象: ![]() SQL Server
SQL Server
分散型可用性グループを作成するには、それぞれに独自のリスナーを持つ可用性グループをそれぞれ 2 つ作成する必要があります。 次に、これらの可用性グループを分散型可用性グループに結合します。 次の手順は、Transact-SQL の基本的な例です。 この例では、可用性グループとリスナーを作成するすべての手順を取り上げていません。主な要件を強調することに重点を置いています。
分散型可用性グループの技術の概要については、「Distributed availability groups」 (分散可用性グループ) を参照してください。
前提条件
分散型可用性グループを構成するには、次の前提条件を満たしている必要があります。
- サポートされている SQL Server のバージョン
Note
分散ネットワーク名 (DNN) を使って Azure VM 上の SQL Server に可用性グループ用のリスナーを構成した場合、可用性グループの上に分散可用性グループを構成することはサポートされていません。 詳しくは、Azure VM 上の SQL Server での AG と DNN リスナーとの機能の相互運用性に関する記事をご覧ください。
エンドポイント リスナーがすべての IP アドレスをリッスンするよう設定する
分散型可用性グループで、エンドポイントが別の可用性グループとも通信できることを確認します。 エンドポイント上で 1 つの可用性グループが特定のネットワークに設定されている場合、分散型可用性グループは正しく機能しません。 分散型可用性グループ内のレプリカをホストする各サーバーで、リスナーがすべての IP アドレス (LISTENER_IP = ALL) をリッスンするように構成します。
すべての IP アドレスをリッスンするためのエンドポイントを作成する
たとえば、次のスクリプトで、TCP ポート 5022 上ですべての IP アドレスをリッスンするリスナー エンドポイントを作成します。
CREATE ENDPOINT [aodns-hadr]
STATE=STARTED
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = ALL)
FOR DATA_MIRRORING (
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
)
GO
すべての IP アドレスをリッスンするためのエンドポイントを変更する
たとえば、次のスクリプトで、すべての IP アドレスをリッスンするようリスナー エンドポイントを変更します。
ALTER ENDPOINT [aodns-hadr]
AS TCP (LISTENER_IP = ALL)
GO
最初の可用性グループを作成する
最初のクラスターにプライマリ可用性グループを作成する
最初の Windows Server フェールオーバー クラスター (WSFC) に可用性グループを作成します。 この例では、データベース ag1 の db1という可用性グループです。 プライマリ可用性グループのプライマリ レプリカは、分散型可用性グループではグローバル プライマリと呼ばれます。 この例の server1 はグローバル プライマリです。
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
注意
上記の例では、自動シード処理を使用しています。レプリカと分散型可用性グループの両方について、SEEDING_MODE は AUTOMATIC に設定されます。 この構成では、確立後に、セカンダリ レプリカとセカンダリ可用性グループは自動的に設定されます。プライマリ データベースの手動バックアップと復元を実行する必要はありません。
セカンダリ レプリカをプライマリ可用性グループに追加する
ALTER AVAILABILITY GROUP に JOIN オプションを指定して、すべてのセカンダリ レプリカを可用性グループに追加する必要があります。 この例では自動シード処理を使用しているため、ALTER AVAILABILITY GROUP に GRANT CREATE ANY DATABASE オプションを指定して呼び出す必要もあります。 この設定では、可用性グループでデータベースを作成し、プライマリ レプリカから自動的にシード処理を開始できるようになります。
この例では、セカンダリ レプリカ server2で次のコマンドが実行され、 ag1 可用性グループに追加されます。 この可用性グループは、セカンダリ上にデータベースを作成できるようになります。
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
注意
可用性グループがセカンダリ レプリカにデータベースを作成すると、ALTER AVAILABILITY GROUP ステートメントを実行したアカウントとしてデータベース所有者が設定され、任意のデータベースを作成するアクセス許可が付与されます。 詳細については、「セカンダリ レプリカの CREATE DATABASE アクセス許可を可用性グループに付与する」を参照してください。
プライマリ可用性グループのリスナーを作成する
次に、プライマリ可用性グループのリスナーを最初の WSFC に追加します。 この例では、 ag1-listenerというリスナーです。 リスナーの詳細な作成手順については、「可用性グループ リスナーの作成または構成 (SQL Server)」を参照してください。
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
2 つ目の可用性グループを作成する
2 つ目の WSFC に 2 つ目の可用性グループ ag2を作成します。 この場合、データベースはプライマリ可用性グループから自動的にシード処理されるため、データベースを指定しません。 セカンダリ可用性グループのプライマリ レプリカは、分散型可用性グループではフォワーダーと呼ばれます。 この例の server3 はフォワーダーです。
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
注意
セカンダリ可用性グループは、同じデータベース ミラーリング エンドポイント (この例ではポート 5022) を使用する必要があります。 そうしないと、ローカルのフェールオーバー後にレプリケーションは停止します。
セカンダリ レプリカをセカンダリ可用性グループに追加する
この例では、セカンダリ レプリカ server4で次のコマンドが実行され、 ag2 可用性グループに追加されます。 この可用性グループは、自動シード処理をサポートするデータベースをセカンダリ上に作成できるようになります。
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
セカンダリ可用性グループのリスナーを作成する
次に、セカンダリ可用性グループのリスナーを 2 つ目の WSFC に追加します。 この例では、 ag2-listenerというリスナーです。 リスナーの詳細な作成手順については、「可用性グループ リスナーの作成または構成 (SQL Server)」を参照してください。
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
最初のクラスターに分散型可用性グループを作成する
最初の WSFC に分散型可用性グループ (この例では distributedag ) を作成します。 CREATE AVAILABILITY GROUP コマンドに DISTRIBUTED オプションを指定して実行します。 AVAILABILITY GROUP ON パラメーターに、メンバー可用性グループの ag1 と ag2 を指定します。
自動シード処理を使用して分散型可用性グループを作成するには、次の Transact-SQL コードを使用します。
CREATE AVAILABILITY GROUP [distributedag]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
注意
LISTENER_URL で、各可用性グループのリスナーと、可用性グループのデータベース ミラーリング エンドポイントを指定します。 この例では、ポート 5022 です (リスナーの作成に使用したポート 60173 ではありません)。 Azure でインスタンスにロード バランサーを使用している場合、分散型可用性グループのポートの負荷分散の規則を追加します。 SQL Server インスタンスのポートだけでなく、リスナー ポートの規則を追加します。
フォワーダーへの自動シード処理を取り消す
何らかの理由で、2 つの可用性グループを同期する前にフォワーダーの初期化を取り消すことが必要になる場合、フォワーダーの SEEDING_MODE パラメーターを MANUAL に設定することで分散型可用性グループを変更し、すぐにシード処理を取り消します。 グローバル プライマリでコマンドを実行します。
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedag]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
2 つ目のクラスターの分散型可用性グループに参加する
次に、2 つ目の WSFC の分散型可用性グループに参加します。
自動シード処理を使用して分散型可用性グループに参加するには、次の Transact-SQL コードを使用します。
ALTER AVAILABILITY GROUP [distributedag]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
2 つ目の可用性グループのセカンダリ上のデータベースを結合する
2 つ目の可用性グループが自動シーディングを使うように設定されている場合は、手順 2 に進みます。
- 2 つ目の可用性グループが手動シーディングを使っている場合は、グローバル プライマリで作成したバックアップを 2 つ目の可用性グループのセカンダリに復元します。
RESTORE DATABASE [db1]
FROM DISK = '<full backup location>' WITH NORECOVERY
RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY
- 2 つ目の可用性グループのセカンダリ レプリカ上のデータベースが復元状態になったら、それを可用性グループに手動で結合する必要があります。
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
分散型可用性グループのフェールオーバー操作
SQL Server 2022 (16.x) では REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定に対する分散型可用性グループのサポートが導入されているため、SQL Server 2022 以降のバージョンでは、分散型可用性をフェールオーバーする手順は SQL Server 2019 以前のバージョンとは異なります。
分散型可用性グループの場合、サポートされているフェールオーバーの種類はユーザーが手動で開始する FORCE_FAILOVER_ALLOW_DATA_LOSS のみです。 したがって、データの損失を防ぐには、フェールオーバーを開始する前に、2 つのレプリカ間でデータが確実に同期されるように、追加の手順 (このセクションで詳しく説明されている) を実行する必要があります。
データ損失が許容される緊急事態が発生した場合、次の内容を実行してデータ同期を確保せずにフェールオーバーを開始できます。
ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS
同じコマンドを使用してフォワーダーにフェールオーバーするだけではなく、グローバル プライマリにフェールバックすることもできます。
SQL Server 2022 (16.x) 以降では、分散型可用性グループの REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定を構成できます。分散型可用性グループのフェールオーバー時にデータ損失が保証されるように設計されています。 この設定が構成されている場合、このセクションの手順に従って分散型可用性グループをフェールオーバーします。 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定を使用しない場合、手順に従って SQL Server 2019 以前の分散型可用性グループをフェールオーバーします。
確実にデータが失われないようにするには、次の事項を確認してください。
- グローバル プライマリ データベース (つまり、プライマリ可用性グループのデータベース) ですべてのトランザクションを停止します
- 分散型可用性グループを同期コミットに設定します。
- 分散型可用性グループが同期され、データベースごとの last_hardened_lsn が同じになるまで待機します。
データが同期されたら、分散型可用性グループをフェールオーバーできます。
- グローバル プライマリ レプリカで分散型可用性グループのロールを
SECONDARYに設定すると、分散型可用性グループが利用できなくなります。 - [可用性グループの変更] を使用し、分散型可用性グループの
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT設定を 1 に設定します。 - フェールオーバーの準備ができたかテストします。
FORCE_FAILOVER_ALLOW_DATA_LOSSと一緒に [可用性グループの変更] を使用し、プライマリ可用性グループをフェールオーバーします。- 分散型可用性グループ REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT を 0 に設定します。
次の Transact-SQL の例では、distributedag という名前の分散型可用性グループをフェールオーバーする詳細な手順が示されています。
データが決して失われないようにするには、グローバル プライマリ データベース (つまり、プライマリ可用性グループのデータベース) でのすべてのトランザクションを停止します。 次に、グローバル プライマリとフォワーダーの "両方" で次のコードを実行して、分散型可用性グループを同期コミットに設定します。
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedag] MODIFY AVAILABILITY GROUP ON 'ag1' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), 'ag2' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ); -- verifies the commit state of the distributed availability group select ag.name, ag.is_distributed, ar.replica_server_name, ar.availability_mode_desc, ars.connected_state_desc, ars.role_desc, ars.operational_state_desc, ars.synchronization_health_desc from sys.availability_groups ag join sys.availability_replicas ar on ag.group_id=ar.group_id left join sys.dm_hadr_availability_replica_states ars on ars.replica_id=ar.replica_id where ag.is_distributed=1 GO注意
分散型可用性グループでは、2 つの可用性グループが同期された状態であるかどうかは、両方のレプリカの可用性モードに依存します。 同期コミット モードでは、現在のプライマリ可用性グループと現在のセカンダリ可用性グループの両方が
SYNCHRONOUS_COMMIT可用性モードを持つ必要があります。 このため、グローバルのプライマリ レプリカとフォワーダーの両方で上記のスクリプトを実行する必要があります。分散型可用性グループの状態が
SYNCHRONIZEDに変化し、すべてのレプリカの (データベースごとの) last_hardened_lsn が同じになるまで待機します。 プライマリ可用性グループのプライマリ レプリカであるグローバル プライマリと、フォワーダーの両方に対して次のクエリを実行することで、synchronization_state_desc と last_hardened_lsn を確認します。-- Run this query on the Global Primary and the forwarder -- Check the results to see if synchronization_state_desc is SYNCHRONIZED, and the last_hardened_lsn is the same per database on both the global primary and forwarder -- If not rerun the query on both side every 5 seconds until it is the case -- SELECT ag.name , drs.database_id , db_name(drs.database_id) as database_name , drs.group_id , drs.replica_id , drs.synchronization_state_desc , drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag on drs.group_id = ag.group_id;可用性グループ synchronization_state_desc が
SYNCHRONIZEDになり、さらにグローバル プライマリとフォワーダーの両方でデータベースごとの last_hardened_lsn が同じになったら、先に進みます。 synchronization_state_desc がSYNCHRONIZEDではない場合、または last_hardened_lsn が同じではない場合は、その状態に変化するまで 5 秒間隔でコマンドを実行します。 synchronization_state_desc =SYNCHRONIZEDとなり、かつデータベースごとの last_hardened_lsn が同じになるまで、先に進まないでください。グローバル プライマリで、分散型可用性グループのロールを
SECONDARYに設定します。ALTER AVAILABILITY GROUP distributedag SET (ROLE = SECONDARY);この時点で、分散型可用性グループは使用できません。
SQL Server 2022 (16.x) 以降の場合は、グローバル プライマリで REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT を設定します。
ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);フェールオーバーの準備をテストします。 グローバル プライマリとフォワーダーの両方に対して次のクエリを実行します。
-- Run this query on the Global Primary and the forwarder -- Check the results to see if the last_hardened_lsn is the same per database on both the global primary and forwarder -- The availability group is ready to fail over when the last_hardened_lsn is the same for both availability groups per database -- SELECT ag.name, drs.database_id, db_name(drs.database_id) as database_name, drs.group_id, drs.replica_id, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag ON drs.group_id = ag.group_id;可用性グループは、両方の可用性グループにおいてデータベースごとの last_hardened_lsn が同じである場合に、フェールオーバーできる状態となります。 一定の時間が経過しても last_hardened_lsn が同じにならない場合は、データの損失を避けるために、グローバル プライマリ上で次のコマンドを実行することでグローバル プライマリにフェールバックして、2 番目の手順からやり直します。
-- If the last_hardened_lsn is not the same after a period of time, to avoid data loss, -- we need to fail back to the global primary by running this command on the global primary -- and then start over from the second step: ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;プライマリ可用性グループからセカンダリ可用性グループにフェールオーバーします。 セカンダリ可用性グループのプライマリ レプリカをホストする SQL Server であるフォワーダーに対して、次のコマンドを実行します。
-- Once the last_hardened_lsn is the same per database on both sides -- We can Fail over from the primary availability group to the secondary availability group. -- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;この手順の後で、分散型可用性グループが使用できるようになります。
SQL Server 2022 (16.x) 以降の場合、分散型可用性グループの
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITを消去します。ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);
上記の手順が完了したら、データを損失せずに分散型可用性グループのフェールオーバーが行われます。 可用性グループ間の地理的な距離が遅延を引き起こす距離にある場合、可用性モードを ASYNCHRONOUS_COMMIT に変更してください。
分散型可用性グループを削除する
次の Transact-SQL ステートメントは、 distributedagという分散型可用性グループを削除します。
DROP AVAILABILITY GROUP [distributedag]
フェールオーバー クラスター インスタンスに分散可用性グループを作成する
フェールオーバー クラスター インスタンス (FCI) で可用性グループを使用して、分散可用性グループを作成することができます。 この場合、可用性グループ リスナーは必要ありません。 FCI インスタンスのプライマリ レプリカに対して仮想ネットワーク名 (VNN) を使用します。 次の例は、SQLFCIDAG と呼ばれる分散型可用性グループを示しています。 1 つの可用性グループは SQLFCIAG です。 SQLFCIAG には、2 つの FCI レプリカがあります。 プライマリ FCI レプリカの VNN は SQLFCIAG-1 であり、セカンダリ FCI レプリカの VNN は SQLFCIAG 2 です。 分散型可用性グループには、ディザスター リカバリーのための SQLAG DR も含まれています。
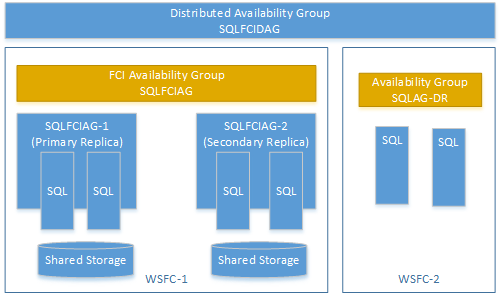
次の DDL では、この分散可用性グループが作成されます。
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
リスナーの URL は、プライマリ FCI インスタンスの VNN です。
分散型可用性グループで FCI を手動でフェールオーバーする
FCI 可用性グループを手動でフェールオーバーするには、分散型可用性グループを更新してリスナー URL の変更を反映します。 たとえば、分散型 AG のグローバル プライマリと、SQLFCIDAG の分散型 AG のフォワーダーの両方で、次の DDL を実行します。
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)
次のステップ
CREATE AVAILABILITY GROUP (Transact-SQL)
ALTER AVAILABILITY GROUP (Transact-SQL)