SQL Server でラッチの競合を診断および解決する
このガイドでは、ある種のワークロードで高コンカレンシー システム上の SQL Server アプリケーションを実行したときに見られるラッチの競合の問題を特定し、解決する方法について説明します。
サーバー上の CPU コアの数が増え続けると、それに関連するコンカレンシーの上昇により、データベース エンジン内で順次アクセスする必要がある競合ポイントがデータ構造内に発生する可能性があります。 これは、高スループットで高コンカレンシーのトランザクション処理 (OLTP) ワークロードに特に当てはまります。 これらの課題に対処するさまざまなツール、テクニック、手段と、それらを完全に回避するのに役立つ、アプリケーションの設計時に従うことができる手法があります。 この記事では、スピンロックを使用してこれらのデータ構造へのアクセスをシリアル化するデータ構造での特定の種類の競合について説明します。
Note
このコンテンツは、Microsoft SQL Server Customer Advisory Team (SQLCAT) チームにより、高コンカレンシー システム上の SQL Server アプリケーションにおけるページ ラッチの競合に関連する問題の特定と解決についてのそのプロセスに基づいて作成されたものです。 ここに記載されている推奨事項とベスト プラクティスは、実際の OLTP システムの開発と展開における実際の経験に基づいています。
SQL Server のラッチの競合とは
ラッチとは、インデックス、データ ページ、および B ツリー内の非リーフ ページのような内部構造など、メモリ内の構造の整合性を保証するために SQL Server エンジンによって使用される、軽量の同期プリミティブです。 SQL Server では、バッファー プール内のページを保護するためにはバッファー ラッチが使用され、バッファー プールにまだ読み込まれていないページを保護するためには I/O ラッチが使用されます。 SQL Server バッファー プール内のページのデータの書き込みまたは読み取りが行われるときは常に、ワーカー スレッドにおいて最初にそのページのバッファー ラッチを取得する必要があります。 バッファー プール内のページにアクセスするために使用できるバッファー ラッチには、排他的ラッチ (PAGELATCH_EX) や共有ラッチ (PAGELATCH_SH) など、さまざまな種類があります。 SQL Server によってバッファー プールにまだ存在しないページへのアクセスが試みられると、そのページをバッファー プールに読み込むための非同期 I/O がポストされます。 SQL Server で I/O サブシステムの応答を待機する必要がある場合は、要求の種類に応じて、排他 (PAGEIOLATCH_EX) または共有 (PAGEIOLATCH_SH) の I/O ラッチで待機が行われます。これは、別のワーカー スレッドにより互換性のないラッチを使用して同じページがバッファー プールに読み込まれるのを防ぐために行われます。 ラッチは、バッファー プール ページ以外の内部メモリ構造へのアクセスを保護するためにも使用されます。これらは、非バッファー ラッチと呼ばれます。
ページ ラッチでの競合は、マルチ CPU システムで発生する最も一般的なシナリオであるため、この記事の大部分でこれらに焦点を当てています。
ラッチの競合は、複数のスレッドが同じメモリ内構造に対して互換性のないラッチを同時に取得しようとすると発生します。 ラッチは内部的な制御メカニズムであるため、それらを使用するタイミングは SQL エンジンによって自動的に決定されます。 ラッチの動作は決定論的であるため、スキーマの設計を含むアプリケーションの決定が、この動作に影響することがあります。 この記事の目的は、次の情報を提供することです。
- SQL Server によるラッチの使用方法に関する背景情報。
- ラッチの競合を調査するために使用されるツール。
- 観測されている競合の量が問題であるかどうかを判断する方法。
いくつかの一般的なシナリオと、競合を軽減するための最適な対処方法について説明します。
SQL Server によるラッチの使用方法
SQL Server のページは 8 KB で、複数の行を格納できます。 コンカレンシーとパフォーマンスを向上させるため、論理トランザクションの間保持されるロックとは異なり、バッファー ラッチが保持されるのはページに対する物理操作の間だけです。
ラッチが SQL エンジンの内部に存在し、メモリの整合性を提供するために使用されるのに対し、ロックは論理的なトランザクションの整合性を提供するために SQL Server によって使用されます。 次の表は、ラッチとロックを比較したものです。
| 構造 | 目的 | 何によって制御されるか | パフォーマンス コスト | 何によって公開されるか |
|---|---|---|---|---|
| ラッチ | メモリ内の構造の整合性を保証します。 | SQL Server エンジンのみ。 | パフォーマンス コストは低いです。 最大限のコンカレンシーを可能にし、最大のパフォーマンスを提供するため、論理トランザクションの間保持されるロックとは異なり、ラッチが保持されるのはメモリ内の構造に対する物理操作の間だけです。 | sys.dm_os_wait_stats (Transact-SQL) - PAGELATCH、PAGEIOLATCH、LATCH の各待機の種類に関する情報が提供されます (LATCH_EX、LATCH_SH はすべてのバッファー ラッチ以外の待機をグループ化するために使用されます)。 sys.dm_os_latch_stats (Transact-SQL) – バッファー ラッチ以外の待機に関する詳細情報が提供されます。 sys.dm_db_index_operational_stats (Transact-SQL) - この DMV により、各インデックスの集計された待機が提供されます。これは、ラッチ関連のパフォーマンスの問題のトラブルシューティングに役立ちます。 |
| ロック | トランザクションの整合性が保証されます。 | ユーザーが制御できます。 | ロックはトランザクションの期間保持する必要があるため、ラッチに比べてパフォーマンス コストは高くなります。 | sys.dm_tran_locks (Transact-SQL)。 sys.dm_exec_sessions (Transact-SQL)。 |
SQL Server のラッチ モードと互換性
ある程度のラッチの競合は、SQL Server エンジンの動作の通常の部分として予想されます。 さまざまな互換性の複数のラッチ要求が同時に発生することは、高コンカレンシー システムでは避けられないことです。 SQL Server の場合、未処理のラッチ要求が完了するまで、互換性のないラッチ要求をキューで待機させることによって、ラッチの互換性が適用されます。
ラッチは、アクセスのレベルに関連する 5 つの異なるモードのいずれかで取得されます。 SQL Server のラッチ モードは、次のようにまとめることができます。
KP -- 保持ラッチ (Keep Latch)。参照されている構造を破棄できないようにします。 スレッドでバッファーの構造を確認する必要がある場合に使用されます。 KP ラッチは、破棄 (DT) ラッチを除くすべてのラッチと互換性があるため、KP ラッチは "軽量" と見なされます。つまり、使用したときのパフォーマンスへの影響が最小限です。 KP ラッチは DT ラッチと互換性がないため、参照されている構造体が他のスレッドによって破棄されることはありません。 たとえば、KP ラッチを使用すると、それによって参照される構造体が、レイジーライター プロセスによって破棄されなくなります。 SQL Server のバッファー ページ管理でレイジーライター プロセスを使用する方法の詳細については、「ページの書き込み」を参照してください。
SH -- 共有ラッチ。参照されている構造体を読み取るために必要です (データ ページの読み取りなど)。 共有ラッチの下では、複数のスレッドからリソースに同時にアクセスして読み取りを行うことができます。
UP -- 更新ラッチ (Update Latch)。SH (共有ラッチ) および KP とは互換性がありますが、それ以外とはないので、参照されている構造体に EX ラッチで書き込むことはできません。
EX - 排他ラッチ (Exclusive Latch)。参照されている構造体に対する他のスレッドによる書き込みまたは読み取りをブロックします。 使用例の 1 つは、破損ページ保護のためにページの内容を変更する場合です。
DT -- 破棄ラッチ (Destroy Latch)。参照されている構造の内容を破棄する前に取得する必要があります。 たとえば、他のスレッドで使用できる空きバッファーのリストに追加する前に、クリーン ページを解放するため、レイジーライター プロセスで DT ラッチを取得する必要があります。
ラッチ モードにはさまざまな互換性レベルがあります。たとえば、共有ラッチ (SH) は、更新ラッチ (UP) または保持ラッチ (KP) とは互換性がありますが、破棄ラッチ (DT) とは互換性がありません。 ラッチに互換性がある限り、同じ構造に対して複数のラッチを同時に取得できます。 互換性のないモードで保持されるラッチの取得をスレッドが試みると、それはキューに配置されて、リソースが使用可能であることを示すシグナルを待機します。 SOS_Task 型のスピンロックは、キューに対してシリアル化されたアクセスを適用することにより、待機キューを保護するために使用されます。 項目をキューに追加するには、このスピンロックを取得する必要があります。 また、互換性のないラッチが解放されたときも、SOS_Task スピンロックによってキュー内のスレッドに通知されるため、待機中のスレッドは互換性のあるラッチを取得して操作を続行できます。 待機キューは、ラッチ要求が解放されると、先入れ先出し (FIFO) ベースで処理されます。 ラッチがこの FIFO システムに従うことにより、公平性が保証され、スレッドの枯渇が防止されます。
ラッチ モードの互換性を次の表に示します (Y は互換性があることを示し、N は互換性がないことを示します)。
| ラッチ モード | KP | SH | UP | EX | DT |
|---|---|---|---|---|---|
| KP | 年 | 年 | 年 | 年 | N |
| SH | 年 | 年 | 年 | N | N |
| UP | 年 | 年 | N | N | N |
| EX | 年 | N | N | N | N |
| DT | N | N | N | N | N |
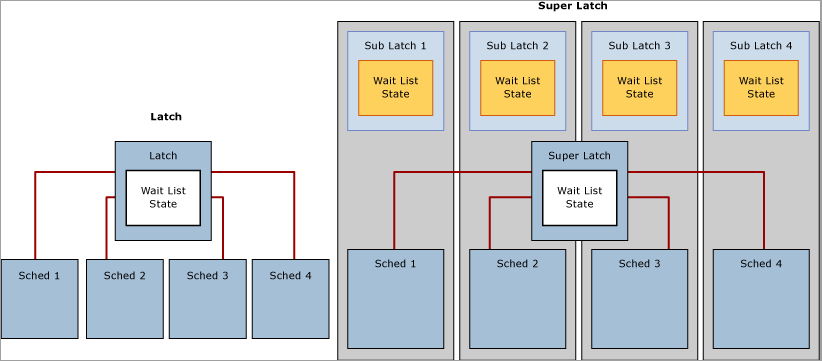
SQL Server の SuperLatch とサブラッチ
NUMA ベースの複数ソケットおよびマルチコア システムの増加に伴い、SQL Server 2005 では SuperLatch (サブラッチとも呼ばれます) が導入されました。これは、32 個以上の論理プロセッサを搭載したシステムでのみ有効です。 SuperLatch を使用すると、高コンカレンシーの OLTP ワークロードにおける特定の使用パターンで、SQL エンジンの効率が向上します。たとえば、特定のページのパターンが、読み取り専用の共有 (SH) アクセスは多くても、書き込みはほとんど行われないような場合です。 このようなアクセス パターンを持つページの例としては、B ツリー (つまり、インデックス) のルート ページがあります。SQL エンジンでは、B ツリーの任意のレベルでページ分割が発生するとき、ルート ページで共有ラッチが保持されている必要があります。 挿入量の多い高コンカレンシー OLTP ワークロードでは、スループットに合わせてページ分割の数が大きく増加し、パフォーマンスが低下する可能性があります。 SuperLatch を使用すると、同時に実行されている複数のワーカー スレッドで SH ラッチが必要な場合に、共有ページへのアクセスのパフォーマンスが向上します。 これを実現するため、SQL Server エンジンによりそのようなページのラッチが SuperLatch に動的にレベル上げされます。 SuperLatch を使用すると、1 つのラッチがサブラッチ構造 (CPU コアのパーティションごとに 1 つのサブラッチ) の配列にパーティション分割されることにより、メイン ラッチがプロキシ リダイレクターになり、読み取り専用のラッチに対するグローバル状態の同期が必要なくなります。 このようにすると、ワーカーは常に特定の CPU に割り当てられ、ローカル スケジューラに割り当てられた共有 (SH) サブラッチを取得することだけが必要です。
Note
ドキュメントでは、一般的にインデックスに関して B ツリーという用語が使用されます。 行ストア インデックスで、データベース エンジンによって B+ ツリーが実装されます。 これは、列ストア インデックスやメモリ最適化テーブルのインデックスには適用されません。 詳細については、「SQL Server と Azure SQL のインデックスのアーキテクチャとデザイン ガイド」を参照してください。
グローバルな状態を同期する必要がなくなると、ローカルな NUMA メモリにだけアクセスすればよく、パフォーマンスが大幅に向上するので、パーティション分割されていない共有ラッチより、共有 SuperLatch などの互換性のあるラッチの取得で使用されるリソースが減り、ホット ページへのアクセスのスケーリングが向上します。 逆に、排他 (EX) SuperLatch の取得の場合は、SQL ですべてのサブラッチに通知する必要があるため、標準的な EX ラッチの取得よりコストが高くなります。 SuperLatch において大量の EX アクセスのパターンが使用されていることが観察された場合は、ページがバッファー プールから破棄された後、SQL エンジンでそれをレベル下げできます。 次の図は、通常のラッチとパーティション分割された SuperLatch を示したものです。
SuperLatch の数、1 秒あたりの SuperLatch のレベル上げ数、1 秒あたりの SuperLatch のレベル下げ数など、SuperLatch に関する情報を収集するには、パフォーマンス モニターで SQL Server:Latches オブジェクトとそれに関連付けられたカウンターを使用します。 SQL Server:Latches オブジェクトおよび関連付けられているカウンターの詳細については、「SQL Server の Latches オブジェクト」を参照してください。
ラッチ待機の種類
累積的な待機の情報は SQL Server によって追跡され、動的管理ビュー (DMW) sys.dm_os_wait_stats でアクセスできます。 SQL Server では、対応する wait_type に sys.dm_os_wait_stats DMV で定義された、3 つのラッチ待機種類を使用しています。
バッファー (BUF) ラッチ: ユーザー オブジェクトのインデックスとデータ ページの整合性を保証するために使用されます。 また、SQL Server によってシステム オブジェクト用に使用されるデータ ページへのアクセスを保護するためにも使用されます。 たとえば、割り当てを管理するページは、バッファー ラッチによって保護されます。 これらには、Page Free Space (PFS)、Global Allocation Map (GAM)、Shared Global Allocation Map (SGAM)、Index Allocation Map (IAM) などのページが含まれます。 バッファー ラッチは、PAGELATCH_* という
wait_typeを持つsys.dm_os_wait_statsでレポートされます。非バッファー (非 BUF) ラッチ: バッファー プールページ以外のメモリ内構造の整合性を保証するために使用されます。 非バッファー ラッチに対するすべての待機は、LATCH_* の
wait_typeとしてレポートされます。IO ラッチ: バッファー ラッチのサブセットであり、バッファー ラッチによって保護される同じ構造が I/O 操作でバッファー プールに読み込まれる必要があるときに、これらの構造の整合性を保証します。 IO ラッチを使用すると、別のスレッドによって、互換性のないラッチによって同じページがバッファー プールに読み込まれることが防がれます。 PAGEIOLATCH_* の
wait_typeに関連付けられています。Note
PAGEIOLATCH 待機が大量に発生する場合は、SQL Server が I/O サブシステムで待機していることを意味します。 ある程度の量の PAGEIOLATCH 待機が発生することは想定され、通常の動作ですが、PAGEIOLATCH 待機の平均時間が常に 10 ミリ秒 (ms) を超えている場合は、I/O サブシステムに負荷がかかっている原因を調査する必要があります。
sys.dm_os_wait_stats DMV を調べていて、非バッファー ラッチが検出される場合は、sys.dm_os_latch_stats を調べて、非バッファー ラッチの累積待機情報の詳細な内訳を取得する必要があります。 すべてのバッファー ラッチ待機は BUFFER ラッチ クラスに分類され、残りは非バッファー ラッチを分類するために使用されます。
SQL Server のラッチの競合の現象と原因
ビジー状態の高コンカレンシー システムにおいては、SQL Server のラッチおよび他の制御メカニズムによって頻繁にアクセスされ、保護されている構造で、アクティブな競合が見られるのが普通です。 ページのラッチの取得に関連する競合と待機時間が、リソース (CPU) の使用率低下をもたらすほど大きく、それによりスループットに悪影響があるときは、問題であると考えられます。
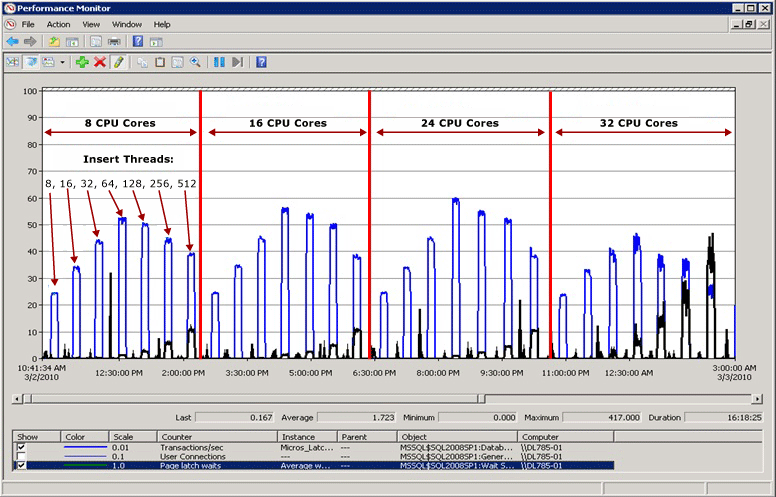
ラッチの競合の例
次の図で、青い線は 1 秒あたりのトランザクション数によって測定された SQL Server のスループットを表し、黒い線はページ ラッチの平均待機時間を表します。 この場合、各トランザクションでは、先頭の値を順番に増やしながら、クラスター化インデックスへの INSERT が実行されます (bigint データ型の IDENTITY 列の設定時など)。 CPU の数が 32 まで増えるのに伴い、全体のスループットは低下し、黒い線でわかるようにページ ラッチ待機時間は約 48 ミリ秒に増加していることが明らかです。 スループットとページ ラッチ待機時間の間にあるこのような逆相関関係は、簡単に診断できる一般的なシナリオです。
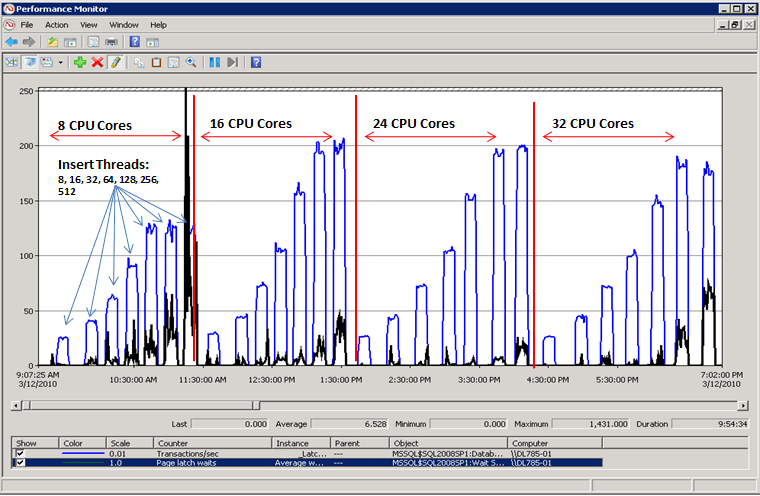
ラッチの競合が解決された場合のパフォーマンス
次の図に示すように、ページ ラッチ待機が SQL Server のボトルネックになることはなくなり、スループットは 1 秒あたりのトランザクション数で測定して 300% 増加します。 これは、後の「計算列でハッシュ パーティション分割を使用する」で説明する手法によって実現されました。 このパフォーマンス向上は、コア数が多く、コンカレンシー レベルの高いシステムを対象とするものです。
ラッチの競合に影響を与える要因
OLTP 環境でパフォーマンスを妨げるラッチの競合は、通常、次の 1 つ以上の要因に関連する高コンカレンシーに起因します。
| 要素 | 詳細 |
|---|---|
| SQL Server によって使用されている論理 CPU の数が多い | ラッチの競合は、すべてのマルチコア システムで発生する可能性があります。 許容できるレベルを超えてアプリケーションのパフォーマンスに影響を与える過度なラッチの競合が発生した SQLCAT では、CPU コアの数が 16 以上のシステムで最もよく検出され、使用できるコアの数が増えると増加する可能性があります。 |
| スキーマの設計とアクセス パターン | B ツリーの深さ、クラスター化および非クラスター化インデックスの設計、ページごとの行のサイズと密度、およびアクセス パターン (読み取り、書き込み、削除アクティビティ) は、ページ ラッチの過剰な競合に寄与する可能性のある要因です。 |
| アプリケーション レベルでの高いコンカレンシー | ページ ラッチの過剰な競合は、通常、アプリケーション層からの高いレベルの同時要求と共に発生します。 やはり特定のページに対して多数の要求が発生する可能性のあるプログラミング プラクティスもあります。 |
| SQL Server データベースによって使用される論理ファイルのレイアウト | 論理ファイルのレイアウトが、Page Free Space (PFS)、Global Allocation Map (GAM)、Shared Global Allocation Map (SGAM)、Index Allocation Map (IAM) ページなどの割り当て構造によって発生するページ ラッチの競合のレベルに影響を与える可能性があります。 詳細については、「TempDB の監視とトラブルシューティング: 割り当てのボトルネック」をご覧ください。 |
| I/O サブシステムのパフォーマンス | 大量の PAGEIOLATCH 待機は、SQL Server が I/O サブシステムで待機していることを示します。 |
SQL Server のラッチの競合の診断
このセクションでは、環境に問題があるかどうかを判断するための SQL Server のラッチの競合の診断について説明します。
ラッチの競合を診断するためのツールと方法
ラッチの競合の診断に使用される主なツールは次のとおりです。
SQL Server 内で CPU 使用率と待機時間を監視し、CPU 使用率とラッチ待機時間の間に関係があるかどうかを確認するためのパフォーマンス モニター。
問題の原因になっている特定のラッチの種類と、影響を受けるリソースを確認するために使用できる SQL Server DMV。
場合によっては、SQL Server プロセスのメモリ ダンプを取得し、Windows デバッグ ツールで分析する必要があります。
Note
このレベルの高度なトラブルシューティングは、通常、非バッファー ラッチの競合のトラブルシューティングを行う場合にのみ必要です。 この種の高度なトラブルシューティングについては、マイクロソフト製品サポート サービスへの問い合わせが必要になる場合があります。
ラッチの競合を診断するための技術的なプロセスは、次の手順にまとめられます。
ラッチに関連している可能性のある競合が発生しているかどうかを確認します。
付録: SQL Server ラッチ競合スクリプト の DMV ビューを使用して、影響を受けたラッチとリソースの種類を特定します。
「さまざまなテーブル パターンに対するラッチの競合の処理」で説明されている手法のいずれかを使用して、競合を軽減します。
ラッチの競合のインジケーター
前に説明したように、ラッチの競合は、ページ ラッチの取得に関連する競合と待機時間が原因で、使用できる CPU リソースがあるのにスループットが高くならない場合にのみ問題になります。 許容される競合の量を決定するには、パフォーマンスとスループットの要件と、利用できる I/O および CPU リソースを併せて考慮する、包括的なアプローチが必要です。 このセクションでは、次のようにようにして、ワークロードに対するラッチの競合の影響を判断する方法について説明します。
代表的なテストの間の全体的な待機時間を測定します。
それらを順番にランク付けします。
ラッチに関係があるものの割合を判断します。
累積待機情報は、sys.dm_os_wait_stats DMV から入手できます。 最も一般的なラッチの競合の種類はバッファー ラッチ競合であり、wait_type が *PAGELATCH_ であるラッチ待機時間の増加として発生します。 非バッファ ラッチは、LATCH* 待機タイプにグループ化されます。 次の図に示すように、まず、sys.dm_os_wait_stats DMV を使用してシステムの累積待機時間を取得し、バッファーまたは非バッファー ラッチによる全体的な待機時間の割合を確認する必要があります。 非バッファー ラッチが発生している場合は、sys.dm_os_latch_stats DMV も調べる必要があります。
次の図は、sys.dm_os_wait_stats と sys.dm_os_latch_stats DMV によって返される情報の関係を示したものです。

sys.dm_os_wait_stats DMV の詳細については、SQL Server のヘルプの「sys.dm_os_wait_stats (Transact-SQL)」を参照してください。
sys.dm_os_latch_stats DMV の詳細については、SQL Server のヘルプの「sys.dm_os_latch_stats (Transact-SQL)」を参照してください。
ラッチ待機時間の次のメジャーは、過度なラッチの競合がアプリケーションのパフォーマンスに影響を与えていることを示すインジケーターです。
平均ラッチ待機時間が、スループットと共に一貫して増加し続ける: スループットと共にページ ラッチの平均待機時間が一貫して上昇し、バッファー ラッチの平均待機時間も予想されるディスク応答時間を上回る場合は、
sys.dm_os_waiting_tasksDMV を使用して現在の待機中のタスクを調べる必要があります。 平均は、それだけで分析すると誤って解釈される可能性があるため、可能な場合はシステムをライブで確認し、ワークロードの特性を理解することが重要です。 特に、任意のページの PAGELATCH_EX 要求や PAGELATCH_SH 要求で長い待機時間が発生しているかどうかを確認します。 次の手順に従って、スループットに伴う平均ページ ラッチ待機時間の一貫した上昇を診断します。- 「sys.dm_os_waiting_tasks のクエリを実行してセッション ID の順に並べ替える」または「一定期間の待機時間を計算する」のサンプル スクリプトを使用して、現在の待機中のタスクを調べ、ラッチの平均待機時間を測定します。
- 「バッファー記述子のクエリを実行して、ラッチ競合の原因となっているオブジェクトを特定する」のサンプル スクリプトを使用して、競合が発生しているインデックスと基になるテーブルを特定します。
- パフォーマンス モニターのカウンター MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Wait Time を使用して、または
sys.dm_os_wait_statsDMV を実行することで、平均ページ ラッチ待機時間を測定します。
Note
特定の待機の種類 (
sys.dm_os_wait_statsによって wt_:type として返されます) に対する平均待機時間を計算するには、合計待機時間 (wait_time_msとして返されます) を待機中のタスクの数 (waiting_tasks_countとして返されます) で除算します。ピーク ロード時のラッチ待機にかかった合計待機時間の割合: 合計待機時間の割合としての平均ラッチ待機時間が、アプリケーションの負荷に従って増加する場合、ラッチの競合がパフォーマンスに影響を与えている可能性があり、調査する必要があります。
SQLServer:Wait Statistics Object パフォーマンス カウンターを使用して、ページ ラッチ待機と非ページ ラッチ待機を測定します。 その後、これらのパフォーマンス カウンターの値を、CPU、I/O、メモリ、ネットワーク スループットに関連付けられているパフォーマンス カウンターと比較します。 たとえば、トランザクション数/秒とバッチ要求数/秒は、リソース使用率の 2 つの適切な測定値です。
Note
各待機の種類に対する相対待機時間は、
sys.dm_os_wait_statsDMV には含まれません。この DMW を使用すると、SQL Server のインスタンスが最後に開始されてから、または DBCC SQLPERF を使用して累積待機統計がリセットてからの待機時間が、測定されるためです。 各待機の種類の相対的な待機時間を計算するには、ピーク負荷の前と後にsys.dm_os_wait_statsのスナップショットを取得して、その差を計算します。 「一定期間の待機時間を計算する」のサンプル スクリプトを、この目的に使用できます。非運用環境のみの場合は、次のコマンドを使用して
sys.dm_os_wait_statsDMV をクリアします。dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')同様のコマンドを実行して
sys.dm_os_latch_statsDMV をクリアできます。dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')アプリケーションの負荷が増加して、SQL Server で使用可能な CPU の数が増えても、スループットが上昇せず、場合によっては低下する: これについて、ラッチの競合例 で例示しました。
アプリケーションのワークロードが増加しても CPU 使用率が上がらない: アプリケーションのスループットによってコンカレンシーが上昇しても、システムの CPU 使用率が増加しない場合、これは SQL Server が何かを待機していることを示し、ラッチの競合の兆候です。
根本原因を分析します。 前記の各条件が当てはまる場合でも、パフォーマンスの問題の根本原因が他にある可能性があります。 実際、CPU の使用率が最適にならない場合の最大の原因は、ロックでのブロック、I/O 関連の待機、ネットワーク関連の問題など、他の種類の待機です。 経験則として、より詳細な分析を進める前に、待機時間全体に対する割合が最大のリソース待機を解決するのが、常に最善の方法です。
現在の待機バッファー ラッチの分析
バッファー ラッチの競合は、sys.dm_os_wait_stats DMV が示すように、PAGELATCH_ または _PAGEIOLATCH のいずれかの wait_type のラッチ待機時間が増える場合に発生します。 システムをリアルタイムで確認するには、システムで次のクエリを実行して、sys.dm_os_wait_stats、sys.dm_exec_sessions、sys.dm_exec_requests DMV を結合します。 その結果を使用して、サーバーで実行されているセッションの現在の待機の種類を特定できます。
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc

このクエリによって公開される統計の説明は、次のとおりです。
| 統計 | 説明 |
|---|---|
| Session_id | タスクに関連付けられているセッションの ID。 |
| Wait_type | SQL Server によってエンジンに記録された待機の種類。これにより、現在の要求の実行が妨げられています。 |
| Last_wait_type | 要求がブロックされていた場合の最後の待機の種類。 NULL 値は許可されません。 |
| Wait_duration_ms | SQL Server インスタンスが開始された後、または累積待機統計がリセットされた後に、この待機の種類での待機に費やされた合計待機時間 (ミリ秒単位)。 |
| Blocking_session_id | 要求をブロックしているセッションの ID。 |
| Blocking_exec_context_id | タスクに関連付けられている実行コンテキストの ID。 |
| Resource_description | resource_description 列には、待機中の正確なページが <database_id>:<file_id>:<page_id> の形式で一覧表示されます。 |
次のクエリを実行すると、すべての非バッファー ラッチに関する情報が返されます。
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;
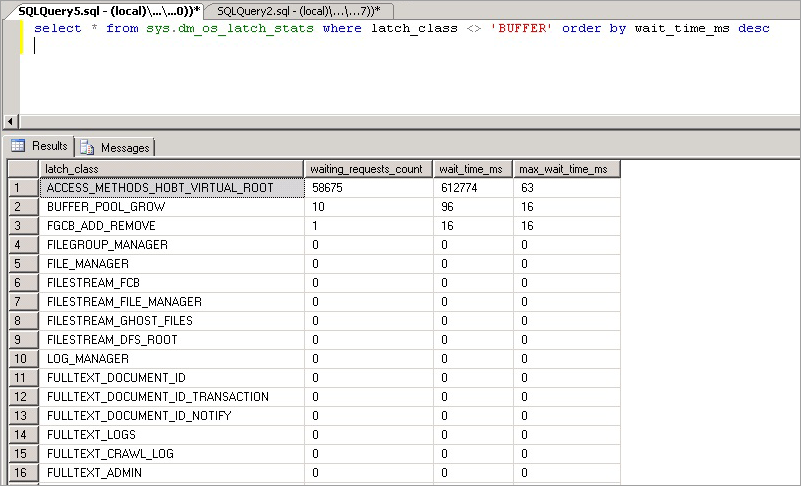
このクエリによって公開される統計の説明は、次のとおりです。
| 統計 | 説明 |
|---|---|
| latch_class | SQL Server によってエンジンに記録されたラッチの種類。これにより、現在の要求の実行が妨げられています。 |
| waiting_requests_count | SQL Server が再起動されてからの、このクラスのラッチでの待機の数。 このカウンターは、ラッチ待機の開始時に増分されます。 |
| wait_time_ms | このラッチの種類での待機に費やされた合計待機時間 (ミリ秒単位)。 |
| max_wait_time_ms | 任意の要求で、このラッチの種類での待機に費やされた最大時間 (ミリ秒単位)。 |
Note
この DMV が返す値は、データベース エンジンが最後に再起動されたとき、または DMV がリセットされたときからの累積です。 データベース エンジンが最後に起動された時刻を調べるには、sys.dm_os_sys_info の sqlserver_start_time を使用します。 長時間実行されているシステムの場合、これは max_wait_time_ms などの一部の統計が有用ではないことを意味します。 次のコマンドを使用して、この DMV の待機統計をリセットできます。
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
SQL Server におけるラッチの競合のシナリオ
以下のシナリオは、過度なラッチ競合の原因として観察されたものです。
最後のページまたは後続のページでの挿入の競合
ID 列または日付列に対するクラスター化インデックスの作成は、OLTP での一般的なプラクティスです。 これはインデックスの物理的な編成の維持に役立ち、インデックスの読み取りと書き込み両方のパフォーマンスを大幅に向上させることができます。 ただし、このスキーマの設計により、誤ってラッチの競合が発生する可能性があります。 この問題が最もよく見られるのは、小さい行が含まれる大きいテーブルでの、昇順の整数や日時キーなどの順番に増加するキー列が先頭に含まれるインデックスへの挿入です。 このシナリオの場合、アプリケーションで更新または削除が実行されることはめったにありませんが、アーカイブ操作は例外です。
次の例では、スレッド 1 とスレッド 2 の両方で、ページ 299 に格納されるレコードの挿入が実行されます。 論理的なロックの観点からは、行レベルのロックが使用され、同じページ上の両方のレコードに対して排他ロックを同時に保持できるため、問題はありません。 ただし、物理メモリの整合性を保証するため、排他的ラッチを取得できるのは一度に 1 つのスレッドのみなので、ページへのアクセスはシリアル化され、メモリ内の更新は失われません。 この場合、スレッド 1 が排他ラッチを取得し、スレッド 2 は待機します。これにより、このリソースの PAGELATCH_EX 待機が待機統計に登録されます。 これは wait_type DMV の sys.dm_os_waiting_tasks 値で表示されます。
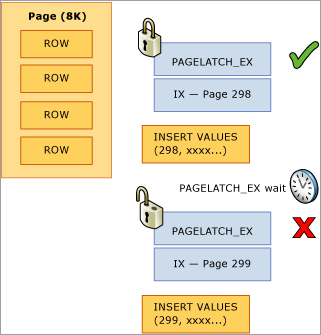
この競合は、次の図に示すように、B ツリーの右端で発生するため、"最終ページの挿入" 競合と呼ばれることがよくあります。
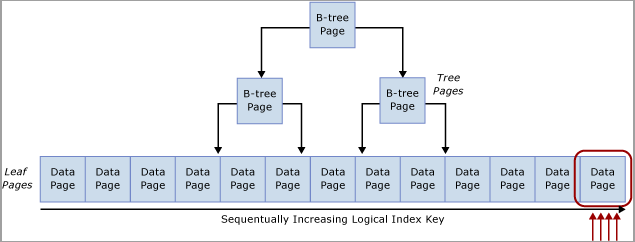
この種類のラッチの競合は、次のように説明できます。 新しい行がインデックスに挿入されると、SQL Server により次のアルゴリズムを使用して変更が実行されます。
B ツリーを走査して、新しいレコードを保持する正しいページを見つけます。
PAGELATCH_EX でページをラッチして他から変更できないようにし、すべての非リーフ ページに対する共有ラッチ (PAGELATCH_SH) を取得します。
Note
場合によっては、SQL エンジンで非リーフ B ツリーページに対する EX ラッチも取得する必要があります。 たとえば、ページ分割が発生する場合は、直接影響を受けるページを排他的にラッチする必要があります (PAGELATCH_EX)。
行が変更されたことを示すログ エントリを記録します。
行をページに追加し、ページをダーティとしてマークします。
すべてのページのラッチを解除します。
テーブル インデックスが順番に増加するキーに基づいている場合、各新規挿入は、B ツリーの最後にある同じページに、そのページがいっぱいになるまで送られます。 高コンカレンシーのシナリオの場合、これにより B ツリーの右端で競合が発生する可能性があります。これは、クラスター化インデックスと非クラスター化インデックスの両方で発生する場合があります。 この種類の競合の影響を受けるテーブルは、主に INSERT を受け入れ、問題のあるインデックスのページは比較的高密度です (たとえば、行のオーバーヘッドを含む行サイズ約 165 バイトは、1 ページあたり約 49 行になります)。 この挿入の多い例の場合、PAGELATCH_EX および PAGELATCH_SH 待機が発生することが予想され、これは一般的な観察です。 ページ ラッチ待機とツリー ページ ラッチ待機を調べるには、sys.dm_db_index_operational_stats DMV を使用します 。
次の表は、この種類のラッチの競合によって見られる主な要素をまとめたものです。
| 要素 | 一般的な観測 |
|---|---|
| SQL Server によって使用されている論理 CPU | この種類のラッチの競合は、主に CPU コアが 16 個以上のシステムで発生し、CPU コアが 32 個以上のシステムで最も一般的です。 |
| スキーマの設計とアクセス パターン | トランザクション データのテーブルのインデックスでの先頭列として、順番に増加する ID 値を使用します。 インデックスには、挿入の率が高い、増加する主キーがあります。 インデックスには、少なくとも 1 つの順番に増加する列の値があります。 通常、行サイズが小さく、ページごとに多数の行が含まれます。 |
| 観察される待機の種類 | 待機時間順に並べ替えられた sys.dm_os_waiting_tasks クエリによって返される sys.dm_os_waiting_tasks DMV 内の同じ resource_description に関連付けられている排他 (EX) または共有 (SH) ラッチ待機で同じリソースに対して競合している多くのスレッド。 |
| 考慮する設計要素 | 挿入が常に B ツリー全体に一様に分散されることを保証できる場合は、連続しないインデックスの軽減戦略で説明されているように、インデックス列の順序を変更を検討します。 ハッシュ パーティション軽減戦略を使用した場合は、スライディング ウィンドウ アーカイブなどの他の目的にパーティション分割を使用できなくなります。 ハッシュ パーティション軽減戦略を使用すると、アプリケーションによって使用される SELECT クエリに対してパーティション削除の問題が発生する可能性があります。 |
非クラスター化インデックスとランダムな挿入を使用する小さなテーブルでのラッチの競合 (キュー テーブル)
このシナリオは、通常、SQL テーブルが一時キュー (非同期メッセージング システムなど) として使用されている場合に表示されます。
このシナリオでは、次のような状況で排他 (EX) と共有 (SH) のラッチの競合が発生する可能性があります。
- 挿入、選択、更新、または削除の各操作が、高コンカレンシーで発生します。
- 行のサイズは比較的小さいものです (高密度のページになります)。
- テーブル内の行数は比較的少なく、2 つまたは 3 つのインデックスの深さで定義された浅い B ツリーになります。
Note
これより深さが大きい B ツリーであっても、データ操作言語 (DML) の頻度とシステムのコンカレンシーが十分に高い場合は、この種類のアクセス パターンでの競合が発生する可能性があります。 システムで使用可能な CPU コアが 16 個以上あるときは、コンカレンシーが高くなるので、ラッチの競合のレベルが顕著になる場合があります。
連続していない列がクラスター化インデックスの先頭キーであるときなど、アクセスが B ツリー全体でランダムであっても、ラッチの競合が発生する可能性があります。 次のスクリーンショットは、この種類のラッチの競合が発生しているシステムのものです。 この例では、行のサイズが小さく B ツリーが比較的浅いことによるページの密度が原因で、競合が発生しています。 GUID がインデックスの先頭の列であるため、コンカレンシーが高くなると、挿入が B ツリー全体に対してランダムであっても、ページでラッチの競合が発生します。
次のスクリーンショットでは、バッファー データ ページとページ空き領域 (PFS) ページの両方で、待機が発生しています。 PFS ページのラッチの競合の詳細については、サードパーティのブログ記事「SQLSkills: ベンチマーク: SSD 上の複数データファイル」を参照してください。 データ ファイルの数が増えた場合でも、バッファー データ ページではラッチの競合が発生していました。

次の表は、この種類のラッチの競合によって見られる主な要素をまとめたものです。
| 要素 | 一般的な観測 |
|---|---|
| SQL Server によって使用されている論理 CPU | ラッチの競合は、主に CPU コアが 16 個以上のコンピューターで発生します。 |
| スキーマの設計とアクセス パターン | 小さいテーブルに対する高率の挿入、選択、更新、削除アクセス パターン。 浅い B ツリー (インデックスの深さが 2 または 3)。 小さい行サイズ (1 ページあたりのレコード数が多い)。 |
| コンカレンシーのレベル | アプリケーション層からの同時要求のレベルが高い場合にのみ、ラッチの競合が発生します。 |
| 観察される待機の種類 | ルート分割のため、バッファー (PAGELATCH_EX と PAGELATCH_SH) と非バッファー ラッチ ACCESS_METHODS_HOBT_VIRTUAL_ROOT で待機が観察されます。 また、PFS ページで PAGELATCH_UP が待機されます。 非バッファー ラッチ待機の詳細については、SQL Server のヘルプで「sys.dm_os_latch_stats (Transact-SQL)」を参照してください。 |
浅い B ツリーとインデックス全体へのランダムな挿入が組み合わさると、B ツリーでページ分割が発生しやすくなります。 SQL Server でページ分割を実行するには、すべてのレベルで共有 (SH) ラッチを取得した後、ページ分割に含まれる B ツリー内のページで排他 (EX) ラッチを取得する必要があります。 また、コンカレンシーが高く、データが継続的に挿入および削除される場合も、B ツリーのルート分割が発生する可能性があります。 この場合、他の挿入は、B ツリーで取得された非バッファー ラッチを待機することが必要になる場合があります。 これは、sys.dm_os_latch_stats DMV で観察される ACCESS_METHODS_HOBT_VIRTUAL_ROOT ラッチの種類での多数の待機として示されます。
次のスクリプトを変更して、影響を受けたテーブルでのインデックスの B ツリーの深さを確認できます。
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
ページ空き領域 (PFS) ページでのラッチの競合
PFS はページ空き領域 (Page Free Space) を表し、SQL Server により、各データベース ファイルの 8088 ページ (ページ ID = 1 以降) ごとに 1 つの PFS ページが割り当てられます。 PFS ページの各バイトには、ページの空き領域の量、割り当てられているかどうか、ページにゴースト レコードが格納されているかどうかなどの情報が記録されます。 PFS ページには、挿入操作または更新操作で新しいページが必要なときに割り当てに使用できるページに関する情報が含まれます。 PFS ページは、割り当てや割り当て解除が発生したときなど、さまざまなシナリオで更新する必要があります。 PFS ページを保護するには更新 (UP) ラッチを使用する必要があるため、ファイル グループ内のデータ ファイルの数が比較的少なく、CPU コアの数が多い場合、PFS ページでラッチの競合が発生する可能性があります。 これを解決する簡単な方法は、ファイル グループごとのファイルの数を増やすことです。
警告
ファイル グループごとのファイルの数を増やすと、メモリがディスクに書き込まれる多数の大きな並べ替え操作による負荷など、特定の負荷のパフォーマンスに悪影響を及ぼす可能性があります。
tempdb の PFS ページまたは SGAM ページで PAGELATCH_UP 待機が多数発生する場合は、以下の手順のようにして、このボトルネックを解消します。
tempdb のデータ ファイルの数がサーバーのプロセッサ コアの数と同じになるように、データ ファイルを tempdb に追加します。
SQL Server トレース フラグ 1118 を有効にします。
システム ページでの競合によって発生する割り当てのボトルネックの詳細については、ブログ記事「割り当てのボトルネックとは」を参照してください。
tempdb でのテーブル値関数とラッチの競合
割り当ての競合以外にも、クエリ内での TVF の多用など、tempdb でのラッチの競合の原因になる可能性がある他の要因があります。
さまざまなテーブル パターンに対するラッチの競合の処理
以下のセクションでは、過度なラッチの競合に関連するパフォーマンスの問題に対処するために使用できる手法について説明します。
連続していない先頭のインデックス キーを使用する
ラッチの競合を処理する方法のひとつは、連続したインデックス キーを連番でないキーに置き換えて、インデックスの範囲に挿入を均等に配置することです。
これは通常、ワークロードを比例的に配分する先頭列をインデックスに設けることによって実行します。 これには、次の 2 つのオプションがあります。
オプション: テーブル内の列を使用して、インデックス キーの範囲全体に値を分散させる
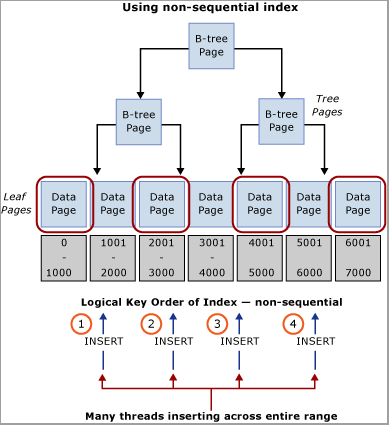
キーの範囲に挿入を分散させるために使用できる自然な値でワークロードを評価します。 たとえば、ATM バンキングのシナリオを考えると、1 人の顧客が一度に使用できる ATM は 1 台だけなので、引き出しの場合に挿入をトランザクション テーブルに分散させるには、ATM_ID がよい候補になる可能性があります。 同様に、販売時点管理システムの場合は、おそらく Checkout_ID や Store ID が、キーの範囲に挿入を分散させるために使用できる自然な値になります。 この手法を使用するには、一意性を提供するために、列を識別する値またはその値のハッシュである先頭のキー列と、1 つ以上の追加列を結合することによって、複合インデックス キーを作成する必要があります。 ほとんどの場合、個別の値が多すぎると物理的な編成が不十分になるため、値のハッシュを使用するのが最善です。 たとえば、販売時点管理システムの場合は、何らかの剰余 (これは、CPU コアの数に合わせます) である Store ID からハッシュを作成できます。 この手法を使用すると、テーブル内の範囲の数は比較的少なくなりますが、ラッチの競合が回避されるように挿入を分散させるには十分です。 次の図は、この手法を示したものです。
重要
このパターンは、従来のインデックス作成のベスト プラクティスとは矛盾しています。 この手法を使用すると、B ツリー全体に挿入を均等に分散させることはできますが、アプリケーション レベルでのスキーマの変更が必要になる場合もあります。 さらに、このパターンの場合、クラスター化インデックスを利用する範囲スキャンが必要なクエリのパフォーマンスに悪影響を与える可能性があります。 この設計アプローチが適切に機能するかどうかを判断するため、ワークロード パターンの分析が必要になります。 挿入のスループットとスケールを得るために、逐次スキャンのパフォーマンスをある程度犠牲にできる場合は、このパターンを実装する必要があります。
このパターンをパフォーマンス ラボのエンゲージメントの間に実装したところ、32 個の物理 CPU コアを搭載したシステムでラッチの競合が解決されました。 テーブルは、トランザクション終了時の残高を格納するために使用されました。各ビジネス トランザクションで、テーブルへの 1 回の挿入が実行されました。
元のテーブルの定義
元のテーブルの定義を使用すると、クラスター化インデックス pk_table1 で過剰なラッチの競合が発生することが観察されました。
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
Note
テーブル定義内のオブジェクト名が、元の値から変更されています。
並べ替えられたインデックスの定義
主キーの先頭列が UserID のインデックスのキー列を並べ替えると、挿入はページ間にほぼランダムに分散されました。 すべてのユーザーが同時にオンラインになるわけではないため、結果の分散は 100% ランダムではありませんが、過剰なラッチの競合を軽減するには十分にランダムな分散になりました。 インデックス定義の並べ替えに関する注意点の 1 つとして、このテーブルに対する選択クエリを、等値述語として UserID と TransactionID の両方を使用するように変更する必要があります。
重要
運用環境で実行する前に、テスト環境で変更を徹底的にテストする必要があります。
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
主キーの先頭列としてハッシュ値を使用する
次のテーブルの定義を使用すると、CPU の数と一致する剰余を生成できます。B ツリー全体に均等に分散されるよう、HashValue は連続して増加する値 TransactionID を使用して生成されます。
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
オプション: インデックスの先頭キー列として GUID を使用する
自然な区切りがない場合は、GUID 列をインデックスの先頭のキー列として使用して、挿入を均等に分散させることができます。 インデックス キーの先頭列として GUID を使用すると、他の機能に対してパーティション分割を使用できるようになりますが、この手法を使用すると、より多くのページ分割、物理的な編成の不備、低ページ密度による潜在的な欠点が生じる可能性もあります。
Note
インデックスの先頭キー列としての GUID の使用は、盛んに議論されたテーマです。 この方法の長所と短所の詳細については、この記事の範囲外です。
計算列でハッシュ パーティション分割を使用する
SQL Server でテーブルのパーティション分割を使用すると、過度なラッチの競合を軽減できます。 パーティション テーブルの計算列でハッシュ パーティション分割の構成を作成することは、次の手順で実行できる一般的な方法です。
新しいファイル グループを作成するか、既存のファイル グループを使用して、パーティションを保持します。
新しいファイル グループを使用する場合は、最適なレイアウトを使用するように注意して、LUN に対して個別のファイルを均等に分散させます。 挿入の割合が高いアクセス パターンの場合は、SQL Server コンピューターの物理 CPU コアと同じ数のファイルを作成するようにします。
CREATE PARTITION FUNCTION コマンドを使用して、テーブルを X 個のパーティションにパーティション分割します。X は SQL Server コンピューター上の物理 CPU コアの数です。 (少なくとも 32 個のパーティション)
Note
CPU コアの数に対してパーティションの数を 1:1 に配置することは、必ずしも必要ではありません。 多くの場合、これは CPU コアの数より小さい値にすることができます。 パーティションを増やすと、すべてのパーティションを検索する必要があるクエリでオーバーヘッドが増加する可能性があります。このような場合は、パーティションを減らすのが有効です。 実際の顧客ワークロードを使用した 64 および 128 個の論理 CPU システムによる SQLCAT テストの場合、過剰なラッチの競合を解決してスケール ターゲットを達成するのに、32 個のパーティションで十分でした。 最終的に、パーティションの最適な数はテストによって決定する必要があります。
CREATE PARTITION SCHEME コマンドを使用します。
- パーティション関数をファイル グループにバインドします。
- tinyint 型または smallint 型のハッシュ列をテーブルに追加します。
- 適切なハッシュ分散を計算します。 たとえば、hashbytes と剰余または binary_checksum を使用します。
次のサンプル スクリプトをカスタマイズして実装に利用できます。
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
このスクリプトを使用すると、最後のページまたは後続のページでの挿入の競合によって引き起こされる問題が発生しているテーブルをハッシュ パーティションできます。 この手法を使用すると、テーブルがパーティション分割され、ハッシュ値剰余演算でテーブル パーティション全体に挿入が分散されることによって、最後のページから競合が移動されます。
計算列でのハッシュ パーティション分割によって行われること
次の図に示すように、この手法を使用すると、ハッシュ関数でインデックスが再構築され、SQL Server コンピューター上の物理 CPU コアと同じ数のパーティションが作成されることによって、最後のページから競合が移動されます。 挿入は引き続き論理範囲 (順番に増加する値) の最後に送られますが、ハッシュ値の剰余演算によって、挿入が異なる B ツリーに分割されることが保証されるため、ボトルネックは軽減されます。 次の図はこれを示したものです。


ハッシュ パーティション分割を使用するときのトレードオフ
ハッシュ パーティション分割によって挿入での競合を解消できますが、この手法を使用するかどうかを決定するときは、いくつかのトレードオフについて検討する必要があります。
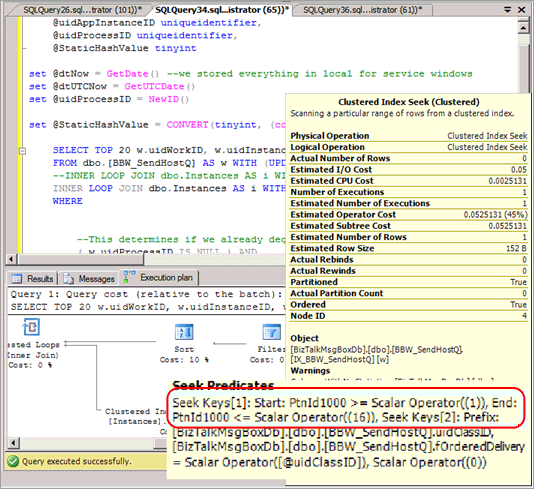
選択クエリは、ほとんどの場合、述語にハッシュ パーティションが含まれ、これらのクエリの発行でパーティションが除去されないようなクエリ プランになるように変更する必要があります。 次のスクリーンショットでは、ハッシュ パーティション分割が実装された後でパーティションの除去が行われない不適切なプランを示します。
範囲ベースのレポートなど、他の特定のクエリでのパーティションの除去の可能性はなくなります。
ハッシュ パーティション分割されたテーブルを別のテーブルに結合するとき、パーティションの除去を実現するには、2 番目のテーブルを同じキーでハッシュ パーティション分割し、ハッシュ キーを結合条件の一部にする必要があります。
ハッシュ パーティション分割を使用すると、スライディング ウィンドウ アーカイブやパーティション切り替え機能などの他の管理機能で、パーティション分割を使用できません。
ハッシュ パーティション分割は、挿入時の競合が軽減されることでシステム全体のスループットが向上するため、過剰なラッチの競合を軽減するための効果的な方法です。 いくつかのトレードオフがあるため、一部のアクセス パターンに対しては最適な解決策でない可能性があります。
ラッチの競合の解決に使用される手法のまとめ
次の 2 つのセクションでは、過剰なラッチの競合に対処するために使用できる手法をまとめます。
連続していないキーとインデックス
長所:
- スライディング ウィンドウ スキームやパーティション切り替え機能を使用するデータのアーカイブなど、他のパーティション分割機能を使用できます。
短所:
- キーまたはインデックスを選択して常に挿入の分散を "ほぼ" 均等にするときに問題が発生する可能性があります。
- GUID を先頭列として使用することで均等な分散を保証できますが、ページ分割操作が過剰になる可能性があることに注意します。
- B ツリー全体にランダムに挿入すると、ページ分割操作が多くなり、非リーフ ページでラッチの競合が発生する可能性があります。
計算列を用いたハッシュ パーティション分割
長所:
- 挿入に対して透過的。
短所:
- パーティション分割は、パーティション切り替えオプションを使用したデータのアーカイブなどの管理機能には使用できません。
- 個別および範囲ベースの選択や更新を含むクエリ、および結合を実行するクエリの場合、パーティション除去の問題が発生する可能性があります。
- 保存される計算列の追加はオフライン操作です。
ヒント
その他の手法については、ブログ記事「PAGELATCH_EX の待機と大量の挿入」を参照してください。
手順説明: ラッチの競合を診断する
次のチュートリアルでは、「SQL Server のラッチの競合の診断」と「さまざまなテーブル パターンに対するラッチの競合の処理」で説明されているツールと手法を使用して、実際のシナリオで問題を解決する方法を示します。 このシナリオでは、256 GB のメモリを搭載した 8 ソケット、32 物理コアのシステムで実行されている SQL Server アプリケーションに対する約 8,000 の店のトランザクションをシミュレートする、販売時点管理システムのロード テストを実行する顧客エンゲージメントについて説明します。
次の図は、販売時点管理システムのテストに使用されるハードウェアの詳細を示したものです。

症状: ホット ラッチ
この例では、普通平均 1 ミリ秒を超えるものとして高く定義される PAGELATCH_EX に対して高い待機が観察されました。 この例では、20 ミリ秒を超える待機を常に観察しました。
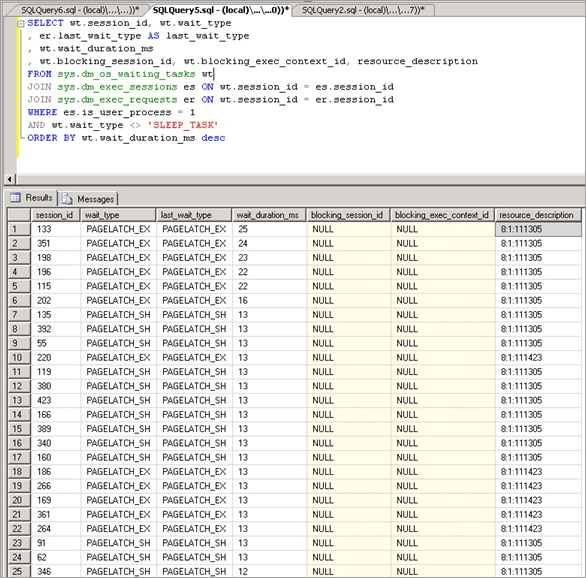
ラッチの競合が問題であると判断した後、ラッチの競合の原因の特定を始めました。
ラッチの競合の原因となったオブジェクトの分離
次のスクリプトを使用すると、resource_description 列を使用して、PAGELATCH_EX 競合の原因となったインデックスが分離されます。
Note
このスクリプトによって返される resource_description 列により、<DatabaseID,FileID,PageID> の形式でリソースの説明が提供されます。DatabaseID に関連付けられているデータベースの名前は、DatabaseID の値を DB_NAME () 関数に渡すと確認できます。
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
ここで示すように、競合はテーブル LATCHTEST およびインデックス名 CIX_LATCHTEST で発生しています。 ワークロードを匿名にするため、名前は変更されていることに注意してください。
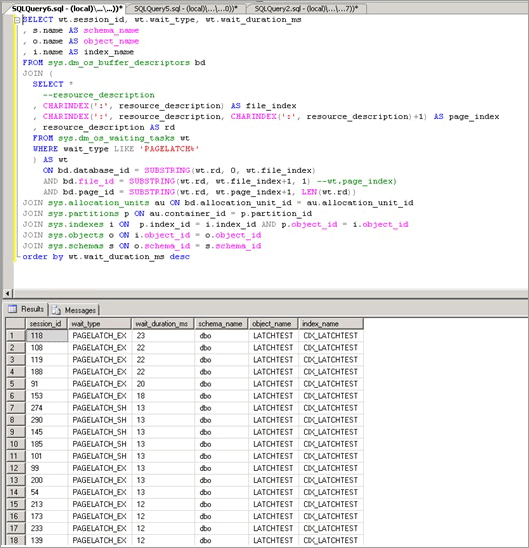
繰り返しポーリングを行い、一時テーブルを使用して構成可能な期間に対する合計待機時間を決定する、さらに高度なスクリプトについては、「付録」の「バッファー記述子のクエリを実行して、ラッチ競合の原因となっているオブジェクトを特定する」を参照してください。
ラッチ競合の原因となるオブジェクトを分離する別の方法
sys.dm_os_buffer_descriptors にクエリを実行するのは実用的 でない場合があります。 バッファー プールに使用できるシステムのメモリが増えると、この DMV を実行するために必要な時間も長くなります。 256 GB のシステムでは、この DMV を実行するのに最大で 10 分、またはそれ以上かかる場合があります。 以下では、使用可能な別の手法を、ラボで別のワークロードを使用して実行した場合の概要を説明します。
付録の「sys.dm_os_waiting_tasks のクエリを実行して待機時間の順に並べ替える」のスクリプトを使用して、現在待機中のタスクのクエリを実行します。
コンボイが観察されているキー ページを特定します。これは、複数のスレッドが同じページで競合している場合に発生します。 この例では、挿入を実行しているスレッドが B ツリーの末尾のページで競合しており、EX ラッチを取得できるまで待機します。 これは、最初のクエリの resource_description によって示されます (この例では 8:1:111305)。
トレース フラグ 3604 を有効にします。これにより、次の構文を使用して DBCC PAGE によりページに関する詳細情報が公開されます。かっこ内の値を、resource_description で取得した値に置き換えます。
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);DBCC の出力を調べます。 これらは、関連付けられたメタデータ ObjectID である必要があります (この例では "78623323")。
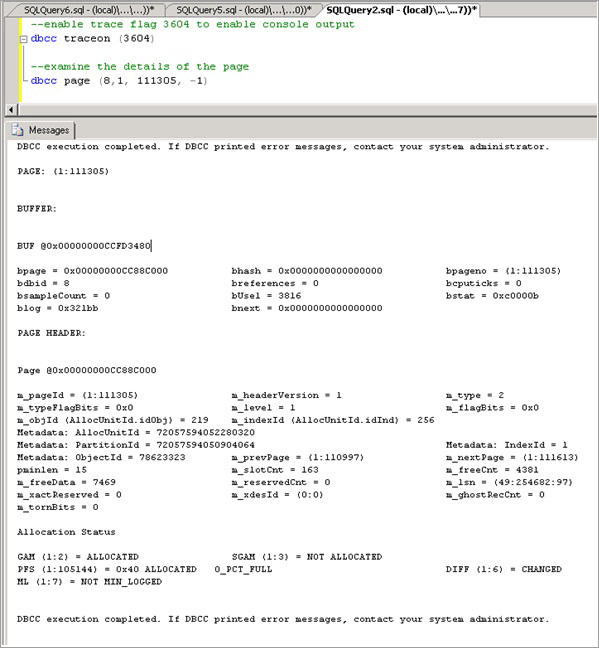
これで、次のコマンドを実行して、競合の原因になっているオブジェクトの名前を特定できます。これは LATCHTEST と予想されます。
Note
データベース コンテキストが正しいことを確認します。そうでない場合は、クエリから NULL が返されます。
--get object name select OBJECT_NAME (78623323);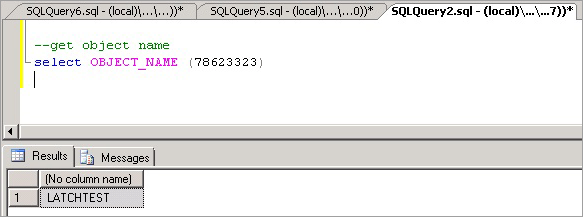
まとめと結果
上記の手法を使用することで、最も多くの挿入を受け取ったテーブルの、順番に増加するキー値のクラスター化インデックスで、競合が発生していることを確認できました。 この種の競合は、日時、ID、アプリケーションで生成されたトランザクション ID など、キー値が順番に増加するインデックスでは一般的ではありません。
この問題を解決するため、計算列でハッシュ パーティション分割を使用し、パフォーマンスが 690% 向上することを観察しました。 次の表は、計算列でハッシュ パーティション分割を実装する前と後の、アプリケーションのパフォーマンスをまとめたものです。 ラッチの競合のボトルネックが解消された後、CPU の使用率は、予想どおりスループットと共に大きくなります。
| 測定 | ハッシュ パーティション分割の前 | ハッシュ パーティション分割の後 |
|---|---|---|
| ビジネス トランザクション数/秒 | 36 | 249 |
| ページ ラッチの平均待機時間 | 36 ミリ秒 | 0.6 ミリ秒 |
| ラッチ待機数/秒 | 9,562 | 2,873 |
| SQL プロセッサ時間 | 24% | 78% |
| SQL バッチ要求数/秒 | 12,368 | 47,045 |
上の表からわかるように、ページ ラッチの過剰な競合によって発生するパフォーマンスの問題を正しく識別して解決すると、アプリケーション全体のパフォーマンスによい影響がある可能性があります。
付録: 代替手法
ページ ラッチの過剰な競合を回避するために可能な方法の 1 つは、CHAR 型の列を含む行を埋め込むことにより、各行でページ全体が使用されるようにすることです。 この方法は、データ全体のサイズが小さく、次の要素の組み合わせによって発生する EX ページ ラッチの競合を解決する必要がある場合に選択できます。
- 小さい行サイズ
- 浅い B ツリー
- ランダムな挿入、選択、更新、削除操作の割合が高いアクセス パターン
- 小さいテーブル (一時キュー テーブルなど)
ページ全体を占める行を埋め込むことにより、追加のページを割り当てるよう SQL に要求し、挿入に使用できるページ数を増やして、EX ページ ラッチの競合を減らします。
各行がページ全体を占めるように行を埋め込む
行を埋め込んでページ全体を占めるには、次のようなスクリプトを使用できます。
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
Note
値の埋め込みに必要な余分な CPU と、行をログに記録するために必要な追加領域を減らすため、可能な限り少ない文字数を使用して、強制的に 1 行を 1 ページにします。 ハイ パフォーマンスのシステムでは、すべてのバイトがカウントされます。
完全を期すため、この手法について説明します。実際の SQLCAT においては、1 回のパフォーマンス エンゲージメントが 10,000 行の小さいテーブルでのみ、これを使用しました。 テーブルが大きい場合、SQL Server でのメモリ負荷が増加し、非リーフ ページで非バッファー ラッチの競合が発生する可能性があるため、この手法の適用には制限があります。 メモリ負荷の増加は、この手法の適用に対する大きな制限要因になることがあります。 最新のサーバーでは使用可能なメモリ量が多いので、通常、OLTP ワークロードのワーキング セットの大部分はメモリに保持されます。 データ セットがメモリに収まらないほど大きいサイズになると、パフォーマンスの大幅な低下が発生します。 したがって、この手法は、小さなテーブルに対してのみ適用できます。 大きいテーブルに対する最後のページまたは後続のページでの挿入の競合などのシナリオの場合、この手法は SQLCAT では使用されません。
重要
この方法を採用すると、B ツリーの非リーフ レベルで大量のページ分割が発生する可能性があるため、ACCESS_METHODS_HOBT_VIRTUAL_ROOT のラッチの種類で多数の待機が発生する可能性があります。 SQL Server でこのようなことが発生した場合は、すべてのレベルで共有 (SH) ラッチを取得した後、ページ分割の可能性がある B ツリー内のページで、排他 (EX) ラッチを取得する必要があります。 行を埋め込んだ後、ACCESS_METHODS_HOBT_VIRTUAL_ROOT のラッチの種類で待機が多いかどうかについて、sys.dm_os_latch_stats DMV を確認します。
付録: SQL Server ラッチ競合スクリプト
このセクションでは、ラッチの競合の問題を診断およびトラブルシューティングするために使用できるスクリプトを示します。
sys.dm_os_waiting_tasks のクエリを実行してセッション ID の順に並べ替える
次のサンプル スクリプトを使用すると、sys.dm_os_waiting_tasks にクエリが実行され、セッション ID の順に並べ替えられたラッチ待機が返されます。
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
sys.dm_os_waiting_tasks のクエリを実行して待機時間の順に並べ替える
次のサンプル スクリプトを使用すると、sys.dm_os_waiting_tasks にクエリが実行され、待機時間の順に並べ替えられたラッチ待機が返されます。
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
一定期間の待機時間を計算する
次のスクリプトを使用すると、一定期間におけるラッチ待機が計算されて返されます。
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
バッファー記述子のクエリを実行して、ラッチ競合の原因となっているオブジェクトを特定する
次のスクリプトを使用すると、バッファー記述子のクエリが実行されて、最も長いラッチ待機時間に関連付けられているオブジェクトが特定されます。
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
ハッシュ パーティション分割のスクリプト
このスクリプトの使用方法については、「計算列でハッシュ パーティション分割を使用する」で説明されており、実装するときはカスタマイズする必要があります。
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
次のステップ
パフォーマンスの監視ツールの詳細については、「パフォーマンス監視およびチューニング ツール」を参照してください。