リアルタイムの運用分析のための列ストア インデックスの概要
適用対象: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Microsoft Fabric SQL Database
Microsoft Fabric SQL Database
SQL Server 2016 (13.x) にはリアルタイム運用分析が導入されており、同じデータベース テーブル上で分析ワークロードと OLTP ワークロードの両方を同時に実行できます。 分析をリアルタイムで実行するだけでなく、ETL やデータ ウェアハウスも不要になります。
リアルタイムの運用分析について説明
従来、企業は運用 (OLTP) ワークロードと分析ワークロード用に別個のシステムを保有していました。 このようなシステムでは、抽出、変換、読み込み (ETL) ジョブにより、データを運用ストアから分析ストアに定期的に移動します。 分析データは通常、分析クエリを専門的に実行するデータ ウェアハウスやデータ マートに格納されています。 今まではこのソリューションが標準でしたが、主に 3 つの課題を抱えています。
複雑さ。 ETL の実装には、修正された行を読み込むだけでも大量のコーディングを必要とする場合があります。 変更された行を識別するのが困難なこともあります。
コスト。 ETL の実装には、追加のハードウェアやソフトウェアのライセンスを購入するためのコストが必要です。
データ待機時間。 ETL の実装により、分析の実行に時間遅延が発生します。 たとえば、ETL ジョブを各営業日の最後に実行する場合、分析クエリは少なくとも 1 日前のデータに対して実行されます。 多くの企業にとって、ビジネスの基盤はリアルタイムでデータを分析することにあるため、この遅延は許容されません。 たとえば、不正行為の検出には運用データに対するリアルタイムの分析が必要です。
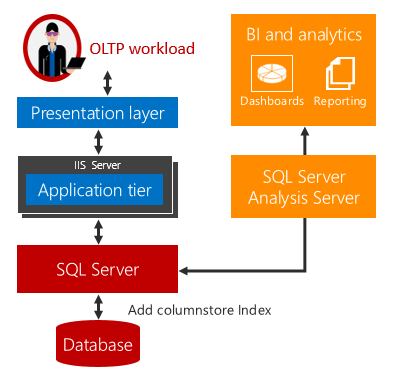
リアルタイム運用分析は、これらの課題を解決します。
分析ワークロードと OLTP ワークロードの実行の基になるテーブルが同じであるため、時間遅延は発生しません。 リアルタイム分析を使用できるシナリオでは、ETL が不要になり、別個のデータ ウェアハウスを購入して維持する必要がなくなるため、コストと複雑さが大幅に軽減されます。
Note
リアルタイム運用分析は、運用ワークロードと分析ワークロードの両方を実行できる、エンタープライズ リソース プランニング (ERP) アプリケーションなどの単一データソースのシナリオをターゲットにしています。 分析ワークロードを実行する前に複数のソースからのデータを統合する必要がある、またはキューブなどの事前集計データを使用して高度な分析パフォーマンスを必要とするときは、別個のデータ ウェアハウスが必要になることもあります。
リアルタイム分析は、行ストア テーブル上の更新可能な列ストア インデックスを使用します。 列ストア インデックスは、OLTP ワークロードと分析ワークロードが同じデータの別のコピーに対して実行されるように、データのコピーを管理します。 これにより、両方のワークロードを同時に実行してもパフォーマンス上の影響を最小限に抑えます。 SQL Server はインデックスの変更を自動的に管理するため、OLTP の変更が分析のために常に最新の状態に保たれます。 この設計により、最新のデータに対するリアルタイム分析を実現しています。 これは、ディスク ベース テーブルとメモリ最適化テーブルの両方で機能します。
作業開始の例
リアルタイム分析を開始するには、次の手順に従います。
分析に必要なデータを含む、運用スキーマ内のテーブルを識別します。
各テーブルに対して、本来 OLTP ワークロードでの既存の分析を高速化するために設計された B ツリー インデックスをすべて削除します。 それらを単一の列ストア インデックスに置き換えます。 これにより、管理するインデックスの数が少なくなるため、OLTP ワークロードの全体的なパフォーマンスが向上します。
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;インメモリ テーブル上の列ストア インデックスでは、インメモリ OLTP テクノロジとインメモリ列ストア テクノロジを統合することによって運用分析が実現し、OLTP ワークロードと分析ワークロードのパフォーマンスが向上しています。 インメモリ テーブル上の列ストア インデックスには、すべての列が含まれている必要があります。
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON ); GO
アプリケーションに変更を加えることがなく、リアルタイム運用分析を実行する準備が整いました。 分析クエリは列ストア インデックスに対して実行され、OLTP 操作は OLTP B ツリー インデックスに対して継続的に実行されます。 OLTP ワークロードは引き続き実行されますが、列ストア インデックスの管理に追加のオーバーヘッドが発生します。 次のセクションでパフォーマンスの最適化について説明します。
Note
ドキュメントでは、一般的にインデックスに関して B ツリーという用語が使用されます。 行ストア インデックスで、データベース エンジンによって B+ ツリーが実装されます。 これは、列ストア インデックスやメモリ最適化テーブルのインデックスには適用されません。 詳細については、「SQL Server と Azure SQL のインデックスのアーキテクチャとデザイン ガイド」を参照してください。
ブログ記事
リアルタイム運用分析の詳細については、次のブログ記事を参照してください。 パフォーマンス ヒントのセクションが理解しやすくなるように、まずこちらのブログ記事を読むことをお勧めします。
ビデオ
Data Exposed ビデオ シリーズでは、いくつかの機能と考慮事項について詳しく説明します。
- パート 1: Azure SQL でリアルタイムの運用分析 (HTAP) を有効にする方法
- パート 2: 運用分析を使用して既存のデータベースとアプリケーションを最適化する
- パート 3: Window Functions を使用して運用分析を作成する方法。
パフォーマンス ヒント 1: フィルター処理されたインデックスを使用したクエリ パフォーマンスの改善
リアルタイム分析の運用を実行すると、OLTP ワークロードのパフォーマンスに影響を及ぼすことがあります。 この影響は最小限に抑える必要があります。 例 A は、フィルター選択されたインデックスを使用して、非クラスター化列ストア インデックスがトランザクション ワークロードに与える影響を最小限に抑えながら、リアルタイムで分析を提供する方法を示しています。
運用ワークロード上で非クラスター化列ストア インデックスを管理するために必要なオーバーヘッドを最小限に抑えるには、フィルター処理条件を使用して ウォーム データ (緩やかに変化するデータ) 対してのみ非クラスター化列ストア インデックスを作成します。 たとえば、注文管理アプリケーションの場合、既に出荷されている注文に対して非クラスター化列ストア インデックスを作成できます。 注文が出荷された後はほとんど変化しないため、ウォーム データと捉えることができます。 フィルター処理されたインデックスを使用すると、非クラスター化列ストア インデックスのデータに必要な更新プログラムの数が少なくなるため、トランザクション ワークロードへの影響が少なくなります。
分析クエリは、ウォーム データおよび必要に応じてホット データに透過的にアクセスすることでリアルタイム分析を提供します。 運用ワークロードの大部分が "ホット" データと接触している場合、それらの操作に対して列ストア インデックスの追加メンテナンスは不要です。 ベスト プラクティスは、列の行ストア クラスター化インデックスをフィルター処理されたインデックス定義に使用することです。 SQL Server は、クラスター化インデックスを使用してフィルター処理条件を満たしていない行を迅速にスキャンします。 このクラスター化インデックスがない場合、これらの行を探すには行ストア テーブルのフル テーブル スキャンが必要になり、分析クエリのパフォーマンスに多大な悪影響を及ぼすことがあります。 クラスター化インデックスが存在しない場合は、補足的にフィルター処理された非クラスター化 B ツリー インデックスを作成してそのような行を特定できますが、非クラスター化 B ツリー インデックスを通じた広範囲の行に対するアクセスは高コストであるため、お勧めしません。
Note
フィルター処理された非クラスター化列ストア インデックスは、ディスク ベースのテーブルに対してのみサポートされます。 メモリ最適化テーブルではサポートされていません。
例 A: B ツリー インデックスからホット データ、列ストア インデックスからウォーム データにアクセスする
この例では、フィルター処理された条件 (accountkey > 0) を使用して、列ストア インデックス内の行を確立します。 目標は、フィルター処理条件と後続のクエリを設計し、頻繁に変化する B ツリー インデックスからの「ホット」データにアクセスすることと、より安定した列ストア インデックスからの「ウォーム」データにアクセスすることです。

Note
クエリ オプティマイザーでは、クエリ プランの列ストア インデックスが考慮されますが、常に選択されるわけではありません。 クエリ オプティマイザーがフィルター処理された列ストア インデックスを選択すると、列ストア インデックスからの行とフィルター処理条件を満たしていない行を透過的に結合され、リアルタイム分析を実現します。 これは、通常のフィルター処理された非クラスター インデックスとは異なり、インデックスに存在する行に限定されたクエリでのみ使用できます。
--Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
Customername nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50));
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fulfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
where orderstatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT top 5 customername, sum (PurchasePrice)
FROM orders
WHERE purchaseprice > 100.0
Group By customername;
分析クエリは、次のクエリ プランで実行されます。 フィルター処理条件を満たしていない行には、クラスター化 B ツリー インデックスを通じてアクセスされます。

詳細については、「 Blog: フィルター処理された非クラスター化列ストア インデックス」を参照してください。
パフォーマンス ヒント 2: AlwaysOn 読み取り可能セカンダリに対する分析の負荷を軽減する
フィルター処理された列ストア インデックスを使用して、列ストア インデックスのメンテナンスを最小限に抑えることはできますが、それでも分析クエリには多大なコンピューティング リソース (CPU、I/O、メモリ) が必要であり、運用ワークロードのパフォーマンスに影響します。 ほとんどのミッション クリティカルなワークロードについては、AlwaysOn 構成を使用することをお勧めします。 この構成では、負荷を読み取り可能セカンダリにオフロードすることで、実行中の分析の影響を除去できます。
パフォーマンス ヒント 3: ホット データを DELTA 行グループに保持することでインデックスの断片化を削減する
ワークロードが圧縮された行を更新または削除すると、列ストア インデックスを持つテーブルが大幅に断片化 (つまり、削除された行) になる可能性があります。 断片化された列ストア インデックスは、メモリと記憶域の非効率的な使用につながります。 また、リソースの非効率的な使用に加え、余分な I/O があることと、結果セットから削除された行をフィルター処理する必要があるため、分析クエリのパフォーマンスにも悪影響を及ぼします。
削除された行は、REORGANIZE コマンドを使用してインデックスのデフラグを実行するか、テーブル全体または影響を受けているパーティションの列ストア インデックスを再構築するまで、物理的には削除されません。 REORGANIZE と REBUILD の両方のインデックスは、高コストな操作であり、リソースを取り除いたり、ワークロードに使用されたりすることもあります。 さらに、行の圧縮が早すぎる場合は、更新によって圧縮オーバーヘッドが無駄になる可能性があるため、複数回圧縮し直す必要があります。
インデックスの断片化は、COMPRESSION_DELAY オプションを使用して最小限に抑えることができます。
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY. The columnstore index will keep the rows in closed delta rowgroup for 100 minutes
-- after it has been marked closed
CREATE NONCLUSTERED COLUMNSTORE index t_colstor_cci on t_colstor (accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION= COLUMNSTORE, COMPRESSION_DELAY = 100);
詳細については、「 Blog: Compression delay」を参照してください。
推奨されているベスト プラクティスを次に示します。
挿入/クエリ ワークロード: ワークロードで主にデータを挿入してクエリを実行する場合、COMPRESSION_DELAY オプションは既定の 0 のままにすることをお勧めします。 単一の DELTA 行グループに 100 万行が挿入されると、新しく挿入された行が圧縮されます。
このようなワークロードの例としては、(a) 従来の DW ワークロード (b) Web アプリケーションで選択パターンを分析する必要がある場合の選択ストリーム分析があります。OLTP ワークロード: ワークロードが DML の負荷が高い場合 (つまり、Update、Delete、Insert の混在が多い場合)、DMV
sys. dm_db_column_store_row_group_physical_statsを調べることで列ストア インデックスの断片化が発生する可能性があります。 10% を上回る行が最近圧縮された行グループで削除済みとマークされている場合、行を圧縮できるタイミングで COMPRESSION_DELAY オプションを使用して時間遅延を追加できます。 たとえば、ワークロードで新しく挿入された行が 60 分間 "ホット" な状態にある (複数回更新される) 場合は、COMPRESSION_DELAY を 60 にすることをお勧めします。
ほとんどのお客様は何もする必要がないことを想定しています。 COMPRESSION_DELAYオプションの既定値は、それらに対して機能する必要があります。
上級ユーザーの場合は、次のクエリを実行し、過去 7 日間に削除された行の割合を収集することをお勧めします。
SELECT row_group_id,cast(deleted_rows as float)/cast(total_rows as float)*100 as [% fragmented], created_time
FROM sys. dm_db_column_store_row_group_physical_stats
WHERE object_id = object_id('FactOnlineSales2')
AND state_desc='COMPRESSED'
AND deleted_rows>0
AND created_time > GETDATE() - 7
ORDER BY created_time DESC;
圧縮された行グループ内の削除された行の数が 20% > 場合、 < 5% のバリエーション (コールド行グループと呼ばれます) が設定された古い行グループでは、 COMPRESSION_DELAY = (youngest_rowgroup_created_time - current_time) に設定されます。 このアプローチは、安定した比較的均一なワークロードに最適です。