CREATE EXTERNAL TABLE (Transact-SQL)
外部テーブルを作成します。
この記事では、選択した SQL 製品について、構文、引数、注釈、アクセス許可、例を紹介します。
構文表記規則の詳細については、「Transact-SQL 構文表記規則」を参照してください。
製品を選択する
次の行で、興味のある製品の名前を選択すると、その製品の情報のみが表示されます。
* SQL Server *
概要:SQL Server
このコマンドでは、Hadoop クラスターに格納されているデータに PolyBase でアクセスするための外部テーブルが作成されるか、Hadoop クラスターまたは Azure Blob Storage に格納されているデータを参照する Azure Blob Storage PolyBase 外部テーブルが作成されます。
適用対象: SQL Server 2016 (またはそれ以降)
PolyBase クエリ用の外部データ ソースが含まれる外部テーブルを使用します。 外部データ ソースを使用して接続を確立し、次の主なユース ケースをサポートします。
- PolyBase を使用したデータ仮想化とデータ読み込み
-
BULK INSERTまたはOPENROWSETを使用して、SQL Server または SQL Database を使用した一括読み込み操作
「CREATE EXTERNAL DATA SOURCE」と「DROP EXTERNAL TABLE」も参照してください。
構文
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
引数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
作成するテーブルの 1 つから 3 つの部分で構成される名前。 外部テーブルの場合、SQL では、Hadoop または Azure Blob Storage で参照されているファイルまたはフォルダーに関する基本的な統計情報と共に、テーブルのメタデータのみが格納されます。 実際のデータは移動されず、SQL Server に格納されません。
重要
最適なパフォーマンスを得るには、外部データ ソース ドライバーが 3 部構成の名前をサポートしている場合は、3 部構成の名前を指定することを強くお勧めします。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE では、列名、データ型、NULL 値の許容、照合順序を構成できます。 外部テーブルに対して DEFAULT CONSTRAINT を使用することはできません。
データ型と列の数を含む列の定義は、外部ファイルのデータと一致している必要があります。 不一致がある場合、実際のデータに対してクエリを実行するときに、ファイルの行が拒否されます。
LOCATION = 'folder_or_filepath'
Hadoop または Azure Blob Storage にある実際のデータのフォルダーまたはファイル パスとファイル名を指定します。 また、S3 互換オブジェクト ストレージは SQL Server 2022 (16.x) 以降でサポートされます。 ルート フォルダーから、場所を開始します。 ルート フォルダーは、外部データ ソースで指定されたデータの場所です。
SQL Server では、CREATE EXTERNAL TABLE ステートメントによって、まだ存在しない場合にパスとフォルダーが作成されます。 その後、INSERT INTO を使用して、ローカルの SQL Server テーブルからのデータを外部データ ソースをエクスポートすることができます。 詳細については、PolyBase クエリに関するページを参照してください。
LOCATION をフォルダーとして指定した場合、外部テーブルから選択する PolyBase クエリでは、フォルダーとそのすべてのサブフォルダーからファイルが取得されます。 Hadoop と同じように PolyBase で非表示のフォルダーは返されません。 ファイル名が下線 (_) またはピリオド (.) で始まるファイルも返されません。
次に示すイメージの例では、LOCATION='/webdata/' である場合、PolyBase のクエリを実行すると、mydata.txt と mydata2.txt からの行が返されます。
mydata3.txt は非表示のサブフォルダー内のファイルであるため、返されません。 また、_hidden.txt は非表示のファイルであるため返されません。
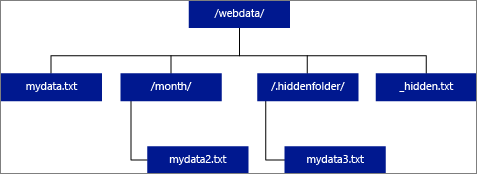
既定値を変更して、読み取りをルート フォルダーからのみに限定するには、core-site.xml 構成ファイル内で属性<polybase.recursive.traversal> を 'false' に設定します。 このファイルは <SqlBinRoot>\PolyBase\Hadoop\Conf の下にあり、SQL Server の bin ルートです。 たとえば、C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn のようにします。
DATA_SOURCE = external_data_source_name
外部データの場所が含まれている外部データ ソースの名前を指定します。 この場所は、Hadoop File System (HDFS)、Azure Blob Storage コンテナー、または Azure Data Lake Store です。 外部データ ソースを作成するには、CREATE EXTERNAL DATA SOURCE を使用します。
FILE_FORMAT = external_file_format_name
外部データのファイル形式や圧縮方法を格納する外部ファイル形式オブジェクトの名前を指定します。 外部ファイル形式を作成するには、CREATE EXTERNAL FILE FORMAT を使用します。
外部ファイル形式は、複数の類似した外部ファイルで再利用できます。
拒否オプション
このオプションは、TYPE = HADOOP である外部データ ソースでのみ使用できます。
PolyBase が外部データ ソースから取得したダーティ レコードを処理する方法を決定する、reject パラメーターを指定できます。 データ レコードの実際のデータの種類または列の数が、外部テーブルの列の定義と一致しない場合、そのデータ レコードは "ダーティ" と見なされます。
reject 値を指定または変更しない場合、PolyBase では既定値が使用されます。 reject パラメーターに関するこの情報は、CREATE EXTERNAL TABLE ステートメントを使用して外部テーブルを作成するときに、追加メタデータとして格納されます。 以降の SELECT ステートメントまたは SELECT INTO SELECT ステートメントで外部テーブルからデータを選択するとき、拒否オプションを使用して、実際のクエリが失敗するまでに拒否できる行の数または割合が PolyBase によって決定されます。 拒否のしきい値を超えるまで、クエリの (部分的な) 結果が返されます。 その後、適切なエラー メッセージと共に失敗します。
REJECT_TYPE = value | percentage
REJECT_VALUE オプションがリテラル値として指定されているか、割合として指定されているかを明確にします。
value
REJECT_VALUE は、割合ではなくリテラル値です。 拒否された行が reject_value を超えると、クエリは失敗します。
たとえば、REJECT_VALUE = 5、REJECT_TYPE = value の場合、SELECT クエリは 5 つの行が拒否された後に失敗します。
percentage
REJECT_VALUE は、リテラル値ではなく割合です。 失敗した行の percentage が reject_value を超えると、クエリは失敗します。 失敗した行の割合は、間隔をおいて計算されます。
REJECT_VALUE = reject_value
クエリが失敗する前に拒否できる行を値または割合で指定します。
REJECT_TYPE = value の場合、reject_value は 0 から 2,147, 483,647 の範囲の整数にする必要があります。
REJECT_TYPE = percentage の場合、reject_value は 0 から 100 の範囲の浮動小数にする必要があります。
REJECT_SAMPLE_VALUE = reject_sample_value
REJECT_TYPE = percentage を指定する場合、この属性は必須です。 それにより、拒否された行の割合が PolyBase によって再計算されるまでに取得が試行される行の数が決定します。
reject_sample_value パラメーターは、0 から 2,147,483,647 の範囲の整数にする必要があります。
たとえば、REJECT_SAMPLE_VALUE = 1000 の場合、PolyBase によって外部データ ファイルから 1000 行のインポートが試みられた後、失敗した行の割合が再計算されます。 失敗した行のパーセンテージが reject_value 未満の場合、PolyBase は別の 1000 行の取得を試みます。 1000 行ずつ追加でインポートを試みた後、失敗した行の割合の再計算を続けます。
Note
PolyBase では間隔を置いて失敗した行のパーセンテージを計算するため、実際の失敗した行のパーセンテージは、reject_value を超える場合があります。
例:
この例は、REJECT の 3 つのオプションが相互にどのように作用するかを示しています。 たとえば、REJECT_TYPE = percentage で REJECT_VALUE = 30、かつ REJECT_SAMPLE_VALUE = 100 の場合、次のシナリオが発生する可能性があります。
- PolyBase で最初の 100 行の取得が試みられ、25 行が失敗し、75 行が成功しました。
- 失敗した行の割合は 25% と計算されます。これは reject 値である 30% を下回っています。 その結果、PolyBase は引き続き、外部データ ソースからデータを取得します。
- PolyBase は次の 100 行の読み込みを試み、今回は 25 行が成功し、75 行が失敗しました。
- 失敗した行の割合が 50% として再計算されます。 失敗した行の割合が、30% という reject 値を超えました。
- PolyBase クエリは、最初の 200 行を取得しようとした後、拒否された行 50% で失敗します。 拒否のしきい値を超えたことが PolyBase クエリによって検出される前に、一致した行が返されていることに注意してください。
REJECTED_ROW_LOCATION = <ディレクトリの場所>
"適用対象:" SQL Server 2019 CU6 以降のバージョン、Azure Synapse Analytics。
外部データ ソース内のディレクトリを指定します。拒否された行と該当エラー ファイルをそこに書き込みます。
指定したパスが存在しない場合、PolyBase では、そのパスが自動的に作成されます。 "_rejectedrows" という名前で子ディレクトリが作成されます。 "_" 文字があることで、場所パラメーターで明示的に指定されない限り、他のデータ処理ではこのディレクトリがエスケープされます。 このディレクトリ内には、YearMonthDay -HourMinuteSecond という形式のロード サブミッション時間に基づいて作成されたフォルダーがあります (例: 20230330-173205)。 このフォルダーで、2 種類のファイル、理由ファイルとデータ ファイルが書き込まれます。 このオプションは、TYPE = HADOOP の外部データ ソースと、DELIMITEDTEXT FORMAT_TYPE を使用する外部テーブルでのみ使用できます。 詳細については、「CREATE EXTERNAL DATA SOURCE」と「CREATE EXTERNAL FILE FORMAT」を参照してください。
理由ファイルとデータ ファイルのいずれにも、CTAS ステートメントと関連付けられている queryID が含まれます。 データと理由が別々のファイル内にあるため、対応するファイルはサフィックスが一致しています。
アクセス許可
これらのユーザー アクセス許可が必要です。
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT (Hadoop と Azure Storage の外部データ ソースにのみ適用されます)
- CONTROL DATABASE (Hadoop と Azure Storage の外部データ ソースにのみ適用されます)
CREATE EXTERNAL TABLE コマンドで使われる DATABASE SCOPED CREDENTIAL で指定するリモート ログインには、LOCATION パラメーターで指定する外部データ ソースのパス、テーブル、コレクションに対する読み取りアクセス許可が必要です。 この EXTERNAL TABLE を使って Hadoop または Azure Storage の外部データ ソースにデータをエクスポートする場合は、指定するログインに LOCATION で指定するパスに対する書き込みアクセス許可が必要です。 現在、Hadoop は SQL Server 2022 (16.x) ではサポートされていないことに注意してください。
Azure Blob Storage の場合、Azure portal、Azure Blob Storage、または ADLS Gen2 のストレージ アカウントでアクセス キーと Shared Access Signature (SAS) を構成するときに、少なくとも読み取りと書き込みのアクセス許可を付与するように、[与えられているアクセス許可] を構成します。 フォルダーをまたいで検索する場合は、一覧表示アクセス許可も必要になる場合があります。 また、許可されるリソースの種類として [コンテナー] と [オブジェクト] の両方を選ぶ必要もあります。
重要
ALTER ANY EXTERNAL DATA SOURCE 権限は、あらゆる外部データ ソース オブジェクトを作成し、変更する能力をプリンシパルに与えます。そのため、データベース上のすべてのデータベース スコープ資格情報にアクセスする能力も与えます。 この権限は特権として考える必要があります。したがって、システム内の信頼できるプリンシパルにのみ与える必要があります。
エラー処理
CREATE EXTERNAL TABLE ステートメントの実行中に、PolyBase から外部データ ソースへの接続が試みられます。 接続が失敗した場合、ステートメントは失敗し、外部テーブルは作成されません。 クエリが最終的に失敗となる前に、PolyBase によって接続が再試行されるため、コマンドが失敗するまで 1 分以上かかる可能性があります。
解説
SELECT FROM EXTERNAL TABLE などのアドホック クエリのシナリオの場合、PolyBase では外部データ ソースから取得された行が一時テーブルに格納されます。 クエリ完了後、PolyBase によって一時テーブルが削除されます。 SQL テーブルには、永続的なデータは格納されません。
これに対し、SELECT INTO FROM EXTERNAL TABLE などのインポートのシナリオでは、外部データ ソースから取得された行が、PolyBase によって永続的なデータとして SQL テーブルに格納されます。 PolyBase が外部のデータを取得するときに、クエリの実行中に、新しいテーブルが作成されます。
PolyBase では、クエリのパフォーマンスを向上させるためにクエリ計算の一部を Hadoop にプッシュできます。 このアクションは述語プッシュダウンと呼ばれます。 それを有効にするには、CREATE EXTERNAL DATA SOURCE で、Hadoop のリソース マネージャーの場所のオプションを指定します。
同じまたは別の外部データ ソースを参照している多数の外部テーブルを作成できます。
制限事項と制約事項
外部テーブル用のデータは SQL Server の直接の管理下にないため、外部プロセスによっていつでも変更または削除することができます。 その結果、外部のテーブルに対するクエリの結果は確定的であることが保証されません。 同じクエリを外部のテーブルに対して実行するたびに、異なる結果が返される可能性があります。 同様に、外部データが移動または削除された場合、クエリが失敗する可能性があります。
それぞれが異なる外部データ ソースを参照する複数の外部テーブルを作成できます。 異なる複数の Hadoop データ ソースに対して同時にクエリを実行する場合は、各 Hadoop ソースに同じ 'Hadoop 接続' サーバー構成の設定が使用されている必要があります。 たとえば、ことはできません同時にクエリを実行する Cloudera Hadoop クラスターと Hortonworks の Hadoop クラスターに対してこれらさまざまな構成設定を使用するためです。 構成設定とサポートされる組み合わせについては、「PolyBase 接続構成」を参照してください。
外部テーブルがデータ型として DELIMITEDTEXT、CSV、PARQUET、または DELTA を使用している場合、外部テーブルは CREATE STATISTICS コマンドごとに 1 列の統計のみをサポートします。
外部テーブルに対しては、これらのデータ定義言語 (DDL) ステートメントのみを使用できます。
- CREATE TABLE および DROP TABLE
- CREATE STATISTICS および DROP STATISTICS
- CREATE VIEW および DROP VIEW
サポートされていない構成要素と操作:
- 外部テーブルの列に対する DEFAULT 制約
- データ操作言語 (DML) の削除、挿入、更新の操作
クエリの制限事項
PolyBase では、32 個の同時 PolyBase クエリを実行しているときに、フォルダーあたり最大 33,000 ファイルを使用できます。 この最大数には、各 HDFS フォルダー内のファイルとサブフォルダーの両方が含まれます。 コンカレンシーの度合いが 32 未満である場合、ユーザーは 33,000 より多いファイルが含まれている HDFS のフォルダーに対して PolyBase クエリを実行できます。 外部ファイルのパスを短く維持し、使用するファイルの数を HDFS フォルダーあたり 30,000 以下にすることをお勧めします。 参照しているファイルの数が多すぎる場合は、Java 仮想マシン (JVM) のメモリ不足例外が発生する可能性があります。
テーブルの幅の制限事項
SQL Server 2016 の PolyBase には、テーブル定義による有効な 1 つの行の最大幅に基づいた、行の幅 32 KB という制限があります。 列スキーマの合計が 32 KB を超えている場合、PolyBase によるデータのクエリは実行できません。
データ型の制限事項
次のデータ型は、PolyBase 外部テーブルでは使用できません。
geographygeometryhierarchyidimagetextnTextxml- 任意のユーザー定義型
データ ソース固有の制限事項
Oracle
PolyBase での使用では、Oracle シノニムはサポートされていません。
配列を含む MongoDB コレクションの外部テーブル
配列を含む MongoDB コレクションに外部テーブルを作成するには、Azure Data Studio 用のデータ仮想化の拡張機能を使用して、MongoDB 用 PolyBase ODBC ドライバーによって検出されたスキーマに基づいて CREATE EXTERNAL TABLE ステートメントを生成する必要があります。 フラット化アクションは、ドライバーによって自動的に実行されます。 または、sp_data_source_objects (Transact-SQL) を使用してコレクション スキーマ (列) を検出し、外部テーブルを手動で作成することもできます。
sp_data_source_table_columns ストアド プロシージャでは、MongoDB 用 PolyBase ODBC ドライバーによってフラット化も自動的に実行されます。 Azure Data Studio 用のデータ仮想化の拡張機能と sp_data_source_table_columns は同じ内部ストアド プロシージャを使用して、外部スキーマのクエリを実行します。
ロック
SCHEMARESOLUTION オブジェクトに対する共有ロック。
セキュリティ
外部テーブルのデータ ファイルは、Hadoop または Azure Blob Storage に格納されます。 これらのデータ ファイルはご自身のプロセスによって作成され、管理されます。 外部データのセキュリティを管理することは、ユーザー自身の責任になります。
例
A. テキスト区切り形式のデータを含む外部テーブルを作成します
この例では、テキスト区切りのファイルで書式設定されたデータを含む外部テーブルを作成するために必要なすべての手順を示します。 これは、外部データ ソース mydatasourcec と外部ファイルの形式 myfileformat を定義します。 その後、これらのデータベース レベル オブジェクトは、CREATE EXTERNAL TABLE ステートメントで参照されます。 詳細については、「CREATE EXTERNAL DATA SOURCE」と「CREATE EXTERNAL FILE FORMAT」を参照してください。
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. RCFile 形式のデータを含む外部テーブルを作成します
この例では、RCFile として書式設定されたデータを含む外部テーブルを作成するために必要なすべての手順を示します。 これは、外部データ ソース mydatasource_rc と外部ファイルの形式 myfileformat_rc を定義します。 その後、これらのデータベース レベル オブジェクトは、CREATE EXTERNAL TABLE ステートメントで参照されます。 詳細については、「CREATE EXTERNAL DATA SOURCE」と「CREATE EXTERNAL FILE FORMAT」を参照してください。
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. ORC 形式のデータを含む外部テーブルを作成します
この例では、ORC ファイルとして書式設定されたデータを含む外部テーブルを作成するために必要なすべての手順を示します。 それにより、外部データ ソース mydatasource_orc と外部ファイル myfileformat_orc を定義します。 その後、これらのデータベース レベル オブジェクトは、CREATE EXTERNAL TABLE ステートメントで参照されます。 詳細については、「CREATE EXTERNAL DATA SOURCE」と「CREATE EXTERNAL FILE FORMAT」を参照してください。
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Hadoop のデータのクエリを実行する
ClickStream は、Hadoop クラスター上の区切りテキスト ファイルである employee.tbl に接続する外部テーブルです。 次のクエリは、標準のテーブルに対するクエリとまったく同じように見えます。 ただし、このクエリでは Hadoop からデータを取得し、restuls を計算します。
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. SQL データと Hadoop データの結合
このクエリは、2 つの SQL テーブルに対する標準の JOIN とまったく同じように見えます。 違いは、PolyBase によって Hadoop からクリックストリーム データが取得され、その後 UrlDescription テーブルに結合されることです。 一方のテーブルは外部テーブルで、もう一方は標準の SQL テーブルです。
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Hadoop から SQL テーブルへのデータのインポート
この例では、標準の SQL テーブル ms_user と外部テーブル user との結合の結果を永続的に格納する新しい SQL テーブル ClickStream を作成します。
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. SQL Server の外部テーブルの作成
データベース スコープ資格情報を作成する前に、ユーザー データベースに資格情報を保護するためのマスター キーが必要です。 詳細については、「CREATE MASTER KEY」と「CREATE DATABASE SCOPED CREDENTIAL」を参照してください。
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
SQLServerInstance という名前の新しい外部データ ソースと、sqlserver.customer という名前の外部テーブルが作成されます。
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
I. Oracle の外部テーブルの作成
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Teradata の外部テーブルの作成
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. MongoDB の外部テーブルの作成
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. 外部テーブルを使用して S3 互換のオブジェクト ストレージにクエリを実行する
適用対象: SQL Server 2022 (16.x) 以降
次の例では、T-SQL を使用して、外部テーブルにクエリを実行して、S3 互換のオブジェクト ストレージに格納されている Parquet ファイルに対してクエリを実行する方法を示します。 このサンプルでは、外部データ ソース内の相対パスを使用します。
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
次の手順
関連する概念の詳細については、次の記事を参照してください。
* Azure SQL Database *
概要:Azure SQL データベース
Azure SQL Database で、エラスティック クエリ (プレビュー) 用外部テーブルを作成します。
「CREATE EXTERNAL DATA SOURCE」を参照してください。
構文
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
引数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
作成するテーブルの 1 つから 3 つの部分で構成される名前。 外部テーブルの場合、SQL では、Azure SQL Database 内で参照されているファイルまたはフォルダーに関する基本的な統計情報と共に、テーブルのメタデータのみが格納されます。 実際のデータは移動されず、Azure SQL Database に格納されません。
重要
最適なパフォーマンスを得るには、外部データ ソース ドライバーが 3 部構成の名前をサポートしている場合は、3 部構成の名前を指定することを強くお勧めします。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE では、列名、データ型、NULL 値の許容、照合順序を構成できます。 外部テーブルに対して DEFAULT CONSTRAINT を使用することはできません。
Note
Text、nText、および XML は、Azure SQL Database の外部テーブルの列に対してサポートされているデータ型ではありません。
データ型と列の数を含む列の定義は、外部ファイルのデータと一致している必要があります。 不一致がある場合、実際のデータに対してクエリを実行するときに、ファイルの行が拒否されます。
シャード化された外部テーブルのオプション
エラスティック クエリの外部データ ソース (SQL Server 以外のデータ ソース) と配布方法を指定します。
DATA_SOURCE
DATA_SOURCE 句では、外部テーブルに使用される外部データ ソース (シャード マップ) を定義します。 例については、「外部テーブルを作成する」を参照してください。
重要
Azure SQL Database では、外部データ ソース タイプの RDMS および SHARD_MAP_MANAGER への外部テーブルの作成がサポートされています。 Azure SQL Database では、Azure Blob Storage への外部テーブルの作成はサポートされていません。
SCHEMA_NAME と OBJECT_NAME
SCHEMA_NAME 句と OBJECT_NAME 句では、外部テーブルの定義を別のスキーマ内のテーブルにマップします。 これらを省略した場合、リモート オブジェクトのスキーマは "dbo" と見なされ、その名前は定義されている外部テーブルの名前と同一であると見なされます。 これは、リモート テーブルの名前が、外部テーブルを作成するデータベースで既に取得されている場合に便利です。 たとえば、スケールアウトされたデータ層のカタログ ビューまたは DMV の集計ビューを取得する外部テーブルを定義する場合が挙げられます。 カタログ ビューと DMV は既にローカルに存在するため、外部テーブルの定義にその名前を使うことはできません。 代わりに、別の名前を使用して、カタログ ビューまたは DMV の名前を SCHEMA_NAME 句または OBJECT_NAME 句で使用します。 例については、「外部テーブルを作成する」を参照してください。
DISTRIBUTION
省略可能。 これは SHARD_MAP_MANAGER 型のデータベースの場合にのみ必須です。 この引数では、テーブルをシャード化されたテーブルとして扱うか、レプリケートされたテーブルとして扱うかを制御します。 SHARDED (列名) テーブルでは、異なるテーブルからのデータは重複しません。 REPLICATED は、テーブルですべてのシャードに同じデータを持つことを指定します。 ROUND_ROBIN は、データを分散するためにアプリケーション固有のメソッドが使用されていることを示します。
DISTRIBUTION 句は、このテーブルに使用するデータ分散を指定します。 クエリ プロセッサは、DISTRIBUTION 句で提供される情報を使用して、最も効率的なクエリ プランを作成します。
- SHARDED は、データがデータベース間で行方向にパーティション分割されることを意味します。 データ分散のパーティション分割キーは、
sharding_column_nameパラメーターです。 - REPLICATED は、テーブルの同一のコピーが各データベースに存在することを意味します。 データベース間でレプリカが同じであることを自分で確認する必要があります。
- ROUND_ROBIN は、テーブルがアプリケーションに依存する分散方法を使用して、行方向にパーティション分割されることを意味します。
アクセス許可
外部テーブルへのアクセス権を持つユーザーは、外部データ ソース定義に指定された資格情報の下で、基になるリモート テーブルへのアクセス権を自動的に取得します。 外部データ ソースの資格情報による不要な特権の昇格を防ぎます。 外部テーブルに対して、通常のテーブルであるかのように GRANT または REVOKE を使用します。 外部データ ソースと外部テーブルを定義すると、外部テーブルに対して完全に T-SQL を使用できるようになります。
エラー処理
CREATE EXTERNAL TABLE ステートメントの実行時、接続が失敗した場合、ステートメントは失敗し、外部テーブルは作成されません。 クエリが最終的に失敗となる前に、SQL Database によって接続が再試行されるため、コマンドが失敗するまで 1 分以上かかる可能性があります。
解説
SELECT FROM EXTERNAL TABLE などのアドホック クエリのシナリオの場合、SQL Database では外部データ ソースから取得された行が一時テーブルに格納されます。 クエリ完了後、SQL Database によって一時テーブルが削除されます。 SQL テーブルには、永続的なデータは格納されません。
これに対し、SELECT INTO FROM EXTERNAL TABLE などのインポートのシナリオでは、外部データ ソースから取得された行が、SQL Database によって永続的なデータとして SQL テーブルに格納されます。 SQL Database が外部のデータを取得するときに、クエリの実行中に、新しいテーブルが作成されます。
同じまたは別の外部データ ソースを参照している多数の外部テーブルを作成できます。
それぞれが異なる外部データ ソースを参照する複数の外部テーブルを作成できます。
制限
分離セマンティクス: 外部テーブルを介したデータへのアクセスは、SQL Server 内の分離セマンティクスに準拠していません。 つまり、外部テーブルに対してクエリを実行しても、ロックやスナップショットの分離は強制されません。 したがって、外部データ ソース内のデータが変更されている場合、データの戻り値が変更される可能性があります。 同じクエリを外部のテーブルに対して実行するたびに、異なる結果が返される可能性があります。 同様に、外部データが移動または削除された場合、クエリが失敗する可能性があります。
コンストラクトと操作は、サポートされていません。
- 外部テーブルの列に対する DEFAULT 制約。
- データ操作言語 (DML) の削除、挿入、更新の操作。
- 外部テーブル列に対する動的データ マスク。
- Azure SQL Database の外部テーブルでは、カーソルはサポートされていません。
リテラル述語のみ: クエリで定義されているリテラル述語のみを外部データ ソースにプッシュダウンできます。 これはリンク サーバーとは異なり、クエリ実行中に決定された述語を使用できる場合、つまりクエリ プランで入れ子になったループと組み合わせて使用されるときにアクセスします。 多くの場合、外部テーブル全体がローカルにコピーされ、結合されます。
次の例では、
External.Ordersが外部テーブルで、Customerがローカル テーブルの場合、コンパイル時に必要な述語がわからないため、クエリによって外部テーブル全体がローカルにコピーされます。SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );並列処理なし: 外部テーブルを使用すると、クエリ プランで並列処理を使用できなくなります。
リモート クエリとして実行: 外部テーブルはリモート クエリとして実装されるため、返される推定行数は通常 1000 です。 外部テーブルのフィルター処理に使用される述語の種類に基づく他の規則があります。 これらは、外部テーブルの実際のデータに基づく推定ではなく、ルールベースの推定です。 Optimiser は、リモート データ ソースにアクセスせず、より正確な推定を取得します。
プライベート エンドポイントではサポートされていません:リモート テーブルへの接続がプライベート エンドポイントの場合、外部テーブル クエリはサポートされません。
データ型の制限事項
次のデータ型は、PolyBase 外部テーブルでは使用できません。
geographygeometryhierarchyidimagetextnTextxml- 任意のユーザー定義型
ロック
SCHEMARESOLUTION オブジェクトに対する共有ロック。
例
A. Azure SQL Database の外部テーブルを作成します
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. シャード化されたデータ ソース用の外部テーブルの作成
この例では、SCHEMA_NAME 句と OBJECT_NAME 句を使用してリモートの DMV を外部テーブルに再マッピングします。
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
次の手順
外部テーブルの詳細については、次の記事の Azure SQL Database を参照してください。
* Azure Synapse
Analytics *
概要:Azure Synapse Analytics
次のために外部テーブルを使用します。
- 専用 SQL プールでは、Hadoop、Azure Blob Storage、Azure Data Lake Storage Gen1 および Gen2 のデータのクエリ、インポート、格納を行うことができます。
- サーバーレス SQL プールでは、Azure Blob Storage、Azure Data Lake Storage Gen1 および Gen2 のデータのクエリ、インポート、格納を行うことができます。 サーバーレスでは、
TYPE=Hadoopはサポートされていません。
「CREATE EXTERNAL DATA SOURCE」と「DROP EXTERNAL TABLE」も参照してください。
Azure Synapse で外部テーブルを使用するためのその他のガイダンスと例については、「Synapse SQL で外部テーブルを使用する」を参照してください。
構文
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
引数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
作成するテーブルの 1 つから 3 つの部分で構成される名前。 外部テーブルの場合、Azure Data Lake、Hadoop、または Azure Blob Storage で参照されているファイルまたはフォルダーに関する基本的な統計情報と共に、テーブルのメタデータのみ。 外部テーブルの作成時に、実際のデータは移動または格納されません。
重要
最適なパフォーマンスを得るには、外部データ ソース ドライバーが 3 部構成の名前をサポートしている場合は、3 部構成の名前を指定することを強くお勧めします。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE では、列名、データ型、NULL 値の許容、照合順序を構成できます。 外部テーブルに対して DEFAULT CONSTRAINT を使用することはできません。
Note
非推奨のデータ型 text、ntext および XML は、Synapse Analytics の外部テーブルの列に対してサポートされているデータ型ではありません。
- 区切りファイルを読み取る場合、データ型と列の数を含む列の定義は、外部ファイルのデータと一致している必要があります。 不一致がある場合、実際のデータに対してクエリを実行するときに、ファイルの行が拒否されます。
- Parquet ファイルからの読み取りの場合は、読み取りたい列だけを指定して、残りをスキップすることができます。
LOCATION = 'folder_or_filepath'
Azure Data Lake、Hadoop、または Azure Blob Storage にある実際のデータのフォルダーまたはファイル パスとファイル名を指定します。 ルート フォルダーから、場所を開始します。 ルート フォルダーは、外部データ ソースで指定されたデータの場所です。
CREATE EXTERNAL TABLE AS SELECT ステートメントによって、存在しない場合にパスとフォルダーが作成されます。
CREATE EXTERNAL TABLE では、パスとフォルダーが作成されません。
LOCATION をフォルダーとして指定した場合、外部テーブルから選択する PolyBase クエリでは、フォルダーとそのすべてのサブフォルダーからファイルが取得されます。 Hadoop と同じように PolyBase で非表示のフォルダーは返されません。 ファイル名が下線 (_) またはピリオド (.) で始まるファイルも返されません。
次に示すイメージの例では、LOCATION='/webdata/' である場合、PolyBase のクエリを実行すると、mydata.txt と mydata2.txt からの行が返されます。
mydata3.txt は非表示のフォルダーのサブフォルダー内にあるため、返されません。 また、_hidden.txt は非表示のファイルであるため返されません。
Hadoop 外部テーブルとは異なり、ネイティブ外部テーブルでは、パスの最後に /** を指定しない限り、サブフォルダーが返されません。 この例では、LOCATION='/webdata/' である場合、サーバーレス SQL プールのクエリで mydata.txt から行が返されます。 mydata2.txt と mydata3.txt はサブフォルダー内にあるため、これらは返されません。 Hadoop テーブルでは、サブフォルダー内のすべてのファイルが返されます。
Hadoop 外部テーブルとネイティブ外部テーブルではどちらも、名前が下線 (_) またはピリオド (.) で始まるファイルはスキップされます。
DATA_SOURCE = external_data_source_name
外部データの場所が含まれている外部データ ソースの名前を指定します。 この場所は Azure Data Lake 内にあります。 外部データ ソースを作成するには、CREATE EXTERNAL DATA SOURCE を使用します。
FILE_FORMAT = external_file_format_name
外部データのファイル形式や圧縮方法を格納する外部ファイル形式オブジェクトの名前を指定します。 外部ファイル形式を作成するには、CREATE EXTERNAL FILE FORMAT を使用します。
TABLE_OPTIONS
基になるファイルを読み取る方法を示す一連のオプションを指定します。 現時点で使用できる唯一のオプションは、{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]} です。これは、不整合な読み取り操作が発生する可能性がある場合でも、基になるファイルに対して行われた更新を無視するように外部テーブルに指示します。 このオプションは、ファイルが頻繁に追加される特殊な場合にのみ使用してください。 このオプションは、CSV 形式のサーバーレス SQL プールで使用できます。
REJECT オプション
Azure Synapse Analytics のサーバーレス SQL プールの拒否オプションはプレビュー段階です。
このオプションは、TYPE = HADOOP である外部データ ソースでのみ使用できます。
PolyBase が外部データ ソースから取得したダーティ レコードを処理する方法を決定する、reject パラメーターを指定できます。 データ レコードの実際のデータの種類または列の数が、外部テーブルの列の定義と一致しない場合、そのデータ レコードは "ダーティ" と見なされます。
reject 値を指定または変更しない場合、PolyBase では既定値が使用されます。 reject パラメーターに関するこの情報は、CREATE EXTERNAL TABLE ステートメントを使用して外部テーブルを作成するときに、追加メタデータとして格納されます。 以降の SELECT ステートメントまたは SELECT INTO SELECT ステートメントで外部テーブルからデータを選択するとき、拒否オプションを使用して、実際のクエリが失敗するまでに拒否できる行の数または割合が PolyBase によって決定されます。 拒否のしきい値を超えるまで、クエリの (部分的な) 結果が返されます。 その後、適切なエラー メッセージと共に失敗します。
PARSER_VERSION 形式オプションは、サーバーレス SQL プールでのみサポートされます。
REJECT_TYPE = value | percentage
REJECT_VALUE オプションがリテラル値として指定されているか、割合として指定されているかを明確にします。
value
REJECT_VALUE は、割合ではなくリテラル値です。 拒否された行が reject_value を超えると、PolyBase クエリは失敗します。
たとえば、REJECT_VALUE = 5 で REJECT_TYPE = value の場合、PolyBase の SELECT クエリは、5 行を拒否した後に失敗します。
percentage
REJECT_VALUE は、リテラル値ではなく割合です。 失敗した行の percentage が reject_value を超えると、PolyBase クエリは失敗します。 失敗した行の割合は、間隔をおいて計算されます。
REJECT_VALUE = reject_value
クエリが失敗する前に拒否できる行を値または割合で指定します。
- REJECT_TYPE = value の場合、reject_value は 0 から 2,147, 483,647 の範囲の整数にする必要があります。
- REJECT_TYPE = percentage の場合、reject_value は 0 から 100 の範囲の浮動小数にする必要があります。 割合は、
TYPE=HADOOPである専用 SQL プールに対してのみ有効です。
拒否された行が reject_value を超えると、クエリは失敗します。 たとえば、REJECT_VALUE = 5 で REJECT_TYPE = value の場合、SELECT クエリは、5 行を拒否した後に失敗します。
REJECT_SAMPLE_VALUE = reject_sample_value
REJECT_TYPE = percentage を指定する場合、この属性は必須です。 それにより、拒否された行の割合が PolyBase によって再計算されるまでに取得が試行される行の数が決定します。
reject_sample_value パラメーターは、0 から 2,147,483,647 の範囲の整数にする必要があります。
たとえば、REJECT_SAMPLE_VALUE = 1000 の場合、PolyBase によって外部データ ファイルから 1000 行のインポートが試みられた後、失敗した行の割合が再計算されます。 失敗した行のパーセンテージが reject_value 未満の場合、PolyBase は別の 1000 行の取得を試みます。 1000 行ずつ追加でインポートを試みた後、失敗した行の割合の再計算を続けます。
Note
PolyBase では間隔を置いて失敗した行のパーセンテージを計算するため、実際の失敗した行のパーセンテージは、reject_value を超える場合があります。
例:
この例は、REJECT の 3 つのオプションが相互にどのように作用するかを示しています。 たとえば、REJECT_TYPE = percentage で REJECT_VALUE = 30、かつ REJECT_SAMPLE_VALUE = 100 の場合、次のシナリオが発生する可能性があります。
- PolyBase で最初の 100 行の取得が試みられ、25 行が失敗し、75 行が成功しました。
- 失敗した行の割合は 25% と計算されます。これは reject 値である 30% を下回っています。 その結果、PolyBase は引き続き、外部データ ソースからデータを取得します。
- PolyBase は次の 100 行の読み込みを試み、今回は 25 行が成功し、75 行が失敗しました。
- 失敗した行の割合が 50% として再計算されます。 失敗した行の割合が、30% という reject 値を超えました。
- PolyBase クエリは、最初の 200 行を取得しようとした後、拒否された行 50% で失敗します。 拒否のしきい値を超えたことが PolyBase クエリによって検出される前に、一致した行が返されていることに注意してください。
REJECTED_ROW_LOCATION = <ディレクトリの場所>
外部データ ソース内のディレクトリを指定します。拒否された行と該当エラー ファイルをそこに書き込みます。
指定したパスが存在しない場合は、作成されます。
_rejectedrows という名前で子ディレクトリが作成されます。
_ 文字があることで、場所パラメーターで明示的に指定されない限り、他のデータ処理ではこのディレクトリがエスケープされます。
- サーバーレス SQL プールでは、パスは
YearMonthDay_HourMinuteSecond_StatementIDです。 ステートメント id を使用して、フォルダーをその生成元のクエリと関連付けることができます。 - 専用 SQL プールでは、作成されるパスはロード サブミッションの時間に基づき、
YearMonthDay -HourMinuteSecondという形式になります (例:20180330-173205)。
このフォルダーに、2 種類のファイル (_reason ファイルとデータ ファイル) が書き込まれます。
詳しくは、「CREATE EXTERNAL DATA SOURCE」をご覧ください。
理由ファイルとデータ ファイルのいずれにも、CTAS ステートメントと関連付けられている queryID が含まれます。 データと理由が別々のファイル内にあるため、対応するファイルはサフィックスが一致しています。
サーバーレス SQL プールの場合、error.json ファイルには、拒否された行に関連して発生したエラーを含む JSON 配列が含まれます。 エラーを表す各要素には、次の属性が含まれています。
| 属性 | 説明 |
|---|---|
| エラー | 行が拒否された理由。 |
| 行 | ファイル内の拒否された行の序数。 |
| 列 | 拒否された列の序数。 |
| 値 | 拒否された列の値。 値が 100 文字を超える場合は、最初の 100 文字のみが表示されます。 |
| File | 行が属しているファイルのパス。 |
アクセス許可
これらのユーザー アクセス許可が必要です。
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Note
MASTER KEY、DATABASE SCOPED CREDENTIAL、および EXTERNAL DATA SOURCE のみを作成するには、CONTROL DATABASE のアクセス許可が必要です
外部データ ソースを作成するログインには、Hadoop または Azure Blob Storage 内にある外部データ ソースに対する読み取りおよび書き込みのアクセス許可が必要であることに注意してください。
重要
ALTER ANY EXTERNAL DATA SOURCE 権限は、あらゆる外部データ ソース オブジェクトを作成し、変更する能力をプリンシパルに与えます。そのため、データベース上のすべてのデータベース スコープ資格情報にアクセスする能力も与えます。 この権限は特権として考える必要があります。したがって、システム内の信頼できるプリンシパルにのみ与える必要があります。
エラー処理
CREATE EXTERNAL TABLE ステートメントの実行中に、PolyBase から外部データ ソースへの接続が試みられます。 接続が失敗した場合、ステートメントは失敗し、外部テーブルは作成されません。 クエリが最終的に失敗となる前に、PolyBase によって接続が再試行されるため、コマンドが失敗するまで 1 分以上かかる可能性があります。
解説
SELECT FROM EXTERNAL TABLE などのアドホック クエリのシナリオの場合、PolyBase では外部データ ソースから取得された行が一時テーブルに格納されます。 クエリ完了後、PolyBase によって一時テーブルが削除されます。 SQL テーブルには、永続的なデータは格納されません。
これに対し、SELECT INTO FROM EXTERNAL TABLE などのインポートのシナリオでは、外部データ ソースから取得された行が、PolyBase によって永続的なデータとして SQL テーブルに格納されます。 PolyBase が外部のデータを取得するときに、クエリの実行中に、新しいテーブルが作成されます。
PolyBase では、クエリのパフォーマンスを向上させるためにクエリ計算の一部を Hadoop にプッシュできます。 このアクションは述語プッシュダウンと呼ばれます。 それを有効にするには、CREATE EXTERNAL DATA SOURCE で、Hadoop のリソース マネージャーの場所のオプションを指定します。
同じまたは別の外部データ ソースを参照している多数の外部テーブルを作成できます。
UTF-8 照合順序を使用するソース データに注意してください。 UTF-8 照合順序を使用するソース データの場合は、CREATE EXTERNAL TABLE ステートメントで UTF-8 以外の照合順序を各 UTF-8 列に手動で指定する必要があります。 これは、UTF-8 のサポートが外部テーブルに拡張されないためです。 UTF-8 照合順序を使用して外部テーブルを作成しようとすると、Unsupported collation エラー メッセージが表示されます。 外部テーブルのデータベース照合順序が UTF-8 照合順序の場合、たとえば、[UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL, など、UTF-8 以外の列の照合順序を明示的に指定しない限り、外部テーブルの作成は失敗します。
Azure Synapse Analytics のサーバーレスおよび専用 SQL プールでは、データ仮想化に異なるコード ベースを使用します。 サーバーレス SQL プールでは、ネイティブ データ仮想化テクノロジがサポートされています。 専用 SQL プールでは、ネイティブと PolyBase の両方のデータ仮想化がサポートされています。 PolyBase データ仮想化は、EXTERNAL DATA SOURCE が TYPE=HADOOP で作成されるときに使用されます。
制限事項と制約事項
外部テーブル用のデータは Azure Synapse の直接の管理下にないため、外部プロセスによっていつでも変更または削除することができます。 その結果、外部のテーブルに対するクエリの結果は確定的であることが保証されません。 同じクエリを外部のテーブルに対して実行するたびに、異なる結果が返される可能性があります。 同様に、外部データが移動または削除された場合、クエリが失敗する可能性があります。
それぞれが異なる外部データ ソースを参照する複数の外部テーブルを作成できます。
外部テーブルに対しては、これらのデータ定義言語 (DDL) ステートメントのみを使用できます。
- CREATE TABLE および DROP TABLE
- CREATE STATISTICS および DROP STATISTICS
- CREATE VIEW および DROP VIEW
サポートされていない構成要素と操作:
- 外部テーブルの列に対する DEFAULT 制約
- データ操作言語 (DML) の削除、挿入、更新の操作
- 外部テーブル列に対する動的データ マスク
クエリの制限事項
フォルダーあたりのファイルは 30,000 個を超えないようにすることをお勧めします。 参照しているファイルの数が多すぎる場合は、Java 仮想マシン (JVM) のメモリ不足の例外が発生したり、パフォーマンスが低下したりする可能性があります。
テーブルの幅の制限事項
Azure Data Warehouse の PolyBase には、テーブル定義による有効な 1 つの行の最大幅に基づいた、行の幅 1 MB という制限があります。 列スキーマの合計が 1 MB を超えている場合、PolyBase によるデータのクエリは実行できません。
データ型の制限事項
次のデータ型は、PolyBase 外部テーブルでは使用できません。
geographygeometryhierarchyidimagetextnTextxml- 任意のユーザー定義型
ロック
SCHEMARESOLUTION オブジェクトに対する共有ロック。
例
A. ADLS Gen 2 から Azure Microsoft Azure Synapse Analytics にデータをインポートする
ADLS Gen 1 の例については、「CREATE EXTERNAL DATA SOURCE」を参照してください。
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Parquet から Azure Synapse Analytics にデータをインポートする
次の例では、外部テーブルを作成します。 次に、最初の行が返されます。
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
次の手順
外部テーブルと関連する概念の詳細については、次の記事を参照してください。
* Analytics
Platform System (PDW) *
概要:分析プラットフォーム システム
次のために外部テーブルを使用します。
- Transact-SQL ステートメントで Hadoop または Azure Blob Storage のデータのクエリを実行します。
- Hadoop または Azure Blob Storage からデータをインポートして、Analytics Platform System に格納します。
「CREATE EXTERNAL DATA SOURCE」と「DROP EXTERNAL TABLE」も参照してください。
構文
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
引数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
作成するテーブルの 1 つから 3 つの部分で構成される名前。 外部テーブルの場合、Analytics Platform System では、Hadoop または Azure Blob Storage で参照されているファイルまたはフォルダーに関する基本的な統計情報と共に、テーブルのメタデータのみが格納されます。 実際のデータが Analytics Platform System に移されたり、格納されたりすることはありません。
重要
最適なパフォーマンスを得るには、外部データ ソース ドライバーが 3 部構成の名前をサポートしている場合は、3 部構成の名前を指定することを強くお勧めします。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE では、列名、データ型、NULL 値の許容、照合順序を構成できます。 外部テーブルに対して DEFAULT CONSTRAINT を使用することはできません。
データ型と列の数を含む列の定義は、外部ファイルのデータと一致している必要があります。 不一致がある場合、実際のデータに対してクエリを実行するときに、ファイルの行が拒否されます。
LOCATION = 'folder_or_filepath'
Hadoop または Azure Blob Storage にある実際のデータのフォルダーまたはファイル パスとファイル名を指定します。 ルート フォルダーから、場所を開始します。 ルート フォルダーは、外部データ ソースで指定されたデータの場所です。
Analytics Platform System では、CREATE EXTERNAL TABLE AS SELECT ステートメントによって、存在しない場合にパスとフォルダーが作成されます。
CREATE EXTERNAL TABLE では、パスとフォルダーが作成されません。
LOCATION をフォルダーとして指定した場合、外部テーブルから選択する PolyBase クエリでは、フォルダーとそのすべてのサブフォルダーからファイルが取得されます。 Hadoop と同じように PolyBase で非表示のフォルダーは返されません。 ファイル名が下線 (_) またはピリオド (.) で始まるファイルも返されません。
次に示すイメージの例では、LOCATION='/webdata/' である場合、PolyBase のクエリを実行すると、mydata.txt と mydata2.txt からの行が返されます。
mydata3.txt は非表示のフォルダーのサブフォルダー内にあるため、返されません。 また、_hidden.txt は非表示のファイルであるため返されません。
既定値を変更して、読み取りをルート フォルダーからのみに限定するには、<polybase.recursive.traversal> 構成ファイルで属性 core-site.xml を "false" に設定します。 このファイルは <SqlBinRoot>\PolyBase\Hadoop\Conf\ の下にあり、SQL Server の bin ルートです。 たとえば、C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\ のようにします。
DATA_SOURCE = external_data_source_name
外部データの場所が含まれている外部データ ソースの名前を指定します。 この場所は、Hadoop または Azure Blob Storage です。 外部データ ソースを作成するには、CREATE EXTERNAL DATA SOURCE を使用します。
FILE_FORMAT = external_file_format_name
外部データのファイル形式や圧縮方法を格納する外部ファイル形式オブジェクトの名前を指定します。 外部ファイル形式を作成するには、CREATE EXTERNAL FILE FORMAT を使用します。
拒否オプション
このオプションは、TYPE = HADOOP である外部データ ソースでのみ使用できます。
PolyBase が外部データ ソースから取得したダーティ レコードを処理する方法を決定する、reject パラメーターを指定できます。 データ レコードの実際のデータの種類または列の数が、外部テーブルの列の定義と一致しない場合、そのデータ レコードは "ダーティ" と見なされます。
reject 値を指定または変更しない場合、PolyBase では既定値が使用されます。 reject パラメーターに関するこの情報は、CREATE EXTERNAL TABLE ステートメントを使用して外部テーブルを作成するときに、追加メタデータとして格納されます。 以降の SELECT ステートメントまたは SELECT INTO SELECT ステートメントで外部テーブルからデータを選択するとき、拒否オプションを使用して、実際のクエリが失敗するまでに拒否できる行の数または割合が PolyBase によって決定されます。 拒否のしきい値を超えるまで、クエリの (部分的な) 結果が返されます。 その後、適切なエラー メッセージと共に失敗します。
REJECT_TYPE = value | percentage
REJECT_VALUE オプションがリテラル値として指定されているか、割合として指定されているかを明確にします。
value
REJECT_VALUE は、割合ではなくリテラル値です。 拒否された行が reject_value を超えると、PolyBase クエリは失敗します。
たとえば、REJECT_VALUE = 5 で REJECT_TYPE = value の場合、PolyBase の SELECT クエリは、5 行を拒否した後に失敗します。
percentage
REJECT_VALUE は、リテラル値ではなく割合です。 失敗した行の percentage が reject_value を超えると、PolyBase クエリは失敗します。 失敗した行の割合は、間隔をおいて計算されます。
REJECT_VALUE = reject_value
クエリが失敗する前に拒否できる行を値または割合で指定します。
REJECT_TYPE = value の場合、reject_value は 0 から 2,147, 483,647 の範囲の整数にする必要があります。
REJECT_TYPE = percentage の場合、reject_value は 0 から 100 の範囲の浮動小数にする必要があります。
REJECT_SAMPLE_VALUE = reject_sample_value
REJECT_TYPE = percentage を指定する場合、この属性は必須です。 それにより、拒否された行の割合が PolyBase によって再計算されるまでに取得が試行される行の数が決定します。
reject_sample_value パラメーターは、0 から 2,147,483,647 の範囲の整数にする必要があります。
たとえば、REJECT_SAMPLE_VALUE = 1000 の場合、PolyBase によって外部データ ファイルから 1000 行のインポートが試みられた後、失敗した行の割合が再計算されます。 失敗した行のパーセンテージが reject_value 未満の場合、PolyBase は別の 1000 行の取得を試みます。 1000 行ずつ追加でインポートを試みた後、失敗した行の割合の再計算を続けます。
Note
PolyBase では間隔を置いて失敗した行のパーセンテージを計算するため、実際の失敗した行のパーセンテージは、reject_value を超える場合があります。
例:
この例は、REJECT の 3 つのオプションが相互にどのように作用するかを示しています。 たとえば、REJECT_TYPE = percentage で REJECT_VALUE = 30、かつ REJECT_SAMPLE_VALUE = 100 の場合、次のシナリオが発生する可能性があります。
- PolyBase で最初の 100 行の取得が試みられ、25 行が失敗し、75 行が成功しました。
- 失敗した行の割合は 25% と計算されます。これは reject 値である 30% を下回っています。 その結果、PolyBase は引き続き、外部データ ソースからデータを取得します。
- PolyBase は次の 100 行の読み込みを試み、今回は 25 行が成功し、75 行が失敗しました。
- 失敗した行の割合が 50% として再計算されます。 失敗した行の割合が、30% という reject 値を超えました。
- PolyBase クエリは、最初の 200 行を取得しようとした後、拒否された行 50% で失敗します。 拒否のしきい値を超えたことが PolyBase クエリによって検出される前に、一致した行が返されていることに注意してください。
アクセス許可
これらのユーザー アクセス許可が必要です。
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
- CONTROL DATABASE
外部データ ソースを作成するログインには、Hadoop または Azure Blob Storage 内にある外部データ ソースに対する読み取りおよび書き込みのアクセス許可が必要であることに注意してください。
重要
ALTER ANY EXTERNAL DATA SOURCE 権限は、あらゆる外部データ ソース オブジェクトを作成し、変更する能力をプリンシパルに与えます。そのため、データベース上のすべてのデータベース スコープ資格情報にアクセスする能力も与えます。 この権限は特権として考える必要があります。したがって、システム内の信頼できるプリンシパルにのみ与える必要があります。
エラー処理
CREATE EXTERNAL TABLE ステートメントの実行中に、PolyBase から外部データ ソースへの接続が試みられます。 接続が失敗した場合、ステートメントは失敗し、外部テーブルは作成されません。 クエリが最終的に失敗となる前に、PolyBase によって接続が再試行されるため、コマンドが失敗するまで 1 分以上かかる可能性があります。
解説
SELECT FROM EXTERNAL TABLE などのアドホック クエリのシナリオの場合、PolyBase では外部データ ソースから取得された行が一時テーブルに格納されます。 クエリ完了後、PolyBase によって一時テーブルが削除されます。 SQL テーブルには、永続的なデータは格納されません。
これに対し、SELECT INTO FROM EXTERNAL TABLE などのインポートのシナリオでは、外部データ ソースから取得された行が、PolyBase によって永続的なデータとして SQL テーブルに格納されます。 PolyBase が外部のデータを取得するときに、クエリの実行中に、新しいテーブルが作成されます。
PolyBase では、クエリのパフォーマンスを向上させるためにクエリ計算の一部を Hadoop にプッシュできます。 このアクションは述語プッシュダウンと呼ばれます。 それを有効にするには、CREATE EXTERNAL DATA SOURCE で、Hadoop のリソース マネージャーの場所のオプションを指定します。
同じまたは別の外部データ ソースを参照している多数の外部テーブルを作成できます。
制限事項と制約事項
外部テーブル用のデータはアプライアンスの直接の管理下にないため、外部プロセスによっていつでも変更または削除することができます。 その結果、外部のテーブルに対するクエリの結果は確定的であることが保証されません。 同じクエリを外部のテーブルに対して実行するたびに、異なる結果が返される可能性があります。 同様に、外部データが移動または削除された場合、クエリが失敗する可能性があります。
それぞれが異なる外部データ ソースを参照する複数の外部テーブルを作成できます。 異なる複数の Hadoop データ ソースに対して同時にクエリを実行する場合は、各 Hadoop ソースに同じ 'Hadoop 接続' サーバー構成の設定が使用されている必要があります。 たとえば、ことはできません同時にクエリを実行する Cloudera Hadoop クラスターと Hortonworks の Hadoop クラスターに対してこれらさまざまな構成設定を使用するためです。 構成設定とサポートされる組み合わせについては、「PolyBase 接続構成」を参照してください。
外部テーブルに対しては、これらのデータ定義言語 (DDL) ステートメントのみを使用できます。
- CREATE TABLE および DROP TABLE
- CREATE STATISTICS および DROP STATISTICS
- CREATE VIEW および DROP VIEW
サポートされていない構成要素と操作:
- 外部テーブルの列に対する DEFAULT 制約
- データ操作言語 (DML) の削除、挿入、更新の操作
- 外部テーブル列に対する動的データ マスク
クエリの制限事項
PolyBase では、32 個の同時 PolyBase クエリを実行しているときに、フォルダーあたり最大 33,000 ファイルを使用できます。 この最大数には、各 HDFS フォルダー内のファイルとサブフォルダーの両方が含まれます。 コンカレンシーの度合いが 32 未満である場合、ユーザーは 33,000 より多いファイルが含まれている HDFS のフォルダーに対して PolyBase クエリを実行できます。 外部ファイルのパスを短く維持し、使用するファイルの数を HDFS フォルダーあたり 30,000 以下にすることをお勧めします。 参照しているファイルの数が多すぎる場合は、Java 仮想マシン (JVM) のメモリ不足例外が発生する可能性があります。
テーブルの幅の制限事項
SQL Server 2016 の PolyBase には、テーブル定義による有効な 1 つの行の最大幅に基づいた、行の幅 32 KB という制限があります。 列スキーマの合計が 32 KB を超えている場合、PolyBase によるデータのクエリは実行できません。
Azure Synapse Analytics では、この制限は 1 MB に引き上げられました。
データ型の制限事項
次のデータ型は、PolyBase 外部テーブルでは使用できません。
geographygeometryhierarchyidimagetextnTextxml- 任意のユーザー定義型
ロック
SCHEMARESOLUTION オブジェクトに対する共有ロック。
セキュリティ
外部テーブルのデータ ファイルは、Hadoop または Azure Blob Storage に格納されます。 これらのデータ ファイルはご自身のプロセスによって作成され、管理されます。 外部データのセキュリティを管理することは、ユーザー自身の責任になります。
例
A. HDFS データと Analytics Platform System データを結合します
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. HDFS から分散 Analytics Platform System テーブルに行データをインポートします
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. HDFS から複製 Analytics Platform System テーブルに行データをインポートします
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
次の手順
分析プラットフォームシステムの外部テーブルの詳細については、次の記事を参照してください。
* Azure SQL Managed Instance *
概要:Azure SQL Managed Instance
Azure SQL Managed Instance で外部データ テーブルを作成します。 詳細については、「Azure SQL Managed Instance によるデータ仮想化」を参照してください。
Azure SQL Managed Instance のデータ仮想化では、Azure Data Lake Storage Gen2 または Azure Blob Storage でさまざまなファイル形式の外部データにアクセスしたり、T-SQL ステートメントを使ってそれらに対してクエリを実行したりできます。結合を使用することでデータを、ローカルに格納されたリレーショナル データと組み合わせることもできます。
「CREATE EXTERNAL DATA SOURCE」と「DROP EXTERNAL TABLE」も参照してください。
構文
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
引数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
作成するテーブルの 1 つから 3 つの部分で構成される名前。 外部テーブルの場合、Azure Data Lake または Azure Blob Storage で参照されているファイルまたはフォルダーに関する基本的な統計情報と共に、テーブルのメタデータのみ。 外部テーブルの作成時に、実際のデータは移動または格納されません。
重要
最適なパフォーマンスを得るには、外部データ ソース ドライバーが 3 部構成の名前をサポートしている場合は、3 部構成の名前を指定することを強くお勧めします。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE では、列名、データ型、NULL 値の許容、照合順序を構成できます。 外部テーブルに対して DEFAULT CONSTRAINT を使用することはできません。
データ型と列の数を含む列の定義は、外部ファイルのデータと一致している必要があります。 不一致がある場合、実際のデータに対してクエリを実行するときに、ファイルの行が拒否されます。
LOCATION = 'folder_or_filepath'
Azure Data Lake または Azure Blob Storage にある実際のデータのフォルダーまたはファイルのパスとファイル名を指定します。 ルート フォルダーから、場所を開始します。 ルート フォルダーは、外部データ ソースで指定されたデータの場所です。
CREATE EXTERNAL TABLE では、パスとフォルダーが作成されません。
LOCATION としてフォルダーを指定すると、外部テーブルから選択する Azure SQL Managed Instance からのクエリでは、そのフォルダーからファイルを取得します。ただし、そのサブフォルダーはすべて対象外となります。
Azure SQL Managed Instance では、サブフォルダーまたは非表示フォルダー内のファイルを見つけることができません。 ファイル名が下線 (_) またはピリオド (.) で始まるファイルも返されません。
次に示すイメージの例では、LOCATION='/webdata/' である場合、クエリを実行すると mydata.txt からの行が返されます。
mydata2.txt はサブフォルダー内にあるために返されず、mydata3.txt は隠しフォルダー内にあるために返されず、_hidden.txt は隠しファイルであるために返されません。
DATA_SOURCE = external_data_source_name
外部データの場所が含まれている外部データ ソースの名前を指定します。 この場所は Azure Data Lake 内にあります。 外部データ ソースを作成するには、CREATE EXTERNAL DATA SOURCE を使用します。
FILE_FORMAT = external_file_format_name
外部データのファイル形式や圧縮方法を格納する外部ファイル形式オブジェクトの名前を指定します。 外部ファイル形式を作成するには、CREATE EXTERNAL FILE FORMAT を使用します。
アクセス許可
これらのユーザー アクセス許可が必要です。
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Note
MASTER KEY、DATABASE SCOPED CREDENTIAL、および EXTERNAL DATA SOURCE のみを作成するには、CONTROL DATABASE のアクセス許可が必要です
外部データ ソースを作成するログインには、Hadoop または Azure Blob Storage 内にある外部データ ソースに対する読み取りおよび書き込みのアクセス許可が必要であることに注意してください。
重要
ALTER ANY EXTERNAL DATA SOURCE 権限は、あらゆる外部データ ソース オブジェクトを作成し、変更する能力をプリンシパルに与えます。そのため、データベース上のすべてのデータベース スコープ資格情報にアクセスする能力も与えます。 この権限は特権として考える必要があります。したがって、システム内の信頼できるプリンシパルにのみ与える必要があります。
解説
SELECT FROM EXTERNAL TABLE などのアドホック クエリのシナリオの場合、外部データ ソースから取得された行が一時テーブルに格納されます。 クエリが完了すると、行が削除され、一時テーブルは削除されます。 SQL テーブルには、永続的なデータは格納されません。
これに対し、SELECT INTO FROM EXTERNAL TABLE などのインポートのシナリオでは、外部データ ソースから取得された行が永続的なデータとして SQL テーブルに格納されます。 外部のデータを取得する場合は、クエリの実行中に新しいテーブルが作成されます。
現在、Azure SQL Managed Instance によるデータの仮想化は読み取り専用となっています。
同じまたは別の外部データ ソースを参照している多数の外部テーブルを作成できます。
制限事項と制約事項
外部テーブル用のデータは Azure SQL Managed Instance の直接の管理下にないため、外部プロセスによっていつでも変更または削除することができます。 その結果、外部のテーブルに対するクエリの結果は確定的であることが保証されません。 同じクエリを外部のテーブルに対して実行するたびに、異なる結果が返される可能性があります。 同様に、外部データが移動または削除された場合、クエリが失敗する可能性があります。
それぞれが異なる外部データ ソースを参照する複数の外部テーブルを作成できます。
外部テーブルに対しては、これらのデータ定義言語 (DDL) ステートメントのみを使用できます。
- CREATE TABLE および DROP TABLE
- CREATE STATISTICS および DROP STATISTICS
- CREATE VIEW および DROP VIEW
サポートされていない構成要素と操作:
- 外部テーブルの列に対する DEFAULT 制約
- データ操作言語 (DML) の削除、挿入、更新の操作
テーブルの幅の制限事項
1 MB という行幅の制限は、テーブル定義による単一の有効な行の最大サイズに基づいています。 列スキーマの合計が 1 MB を超える場合、データ仮想化クエリは失敗します。
データ型の制限事項
Azure SQL Managed Instance では、次のデータ型を外部テーブルで使用することはできません。
geographygeometryhierarchyidimagetextnTextxml- 任意のユーザー定義型
ロック
SCHEMARESOLUTION オブジェクトに対する共有ロック。
例
A. 外部テーブルを使用して Azure SQL Managed Instance から外部データに対してクエリを実行する
その他の例については、外部データ ソースの作成に関するページまたは「Azure SQL Managed Instance によるデータ仮想化」を参照してください。
データベース マスター キーが存在しない場合は作成します。
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOSAS トークンを使用して、データベース スコープ資格情報を作成します。 マネージド ID も使用できます。
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GO資格情報を使用して外部データ ソースを作成します。
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOEXTERNAL FILE FORMAT と EXTERNAL TABLE を作成して、ローカル テーブルであるかのようにデータに対してクエリを実行します。
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
次の手順
外部テーブルと関連する概念の詳細については、次の記事を参照してください。