演習 - ニューラル ネットワークを構築してトレーニングする
このユニットでは、テキストのセンチメントを分析するニューラル ネットワークを、Keras を使用して構築およびトレーニングします。 ニューラル ネットワークをトレーニングするには、トレーニングするためのデータが必要です。 外部のデータセットをダウンロードするのではなく、Keras に含まれる「IMDB movie reviews sentiment classification」 (IMDB 映画レビュー センチメント分類) データセットを使用します。 IMDB データセットには、それぞれ肯定的 (1) または否定的 (0) とスコア付けされた 50,000 件の映画レビューが含まれています。 データセットは、トレーニング用の 25,000 レビューと、テスト用の 25,000 レビューに分けられています。 このニューラル ネットワークでは、これらのレビューで表されているセンチメントを基にして、提供されたテキストを分析してセンチメントのスコアを付けます。
IMDB データセットは、Keras に含まれているいくつかの便利なデータセットの 1 つです。 組み込みデータセットの完全な一覧については、https://keras.io/datasets/. をご覧ください
ノートブックの最初のセルに次のコードを入力するか貼り付けてから、[実行] ボタンをクリックして (または Shift + Enter キーを押して) 実行し、下に新しいセルを追加します。
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)このコードでは、Keras に含まれる IMDB データセットが読み込まれて、全 50,000 件のレビューに含まれる単語を、単語の相対的な出現頻度を示す整数にマッピングする辞書が作成されます。 各単語には、一意の整数が割り当てられます。 最も一般的な単語には値 1 が割り当てられ、その次に一般的な単語には値 2 が割り当てられる、という具合です。 また、
load_dataでは、映画のレビューを含むタプル (この例ではx_trainとx_test) と、それらのレビューを肯定的または否定的に分類する 1 と 0 の値を含むタプル (y_trainとy_test) のペアが返されます。Keras がバックエンドとして TensorFlow を使用していることを示す "Using TensorFlow backend" (TensorFlow バックエンドを使用中) というメッセージが表示されることを確認します。
IMDB データセットの読み込み
Keras のバックエンドとして Microsoft Cognitive Toolkit (CNTK) を使用したい場合は、ノートブックの先頭の数行のコードを追加することでできます。 例については、「CNTK and Keras in Azure Notebooks」(Azure Notebooks での CNTK と Keras) をご覧ください。
ところで、
load_data関数では何が読み込まれたのでしょうか。x_trainという名前の変数は 25,000 個のリストのリストであり、それぞれが映画のレビューを表します。 (x_testも 25,000 のレビューを表す 25,000 のリストです。x_trainはトレーニングに使用されるのに対し、x_testはテストに使用されます。) ただし、内部のリスト (映画のレビューを表すリスト) には、単語は含まれず、整数が含まれています。 Keras のドキュメントでどのように説明されているかを次に示します。
内部リストにテキストではなく数値が含まれている理由は、ニューラル ネットワークのトレーニングをテキストではなく数値で行うためです。 具体的には、テンソルを使用してトレーニングします。 この場合、各レビューは、レビューに含まれる単語を示す整数を含む 1 次元のテンソル (1 次元の配列と考えてください) です。 例として、空のセルに次の Python ステートメントを入力して実行し、トレーニング セット内の最初のレビューを表す整数を見てみます。
x_train[0]
IMDB トレーニング セット内の最初のレビューを構成する整数
リストの最初の値 1 は、どのような単語も表していません。 それは、レビューの開始をマークするものであり、データセット内のすべてのレビューについて同じです。 値 0 と 2 も予約されており、レビューの整数を辞書の対応する整数にマップするには、他の値から 3 を減算します。 2 番目の値 14 は、辞書での値 11 に対応する単語を参照します。3 番目の値は、辞書で値 19 を割り当てられている単語を表します。以下同様です。
辞書がどのようになっているのか知りたくありませんか。 ノートブックの新しいセルで次のステートメントを実行します。
imdb.get_word_index()辞書のエントリのサブセットしか示されていませんが、全部では、88,000 以上の単語とそれらに対応する整数が辞書に含まれます。 辞書は
load_dataを呼び出すたびに新しく生成されるため、実際に表示される出力は、スクリーンショットの出力と一致しないはずです。
単語を整数にマッピングしている辞書
これまで説明したように、データセット内の各レビューは、単語ではなく整数のコレクションとしてエンコードされます。 レビューを逆エンコードして、レビューを構成する元のテキストを見ることはできるでしょうか。 新しいセルに次のステートメントを入力して実行し、
x_trainの最初のレビューをテキスト形式で表示します。word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))出力で、">" はレビューの開始を示し、"?" はデータセット内の最も一般的な 10,000 語に含まれない単語を示します。 "不明の" 単語は、レビューを表す整数のリストでは 2 で表されます。
load_dataにパラメーターnum_wordsを渡していたことを思い出してください。 ここでそれが役に立ちます。 それは、辞書のサイズを小さくするのではなく、レビューのエンコードに使用される整数の範囲を制限します。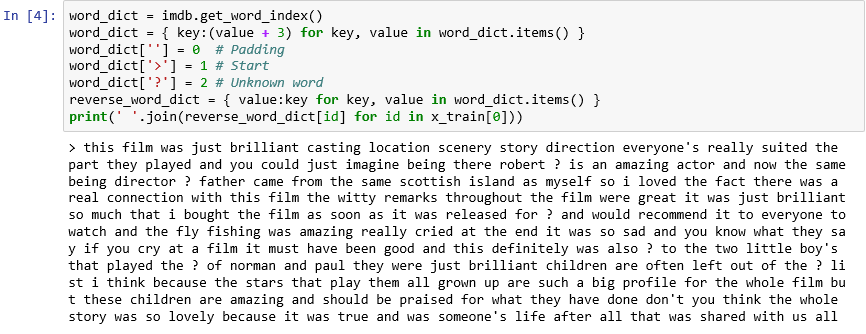
テキスト形式での最初のレビュー
文字が小文字に変換され、区切り文字が削除されているという意味で、レビューは "クリーン" です。 ただし、テキストのセンチメントを分析するためにニューラル ネットワークをトレーニングする準備はまだできていません。 テンソルのコレクションでニューラル ネットワークをトレーニングするときは、各テンソルが同じ長さになっている必要があります。 現時点では、
x_trainとx_testでレビューを表すリストは長さがまちまちです。さいわい、Keras には、リストのリストを入力として受け取り、必要に応じて切り捨てたり 0 を埋め込んだりして、指定された長さに内部リストを変換する関数が含まれます。 ノートブックに次のコードを入力して実行し、映画のレビューを表す
x_trainとx_testのすべてのリストの長さを強制的に整数 500 にします。from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)これでデータのトレーニングとテストを行う準備ができたので、モデルを構築する時間です。 ノートブックで次のコードを実行し、センチメント分析を実行するニューラル ネットワークを作成します。
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())出力が次のようになることを確認します。
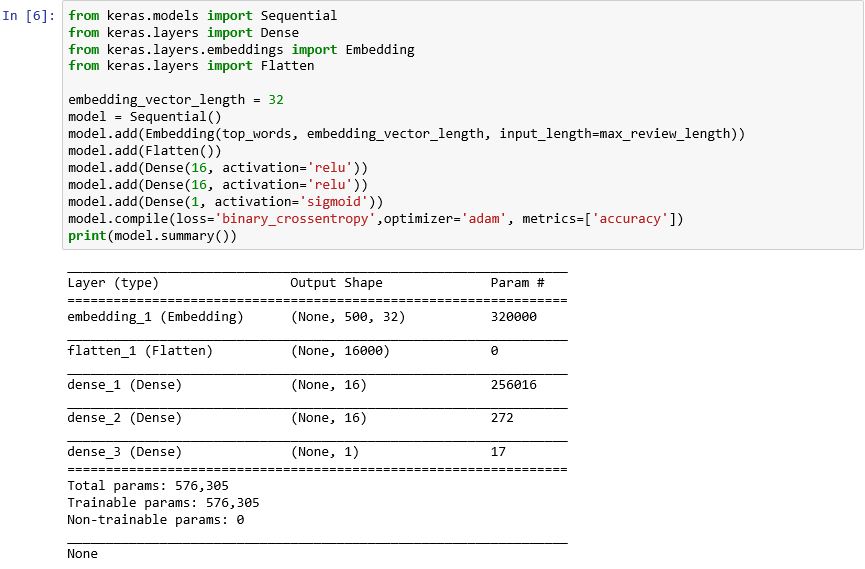
Keras でのニューラル ネットワークの作成
このコードは、Keras でのニューラル ネットワークの構築方法の重要な部分です。 最初に、"シーケンシャル" モデルを表す
Sequentialオブジェクトをインスタンス化します。このモデルは、レイヤーのエンド ツー エンドのスタックで構成されており、1 つのレイヤーからの出力が次のレイヤーへの入力になります。次のいくつかのステートメントでは、モデルにレイヤーを追加します。 1 つ目は埋め込みレイヤーであり、単語を処理するニューラル ネットワークには不可欠です。 埋め込みレイヤーでは、基本的に、整数の単語インデックスを含む多次元配列が、それより少ない次元を含む浮動小数点数の配列にマップされます。 また、似た意味を持つ単語を同じように扱うことができます。 単語の埋め込みの詳細はこのラボの範囲を超えますが、「Why You Need to Start Using Embedding Layers」 (最初に埋め込みレイヤーを使用する必要がある理由) で学習できます。 もっと学術的な説明の方がよい場合は、「Efficient Estimation of Word Representations in Vector Space」 (ベクター空間における単語表現の効率的な推定) をご覧ください。 埋め込みレイヤーを追加した後で Flatten を呼び出し、次のレイヤーに入力できるように出力を再形成します。
次にモデルに追加する 3 つのレイヤーは高密度レイヤーであり、完全結合レイヤーとも呼ばれます。 これらは、ニューラル ネットワークで一般的な従来のレイヤーです。 各レイヤーには n 個のノード (ニューロン) が含まれ、各ニューロンは前のレイヤー内のすべてのニューロンから入力を受け取ります。"完全結合" と呼ばれるのはこのためです。これらのレイヤーにより、ニューラル ネットワークは、出力を繰り返し推測し、結果を確認して、よりよい結果になるように接続を微調整することで、入力データから "学習" することができます。 このネットワークの最初の 2 つの高密度レイヤーには、それぞれ 16 個のニューロンが含まれています。 この数は任意に選択したものです。さまざまなサイズで実験し、モデルの精度を向上させることができます。 ネットワークの最終的な目標は 1 つの出力 (つまり、0.0 から 1.0 の範囲のセンチメント スコア) を予測することなので、最後の高密度レイヤーに含まれるニューロンは 1 つだけです。
結果のニューラル ネットワークは次の図のようになります。 このネットワークには、1 つの入力レイヤー、1 つの出力レイヤー、そして 2 つの非表示レイヤー (それぞれ 16 個のニューロンを含む高密度レイヤー) が含まれます。 ちなみに、今日のさらに高度なニューラル ネットワークの中には、レイヤー数が 100 を超えるものもあります。 たとえば、Microsoft Research の ResNet-152 は、人間より正確に写真内のオブジェクトを識別することがあります。 Keras で ResNet-152 を構築することもできますが、ゼロからトレーニングするには、GPU を搭載したコンピューターのクラスターが必要です。
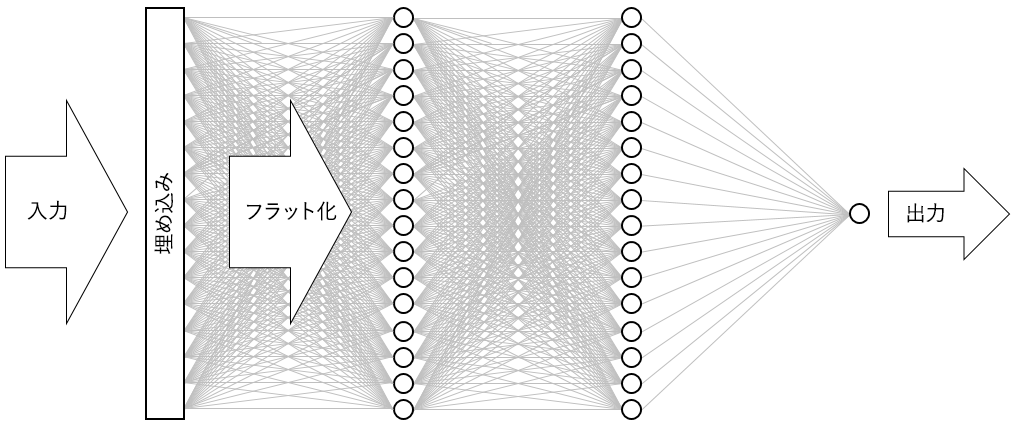
ニューラル ネットワークの図
使用するオプティマイザーや、各トレーニング ステップでモデルの精度を判定するために使用するメトリックなど、重要なパラメーターを指定して compile 関数を呼び出し、モデルを "コンパイル" します。
fit関数を呼び出すまでトレーニングは始まらないので、通常、compileの呼び出しはすぐに実行されます。次に、fit 関数を呼び出して、ニューラル ネットワークをトレーニングします。
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)トレーニングには約 6 分、つまりエポックごとに 1 分少々かかります。
epochs=5は、モデルに対して順方向と逆方向のパスを 5 回行うよう Keras に指示します。 各パスでは、トレーニング データによるモデルの学習が行われ、テスト データを使用して学習の成果が測定 ("検証") されます。 それから調整が行われた後、次のパスつまり "エポック" に戻ります。 これはfit関数からの出力に反映されて、各エポックに対するトレーニングの精度 (acc) と検証の精度 (val_acc) が示されます。batch_size=128は、ネットワークをトレーニングするときに 128 個のトレーニング サンプルを使用するよう Keras に指示します。 バッチ サイズを大きくするとトレーニング時間が短縮されます (すべてのトレーニング データを使用するために各エポックで必要なパスが減るため)、バッチ サイズを小さくすると精度が向上する場合があります。 このラボを終えたら、今度はモデルをバッチ サイズ 32 で再トレーニングし、モデルの精度に対する影響があるかどうかを確認してみてください。 約 2 倍のトレーニング時間がかかります。
"モデルのトレーニング"
このモデルは、数エポックだけでよい学習結果が得られる点が、普通のモデルと異なります。 トレーニング精度は急速に 100% に近づきますが、検証精度は 1 または 2 エポックまで上昇した後、横ばいになります。一般に、これらの精度が安定するために必要な期間より長くモデルをトレーニングすることは望ましくありません。 モデルの実行結果がテスト データに対してはよくても実際のデータではあまりよくなくなる、オーバーフィットのリスクがあります。 モデルがオーバーフィットしていることを示す兆候の 1 つは、トレーニング精度と検証精度の差異が広がることです。 オーバーフィットについてよくわかる概要については、「Overfitting in Machine Learning: What It Is and How to Prevent It」(機械学習でのオーバーフィット: その説明と回避方法) を参照してください。
トレーニングの進行に伴うトレーニング精度と検証精度の変化を目に見えるようにするには、ノートブックの新しいセルで次のステートメントを実行します。
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()精度のデータは、モデルの
fit関数によって返されるhistoryオブジェクトから得られます。 表示されたグラフを基にして、トレーニング エポックの数を増やす、減らす、同じままにする、のどれを推奨しますか。オーバーフィットを確認するもう 1 つの方法は、トレーニングの進行中にトレーニング損失と検証損失を比較することです。 このような最適化の問題では、損失関数が最小限に抑えられます。 詳細については、こちらを参照してください。 特定のエポックについて、トレーニング損失が検証損失より非常に大きい場合は、オーバーフィットの証拠です。 前のステップでは、
historyオブジェクトのhistoryプロパティのaccプロパティとval_accプロパティを使用して、トレーニング精度と検証精度をプロットしました。 同じプロパティに含まれるlossおよびval_lossという名前の値は、それぞれトレーニング損失と検証損失を表します。 これらの値をプロットして次のようなグラフを生成する場合、上記のコードをどのように変更しますか。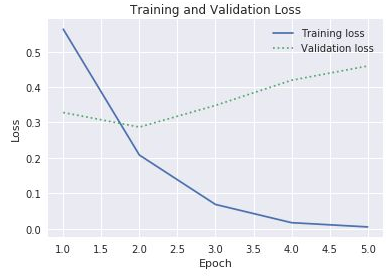
トレーニング損失と検証損失
3 番目のエポックでトレーニング損失と検証損失の間のギャップが大きくなり始めている場合、エポックの数を 10 または 20 に増やすことを提案されたらどうしますか。
最後に、モデルの
evaluateメソッドを呼び出すことにより、x_test(レビュー) とy_test(レビューが肯定的か否定的かを示す 0 と 1 の値 ("ラベル")) に基づいて、モデルがテキストで表現されたセンチメントを計測する精度を判定します。scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))モデルの計算された精度とは何ですか。
おそらく、85% から 90% の範囲の精度を実現したはずです。 モデルを最初から (事前トレーニング済みのニューラル ネットワークを使用するのではなく) 構築し、GPU を使用しないでトレーニング時間が短かったことを考えれば、そう考えるのは当然です。 別のニューラル ネットワーク アーキテクチャ (具体的には、Long Short-Term Memory (LSTM) レイヤーを利用する再帰型ニューラル ネットワーク (RNN)) を使用すると、95% 以上の精度を実現できます。 Keras ではそのようなネットワークを簡単に構築できますが、トレーニング時間は指数関数的に増加します。 構築したモデルでは、精度とトレーニング時間の間の合理的なバランスが取られています。 ただし、Keras で RNN を構築する方法について詳しく学習したい場合は、「Understanding LSTM and its Quick Implementation in Keras for Sentiment Analysis」 (センチメント分析のための Keras での LSTM の概要と迅速な実装) を参照してください。