演習 - アプリケーションの正常性モデルを構築する
Contoso Shoes には、このアーキテクチャ全体の問題を検出、診断、予測する方法が必要です。 ユーザー フローとシステム フローに適用される正常性状態によって測定可能な正常性モデルを構築したいと考えています。 目標は、障害を引き起こす前に、潜在的な障害ポイントを特定することです。
現在の状態と問題
ここまでで、正常性チェック API を追加し、アーキテクチャにマルチリージョンの機能を組み込みました。 ただし、ユーザー フローとシステム フローを含む複雑なトポロジに関する分析情報を取得する方法はありません。 SRE チームが問題をすばやく特定して解決できるように、このギャップを埋める必要があります。
最近のインシデントでは、チームは API コンポーネントがプラットフォームの依存関係に影響を与えるという問題の連鎖的な影響を確認できませんでした。 異常なコンポーネントをすぐに見つけることができなかったため、トラブルシューティングにかなりの時間が費やされました。 最終的に、この非効率性は、ダウンタイムの長期化につながり、会社に財務上の損失を引き起こしました。
仕様
アプリケーション コンポーネントとプラットフォームの依存関係を含むアーキテクチャ内のすべてのコンポーネント間の関係を示す正常性モデルを設計します。 ゲートウェイ、コンピューティング、データベース、ストレージ、キャッシュなど、要求フロー内に存在する項目を考慮します。 また、通常は要求フローの外部に存在するコンポーネントも含めます。 たとえば、Open Container Initiative (OCI) アーティファクト、シークレット ストア、構成サービスなどです。 診断データを送信するようにすべての Azure サービスを構成する必要があります。
さまざまなソースからデータを収集するための統合データ シンクをアーキテクチャに追加します。
集計された履歴ログとメトリックに基づいて全体的な正常性状態を定義します。 異常、低下、正常の 3 つの正常性状態のいずれかで状態を表します。
すべてのフローを表す階層内のすべてのコンポーネントの正常性状態を視覚化します。
推奨される方法
設計を開始するにあたり、次の手順に従うことをお勧めします。
重要
正常性モデリングは包括的な演習です。 このセクションのアプローチは、作業の開始に役立ていただくことを目的としています。 ミッション クリティカルな設計のすべての機能フローと非機能フローにモデルを適用することで、システムの全体像を把握できます。
1 – 正常性モデリングを開始する
この演習は理論上のものです。 アーキテクチャで使用されるコンポーネントの包括的な一覧が必要な、トップダウン設計アクティビティでの正常性モデリングになります。 この一覧には、すべてのアプリケーション コンポーネントと Azure サービスが含まれています。
ソリューションの階層ビューを示す依存関係グラフに、これらのコンポーネントを配置します。 最上位レイヤーには、エンド ユーザーから Web サイトへの要求を追跡する "ユーザー フロー" があり、アプリケーション API レベルでフローします。 最下位レイヤーには、Azure サービスからの “システム フロー” が含まれています。 また、Azure リソース間の依存関係をマップします。
グラフは以下のようになります。
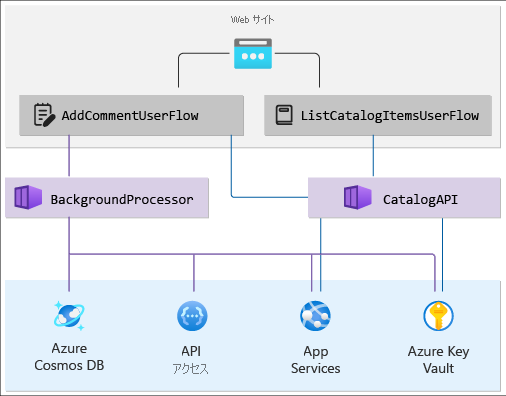
進行状況を確認する: 階層化されたアプリケーションの正常性
2 – 正常性スコアを定義する
コンポーネントごとにメトリックとメトリックのしきい値を収集し、コンポーネントの正常性を表す値を決定します (正常、低下、異常)。 この決定は、期待されるパフォーマンスと非機能のビジネス要件の影響を受けます。 メトリックを次のように分類します。
アプリケーション メトリック:アプリケーション コードからのデータ ポイント(例外数など)。
サービス メトリックス:Azure サービスからのデータ ポイント(使用中のデータベース トランザクション ユニット (DTU) など)。
ソリューション メトリック:要求のエンド ツー エンドの処理時間など、ソリューション レベルのデータ ポイント。
Azure App Service の例を次に示します。
| アプリケーション サービス | 正常性状態 |
|---|---|
| 応答時間 < 200 ミリ秒 HTTP サーバー エラー < 2 |
 |
| 応答時間 < 500 ミリ秒 HTTP サーバー エラー < 2 |
 |
| 応答時間 > 500 ミリ秒 HTTP サーバー エラー > 2 |
 |
3 – 全体的な正常性状態を定義する
ユーザーとシステム フローごとに、全体的な状態を定義します。 そのフローに参加する個々のコンポーネントの正常性状態を集計する必要があります。
システム フローが、アプリケーション コンポーネント、Azure App Service プラン、App Services で構成されるとします。
| API | App Service プラン | アプリケーション サービス | 正常性状態 |
|---|---|---|---|
| 最大待機時間 < 30 ミリ秒 | CPU % < 70% HTTP キューの長さ< 5 |
応答時間 < 200 ミリ秒 HTTP サーバー エラー < 2 |
|
| 最大待機時間 < 30 ミリ秒 | CPU % < 90% HTTP キューの長さ< 5 |
応答時間 < 500 ミリ秒 HTTP サーバー エラー < 2 |
|
| 最大待機時間 > 30 ミリ秒 | CPU % > 90% HTTP キューの長さ > 5 |
応答時間 > 500 ミリ秒 HTTP サーバー エラー > 2 |
|
ユーザー フローの正常性スコアは、マップされたすべてのコンポーネントで最も低いスコアで表されます。 システム フローの場合、ビジネスの重要度に基づいて適切な重みを適用します。 2 つのフローの間で、財務的に重要なユーザー フローまたは顧客向けのユーザー フローを優先する必要があります。
進行状況を確認する: 例 - 階層化された正常性モデル
4 - 監視データを収集する
リージョン スタンプの一部としてデプロイされたすべてのアプリケーションおよびプラットフォーム サービスのログとメトリックを収集する、統合データ シンクが各リージョンに必要です。 Azure Front Door や Cosmos DB など、グローバル リソースから出力されたメトリックを格納するために、別のシンクが必要になります。
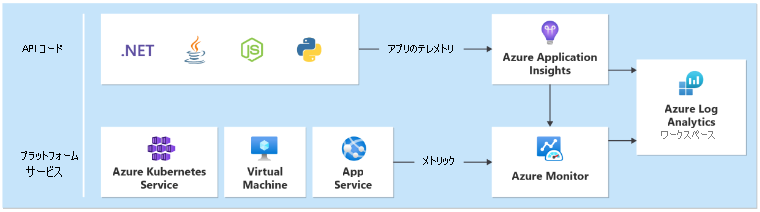
テクノロジの選択
- Azure Application Insights:すべてのアプリケーション テレメトリを収集するために使用されます。
- Azure Monitor ログ:Azure サービスの Application Insights とプラットフォーム メトリックによって送信されるデータを収集します。
- Azure Log Analytics:すべてのアプリケーションとインフラストラクチャ コンポーネントのログとメトリックを分析するための中心的なツールとして使用されます。
進行状況を確認する: 相関分析用の統合データ シンク
5 – 監視データのクエリを設定する
Kusto 照会言語 (KQL) は Log Analytics とよく統合されています。 Azure Monitor からデータを取得するための関数として、カスタム KQL クエリを実装します。
カスタム クエリをコード リポジトリに格納して、継続的インテグレーション/継続的デリバリー (CI/CD) パイプラインの一部として自動的にインポートおよび適用されるようにします。
6 – 正常性状態を視覚化する
交通信号機の表現を使用して、正常性スコアを含む依存関係グラフを視覚化できます。 Azure ダッシュボード、Monitor ブック、Grafana などのツールを使用します。 次に例を示します。
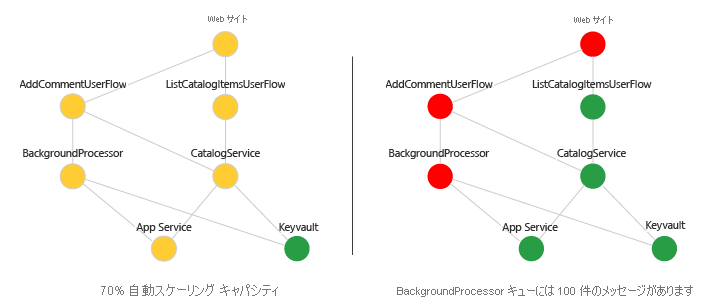
進行状況を確認する: 視覚化
7 – 状態の変更に関するアラートを設定する
問題に早急に対応するには、ダッシュボードでアラートを使用します。
コンポーネントの正常性状態が低下または異常に変わる場合、オペレーターに直ちに通知する必要があります。 このノードに対する変更は、基になるユーザー フローまたはリソースの異常な状態を示しているため、ルート ノードでアラートを設定します。
進行状況を確認する: アラート
作業を確認
監視と正常性のモデリングに関するこのデモをご覧ください。 あなたの設計では、以下の要素すべてが考慮されているでしょうか。
- 相関分析用の統合データ シンクはありますか。
- アプリケーション ログ、プラットフォーム メトリック、ソリューション データ ポイントを含めましたか。
- すべてのコンポーネントの正常性状態を視覚化するようにダッシュボードを設定しましたか。
- 障害を引き起こしたり、スケーリング、デプロイ、監視を妨げたりする可能性がある各サービス (またはそのサービスの一部) で障害ポイントを検討しましたか。
- 問題をより迅速にトリアージするのに役立つ主要なクエリをキャプチャするためにクエリ パックを検討しましたか。
- 正常性チェック API はこのモデルで役に立ちましたか。 正常性モデルに合わせてその API を変更する必要がありましたか。