正常性状態、メトリック、しきい値
正常性モデリングの重要な部分は、主要なビジネス要件のコンテキストで、アプリケーションの "正常"、"低下"、"異常" な状態を定量化することです。 "信号機" モデルは、正常性状態を表す一般的な方法です。
- 緑: "正常な状態"。 機能以外の重要な要件が完全に満たされ、リソースが最適に活用されます。
- 黄色: "低下状態"。 アプリケーションは動作していますが、ユーザー エクスペリエンスが影響を受ける可能性があります。 この状態を軽減するには、管理者の注意が必要です。
- 赤: 異常な状態。 アプリケーションが正常に動作していないか、期待どおりに実行されていません。 異常な状態になると、ユーザーが影響を受けます。
階層化された正常性モデルでは、まず上部のユーザー フローで状態を定義し、プラットフォーム リソースに下方移動します。 次の図は、階層化された正常性モデルの例を示しています。 この図は、基本コンポーネントの正常性状態の変化が、ユーザー フローとアプリケーションの全体的な正常性に、どのような連鎖的な影響を与える可能性があるかを示しています。
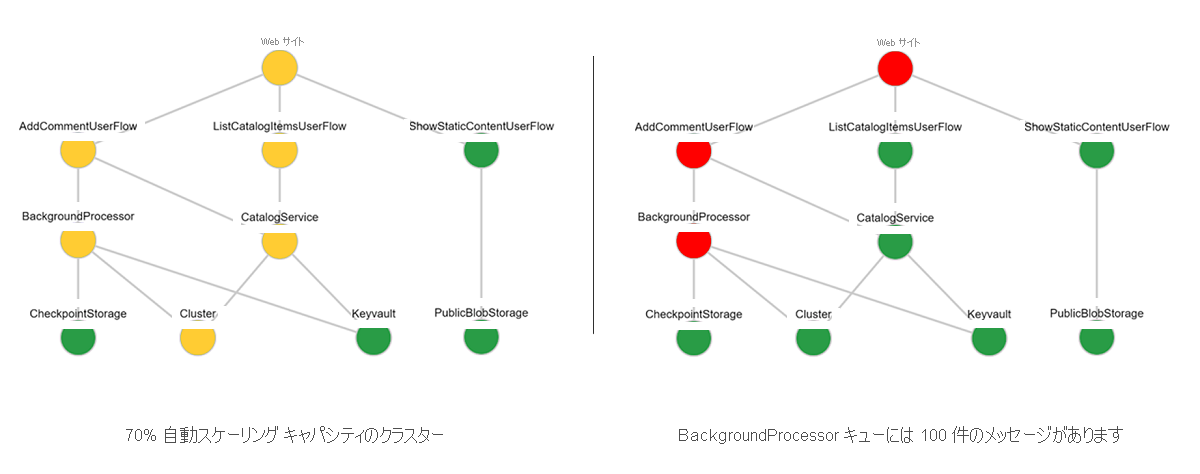
各レイヤーでは、アプリケーションの機能および機能以外の要件に基づいて正常および異常な状態を表すために、コンポーネントに対してメトリックとメトリックしきい値を使用する必要があります。 コンポーネントにおける正常性状態を定義する場合は、運用ワークロードでの個別の運用特性、安定した状態、および予期される動作に基づいて、それを行います。
たとえば、メトリックには、例外の数、応答時間、サービス メトリックを含めることができます。 アプリケーションのコンポーネントには、Azure リソースや、その他のコンポーネントとの依存関係を設定することができます。 それらの正常性状態を考慮する必要があります。
正常性スコアを計算するためのベスト プラクティスを次に示します。
- フローに参加しているコンポーネントの詳細な正常性スコアを集計することで、ユーザー フローの正常性状態を表します。 これには、アプリケーション コンポーネントと、マップされたすべての依存関係を含める必要があります。 機能以外の重要な要件を係数として考慮してください。
- ユーザー フローの正常性スコアは、マップされたすべてのコンポーネントで最も低いスコアで表します。 ユーザー フローの機能以外の要件に対する相対的な達成率を考慮します。
- 正常性スコアが運用の正常性を一貫して反映していることを保証します。 そうなっていない場合は、新しい情報を反映するようにモデルを調整して再デプロイします。
- コンポーネントの正常性の状態を反映するように正常性スコアのしきい値を定義します。
パフォーマンス テストは、それらの状態を確定する上で重要です。 個々のコンポーネントの詳細な正常性スコアは、主要なリソース レベルのメトリックとなります。 次の表は、リソース メトリックを使用して正常性状態を定義する方法の例を示しています。
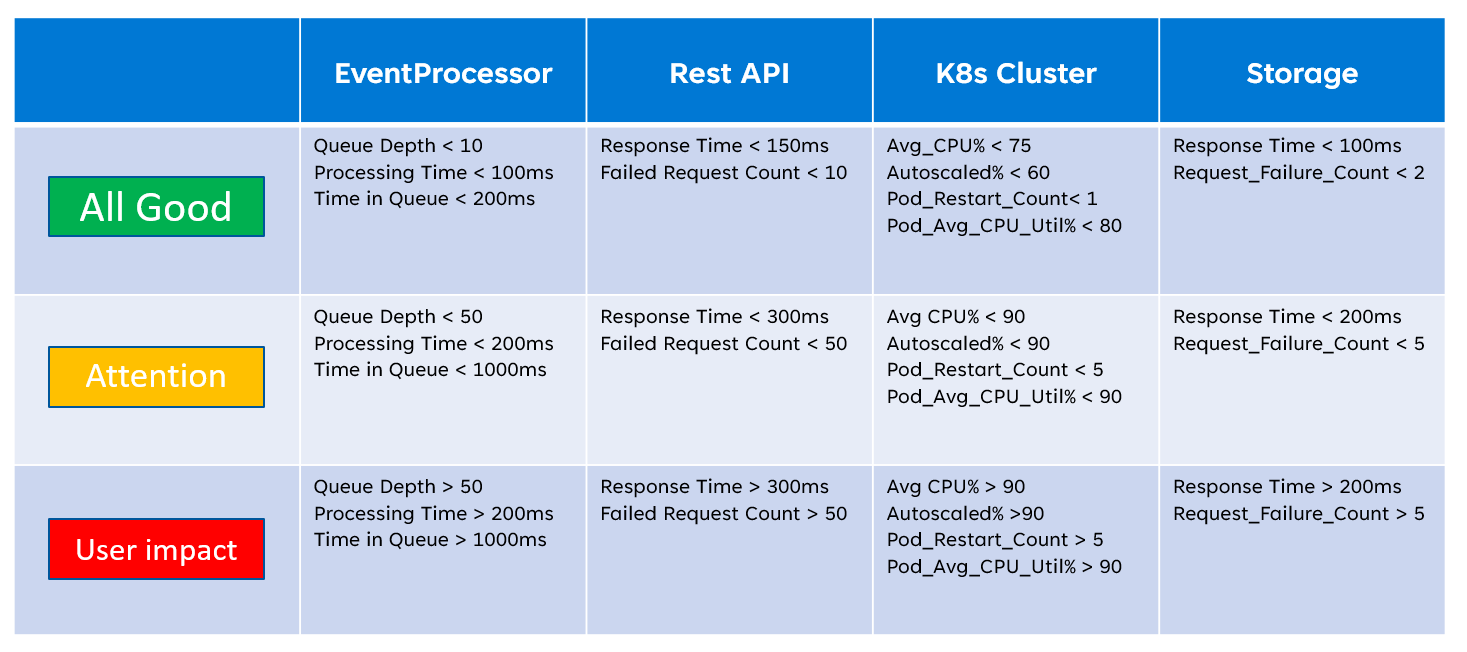
次の演習では、サンプル アプリケーションの正常性状態を定量化します。 この演習は、標準の運用ワークロードに期待される値を理解するのに役立ちます。