MLOps のアーキテクチャを調べる
データ科学者であるあなたは、最高の機械学習モデルをトレーニングしたいと考えています。 モデルを実装するため、あなたはそれをエンドポイントにデプロイし、アプリケーションと統合しようと考えます。
時間が経つと、モデルの再トレーニングが必要になる場合があります。 たとえば、トレーニング データが増えたら、モデルを再トレーニングできます。
一般に、機械学習モデルをトレーニングしたら、モデルをエンタープライズ規模に対応するようにしようと考えます。 モデルを準備して運用化するには、次のことを行います。
- モデル トレーニングを堅牢で再現可能なパイプラインに変換します。
- 開発環境でコードとモデルをテストします。
- 運用環境にモデルをデプロイします。
- エンド ツー エンド プロセスを自動化します。
開発環境と運用環境を設定する
DevOps と同じように、MLOps 内では、環境とはリソースの集まりを指します。 これらのリソースは、アプリケーションをデプロイしたり、機械学習プロジェクトによってモデルをデプロイしたりするために使用されます。
Note
このモジュールでは、環境を DevOps での解釈に基づいて使用しています。 Azure Machine Learning では、環境という用語が、スクリプトの実行に必要な Python パッケージのコレクションを記述するためにも使用されることに注意してください。 これら 2 つの環境の概念は互いに独立しています。
使用する環境の数は、組織によって異なります。 一般的に、開発 (dev) と運用 (prod) の少なくとも 2 つの環境があります。さらに、ステージングや運用前 (pre-prod) 環境など、中間の環境を追加することもできます。
一般的なアプローチは次のとおりです。
- 開発環境でモデル トレーニングを試します。
- 最適なモデルをステージング環境または運用前環境に移動し、そのモデルをデプロイしてテストします。
- 最後に、モデルを運用環境にリリースして、そのモデルをデプロイし、エンドユーザーがモデルを使用できるようにします。
Azure Machine Learning の環境を構成する
MLOps を実装し、大規模な機械学習モデルを扱う場合は、さまざまな段階に対して個別の環境を使用することをお勧めします。
開発、運用前、運用の各環境をチームで使用すると想定します。 チームの全員がすべての環境にアクセスする必要があるわけではありません。 データ サイエンティストは、非運用データを使用して開発環境内でのみ作業する可能性があります。一方、機械学習エンジニアは、運用データを使用して運用前環境と運用環境にモデルをデプロイする作業を行います。
環境を分離すれば、リソースへのアクセスの制御が容易になります。 その後、各環境を個別の Azure Machine Learning ワークスペースに関連付けることができます。

Azure 内で、ロールベースのアクセス制御 (RBAC) を使用して、作業に必要なリソースのサブセットへの適切なレベルのアクセス権を同僚に付与します。
または、Azure Machine Learning ワークスペースを 1 つだけ使用することもできます。 開発と運用に使用するワークスペースが 1 つの場合、Azure 占有領域が小さく、管理オーバーヘッドが少なくなります。 ただし、RBAC は開発と運用両方の環境に適用されます。これにより、ユーザーに付与されるリソースへのアクセス権が少なすぎるか、または多すぎることになる可能性があります。
ヒント
Azure Machine Learning のリソースを編成するためのベスト プラクティスの詳細について説明します。
MLOps のアーキテクチャを設計する
モデルを運用環境に導入するには、ソリューションをスケーリングし、他のチームと連携する必要があります。 あなたは、他のデータ科学者、データ エンジニア、インフラストラクチャ チームと共に、次のアプローチを使用することを決定します。
- データ エンジニアが管理する Azure Blob Storage にすべてのデータを格納します。
- インフラストラクチャ チームは、Azure Machine Learning ワークスペースなど、すべての必要な Azure リソースを作成します。
- データ科学者は、自分達が最もうまくできることであるモデルの開発とトレーニング (内部ループ) に注目します。
- 機械学習エンジニアは、トレーニングの済んだモデルをデプロイします (外部ループ)。
その結果、MLOps アーキテクチャには次の部分が含まれます。
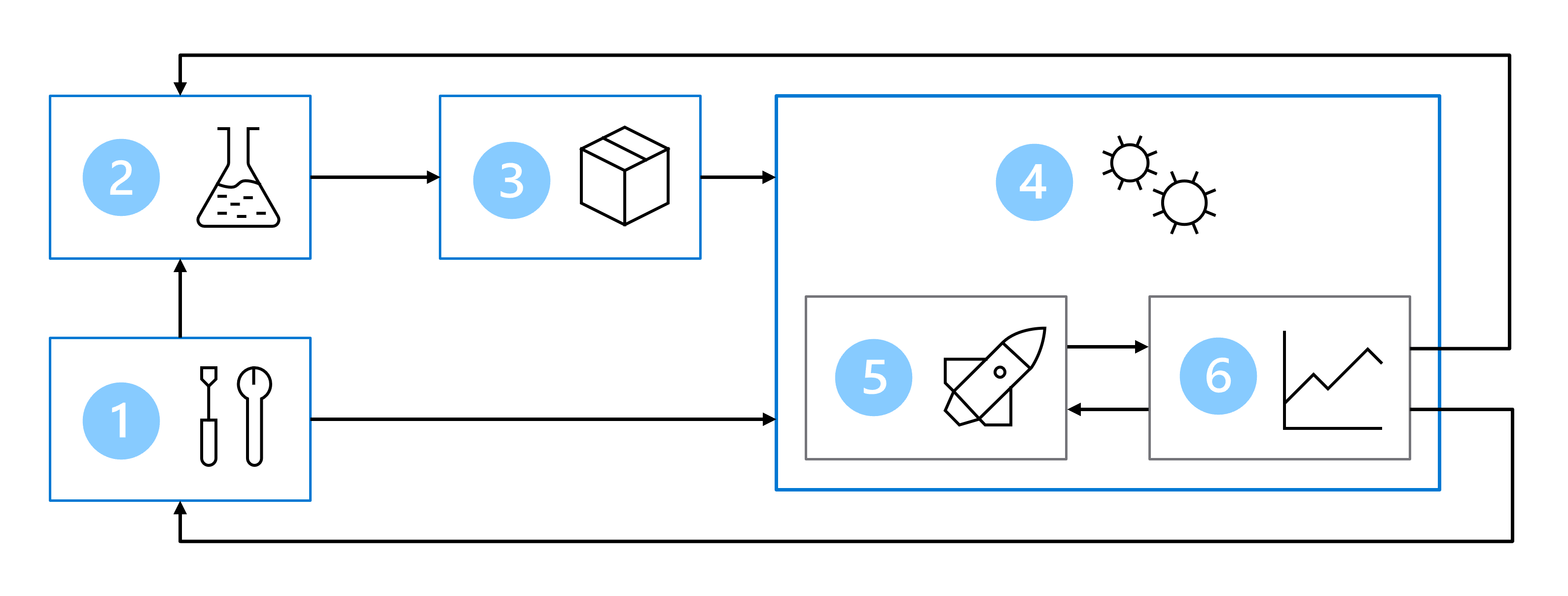
- セットアップ: ソリューションに必要なすべての Azure リソースを作成します。
- モデル開発 (内部ループ): モデルをトレーニングおよび評価するためのデータを探して処理します。
- 継続的インテグレーション: モデルをパッケージ化して登録します。
- モデル デプロイ (外部ループ): モデルをデプロイします。
- 継続的デプロイ: モデルをテストし、運用環境にレベル上げします。
- 監視: モデルとエンドポイントのパフォーマンスを監視します。
大規模なチームで作業している場合、あなたはデータ科学者として MLOps アーキテクチャのすべての部分を担当する必要はありません。 ただし、MLOps 用にモデルを準備するには、監視と再トレーニングに関する設計を行う方法について考える必要があります。