Azure Data Factory のしくみ
ここでは、Azure Data Factory のコンポーネントと相互接続されるシステム、およびそれらがどのように機能するのかについて学習します。 この知識は、自分の組織の要件を満たすために Azure Data Factory を最適に使用する方法を把握する上で役立つはずです。
Azure Data Factory は相互接続されたシステムのコレクションであり、これらを組み合わせることで、エンドツーエンドのデータ分析プラットフォームが提供されます。 このユニットでは、Azure Data Factory の以下の機能について学習します。
- 接続と収集
- 変換と強化
- 継続的インテグレーションおよびデリバリー (CI/CD) と公開
- 監視
また、Azure Data Factory の以下の主要コンポーネントについても学習します。
- パイプライン
- アクティビティ
- データセット
- リンクされたサービス
- データ フロー
- 統合ランタイム
Azure Data Factory の機能
Azure Data Factory はいくつかの機能で構成されており、これらを組み合わせることで、完全なデータ分析プラットフォームがデータ エンジニアに提供されます。
接続と収集
プロセスの最初の部分は、適切なデータ ソースから必要なデータを収集することです。 これらのソースは、オンプレミスのソースやクラウド内など、さまざまな場所に置かれている可能性があります。 データには、次のものがあります。
- 構造化
- 非構造化
- 半構造化
さらに、この異種データは、異なる速度と間隔で到着する可能性があります。 Azure Data Factory のコピー アクティビティを使用して、さまざまなソースのデータを、クラウド内の一元化された単一のデータ ストアに移動できます。 データをコピーしたら、他のシステムを使用してそれを変換して分析します。
コピー アクティビティでは、大まかに次の手順を行います。
ソース データ ストアからデータを読み取ります。
このデータに対して、次のタスクを実行します。
- シリアル化/逆シリアル化
- 圧縮/圧縮解除
- 列マッピング
Note
追加のタスクがある場合もあります。
コピー先のデータ ストア ("シンク" と呼ばれます) にデータを書き込みます。
次の図に、このプロセスをまとめます。

変換と強化
中央のクラウドベースの場所へのデータのコピーが成功したら、Azure Data Factory マッピング データ フローを使用することで、必要に応じてそのデータを処理して変換することができます。 "データ フロー" を使用すると、Spark 上で実行されるデータ変換グラフを作成できます。 しかしその場合でも、Spark クラスターや Spark プログラミングを理解している必要はありません。
ヒント
必須ではなくても、変換を手動でコーディングしたい場合があります。 その場合は、Azure Data Factory により、変換を実行する外部アクティビティがサポートされています。
CI/CD と公開
CI/CD のサポートにより、公開に先立って抽出、変換、読み込み (ETL) プロセスを段階的に開発して提供することができます。 Azure Data Factory から提供されるデータ パイプラインの CI/CD では、以下を使用します。
- Azure DevOps
- GitHub
注意
継続的インテグレーションは、コードベースに対して変更が行われたびに、できるだけ早く自動的にテストすることを意味します。 このテストの後に続くのが継続的デリバリーで、変更内容をステージングまたは実稼働システムにプッシュします。
Azure Data Factory による生データの調整が完了したら、ビジネス ユーザーが各自のビジネス インテリジェンス ツールからアクセスできる以下のような分析エンジンへとそのデータを読み込むことができます。
- Azure Synapse Analytics
- Azure SQL データベース
- Azure Cosmos DB
モニター
データ統合パイプラインの構築とデプロイが成功したら、スケジュールされたアクティビティとパイプラインを監視できることが重要です。 監視によって、成功率と失敗率を追跡できます。 Azure Data Factory では、以下のいずれかを使用するパイプライン監視のサポートが提供されています。
- Azure Monitor
- API
- PowerShell
- Azure Monitor ログ
- Azure portal の [正常性] パネル
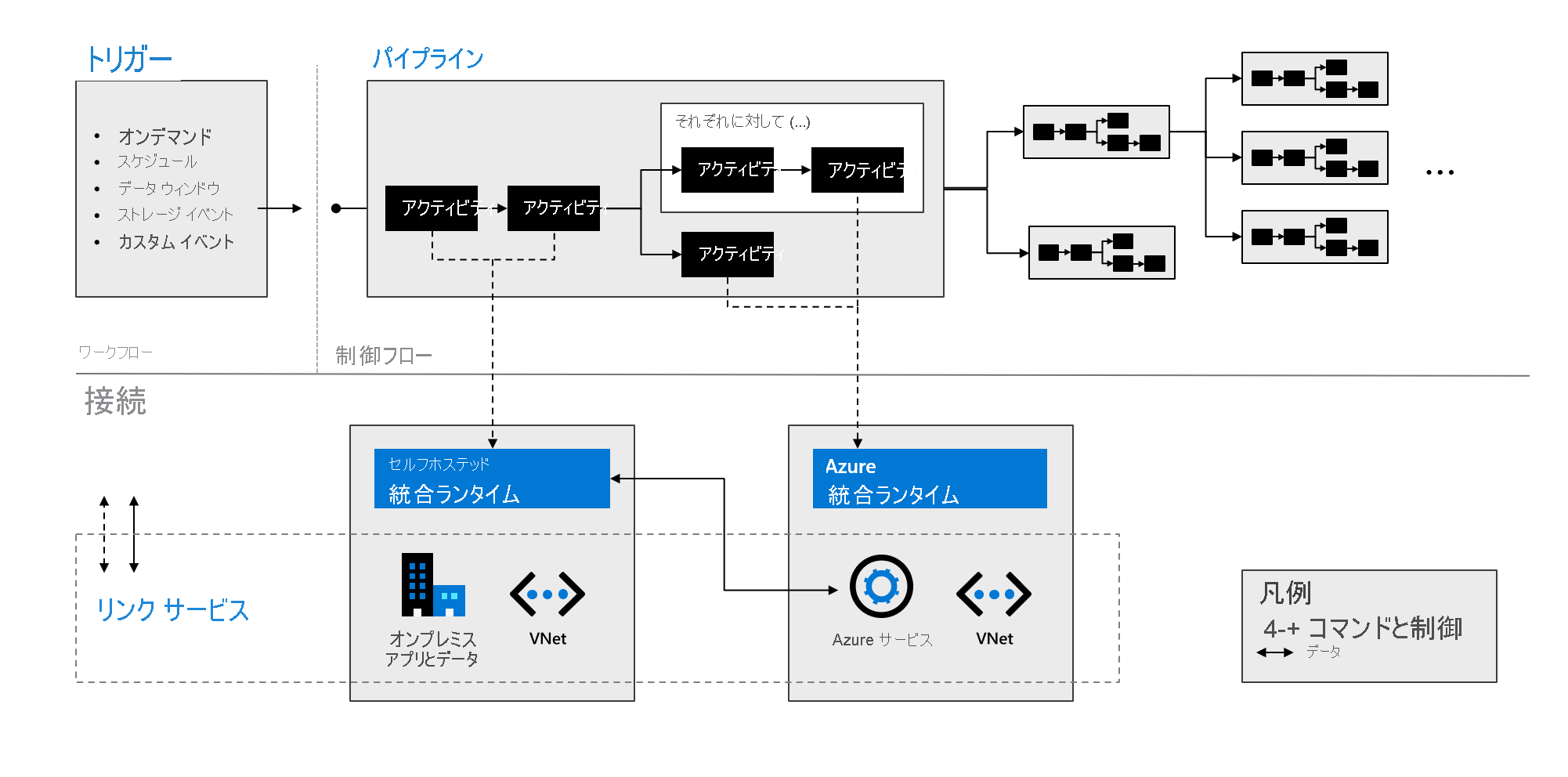
Azure Data Factory のコンポーネント
Azure Data Factory は、次の表で説明されるコンポーネントで構成されています。
| コンポーネント | 説明 |
|---|---|
| Pipelines | 特定の作業単位を実行するアクティビティの論理グループ。 これらのアクティビティは、共に 1 つのタスクを実行します。 パイプラインを使用する利点は、個々の項目としてではなく、セットとして扱うことで、アクティビティをより簡単に管理できることです。 |
| Activities | パイプライン内の単一の処理ステップ。 Azure Data Factory では、データ移動、データ変換、制御アクティビティの 3 種類のアクティビティがサポートされています。 |
| データセット | データ ストア内のデータ構造を表します。 データセットは、アクティビティ内で入力または出力として使用したいデータをポイント (または参照) します。 |
| リンクされたサービス | Azure Data Factory からデータ ソースなどの外部リソースに接続するために必要な必須接続情報を定義します。 Azure Data Factory は、データ ストアまたはコンピューティング リソースを表すという 2 つの目的のためにリンクされたサービスを使用します。 |
| データ フロー | データ エンジニアが、コードを記述することなく、データ変換ロジックを開発できます。 データ フローは、スケールアウトされた Apache Spark クラスターを使用する Azure Data Factory パイプライン内のアクティビティとして実行されます。 |
| 統合ランタイム | Azure Data Factory は、このコンピューティング インフラストラクチャを使用して、さまざまなネットワーク環境において、次のデータ統合機能を提供します: データ フロー、データ移動、アクティビティ ディスパッチ、SQL Server Integration Services (SSIS) パッケージの実行。 Azure Data Factory の統合ランタイムは、アクティビティとリンク サービスを橋渡しします。 |
次の図に示すように、これらのコンポーネントが連携して、完全なエンドツーエンドのプラットフォームがデータ エンジニアに提供されます。 Data Factory を使用して、以下を実行できます。
- 要求に応じてトリガーを設定し、必要に応じてデータ処理をスケジュールします。
- パイプラインをトリガーに関連付ける、または必要なときに手動で開始します。
- リンク サービス (オンプレミスのアプリやデータなど)、または Azure サービスに統合ランタイムを介して接続します。
- すべてのパイプラインがネイティブに実行されていることを、Azure Data Factory のユーザー エクスペリエンスまたは Azure Monitor を使用して監視します。