ストレージとデータベースを構成する
多くの場合、デプロイ プロセスの一部では、データベースまたはストレージ サービスに接続する必要があります。 この接続は、データベース スキーマを適用する場合や、参照データをデータベース テーブルに追加する場合、あるいは BLOB をアップロードする場合に必要になることがあります。 このユニットでは、データ サービスとストレージ サービスを扱うようにワークフローを拡張する方法について説明します。
ワークフローからデータベースを構成する
多くのデータベースには、データベースに格納されているデータの構造を表すスキーマがあります。 多くの場合は、デプロイ ワークフローからデータベースにスキーマを適用することをお勧めします。 このプラクティスは、ソリューションに必要なすべてのものを一緒にデプロイするのに役立ちます。 スキーマの適用時に問題があった場合にワークフローがエラーを示すため、問題を修正して再デプロイできるようにもなります。
Azure SQL を使用する場合は、データベース サーバーに接続し、SQL スクリプトを使用してコマンドを実行することによって、データベース スキーマを適用する必要があります。 これらのコマンドは、データ プレーン操作です。 ワークフローは、データベース サーバーに対して認証を行ってからスクリプトを実行する必要があります。 GitHub Actions には、Azure SQL データベース サーバーに接続してコマンドを実行するための azure/sql-action アクションが用意されています。
他のデータ サービスやストレージ サービスの中には、データ プレーン API を使用して構成する必要がないものもあります。 たとえば、Azure Cosmos DB を使用する場合は、コンテナーにデータを格納します。 Bicep ファイル内からコントロール プレーンを直接使用することによって、コンテナーを構成できます。 同様に、Azure Storage BLOB コンテナーのほとんどの部分を Bicep 内でデプロイして管理することもできます。 次の演習では、Bicep から BLOB コンテナーを作成する方法の例を紹介します。
データの追加
多くのソリューションでは、機能するためにはデータベースまたはストレージ アカウントに参照データを追加する必要があります。 ワークフローは、このようなデータを追加するのに適した場所になります。 つまり、ワークフロー実行後は、環境が完全に構成されていて、使用できる状態であるということです。
また、特に非運用環境の場合は、データベースにサンプル データがあると便利です。 サンプル データを使用すると、そのような環境を使用するテスト担当者などのユーザーがソリューションをすぐにテストできるようになります。 このデータには、サンプル製品が含まれることもあれば、偽のユーザー アカウントなどが含まれることもあります。 一般に、このようなデータを運用環境に追加する必要はありません。
データの追加に使用する方法は、使用するサービスによって異なります。 次に例を示します。
- Azure SQL データベースにデータを追加するには、スキーマの構成と同様のスクリプトを実行する必要があります。
- Azure Cosmos DB にデータを挿入する必要がある場合は、そのデータ プレーン API にアクセスする必要があります。そのためには、カスタム スクリプト コードの記述が必要になることがあります。
- Azure Storage BLOB コンテナーに BLOB をアップロードする場合は、AzCopy コマンドライン アプリケーション、Azure PowerShell、Azure CLI など、ワークフロー スクリプトからさまざまなツールを使用できます。 これらの各ツールは、ユーザーに代わって Azure Storage に対して認証を行うことと、データ プレーン API に接続して BLOB をアップロードすることに対応しています。
べき等
デプロイ ワークフローと IaC (コードとしてのインフラストラクチャ) の特性の 1 つに、副作用を一切伴わずに繰り返し再デプロイできるということがあります。 たとえば、既にデプロイした Bicep ファイルを再デプロイすると、送信したファイルとご利用の Azure リソースの既存の状態が Azure Resource Manager によって比較されます。 変更がない場合は、Resource Manager によって何も行われません。 ある操作を繰り返し再実行できることをべき等と呼びます。 スクリプトなどのワークフロー ステップには、べき等性を確保することをお勧めします。
データ サービスは状態を維持するので、データ サービスと対話する場合はべき等が特に重要です。 ワークフローからデータベース テーブルにサンプル ユーザーを挿入するとします。 注意しないと、ワークフローを実行するたびに新しいサンプル ユーザーが作成されます。 この結果は、おそらくあなたが意図しているものではありません。
Azure SQL データベースにスキーマを適用する場合は、データ パッケージ (DACPAC ファイルとも呼ばれる) を使用してスキーマをデプロイできます。 ワークフローはソース コードから DACPAC ファイルをビルドし、アプリケーションと同様にワークフロー成果物を作成します。 次に、ワークフローのデプロイ ジョブが DACPAC ファイルをデータベースに発行します。

DACPAC ファイルはデプロイされると、データベースのターゲット状態をパッケージで定義された状態と比較することによって、べき等で動作します。 多くの場合、これは、べき等の原則に従ったスクリプトを記述する必要がないことを意味します。べき等はツールによって自動的に処理されるからです。 Azure Cosmos DB および Azure Storage 用のツールの一部も正しく動作します。
ただし、自動的にはべき等で動作しない Azure SQL データベースや別のストレージ サービスでサンプル データを作成するときは、まだ存在しない場合にのみデータを作成するようにスクリプトを記述することをお勧めします。
また、たとえば古いバージョンのデプロイ ワークフローを再実行してデプロイをロールバックしなければならない場合があるかどうかを検討することも重要です。 データのロールバックは複雑になる可能性があるため、ロールバックを許可する必要がある場合は、ソリューションがどのように動作するかを慎重に検討してください。
ネットワークのセキュリティ
場合によっては、一部の Azure リソースにネットワーク制限を適用することもあります。 これらの制限で、リソースのデータ プレーンに対して行われる要求に関するルールを適用できます。次に例を示します。
- このデータベース サーバーには、指定された IP アドレスのリストからのみアクセスできる。
- このストレージ アカウントには、特定の仮想ネットワーク内にデプロイされているリソースからのみアクセスできる。
ネットワーク制限は、インターネット上の何もデータベース サーバーに接続する必要がないように思われるので、データベースでよく使用されます。
一方、ネットワーク制限のためにデプロイ ワークフローがリソースのデータ プレーンを操作するのが困難になる場合もあります。 GitHub でホストされたランナーを使用するときに、その IP アドレスを事前に知ることは簡単ではなく、大規模な IP アドレスプールから割り当てられる可能性もあります。 また、GitHub でホストされたランナーを独自の仮想ネットワークに接続することはできません。
データ プレーン操作の実行に役立ついくつかのアクションで、これらの問題を回避できます。 たとえば、azure/sql-action アクションの場合は次のようになります。
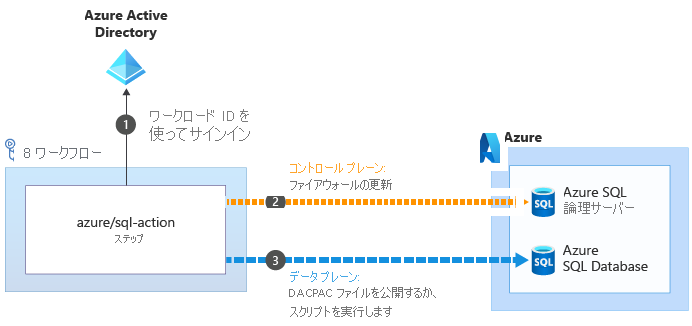
azure/sql-action アクションを使用して Azure SQL 論理サーバーまたはデータベースを操作する場合、Azure SQL 論理サーバーのコントロール プレーンに接続するためにワークロード ID が使用されます。 ファイアウォールが更新されて、ランナーがその IP アドレスからサーバーにアクセスできるようになります
が使用されます。 ファイアウォールが更新されて、ランナーがその IP アドレスからサーバーにアクセスできるようになります  。 その後、実行のための DACPAC ファイルまたはスクリプトを正常に送信できます
。 その後、実行のための DACPAC ファイルまたはスクリプトを正常に送信できます  。 アクションが完了すると、タスクによってファイアウォール ルールが自動的に削除されます。
。 アクションが完了すると、タスクによってファイアウォール ルールが自動的に削除されます。
他の状況では、このような例外を作成することはできません。 このような状況では、仮想マシンなどの管理対象のコンピューティング リソースで実行される "自己ホスト型ランナー" の使用を検討してください。 そうすることで、必要に応じてこのランナーを構成できます。 既知の IP アドレスを使用することも、ご自身の仮想ネットワークに接続することもできます。 このモジュールでは自己ホスト型ランナーについて説明しませんが、モジュールの [概要] ページに詳細情報へのリンクがあります。
デプロイ ワークフロー
次の演習では、デプロイ ワークフローを更新します。Web サイトのデータベース コンポーネントをビルドし、データベースをデプロイして、シード データを追加するための新しいジョブを追加しましょう。
