Spark Structured Streaming について説明する
Spark Structured Streaming は、メモリ内処理のための一般的なプラットフォームです。 バッチとストリーミングの統合パラダイムを採用しています。 バッチについて習得および使用したものすべてをストリーミングにも使用できるため、データのバッチ処理からデータのストリーミング処理への拡張は簡単です。 Spark Streaming とは、単に Apache Spark 上で実行されるエンジンのことです。

Structured Streaming は、入力データに選択、プロジェクション、集計、ウィンドウ化、ストリーミング データフレームの参照データフレームとの結合などの操作を適用するための、実行時間の長いクエリを作成します。 次に、その結果をファイル ストレージ (Azure Storage BLOB や Data Lake Storage) に、またはカスタム コード (SQL Database や Power BI など) を使用して任意のデータストアに出力します。 Structured Streaming ではまた、ローカルでのデバッグのためにコンソールに出力したり、HDInsight でのデバッグのために生成されたデータを表示できるようにインメモリ テーブルに出力したりする機能も提供されます。
テーブルとしてのストリーム
Spark Structured Streaming は、データのストリームを深さが無限のテーブルとして表します。つまり、このテーブルは新しいデータが到着するたびに増大し続けます。 この入力テーブルは実行時間の長いクエリによって継続的に処理され、その結果が出力テーブルに送信されます。

Structured Streaming では、データがシステムに到着すると、直ちに入力テーブルに取り込まれます。 この入力テーブルに対して操作を実行するクエリを (データフレームおよびデータセット API を使用して) 記述します。 このクエリの出力により、別のテーブルである結果テーブルが生成されます。 結果テーブルにはクエリの結果が含まれており、そこから、データをリレーショナル データベースなどの外部のデータストアに取り出します。 入力テーブルのデータが処理されるタイミングは、トリガー間隔によって制御されます。 既定では、トリガー間隔は 0 であるため、Structured Streaming はデータが到着するとすぐに処理しようとします。 これは、実際には、Structured Streaming が前のクエリの処理を完了するとすぐに、新しく受信したデータに対する別の処理を開始することを示します。 ストリーミング データが時間ベースのバッチで処理されるように、トリガーを一定の間隔で実行されるように構成することができます。
結果テーブル内のデータに、最後にクエリが処理されてからの新しいデータのみを含めることも (追加モード)、新しいデータが到着するたびにテーブルを更新して、そのテーブルにストリーミング クエリが開始されてからのすべての出力データが含まれるようにすることもできます (完全モード)。
追加モード
追加モードでは、最後のクエリ実行の後に結果テーブルに追加された行のみが結果テーブル内に存在し、外部ストレージに書き込まれます。 たとえば、最も単純なクエリは、すべてのデータを入力テーブルから結果テーブルにそのままコピーするだけです。 トリガー間隔が経過するたびに、新しいデータが処理され、その新しいデータを表す行が結果テーブルに現れます。
株価データを処理しているシナリオを考えてみます。 最初のトリガーで、株価が 95 ドルの MSFT の株式に関して時間 00:01 に 1 つのイベントが処理されたとします。 クエリの最初のトリガーでは、時間 00:01 の行のみが結果テーブルに現れます。 別のイベントが到着した時間 00:02 には、新しい行は時間 00:02 の行だけであるため、結果テーブルにはその 1 行のみが含まれます。
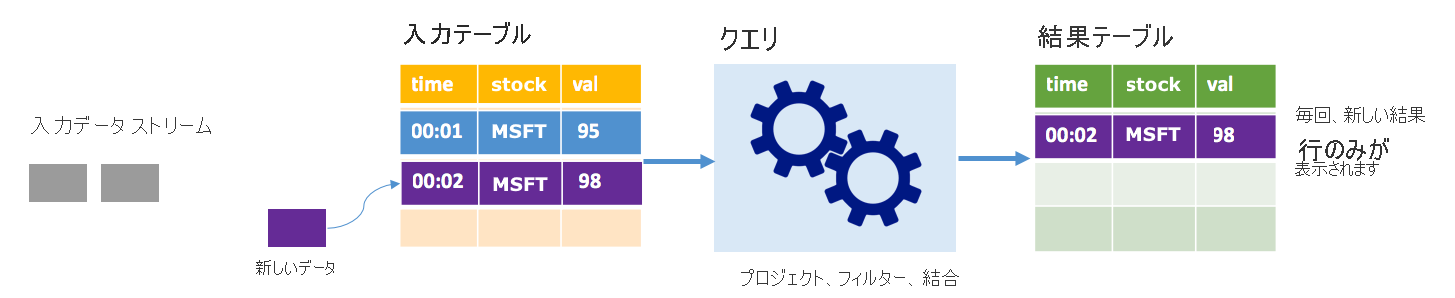
追加モードを使用しているとき、クエリはプロジェクションを適用している (対象の列を選択している) か、フィルター処理している (特定の条件に一致する行のみを選択している) か、結合している (静的ルックアップ テーブルからのデータを含むデータを増やしている) かのいずれかです。 追加モードにより、関連する新しいデータ ポイントのみを外部ストレージにプッシュすることが容易になります。
完全モード
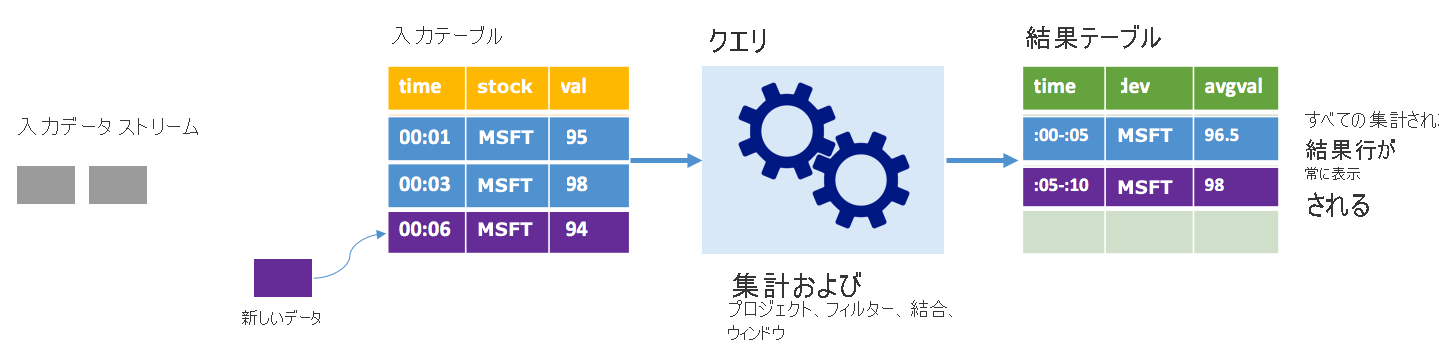
同じシナリオを考えますが、今回は完全モードを使用します。 完全モードでは、テーブルに最新のトリガー実行だけでなく、すべての実行のデータが含まれるように、トリガーごとに出力テーブル全体が更新されます。 完全モードを使用すると、データを入力テーブルから結果テーブルにそのままコピーすることもできます。 トリガーが実行されるたびに、新しい結果行が以前のすべての行と共に現れます。 出力結果テーブルには、クエリの開始以降に収集されたすべてのデータが格納され、最終的にメモリが不足します。 完全モードは受信データを何らかの方法で集計する集計クエリで使用されることを目的にしているため、トリガーが実行されるたびに、結果テーブルは新しい集計値で更新されます。
これまでに既に 5 秒分のデータが処理されており、これから 6 秒目のデータが処理されるものとします。 入力テーブルには、時間 00:01 と時間 00:03 のイベントが含まれています。 このクエリ例の目標は、5 秒ごとに株式の平均価格を示すことです。 このクエリの実装では、各 5 秒間ウィンドウに含まれるすべての値を取得する集計を適用し、株価を平均して、その間隔の平均株価の行を生成します。 最初の 5 秒間ウィンドウの最後には、(00:01, 1, 95) と (00:03, 1, 98) の 2 組が存在します。 このため、ウィンドウ 00:00-00:05 では、集計によって平均株価が $96.50 である組が生成されます。 次の 5 秒間では、データ ポイントが時間 00:06 に 1 つしか存在しないため、結果として得られる平均株価は 98 ドルです。 時間 00:10 には、完全モードを使用しており、このクエリが新しい行だけでなく、集計されたすべての行を出力するため、結果テーブルには 00:00-00:05 と 00:05-00:10 の両方のウィンドウの行が含まれます。 そのため、結果テーブルは、新しいウィンドウが追加されるたびに増大し続けます。
完全モードを使用するすべてのクエリでテーブルが制限なく増大するわけではありません。 前の例で、株価をウィンドウごとに平均するのではなく、代わりに株式で平均したものと考えてみます。 結果テーブルには、各デバイスから受信されたすべてのデータ ポイントにわたるその株式の平均株価を含む固定された行数 (株式ごとに 1 行) が含まれます。 新しい株価を受け取ると、テーブルの平均が常に最新になるように結果テーブルが更新されます。
Spark Structured Streaming の利点
金融部門では、取引のタイミングが非常に重要です。 たとえば、株式取引では、株式市場で株式取引が発生した時刻、取引情報を受信した時刻、またはデータがすべて読み取られた時刻の差が重要になります。 金融機関の場合は、この重要なデータとそれに関連するタイミングにかかっています。
イベント時間、遅延データ、ウォーターマーク
Spark Structured Streaming では、イベント時間と、イベントがシステムによって処理された時間の差を認識しています。 各イベントはテーブル内の行であり、イベント時間はその行内の列の値です。 これにより、ウィンドウベースの集計 (1 分ごとのイベント数など) が、イベント時間の列上のグループ化と集計になります。各時間ウィンドウはグループであり、各行は複数のウィンドウまたはグループに属することができます。 したがって、そのようなイベント時間のウィンドウに基づいた集計のクエリは、静的なデータセットとデータ ストリームの両方で一貫して定義することができ、データ エンジニアの負担が大幅に軽減されます。
さらに、このモデルでは、イベント時間に基づいて予想よりも遅く到着したデータを自然に処理します。 Spark では、遅延データがある場合に古い集計を更新することだけでなく、中間状態のデータのサイズを制限するために古い集計をクリーンアップすることも完全に制御できます。 また、Spark 2.1 以降では、Spark でウォーターマークがサポートされているため、ユーザーは遅延データのしきい値を指定でき、エンジンではそれに応じて古い状態をクリーンアップできます。
最新のデータまたはすべてのデータをアップロードできる柔軟性
前のユニットで説明したように、Spark Structured Streaming を使用する場合は、追加モードと完全モードのどちらを使用するかを選択できるため、結果テーブルには最新のデータのみ、またはすべてのデータが含まれます。
マイクロ バッチから連続処理への移行をサポート
Spark クエリのトリガーの種類を変更すると、フレームワークに他の変更を加えることなく、マイクロ バッチの処理から連続処理に移行できます。 Spark でサポートされているさまざまな種類のトリガーを以下に示します。
- 未指定。これが既定値です。 トリガーが明示的に設定されていない場合、クエリはマイクロ バッチで実行され、連続的に処理されます。
- 一定間隔のマイクロ バッチ。 クエリは、ユーザーが設定した定期的な間隔で開始されます。 新しいデータが受信されない場合、マイクロ バッチ プロセスは実行されません。
- 1 回限りのマイクロ バッチ。 このクエリは、1 つのマイクロ バッチを実行した後、停止します。 これは、前回のマイクロ バッチ以降のすべてのデータを処理する場合に役立ち、連続的に実行する必要がないジョブのコストを削減できます。
- 固定チェックポイントの間隔で連続。 このクエリは、新しい低遅延の連続処理モードで実行されます。これにより、少なくとも 1 回のフォールト トレランスの保証を備えたエンドツーエンドでの低遅延 (1 ミリ秒以下) を実現できます。 これは既定値に似ていますが、既定値では、1 回限りの保証は行われますが、最大で 100 ミリ秒以下の待ち時間しか実現できません。
バッチ ジョブとストリーミング ジョブの組み合わせ
バッチ ジョブからストリーミング ジョブへの移行を簡略化するだけでなく、バッチ ジョブとストリーミング ジョブを組み合わせることもできます。 これは、リアルタイム情報を処理しながら、長期の履歴データを使用して今後の動向を予測する場合に特に役立ちます。 株式の場合、年間または四半期ごとの収益発表をベースに行われる変更を予測するために、現在の株価に加えて過去 5 年間の株価の確認も必要になることがあります。
イベント時間ウィンドウ
1 日ウィンドウまたは 1 分間ウィンドウ (ご自身で決めた任意の間隔) の範囲内でウィンドウ内のデータ (高額の株価や低額の株価など) をキャプチャすることが必要な場合があり、Spark Structured Streaming でもそれがサポートされています。 重複するウィンドウもサポートされています。
障害回復のためのチェックポイント処理
障害または意図的なシャットダウンが発生した場合、前のクエリの以前の進行状況と状態を復旧して、中断した箇所から続行することができます。 これは、チェックポイント処理と先書きログを使用して行われます。 チェックポイントの場所を使用してクエリを構成できます。そのクエリでは、進行状況に関するすべての情報 (各トリガーで処理されるオフセットの範囲など) と実行中の集計をチェックポイントの場所に保存します。 このチェックポイントの場所は、HDFS と互換性のあるファイル システム内のパスである必要があり、クエリの開始時に DataStreamWriter 内にオプションとして設定できます。