データをセカンダリ クラスターにレプリケートする
Kafka は多くの場合、ディザスター リカバリー、高可用性、オンプレミスからハイブリッド クラウドへの移行のシナリオに対応した複数の環境にデプロイされます。 こうしたシナリオでは、Apache Kafka のミラーリング機能を使用して、1 つの Kafka インスタンスから別のインスタンスにデータをレプリケートする必要があります。 ミラーリングは、継続的なプロセスとして実行することも、クラスター間でデータを移行する方法として断続的に使用することもできます。
ミラーリングは、フォールト トレランスを実現するための手段として考慮するべきではありません。 トピック内の項目へのオフセットは、プライマリ クラスターとセカンダリ クラスターによって異なるため、クライアントはこれら 2 つを入れ替えて使用することはできません。
ミラーリングのしくみ
ミラーリングでは、Apache Kafka に含まれるツール MirrorMaker によってプライマリ クラスターのトピックからレコードが使用され、セカンダリ クラスターにローカル コピーが作成されます。 MirrorMaker では、プライマリ クラスターから読み取りを行う 1 つ以上のコンシューマーと、ローカルのセカンダリ クラスターへの書き込みを行う 1 つのプロデューサーを使用します。
ディザスター リカバリーに最も役立つミラーリングの設定では、異なる Azure リージョンの Kafka クラスターを使用します。 これを実現するには、クラスターが存在する仮想ネットワークをピアリングします。
次の図は、ミラーリング プロセスとクラスター間で通信がどのように流れるかを示しています。
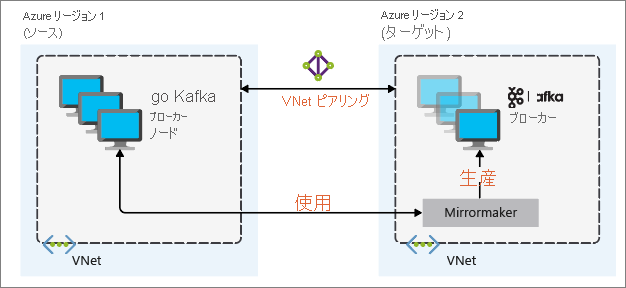
プライマリ クラスターとセカンダリ クラスターでは、ノードとパーティションの数、およびトピック内のオフセットが異なります。 ミラーリングではパーティション分割に使用するキー値が保持されるため、レコードの順序はキー単位で保存されます。
ネットワーク境界を超えたミラーリング
異なるネットワークの Kafka クラスター間でミラーリングの必要がある場合には、次の追加の考慮事項があります。
- ゲートウェイ:ネットワークは、TCP/IP レベルで通信できる必要があります。
- サーバー アドレス指定:IP アドレスまたは完全修飾ドメイン名を使用して、クラスター ノードのアドレスを指定することができます。
- IP アドレス:IP アドレスのアドバタイジングを使用するように Kafka クラスターを構成する場合は、ブローカー ノードと Zookeeper ノードの IP アドレスを使用してミラーリングのセットアップを続行することができます。
- ドメイン名:IP アドレスのアドバタイジングを行うように Kafka クラスターを構成しない場合、クラスターは完全修飾ドメイン名 (FQDN) を使用して相互に接続できる必要があります。 そのためには、要求を他のネットワークに転送するように構成された各ネットワークに、ドメイン ネーム システム (DNS) サーバーが必要です。 Azure Virtual Network を作成するときに、ネットワークで自動的に提供される DNS を使用せず、カスタムの DNS サーバーおよびサーバーの IP アドレスを指定する必要があります。 Virtual Network の作成が完了したら、その IP アドレスを使用する Azure Virtual Machine を作成し、そこに DNS ソフトウェアをインストールして構成を行います。
警告
カスタム DNS サーバーの作成と構成は、HDInsight を Virtual Network にインストールする前に行うようにします。 HDInsight が Virtual Network 用に構成された DNS サーバーを使用するために必要な、追加の構成はありません。