潜在的な危害を軽減する
ベースラインと、ソリューションで生成される有害な出力を測定する方法を決定した後、潜在的な危害を軽減するための手順を実行し、必要に応じて、変更されたシステムを再テストし、有害レベルをベースラインと比較することができます。
生成 AI ソリューションの潜在的な危害を軽減するには、次に示すように、4 つの層のそれぞれに軽減手法を適用できる階層化アプローチを使用する必要があります。
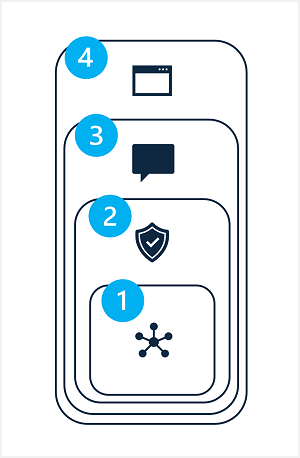
- Model
- 安全システム
- メタプロンプトおよびグラウンディング
- ユーザー エクスペリエンス
1: "モデル" 層
モデル レイヤーは、ソリューションの中心となる 1 つ以上の生成 AI モデルで構成されます。 たとえば、ソリューションは、GPT-4 などのモデルを中心に構築されます。
モデル層で適用できる軽減策としては、次のようなものがあります。
- 目的のソリューションの用途に適したモデルの選択。 たとえば、GPT-4 は強力で汎用性の高いモデルですが、小さな特定のテキスト入力を分類するためだけに必要なソリューションでは、より単純なモデルの方が、有害なコンテンツ生成のリスクを低減しながら必要な機能を提供する可能性があります。
- 独自のトレーニング データによる基本モデルの "微調整"。これにより、生成される応答は、ソリューション シナリオとの関連性が高まり、応答の範囲が絞り込まれる可能性が高くなります。
2: "安全システム" 層
安全システム層には、危害の軽減に役立つプラットフォームレベルの構成と機能が含まれます。 たとえば、Azure AI Studio では、"コンテンツ フィルター" がサポートされています。これは、基準を適用して、潜在的な危害の 4 つのカテゴリ ("ヘイト"、"性的"、"暴力"、"自傷行為") について、コンテンツを 4 つの重大度レベル ("安全"、"低"、"中"、"高") に分類し、それに基づいてプロンプトと応答を抑制します。
その他の安全システム レイヤーの軽減策には、ソリューションが (たとえば、ボットからの大量の自動要求を通して) 体系的に不正使用されているかどうかを特定するための不正使用検出アルゴリズムや、潜在的なシステムの不正使用や有害な動作への迅速な対応を可能にするアラート通知などが含まれます。
3: "メタプロンプトおよびグラウンディング" レイヤー
メタプロンプトおよびグラウンディング レイヤーでは、モデルに送信されるプロンプトの作成に焦点を当てています。 このレイヤーで適用できる危害軽減手法は次のとおりです。
- モデルの動作パラメーターを定義する "メタ プロンプト" またはシステム入力を指定する。
- プロンプト エンジニアリングを適用して、グラウンディング データを入力プロンプトに追加し、関連性が高く無害の出力が生成される可能性を最大化する。
- "検索拡張生成" (RAG) 手法を使用して、信頼されたデータ ソースからコンテキスト データを取得し、プロンプトに含める。
4: "ユーザー エクスペリエンス" レイヤー
ユーザー エクスペリエンス レイヤーには、ユーザーが生成 AI モデルと対話する際に使用するソフトウェア アプリケーションと、そのユーザーと利害関係者に対してソリューションの使用について説明するドキュメントやその他のユーザー向け付帯品が含まれます。
特定のサブジェクトまたは型に入力を制限するようにアプリケーション ユーザー インターフェイスを設計したり、入出力の検証を適用したりすると、潜在的に有害な応答のリスクを軽減できます。
生成 AI ソリューションのドキュメントおよびその他の説明では、システムの機能と制限、そのベースとなっているモデル、導入した軽減策では必ずしも対処できるとは限らない潜在的な危害について、適切に透明性を持たせる必要があります。