Spark を使用してデータを視覚化する
データ クエリの結果を分析する最も直感的な方法の 1 つは、それらをグラフとして視覚化することです。 Azure Synapse Analytics のノートブックには、ユーザー インターフェイスに基本的なグラフ機能がいくつか用意されており、その機能で必要なものが提供されない場合は、多数の Python グラフィックス ライブラリのいずれかを使用して、ノートブックにデータの視覚化を作成して表示できます。
組み込みのノートブック グラフの使用
Azure Synapse Analytics の Spark ノートブックでデータフレームを表示したり、SQL クエリを実行したりすると、結果がコード セルの下に表示されます。 既定では、結果はテーブルとしてレンダリングされますが、次に示すように、結果ビューをグラフに変更し、グラフのプロパティを使用してグラフのデータを視覚化する方法をカスタマイズすることもできます。
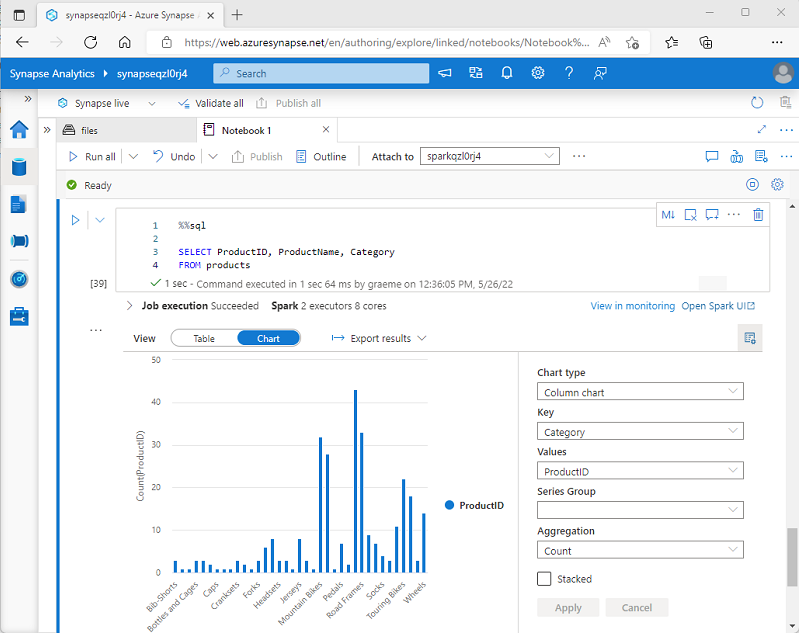
ノートブックの組み込みのグラフ作成機能は、既存のグループ化や集計を含まないクエリの結果を操作し、データをすばやく視覚的に集計する場合に便利です。 データの書式設定方法をより詳細に制御する場合や、クエリで既に集計した値を表示する場合は、グラフィックス パッケージを使用して独自の視覚化を作成することを検討する必要があります。
コードでのグラフィックス パッケージの使用
コードでデータ視覚化を作成するために使用できるグラフィックス パッケージは数多くあります。 特に、Python では多くのパッケージがサポートされています。それらのほとんどは、ベースの Matplotlib ライブラリ上に構築されています。 グラフィックス ライブラリからの出力をノートブックにレンダリングできるため、コードを組み合わせて、インライン データ視覚化とマークダウン セルを使用してデータを取り込んで操作し、コメントを提供できます。
たとえば、次の PySpark コードを使用して、このモジュールで以前に調査した架空の製品データのデータを集計し、Matplotlib を使用して集計データからグラフを作成できます。
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Matplotlib ライブラリでは、データを Spark データフレームではなく Pandas データフレームに格納する必要があるため、toPandas メソッドを使用して変換します。 次に、コードによって、指定したサイズの図形が作成され、カスタム プロパティ構成で横棒グラフがプロットされてから、結果がプロットされます。
コードによって生成されるグラフは、次の図のようになります。
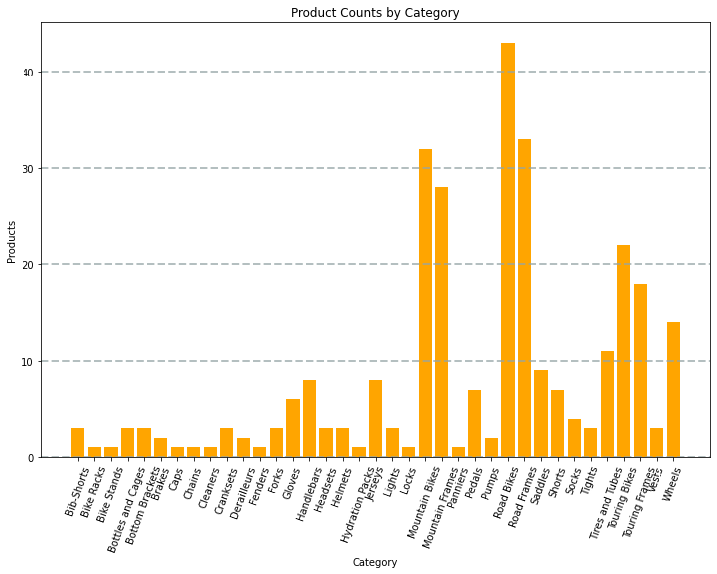
Matplotlib ライブラリを使用して、さまざまな種類のグラフを作成できます。または、必要に応じて、Seaborn などの他のライブラリを使用して、高度にカスタマイズされたグラフを作成することもできます。