Spark クラスターの作成
Azure Databricks ポータルを使って、Azure Databricks ワークスペースに 1 つ以上のクラスターを作成できます。
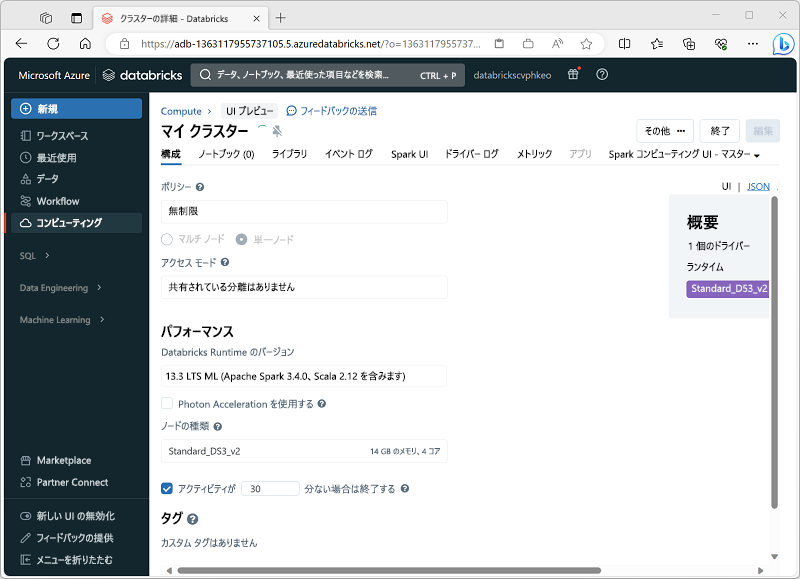
クラスターを作成するときに、次のような構成設定を指定できます。
- クラスターの名前。
- "クラスターのモード"。次のいずれかを指定できます。
- "標準": 複数のワーカー ノードを必要とするシングル ユーザーのワークロードに適しています。
- "高コンカレンシー": 複数のユーザーがクラスターを同時に使うワークロードに適しています。
- "単一ノード": 必要なワーカー ノードが 1 つだけの小規模なワークロードまたはテストに適しています。
- クラスターで使われる Databricks Runtime のバージョン。これは、Spark と、Python、Scala、インストールされる他のコンポーネントなどの個々のコンポーネントのバージョンを示します。
- クラスターのワーカー ノードに使われる仮想マシン (VM) の種類。
- クラスターのワーカー ノードの最小数と最大数。
- クラスターのドライバー ノードに使われる VM の種類。
- クラスターがクラスターのサイズを動的に変更するための "自動スケーリング" をサポートするかどうか。
- クラスターが自動的にシャットダウンされるまでアイドル状態になっていることのできる時間。
Azure がクラスター リソースを管理する方法
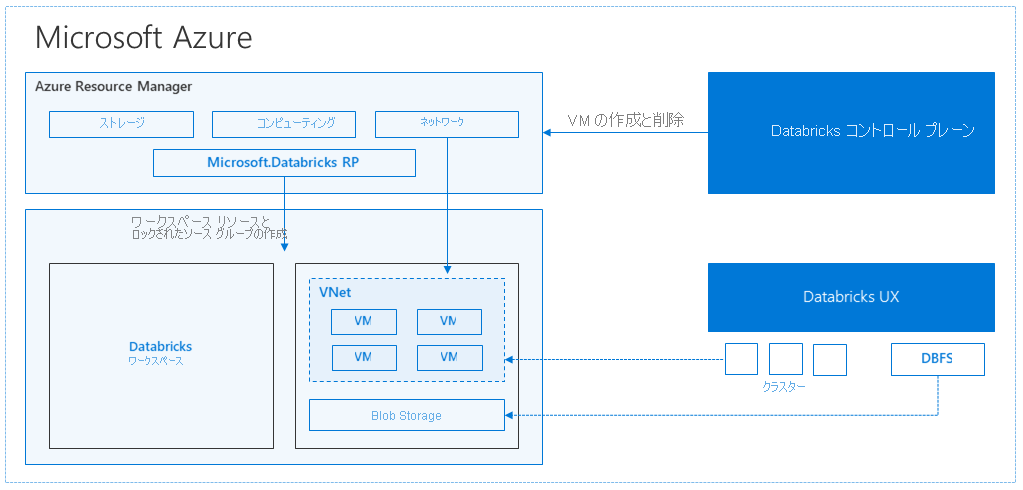
Azure Databricks ワークスペースを作成すると、"Databricks アプライアンス" が Azure リソースとしてお客様のサブスクリプションにデプロイされます。 ワークスペース内にクラスターを作成するときは、ドライバー ノードとワーカー ノードの両方に使う仮想マシン (VM) の種類とサイズおよびその他の構成オプションを指定しますが、クラスターの他のすべての側面は Azure Databricks によって管理されます。
Databricks アプライアンスは、お客様のサブスクリプション内の管理対象リソース グループとして Azure にデプロイされます。 このリソース グループには、クラスターのドライバーとワーカーの VM と、他の必要なリソース (仮想ネットワーク、セキュリティ グループ、ストレージ アカウントなど) が含まれます。 クラスターのメタデータ (スケジュールされたジョブなど) はすべて Azure データベースに格納され、geo レプリケーションによるフォールト トレランスが確保されます。
内部的には、ハイ パフォーマンスの Azure 仮想マシンと高速ネットワーク上で、最新世代の Azure ハードウェア (Dv3 VM) と 100 us の待ち時間を実現できる NvMe SSD で動作するコンテナーを介して、Azure Kubernetes Service (AKS) を使って Azure Databricks のコントロール プレーンとデータ プレーンが実行されます。 Azure Databricks は、Azure のこれらの機能を利用して、Spark のパフォーマンスをさらに向上させます。 管理対象リソース グループ内のサービスの準備ができたら、Azure Databricks UI と、自動スケーリングや自動終了などの機能を使って、Databricks クラスターを管理できます。
Note
また、クラスターの起動時間を短縮するため、アイドル ノードの "プール" にクラスターをアタッチすることもできます。 詳しくは、Azure Databricks のドキュメントの「プール」をご覧ください。