SQL Server Always On 環境での自動フェールオーバーの問題のトラブルシューティング
この記事は、Microsoft SQL Server の自動フェールオーバー中に発生する問題を解決するのに役立ちます。
元の製品バージョン: SQL Server
元の KB 番号: 2833707
まとめ
SQL Server Always On 可用性グループは、自動フェールオーバー用に構成できます。 プライマリ レプリカをホストしている SQL Server のインスタンスで正常性の問題が検出された場合は、プライマリ ロールを自動フェールオーバー パートナー (セカンダリ レプリカ) に移行できます。 ただし、セカンダリ レプリカを常にプライマリ ロールに移行できるわけではありません。 場合によっては、 RESOLVING ロールにのみ移行できます。 この状況では、プライマリ レプリカが正常な状態に戻っていない限り、プライマリ ロールを持つレプリカはありません。 さらに、可用性データベースにアクセスできなくなります。
この記事では、自動フェールオーバーが失敗した一般的な原因をいくつか示し、これらのエラーの原因を診断するために実行できる手順について説明します。
自動フェールオーバーが正常にトリガーされた場合の現象
プライマリ レプリカをホストしている SQL Server のインスタンスで自動フェールオーバーがトリガーされると、セカンダリ レプリカは RESOLVING ロールに移行し、次にプライマリ ロールに移行します。 プロセスは成功しましたが、次のテキストのようなエラー エントリが SQL Server ログ レポートに記録されます。
The state of the local availability replica in availability group '\<Group name>' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'
The state of the local availability replica in availability group '\<Group name>' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'

Note
セカンダリ レプリカは、 RESOLVING_NORMAL 状態から PRIMARY_NORMAL 状態に正常に移行します。
自動フェールオーバーが失敗した場合の現象
自動フェールオーバー イベントが成功しなかった場合、セカンダリ レプリカはプライマリ ロールに正常に移行しません。 そのため、可用性レプリカは、このレプリカが RESOLVING 状態であることを報告します。 さらに、可用性データベースは、それらが NOT SYNCHRONIZING 状態であることを報告し、アプリケーションはこれらのデータベースにアクセスできません。
たとえば、次の図では、SQL Server Management Studio は、自動フェールオーバー プロセスでセカンダリ レプリカをプライマリ ロールに移行できなかったため、セカンダリ レプリカが RESOLVING 状態であることを報告しています。
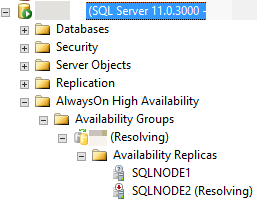
以降のセクションでは、自動フェールオーバーが成功しない可能性があるいくつかの理由と、それぞれの原因を診断する方法について説明します。
ケース 1: "指定された期間内の最大エラー数" の値が使い果たされました
可用性グループには、 Maximum Failures in the Specified Period プロパティなどの Windows クラスター リソース プロパティがあります。 このプロパティは、複数のノード障害が発生した場合に、クラスター化されたリソースの無期限の移動を回避するために使用されます。
これがフェールオーバーの失敗の原因であるかどうかを調査して診断するには、Windows クラスター ログ (Cluster.log) を確認してから、プロパティを確認します。
手順 1: Windows クラスター ログのデータを確認する (Cluster.log)
Windows PowerShell を使用して、プライマリ レプリカをホストしているクラスター ノードで Windows クラスター ログを生成します。 これを行うには、プライマリ レプリカをホストしている SQL Server のインスタンスで、管理者特権の PowerShell ウィンドウで次のコマンドレットを実行します。
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15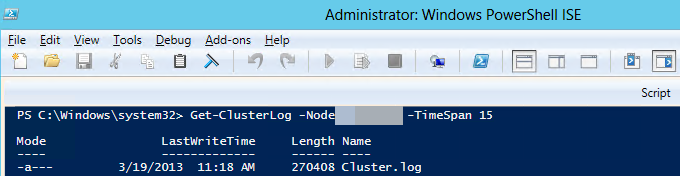
注意事項
- この手順の
-TimeSpan 15パラメーターは、診断中の問題が過去 15 分間に発生したことを前提としています。 - 既定では、ログ ファイルは %WINDIR%\cluster\reports に作成されます。
- この手順の
メモ帳で Cluster.log ファイルを開き、Windows クラスター ログを確認します。
メモ帳で Edit>Find を選択し、ファイルの末尾にある "failoverCount" 文字列を検索します。 結果には、次のメッセージのようなメッセージが表示されます。
グループ <リソース名>、failoverCount 3、failoverThresholdSetting <Number>、computedFailoverThreshold 2 をフェールオーバーしない

手順 2: 指定した期間プロパティの最大エラー数を確認する
フェールオーバー クラスター マネージャーを起動します。
ナビゲーション ウィンドウで Roles を選択します。
Roles ペインで、クラスター化されたリソースを右クリックし、Properties を選択します。
[Failover] タブを選択し、[指定した期間の最大エラー数を選択します。
![[指定された期間] プロパティの [最大エラー数] のスクリーンショット。](media/troubleshooting-automatic-failover-problems/properties.png)
Note
既定の動作では、クラスター化されたリソースが 6 時間以内に 3 回失敗した場合、失敗した状態のままであることを指定します。 可用性グループの場合は、レプリカが
RESOLVING状態のままであることを意味します。
まとめ
ログを分析すると、failoverCount 3 の値が 2 の computedFailoverThreshold 値より大きいことがわかります。 そのため、Windows クラスターは、フェールオーバー パートナーへの可用性グループ リソースのフェールオーバー操作を完了できません。
解像度
この問題を解決するには、指定した期間の Maximum エラー 値を増やします。
Note
この値を大きくしても、問題は解決しない可能性があります。 可用性グループが短期間に何度も失敗する原因となる、より重大な問題が発生する可能性があります。 既定では、この期間は 15 分です。 この値を大きくすると、可用性グループが失敗する回数が増え、失敗した状態のままになる可能性があります。 積極的なトラブルシューティングを使用して、自動フェールオーバーが発生し続ける理由を特定することをお勧めします。
ケース 2: NT 機関\SYSTEM アカウントのアクセス許可が不十分
SQL Server データベース エンジン リソース DLL は、ODBC を使用して正常性を監視することで、プライマリ レプリカをホストしている SQL Server のインスタンスに接続します。 この接続に使用されるログオン資格情報は、ローカル SQL Server NT AUTHORITY\SYSTEM ログイン アカウントです。 既定では、このローカル ログイン アカウントには次のアクセス許可が付与されます。
- 可用性グループの変更
- SQL の接続
- サーバーの状態を表示する
NT AUTHORITY\SYSTEM ログイン アカウントに、自動フェールオーバー パートナー (セカンダリ レプリカ) に対するこれらのアクセス許可がない場合、自動フェールオーバーが発生したときに SQL Server は正常性検出を開始できません。 そのため、セカンダリ レプリカはプライマリ ロールに移行できません。 これが原因であるかどうかを調査して診断するには、Windows クラスター ログを確認します。 これを行うには、次の手順を実行します。
Windows PowerShell を使用して、クラスター ノードに Windows クラスター ログを生成します。 これを行うには、プライマリ ロールに移行しなかったセカンダリ レプリカをホストしている SQL Server のインスタンスで、管理者特権の PowerShell ウィンドウで次のコマンドレットを実行します。
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
メモ帳で Cluster.log ファイルを開き、Windows クラスター ログを確認します。
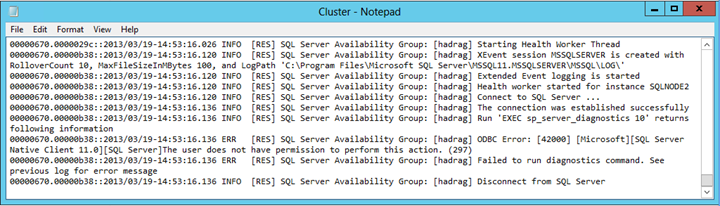
次のテキストのようなエラー エントリを見つけます。
診断コマンドを実行できませんでした。 ユーザーにはこの操作を実行する権限がありません。
まとめ
Cluster.log ファイルは、SQL Server が診断コマンドを実行するときにアクセス許可の問題が存在することを報告します。 この例では、自動フェールオーバー ペアのセカンダリ レプリカをホストしている SQL Server のインスタンス上の NT AUTHORITY\SYSTEM ログイン アカウントからサーバー状態の表示アクセス許可を削除することで、エラーが発生しました。
解像度
この問題を解決するには、SQL Server データベース エンジン リソース DLL の正常性検出のために、NT AUTHORITY\SYSTEM ログイン アカウントに十分なアクセス許可を付与します。
ケース 3: 可用性データベースが SYNCHRONIZED 状態ではない
自動的にフェールオーバーするには、可用性グループで定義されているすべての可用性データベースが、プライマリ レプリカとセカンダリ レプリカの間で SYNCHRONIZED 状態である必要があります。 自動フェールオーバーが発生した場合、データ損失がないことを確認するために、この同期条件を満たす必要があります。 そのため、可用性グループ内の 1 つの可用性データベースが同期中または NOT SYNCHRONIZED 状態の場合、自動フェールオーバーはセカンダリ レプリカをプライマリ ロールに正常に移行しません。
自動フェールオーバーに必要な条件の詳細については、「自動フェールオーバーに必要な条件」を参照してくださいSynchronous コミット レプリカでは、Failover モードとフェールオーバー モード (Always On 可用性グループ)の 2 つの設定セクションがサポートされています。
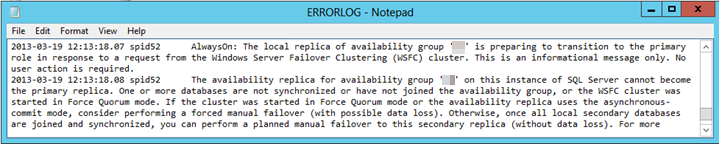
これがフェールオーバーの失敗の原因であるかどうかを調査して診断するには、SQL Server エラー ログを確認します。 次のテキストのようなエラー エントリが表示されます。
1 つ以上のデータベースが同期されていないか、可用性グループに参加していません。
可用性データベースが SYNCHRONIZED 状態であったかどうかを確認するには、次の手順に従います。
セカンダリ レプリカに接続します。
次の SQL スクリプトを実行して、フェールオーバーされなかった可用性グループ内のすべての可用性データベースの
is_failover_ready値を確認します。Note
可用性データベースの値が 0 の場合、自動フェールオーバーを防ぐことができます。 この値は、可用性データベースが
SYNCHRONIZEDされなかったことを示します。SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.dm_hadr_availability_replica_states)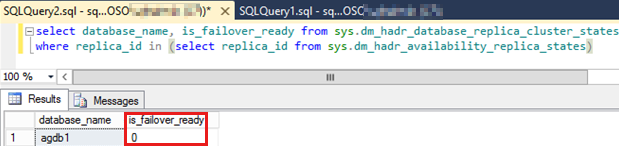
まとめ
可用性グループの自動フェールオーバーが成功するには、すべての可用性データベースが SYNCHRONIZED 状態である必要があります。 可用性モードの詳細については、「Always On 可用性グループの 可用性モードを参照してください。
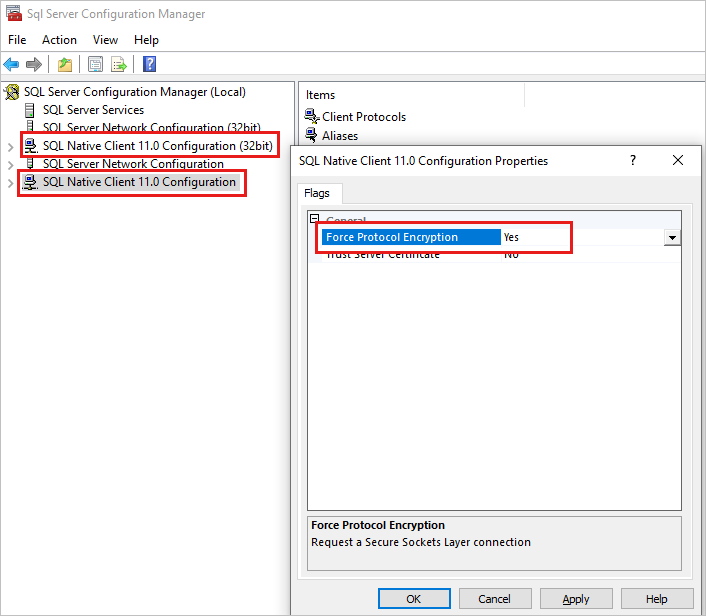
ケース 4: セカンダリ レプリカ (ターゲット プライマリ) 上のクライアント プロトコルに対して "Force Protocol Encryption" 構成が選択されているが、レプリカが暗号化用に構成されていない
フェールオーバー中に、プライマリ サーバーが正常性の問題を検出すると、フェールオーバー パートナー (セカンダリ レプリカ) 上のクラスター DLL がローカル レプリカに接続して正常性の監視を開始しようとします。 これは、プライマリ ロールへの移行の一部です。 セカンダリ レプリカが暗号化用に構成されていないが、クライアント構成で Force Protocol Encryption 設定が誤って設定されている場合、接続は失敗し、フェールオーバーは発生しません。
この構成を確認するには:
- SQL Server 構成マネージャーを起動します。
- left ペインで、SQL Native Client 11.0 Configuration を右クリックし、Properties を選択します。
- ダイアログ ボックスで、 Force Protocol Encryption 設定をオンにします。 Yes に設定されている場合は、値を No に変更します。
- フェールオーバーを再テストします。
まとめ
SQL Server Always On の正常性監視では、ローカル ODBC 接続を使用して SQL Server の正常性を監視します。 SQL Server 構成マネージャーの Client 構成セクションでプロトコル暗号化を強制するを有効にする必要があるのは、SQL Server 自体が SQL Server ネットワーク構成 セクションのSQL Server 構成マネージャーで暗号化を強制するように構成されている場合のみです。 詳細については、「データベース エンジンへの暗号化接続の有効化」を参照してください。
ケース 5: セカンダリ レプリカまたはノードでのパフォーマンスの問題により、Always On 正常性チェックが失敗する
プライマリ レプリカからセカンダリ レプリカにフェールオーバーする前に、SQL Server データベース エンジン リソース DLL はセカンダリ レプリカに接続してレプリカの正常性を確認します。 セカンダリ レプリカのパフォーマンスの問題が原因でこの接続が失敗した場合、自動フェールオーバーは発生しません。
これが原因であるかどうかを調査して診断するには、次の手順に従います。
セカンダリ レプリカのクラスター ログを確認して、エラー メッセージ "サーバー接続を開くのに遅延が発生したため、ログイン プロセスを完了できません" を確認します。
0000110c.00002bcc::2020/08/06-01:17:54.943 INFO [RCM] move of group AOCProd01AG from CO2ICMV3SQL09(1) to CO2ICMV3SQL10(2) of type MoveType::Manual is about to succeed, failoverCount=3, lastFailoverTime=2020/08/05-02:08:54.524 targeted=true 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]Unable to complete login process due to delay in opening server connection (0) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Could not connect to SQL Server (rc -1) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] SQLDisconnect returns following information 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08003] [Microsoft][ODBC Driver Manager] Connection not open (0) 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Failed to connect to SQL Server 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RHS] Online for resource AOCProd01AG failed.この状況は、ビジー状態の既存のワークロードを持つ SQL Server セカンダリ レプリカへのフェールオーバーが行われた場合に発生する可能性があります。 これにより、HADR 正常性接続要求の試行に対する SQL Server の応答が遅れ、フェールオーバーの試行が正常に行われなくなる可能性があります。
システム スケジューラに負荷がかかっているかどうかを判断するには、SQL Server Management Studio を使用してセカンダリ レプリカで次のスクリプトを実行します。
USE MASTER GO WHILE 1=1 BEGIN PRINT convert(varchar(20), getdate(),120) DECLARE @max INT; SELECT @max = max_workers_count FROM sys.dm_os_sys_info; SELECT GETDATE() AS 'CurrentDate', @max AS 'TotalThreads', SUM(active_Workers_count) AS 'CurrentThreads', @max - SUM(active_Workers_count) AS 'AvailableThreads', SUM(runnable_tasks_count) AS 'WorkersWaitingForCpu', SUM(work_queue_count) AS 'RequestWaitingForThreads' --SUM(current_workers_count) AS 'AssociatedWorkers' FROM sys.dm_os_Schedulers WHERE STATUS = 'VISIBLE ONLINE'; wait for delay '0:0:15' END前のクエリの出力例を次に示します。
CurrentDate TotalThreads CurrentThreads AvailableThreads WorkersWaitingForCpu RequestWaitingForThreads 2020-10-06 01:27:01.337 1216 361 855 33 0 2020-10-06 01:27:08.340 1216 1412 -196 22 76 2020-10-06 01:27:15.340 1216 1304 -88 2 161 2020-10-06 01:27:22.340 1216 1242 26- 21 185 2020-10-06 01:27:29.343 1216 13:46 -130 19 476 2020-10-06 01:27:36.350 1216 1350 -134 9 630 2020-10-06 01:27:43.353 1216 13:46 -130 13 539 2020-10-06 01:27:50.360 1216 1378 -162 5 328 2020-10-06 01:27:57.360 1216 197 1019 0 0 WorkersWaitingForCpuとRequestWaitingForThreadsについて報告される値が高い場合は、スケジュールの競合が発生していること、および SQL Server が現在のワークロードにタイムリーにサービスを提供できないことを示します。
解像度
この問題が発生した場合は、セカンダリ レプリカでワークロードを再調整するか、これらのワークロードを実行しているコンピューターの処理能力を増やすこと (プロセッサを追加) することを検討してください。
その他の失敗したフェールオーバー イベントのトラブルシューティング
フェールオーバー中に新しいプライマリ レプリカの正常性を監視するには、プライマリ ロールに移行している SQL Server インスタンスに AlwaysOn 正常性監視をローカルで接続する必要があります。
この記事で説明するより一般的な理由に加えて、この接続試行が失敗する理由は他にも多数あります。 フェールオーバー試行の失敗をさらに調査するには、フェールオーバー パートナー (フェールオーバーできなかったレプリカ) のクラスター ログを確認します。
Windows PowerShell を使用して、クラスター ノードに Windows クラスター ログを生成します。 これを行うには、プライマリ ロールに移行しなかったセカンダリ レプリカをホストしている SQL Server のインスタンスで、管理者特権の PowerShell ウィンドウで次のコマンドレットを実行します。 クラスター ログは、過去 60 分間のアクティビティで生成されます。
Get-ClusterLog -Node <SQLServerNodeName> -TimeSpan 60Windows クラスター ログを確認するには、メモ帳で Cluster.log ファイルを開きます。
失敗したフェールオーバー イベント中に該当する "SQL Server への接続" 文字列を検索します。
スレッド ID (次のスクリーンショットを参照) を使用して後続のログイン メッセージを確認し、ログイン イベントに関連するイベントを関連付けます。 次の例は、"SQL Server への接続" の検索を示しています。また、スレッド ID (左側) を使用して、接続試行が失敗した理由を説明する他の診断を見つけることも示します。
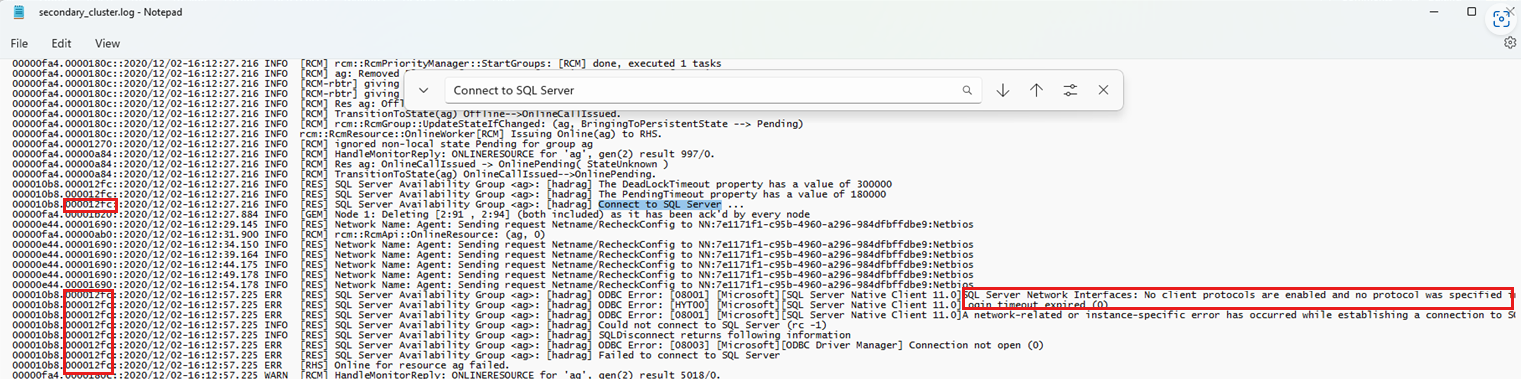

次の例は、新しいプライマリ レプリカへの接続エラーを示しています。
セット 1 の例
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: No client protocols are enabled and no protocol was specified in the connection
string [xFFFFFFFF]. (268435455)
解像度
SQL Server 構成マネージャーを開始し、SQL ネイティブ クライアント構成の Client プロトコルで共有メモリまたは TCP/IP が有効になっていることを確認します。
セット 2 の例
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: Server doesn't support requested protocol [xFFFFFFFF]. (268435455)
解像度
SQL Server 構成マネージャーを開始し、SQL ネイティブ クライアント構成の Client プロトコルで共有メモリまたは TCP/IP が有効になっていることを確認します。
セット 3 の例
000010b8.00001764::2020/12/02-16:52:49.808 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Cannot alter the availability
group 'ag', because it does not exist or you do not have permission. (15151)
000010b8.00000fd0::2020/12/02-17:01:14.821 ERR [RES] SQL Server Availability Group: [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297)
000010b8.00001838::2020/12/02-17:10:04.427 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Login failed for user
'SQLREPRO\NODE2$'. Reason: The account is disabled. (18470)
解像度