Windows ML API を使用してモデルを Windows アプリに展開する
このチュートリアルの前のパートでは、モデルを ONNX 形式で構築し、エクスポートする方法を学習しました。 ここでは、エクスポートしたモデルを Windows アプリケーションに埋め込み、WinML API を呼び出してローカル環境のデバイスで実行する方法について説明します。
完了すると、動作する画像分類アプリができあがります。
サンプル アプリケーションについて
チュートリアルのこのステップでは、ML モデルを使用して画像を分類できるアプリを作成します。 その基本的な UI を使用すると、ローカル デバイスから画像を選択し、前のパートで構築してトレーニングした分類 ONNX モデルを使用して、それを分類できます。 その後、モデルから返されたタグが、画像の横に表示されます。
ここでは、そのプロセスについて説明します。
Note
定義済みのコード サンプルを使用する場合は、ソリューション ファイルをクローンできます。 リポジトリをクローンし、このサンプルに移動して、classifierPyTorch.sln ファイルを Visual Studio で開きます。このページの「アプリケーションの起動」に進み、それが使用されていることを確認します。
以下では、アプリを作成し、Windows ML コードを追加する方法を説明します。
Windows ML UWP (C#) を作成する
Windows ML アプリを動作させるには、以下のことを行う必要があります。
- 機械学習モデルを読み込みます。
- 必要な形式の画像を読み込みます。
- モデルの入力と出力をバインドします。
- モデルを評価し、意味のある結果を表示します。
また、コマンド ラインで満足のいく画像ベースのアプリを作成するのは難しいので、基本的な UI を作成する必要があります。
Visual Studio で新しいプロジェクトを開く
- では、始めましょう。 Visual Studio を開き、[新しいプロジェクトの作成] を選択します。
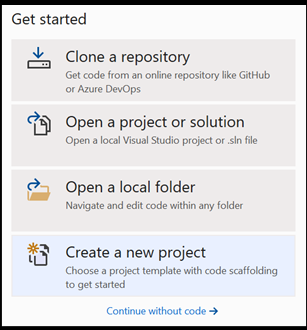
- 検索バーに「
UWP」と入力し、[Blank APP (Universal Windows)] を選択します。 これにより、定義済みのコントロールやレイアウトが含まれる単一ページのユニバーサル Windows プラットフォーム (UWP) アプリ用の C# プロジェクトが開きます。 [next] を選択して、プロジェクトの構成ウィンドウを開きます。
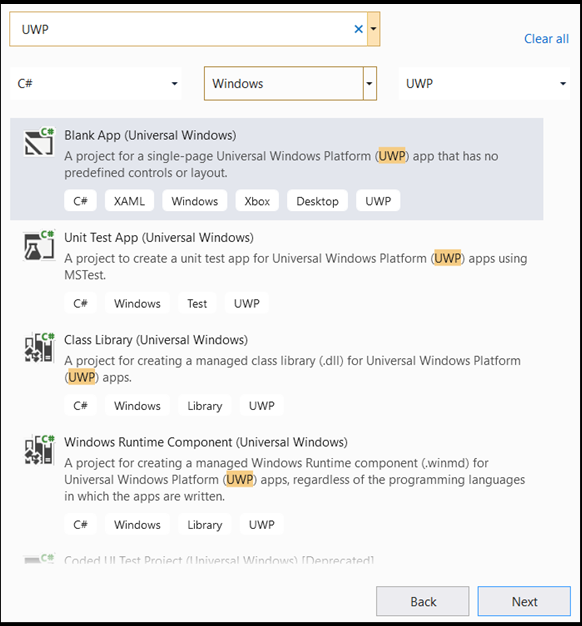
- 構成ウィンドウで、次のようにします。
- プロジェクトに名前を付けます。 ここでは、それを classifierPyTorch という名前にします。
- プロジェクトの場所を選択します。
- VS 2019 を使用する場合は、[
Create directory for solution] がオンになっていることを確認します。 - VS2017 を使用している場合、[
Place solution and project in the same directory] を必ずオフにします。
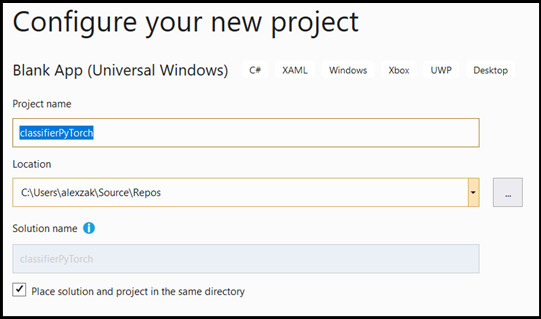
[create] を選択してプロジェクトを作成します。 最小ターゲット バージョン ウィンドウがポップアップ表示される場合があります。 最小バージョンは必ず Windows 10 バージョン 1809 (10.0 ビルド 17763) 以降に設定してください。
- プロジェクトが作成されたら、プロジェクト フォルダーに移動して、assetsフォルダー
[….\classifierPyTorch \Assets]を開き、この場所にImageClassifier.onnxファイルをコピーします。
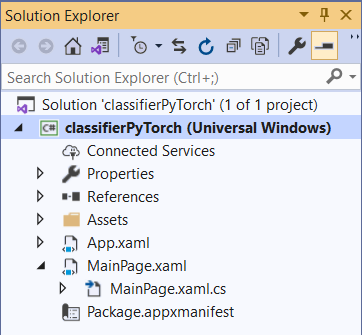
プロジェクトのソリューションを調べる
プロジェクトのソリューションを調べてみましょう。
Visual Studio によって、ソリューション エクスプローラー内にいくつかの cs-code ファイルが自動的に作成されました。 MainPage.xaml には GUI 用の XAML コードが含まれており、MainPage.xaml.cs にはアプリケーションのコード (分離コードとも呼ばれます) が含まれています。 UWP アプリを作成したことがあるなら、これらのファイルはとても見慣れたものでしょう。
アプリケーションの GUI を作成する
まず、アプリ用にシンプルな GUI を作成しましょう。
MainPage.xamlコード ファイルをダブルクリックします。 この空のアプリでは、アプリの GUI 用の XAML テンプレートは空なので、UI 機能を追加する必要があります。次のコードを
MainPage.xamlに追加し、<Grid>タグと</Grid>タグを置き換えます。
<Grid Background="{ThemeResource ApplicationPageBackgroundThemeBrush}">
<StackPanel Margin="1,0,-1,0">
<TextBlock x:Name="Menu"
FontWeight="Bold"
TextWrapping="Wrap"
Margin="10,0,0,0"
Text="Image Classification"/>
<TextBlock Name="space" />
<Button Name="recognizeButton"
Content="Pick Image"
Click="OpenFileButton_Click"
Width="110"
Height="40"
IsEnabled="True"
HorizontalAlignment="Left"/>
<TextBlock Name="space3" />
<Button Name="Output"
Content="Result is:"
Width="110"
Height="40"
IsEnabled="True"
HorizontalAlignment="Left"
VerticalAlignment="Top">
</Button>
<!--Display the Result-->
<TextBlock Name="displayOutput"
FontWeight="Bold"
TextWrapping="Wrap"
Margin="25,0,0,0"
Text="" Width="1471" />
<TextBlock Name="space2" />
<!--Image preview -->
<Image Name="UIPreviewImage" Stretch="Uniform" MaxWidth="300" MaxHeight="300"/>
</StackPanel>
</Grid>
Windows ML コード ジェネレーター (mlgen) を使用してモデルをプロジェクトに追加する
Windows Machine Learning コード ジェネレーター (mlgen) は、UWP アプリ上で WinML API を使い始めるときに役立つ Visual Studio 拡張機能です。 トレーニング済みの ONNX ファイルを UWP プロジェクトに追加すると、テンプレート コードが生成されます。
Windows Machine Learning のコード ジェネレーター mlgen により、Windows ML API を呼び出すラッパー クラスを備えたインターフェイス (C#、C++/WinRT、C++/CX 用) が自動的に作成されます。 そのため、プロジェクト内のモデルの読み込み、バインド、評価を簡単に行うことができます。 このチュートリアルでは、こうした多数の関数を自動的に処理するために使用します。
コード ジェネレーターは、Visual Studio 2017 以降で使用できます。 Visual Studio を使用することをお勧めします。 Windows 10 バージョン 1903 以降では、mlgen が Windows 10 SDK に含まれなくなったため、拡張機能をダウンロードしてインストールする必要があることに注意してください。 最初からこのチュートリアルを実行している場合は済んでいますが、そうでない場合は VS 2019 用または VS 2017 用にダウンロードしてください。
Note
mlgen の詳細については、mlgen のドキュメントを参照してください。
まだの場合は、mlgen をインストールします。
Visual Studio のソリューション エクスプローラーで
Assetsフォルダーを右クリックし、[Add > Existing Item] を選択します。classifierPyTorch [….\classifierPyTorch \Assets]内の assets フォルダーに移動し、そこにコピーした ONNX モデルを探し、[add] を選択します。VS のソリューション エクスプローラーで assets フォルダーに ONNX モデルを追加した後、プロジェクトには 2 つの新しいファイルができているはずです。
ImageClassifier.onnx- これは ONNX 形式のモデルです。ImageClassifier.cs- 自動生成された WinML コード ファイルです。
- アプリケーションをコンパイルするときにモデルが確実に構築されるように、
ImageClassifier.onnxファイルを選択し、[Properties] を選択します。 [Build Action] では、[Content] を選択します。
ONNX ファイルのコード
それでは、ImageClassifier.cs ファイルに新しく生成されたコードを見てみましょう。
生成されたコードには、3 つのクラスが含まれています。
ImageClassifierModel: このクラスには、モデルのインスタンス化とモデルの評価のための 2 つのメソッドが含まれています。 これを使用すると、機械学習モデルの表現を作成し、システムの既定のデバイスでセッションを作成し、特定の入力と出力をモデルにバインドして、モデルを非同期に評価することができます。ImageClassifierInput: このクラスを使用すると、モデルが想定する入力の型を初期化することができます。 モデルの入力は、入力データに対するモデルの要件によって変わります。ImageClassifierOutput: このクラスを使用すると、モデルによる出力の型を初期化することができます。 モデルの出力は、モデルによってどのように定義されているかによって変わります。
このチュートリアルでは、テンソル化は扱いません。 ImageClassifierInput クラスを少し変更し、入力データ型を変更して作業を楽にします。
ImageClassifier.csファイルを次のように変更します。
input 変数を、TensorFloat から ImageFeatureValue に変更します。
public sealed class ImageClassifierInput
{
public ImageFeatureValue input; // shape(-1,3,32,32)
}
モデルを読み込む
MainPage.xaml.csファイルをダブルクリックして、アプリの分離コードを開きます。"using" ステートメントを次のように置き換えて、必要なすべての API にアクセスできるようにします。
// Specify all the using statements which give us the access to all the APIs that we'll need
using System;
using System.Threading.Tasks;
using Windows.AI.MachineLearning;
using Windows.Graphics.Imaging;
using Windows.Media;
using Windows.Storage;
using Windows.Storage.Pickers;
using Windows.Storage.Streams;
using Windows.UI.Xaml;
using Windows.UI.Xaml.Controls;
using Windows.UI.Xaml.Media.Imaging;
MainPageクラス内のpublic MainPage()関数の上に、次の変数宣言を追加します。
// All the required fields declaration
private ImageClassifierModel modelGen;
private ImageClassifierInput image = new ImageClassifierInput();
private ImageClassifierOutput results;
private StorageFile selectedStorageFile;
private string label = "";
private float probability = 0;
private Helper helper = new Helper();
public enum Labels
{
plane,
car,
bird,
cat,
deer,
dog,
frog,
horse,
ship,
truck
}
次は LoadModel メソッドを実装します。 このメソッドを使用すると、ONNX モデルにアクセスし、それをメモリに格納することができます。 次に、CreateFromStreamAsync メソッドを使用して、モデルを LearningModel オブジェクトとしてインスタンス化します。 LearningModel クラスは、トレーニング済みの機械学習モデルを表します。 インスタンス化された LearningModel は、Windows ML との対話に使用する最初のオブジェクトになります。
モデルを読み込むために、LearningModel クラスのいくつかの静的メソッドを使用することができます。 この例では、CreateFromStreamAsync メソッドを使用します。
CreateFromStreamAsync メソッドは mlgen で自動的に作成されているので、このメソッドを実装する必要はありません。 mlgen で生成された classifier.cs ファイルをダブルクリックすると、このメソッドを確認することができます。
Note
LearningModel クラスの詳細については、LearningModel クラスのドキュメントを参照してください。 モデルを読み込むその他の方法については、モデルの読み込みに関するドキュメントを参照してください。
- メイン クラスのコンストラクターに、
loadModelメソッドの呼び出しを追加します。
// The main page to initialize and execute the model.
public MainPage()
{
this.InitializeComponent();
loadModel();
}
- その
MainPageクラス内に、loadModelメソッドの実装を追加します。
private async Task loadModel()
{
// Get an access the ONNX model and save it in memory.
StorageFile modelFile = await StorageFile.GetFileFromApplicationUriAsync(new Uri($"ms-appx:///Assets/ImageClassifier.onnx"));
// Instantiate the model.
modelGen = await ImageClassifierModel.CreateFromStreamAsync(modelFile);
}
画像を読み込む
- モデル実行のための 4 つのメソッド呼び出し (変換、バインドと評価、出力の抽出、結果の表示) のシーケンスを開始するために、クリック イベントを定義する必要があります。
MainPageクラス内のMainPage.xaml.csコード ファイルに次のメソッドを追加します。
// Waiting for a click event to select a file
private async void OpenFileButton_Click(object sender, RoutedEventArgs e)
{
if (!await getImage())
{
return;
}
// After the click event happened and an input selected, begin the model execution.
// Bind the model input
await imageBind();
// Model evaluation
await evaluate();
// Extract the results
extractResult();
// Display the results
await displayResult();
}
- 次は
getImage()メソッドを実装します。 このメソッドにより、入力画像ファイルが選択され、メモリに保存されます。MainPageクラス内のMainPage.xaml.csコード ファイルに次のメソッドを追加します。
// A method to select an input image file
private async Task<bool> getImage()
{
try
{
// Trigger file picker to select an image file
FileOpenPicker fileOpenPicker = new FileOpenPicker();
fileOpenPicker.SuggestedStartLocation = PickerLocationId.PicturesLibrary;
fileOpenPicker.FileTypeFilter.Add(".jpg");
fileOpenPicker.FileTypeFilter.Add(".png");
fileOpenPicker.ViewMode = PickerViewMode.Thumbnail;
selectedStorageFile = await fileOpenPicker.PickSingleFileAsync();
if (selectedStorageFile == null)
{
return false;
}
}
catch (Exception)
{
return false;
}
return true;
}
次に、ファイルの表現をビットマップ BGRA8 形式で取得するために、image Bind() メソッドを実装します。 その前に、画像のサイズを変更するヘルパー クラスを作成します。
- ヘルパー ファイルを作成するには、ソリューション名 (
ClassifierPyTorch) を右クリックして [Add a new item] を選択します。 開いたウィンドウでClassを選択し、名前を付けます。 ここではHelperと呼びます。
- プロジェクト内に新しいクラス ファイルが表示されます。 このクラスを開き、次のコードを追加します。
using System;
using System.Threading.Tasks;
using Windows.Graphics.Imaging;
using Windows.Media;
namespace classifierPyTorch
{
public class Helper
{
private const int SIZE = 32;
VideoFrame cropped_vf = null;
public async Task<VideoFrame> CropAndDisplayInputImageAsync(VideoFrame inputVideoFrame)
{
bool useDX = inputVideoFrame.SoftwareBitmap == null;
BitmapBounds cropBounds = new BitmapBounds();
uint h = SIZE;
uint w = SIZE;
var frameHeight = useDX ? inputVideoFrame.Direct3DSurface.Description.Height : inputVideoFrame.SoftwareBitmap.PixelHeight;
var frameWidth = useDX ? inputVideoFrame.Direct3DSurface.Description.Width : inputVideoFrame.SoftwareBitmap.PixelWidth;
var requiredAR = ((float)SIZE / SIZE);
w = Math.Min((uint)(requiredAR * frameHeight), (uint)frameWidth);
h = Math.Min((uint)(frameWidth / requiredAR), (uint)frameHeight);
cropBounds.X = (uint)((frameWidth - w) / 2);
cropBounds.Y = 0;
cropBounds.Width = w;
cropBounds.Height = h;
cropped_vf = new VideoFrame(BitmapPixelFormat.Bgra8, SIZE, SIZE, BitmapAlphaMode.Ignore);
await inputVideoFrame.CopyToAsync(cropped_vf, cropBounds, null);
return cropped_vf;
}
}
}
それでは、画像を適切な形式に変換しましょう。
ImageClassifierInput クラスを使用すると、モデルが想定する入力の型を初期化することができます。 この例では、ImageFeatureValue を想定するようにコードを構成しました。
ImageFeatureValue クラスには、モデルに渡すために使用される画像のプロパティを記述します。 ImageFeatureValue を作成するには、CreateFromVideoFrame メソッドを使用します。 なぜそうなるのか、これらのクラスとメソッドがどのように機能するのか、より具体的な詳細については、ImageFeatureValue クラスのドキュメントを参照してください
Note
このチュートリアルでは、テンソルではなく ImageFeatureValue クラスを使用します。 モデルの色の形式が Window ML でサポートされていない場合は、この方法を選択できません。 画像の変換とテンソル化の作業方法の例については、カスタム テンソル化サンプルのページを参照してください。
- MainPage クラス内の
MainPage.xaml.csコード ファイルにconvert()メソッドの実装を追加します。 convert メソッドにより、BGRA8 形式の入力ファイルの表現が得られます。
// A method to convert and bide the input image.
private async Task imageBind ()
{
UIPreviewImage.Source = null;
try
{
SoftwareBitmap softwareBitmap;
using (IRandomAccessStream stream = await selectedStorageFile.OpenAsync(FileAccessMode.Read))
{
// Create the decoder from the stream
BitmapDecoder decoder = await BitmapDecoder.CreateAsync(stream);
// Get the SoftwareBitmap representation of the file in BGRA8 format
softwareBitmap = await decoder.GetSoftwareBitmapAsync();
softwareBitmap = SoftwareBitmap.Convert(softwareBitmap, BitmapPixelFormat.Bgra8, BitmapAlphaMode.Premultiplied);
}
// Display the image
SoftwareBitmapSource imageSource = new SoftwareBitmapSource();
await imageSource.SetBitmapAsync(softwareBitmap);
UIPreviewImage.Source = imageSource;
// Encapsulate the image within a VideoFrame to be bound and evaluated
VideoFrame inputImage = VideoFrame.CreateWithSoftwareBitmap(softwareBitmap);
// Resize the image size to 32x32
inputImage=await helper.CropAndDisplayInputImageAsync(inputImage);
// Bind the model input with image
ImageFeatureValue imageTensor = ImageFeatureValue.CreateFromVideoFrame(inputImage);
image.modelInput = imageTensor;
// Encapsulate the image within a VideoFrame to be bound and evaluated
VideoFrame inputImage = VideoFrame.CreateWithSoftwareBitmap(softwareBitmap);
// bind the input image
ImageFeatureValue imageTensor = ImageFeatureValue.CreateFromVideoFrame(inputImage);
image.modelInput = imageTensor;
}
catch (Exception e)
{
}
}
モデルのバインドと評価
次に、モデルに基づいてセッションを作成し、セッションからの入力と出力を結合し、モデルを評価します。
モデルをバインドするセッションを作成します。
セッションの作成には LearningModelSession クラスを使用します。 このクラスは、機械学習モデルを評価するために使用されます。また、モデルの実行と評価を行うデバイスにモデルがバインドされます。 セッションを作成する際にデバイスを選択して、マシンの特定のデバイス上でモデルを実行することができます。 既定のデバイスは CPU です。
Note
デバイスの選択方法の詳細については、セッションの作成に関するドキュメントを参照してください。
モデルの入力と出力をバインドする:
入力と出力をバインドするには、LearningModelBinding クラスを使用します。 機械学習モデルには、モデルとの間で情報をやり取りする入力および出力機能があります。 必要な機能は Window ML API でサポートされている必要があることに注意してください。 LearningModelBinding クラスは LearningModelSession に適用され、名前付きの入力機能と出力機能に値がバインドされます。
バインドの実装は mlgen によって自動的に生成されるので、これに対応する必要ありません。 バインドは LearningModelBinding クラスの定義済みメソッドを呼び出すことで実装されます。 この例では、Bind メソッドを使用して、名前付きの特徴の種類に値をバインドします。
モデルを評価する:
セッションを作成してモデルをバインドし、バインドされた値をモデルの入力と出力に設定すると、モデルの入力を評価して予測値を取得できるようになります。 モデル実行を行うには、LearningModelSession に対して定義済みの evaluate メソッドのいずれかを呼び出す必要があります。 この例では EvaluateAsync メソッドを使用します。
CreateFromStreamAsync と同様に、EvaluateAsync メソッドも WinML コード ジェネレーターによって自動生成されるので、このメソッドを実装する必要はありません。 このメソッドは ImageClassifier.cs ファイルで確認できます。
EvaluateAsync メソッドを使用すると、既にバインドにバインドされている特徴量の値を使用し、機械学習モデルを非同期的に評価することができます。 また、LearningModelSession を使用してセッションを作成し、LearningModelBinding を使用して入力と出力をバインドし、モデルの評価を実行し、LearningModelEvaluationResult クラスを使用してモデルの出力特徴量を取得することができます。
Note
モデルを実行するための他の評価メソッドについては、LearningModelSession クラスのドキュメントを参照して、LearningModelSession にどのようなメソッドを実装できるかを確認してください。
- MainPage クラス内の
MainPage.xaml.csコード ファイルに次のメソッドを追加し、セッションの作成、モデルのバインドと評価を行います。
// A method to evaluate the model
private async Task evaluate()
{
results = await modelGen.EvaluateAsync(image);
}
結果の抽出と表示
次に、モデルの出力を抽出して正しい結果を表示する必要があります。これを行うには、extractResult と displayResult のメソッドを実装します。 正しいラベルを返すには、最も高い確率を見つける必要があります。
MainPageクラス内のMainPage.xaml.csコード ファイルにextractResultメソッドを追加します。
// A method to extract output from the model
private void extractResult()
{
// Retrieve the results of evaluation
var mResult = results.modelOutput as TensorFloat;
// convert the result to vector format
var resultVector = mResult.GetAsVectorView();
probability = 0;
int index = 0;
// find the maximum probability
for(int i=0; i<resultVector.Count; i++)
{
var elementProbability=resultVector[i];
if (elementProbability > probability)
{
index = i;
}
}
label = ((Labels)index).ToString();
}
MainPageクラス内のMainPage.xaml.csコード ファイルにdisplayResultメソッドを追加します。
private async Task displayResult()
{
displayOutput.Text = label;
}
完了です! 分類モデルをテストするための基本的な GUI を備えた Windows Machine Learning アプリを作成することができました。 次の手順は、アプリケーションを起動して、Windows デバイス上でローカルに実行することです。
アプリケーションを起動します
アプリケーション インターフェイスを完成させ、モデルを追加し、Windows ML コードを生成したら、アプリケーションをテストすることができます。
開発者モードを有効にして、Visual Studio からアプリケーションをテストします。 上部のツール バーのドロップダウン メニューが Debug に設定されていることを確認します。 ローカル コンピューター上でプロジェクトを実行するように、デバイスが 64 ビットの場合は x64 に、32 ビットの場合は x86 にソリューション プラットフォームを変更します。
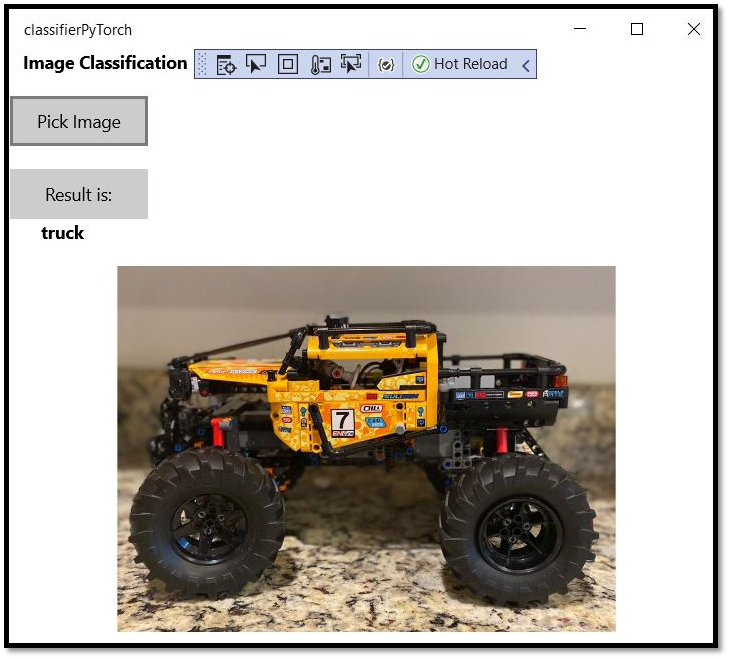
ここでのモデルは、飛行機、自動車、鳥、猫、鹿、犬、蛙、馬、船、トラックの画像を分類するためにトレーニングされました。 アプリをテストするには、このプロジェクト用に作成されたレゴの自動車の画像を使用します。 画像の内容がアプリによってどのように分類されるかを見てみましょう。

アプリをテストするために、この画像をローカル デバイスに保存します。 必要に応じて、画像形式を
.jpgに変更します。 ローカル デバイスから他の関連する画像 (.jpg または .png 形式) を追加することもできます。プロジェクトを実行するには、ツール バーの [
Start Debugging] ボタンを選択するか、F5キーを押します。アプリケーションが起動したら、[Pick image]\(画像の選択\) を選択し、ローカル デバイスから画像を選択します。
結果はすぐに画面に表示されます。 ご覧のように、この Windows ML アプリにより、画像が正しく自動車として分類されました。
まとめ
これで、モデルの作成から実行まで、最初の Windows Machine Learning アプリが完成しました。
その他のリソース
このチュートリアルで説明しているトピックについて詳しくは、次のリソースを参照してください。
- Windows ML ツール: Windows ML ダッシュボード、WinMLRunner、mglen Windows ML コード ジェネレーターなどのツールについて説明します。
- ONNX モデル: ONNX 形式について説明します。
- Windows ML のパフォーマンスとメモリ: Windows ML を使用してアプリのパフォーマンスを管理する方法について説明します。
- Windows Machine Learning API リファレンス: Windows ML の 3 つの領域について説明します。