방법: Metrics Advisor에 메트릭 데이터 온보딩
Important
2023년 9월 20일부터 새로운 Metrics Advisor 리소스를 만들 수 없습니다. Metrics Advisor 서비스는 2026년 10월 1일에 사용 중지됩니다.
이 문서를 사용하여 Metrics Advisor에 데이터를 온보딩하는 방법에 대해 알아보세요.
데이터 스키마 요구 사항 및 구성
Azure AI Metrics Advisor는 시계열 변칙 검색, 진단 및 분석을 위한 서비스입니다. AI 지원 서비스로, 데이터를 사용하여 사용 모델을 학습시킵니다. 이 서비스는 다음 열을 사용하여 집계된 데이터의 테이블을 허용합니다.
- 측정값(필수): 측정값은 기본 또는 단위 관련 용어이며 메트릭의 수량화 가능한 값입니다. 숫자 값을 포함하는 하나 이상의 열을 의미합니다.
- 타임스탬프(옵션):
DateTime또는String형식의 열 0개 또는 1개. 이 열이 설정되지 않은 경우 타임스탬프는 각 수집 기간의 시작 시간으로 설정됩니다. 타임스탬프의 서식을yyyy-MM-ddTHH:mm:ssZ와 같이 지정합니다. - 차원(선택 사항): 차원은 하나 이상의 범주 값입니다. 이러한 값의 조합은 특정 단변량 시계열(예: 국가/지역, 언어 및 테넌트)을 식별합니다. 차원 열은 모든 데이터 형식일 수 있습니다. 대량의 열과 값으로 작업하는 경우에는 너무 많은 차원이 처리되지 않도록 주의하세요.
Azure Data Lake Storage 또는 Azure Blob Storage와 같은 데이터 원본을 사용하는 경우 예상 메트릭 스키마에 맞게 데이터를 집계할 수 있습니다. 이는 이러한 데이터 원본이 파일을 메트릭 입력으로 사용하기 때문입니다.
Azure SQL 또는 Azure Data Explorer와 같은 데이터 원본을 사용하는 경우 집계 함수를 사용하여 데이터를 예상 스키마로 집계할 수 있습니다. 이는 이러한 데이터 원본이 원본에서 메트릭 데이터를 가져오기 위한 쿼리 실행을 지원하기 때문입니다.
일부 용어에 대해 잘 모르는 경우 용어집을 참조하세요.
부분 데이터 로드 방지
부분 데이터는 Metrics Advisor에 저장된 데이터와 데이터 원본 간의 불일치로 인해 발생합니다. 이 문제는 Metrics Advisor가 데이터 가져오기를 완료한 후 데이터 원본이 업데이트될 때 발생할 수 있습니다. Metrics Advisor는 지정된 데이터 원본에서 데이터를 한 번만 가져옵니다.
예를 들어 모니터링하기 위해 메트릭이 Metrics Advisor에 온보딩되었다고 가정합니다. Metrics Advisor는 타임스탬프 A에서 메트릭 데이터를 성공적으로 가져와서 변칙 검색을 수행합니다. 그러나 데이터를 수집한 후 특정 타임스탬프 A의 메트릭 데이터가 새로 고쳐진 경우 새 데이터 값이 검색되지 않습니다.
나중에 설명된 기록 데이터를 백필하여 불일치를 완화할 수 있지만, 이러한 시간 포인트에 대한 경고가 이미 트리거된 경우에는 새로운 변칙 경고가 트리거되지 않습니다. 이 프로세스는 시스템에 워크로드를 추가할 수 있으며 자동으로 수행되지 않습니다.
부분 데이터 로드를 방지하려면 다음 두 가지 방법을 사용하는 것이 좋습니다.
하나의 트랜잭션으로 데이터 생성:
동일한 타임스탬프의 모든 차원 조합에 대한 메트릭 값이 한 트랜잭션으로 데이터 원본에 저장되는지 확인합니다. 위의 예에서는 모든 데이터 원본의 데이터가 준비될 때까지 기다렸다가 하나의 트랜잭션으로 Metrics Advisor에 로드합니다. Metrics Advisor는 데이터가 성공적으로(또는 부분적으로) 검색될 때까지 데이터 피드를 정기적으로 폴링할 수 있습니다.
수집 시간 오프셋 매개 변수에 적절한 값을 설정하여 데이터 수집을 지연시킵니다.
데이터가 완전히 준비될 때까지 수집을 지연하려면 데이터 피드에 대한 수집 시간 오프셋 매개 변수를 설정합니다. 이 기능은 Azure Table Storage와 같이 트랜잭션을 지원하지 않는 일부 데이터 원본에 유용할 수 있습니다. 자세한 내용은 고급 설정을 참조하세요.
데이터 피드를 추가하여 시작
Metrics Advisor 포털에 로그인하고 작업 영역을 선택한 후 시작하기를 클릭합니다. 그런 다음 작업 영역 기본 페이지의 왼쪽 메뉴에서 데이터 피드 추가를 클릭합니다.
연결 설정 추가
1. 기본 설정
그런 다음 시계열 데이터 원본을 연결할 일련의 매개 변수를 입력합니다.
- 원본 형식: 시계열 데이터가 저장되는 데이터 원본 형식입니다.
- 세분성: 시계열 데이터의 연속 데이터 포인트 간 간격입니다. 현재 Metrics Advisor는 연간, 월별, 주별, 일별, 시간별, 분당 및 사용자 지정을 지원합니다. 사용자 지정 옵션이 지원하는 가장 낮은 간격은 60초입니다.
- 초: granularityName이 사용자 지정으로 설정된 경우 초 수입니다.
- 데이터 수집 시작 시간(UTC): 데이터 수집의 초기 계획 시작 날짜 시간입니다.
startOffsetInSeconds는 데이터 일관성에 도움이 되는 오프셋을 추가하는 데 사용되는 경우가 많습니다.
2. 연결 문자열 지정
다음으로, 데이터 원본에 대한 연결 정보를 지정해야 합니다. 다른 필드 및 다양한 유형의 데이터 원본 연결에 대한 자세한 내용은 방법: 다른 데이터 원본 연결를 참조하세요.
3. 단일 타임스탬프에 대한 쿼리 지정
다양한 유형의 데이터 원본에 대한 자세한 내용은 방법: 다른 데이터 원본 연결을 참조하세요.
데이터 로드
연결 문자열과 쿼리 문자열을 입력한 후 데이터 로드를 선택합니다. 이 작업 내에서 Metrics Advisor는 연결과 데이터 로드 권한, 쿼리에서 사용되어야 하는 필수 매개 변수(@IntervalStart 및 @IntervalEnd), 데이터 원본의 열 이름을 확인합니다.
이 단계에서 오류가 발생하는 경우 다음을 확인합니다.
- 먼저 연결 문자열이 유효한지 확인합니다.
- 또한 충분한 권한이 있는지, 수집 작업자 IP 주소에 액세스 권한이 부여되었는지 확인합니다.
- 그런 다음, 쿼리에서 필수 매개 변수(@IntervalStart 및 @IntervalEnd)가 사용되었는지 확인합니다.
스키마 구성
데이터 스키마가 로드되면 적절한 필드를 선택합니다.
데이터 포인트의 타임스탬프가 생략되면 Metrics Advisor에서 데이터 포인트가 수집된 시간의 타임스탬프를 대신 사용합니다. 각 데이터 피드에 최대 하나의 열을 타임스탬프로 지정할 수 있습니다. 열을 타임스탬프로 지정할 수 없다는 메시지가 표시되면 쿼리 또는 데이터 원본을 확인하고 미리 보기 데이터뿐 아니라 쿼리 결과에 여러 타임스탬프가 있는지 여부를 확인합니다. 데이터를 수집할 때 Metrics Advisor는 매번 지정된 원본에서 하나의 시계열 데이터 청크(예: 세분성에 따라 하루, 한 시간 등)만 사용할 수 있습니다.
| 선택 사항 | 설명 | 참고 |
|---|---|---|
| 표시 이름 | 원래 열 이름 대신 작업 영역에 표시되는 이름입니다. | 선택 사항. |
| Timestamp | 데이터 요소의 타임스탬프. 생략하면 Metrics Advisor가 데이터 요소가 수집된 시간의 타임스탬프를 대신 사용합니다. 각 데이터 피드에 최대 하나의 열을 타임스탬프로 지정할 수 있습니다. | 선택 사항. 최대 하나의 열에 지정해야 합니다. 열을 타임스탬프로 지정할 수 없음 오류가 발생한 경우 쿼리 또는 데이터 원본에서 중복 타임스탬프를 확인합니다. |
| 측정값 | 데이터 피드의 숫자 값. 각 데이터 피드에 여러 측정값을 지정할 수 있지만 하나 이상의 열을 측정값으로 선택해야 합니다. | 하나 이상의 열에 지정해야 합니다. |
| 차원 | 범주별 값. 다양한 값의 조합은 특정 단일 차원 시계열(예: 국가/지역, 언어, 테넌트)을 식별합니다. 0개 이상의 열을 차원으로 선택할 수 있습니다. 참고: 문자열이 아닌 열을 차원으로 선택할 때는 주의하세요. | 선택 사항. |
| 무시 | 선택된 열을 무시하세요. | 선택 사항. 쿼리를 사용한 데이터 가져오기를 지원하는 데이터 원본의 경우 ‘무시’ 옵션이 없습니다. |
열을 무시하려면 해당 열을 제외하도록 쿼리 또는 데이터 원본을 업데이트하는 것이 좋습니다. 또한 열 무시를 사용하여 열을 무시한 다음 특정 열에서 무시할 수 있습니다. 열이 차원이고 무시됨으로 잘못 설정된 경우 Metrics Advisor가 부분 데이터를 수집하게 될 수 있습니다. 예를 들어 쿼리의 데이터가 아래와 같다고 가정합니다.
| 행 ID | 타임스탬프 | 국가/지역 | 언어 | Income |
|---|---|---|---|---|
| 1 | 2019/11/10 | 중국 | ZH-CN | 10000 |
| 2 | 2019/11/10 | 중국 | EN-US | 1000 |
| 3 | 2019/11/10 | US | ZH-CN | 12000 |
| 4 | 2019/11/11 | US | EN-US | 23000 |
| , , | , , | , , | , , | , , |
국가가 차원이고 언어가 무시됨으로 설정된 경우, 첫 번째 행과 두 번째 행은 타임스탬프의 차원이 동일합니다. Metrics Advisor는 두 행의 값 중 하나를 임의로 사용합니다. 이 경우 Metrics Advisor는 행을 집계하지 않습니다.
스키마를 구성한 후 스키마 확인을 선택합니다. 이 작업 내에서 Metrics Advisor는 다음 검사를 수행합니다.
- 쿼리된 데이터의 타임스탬프가 단일 간격에 속하는지 여부
- 하나의 메트릭 간격 내에서 동일한 차원 조합에 대해 반환된 중복 값이 있는지 여부
자동 롤업 설정
Important
근본 원인 분석 및 기타 진단 기능을 사용하도록 설정하려면 자동 롤업 설정을 구성해야 합니다. 사용하도록 설정된 자동 롤업 설정은 변경할 수 없습니다.
Metrics Advisor는 수집 중에 각 차원에서 집계(예: SUM, MAX, MIN)를 자동으로 수행한 후 근본 원인 분석 및 기타 진단 기능에 사용할 계층 구조를 구축할 수 있습니다.
다음 시나리오를 고려하세요.
“데이터에 대한 롤업 분석을 포함할 필요가 없습니다.”
Metrics Advisor 롤업을 사용할 필요가 없습니다.
“데이터가 이미 롤업되었으며 차원 값이 NULL 또는 비어 있음(기본값), NULL만, 기타로 표시됩니다.”
이 옵션은 행이 이미 합산되었기 때문에 Metrics Advisor가 데이터를 롤업할 필요가 없음을 의미합니다. 예를 들어 NULL만을 선택하면 아래 예에서 두 번째 데이터 행이 모든 국가 및 언어 EN-US의 집계로 표시됩니다. 그러나 국가에 대한 값이 비어 있는 네 번째 데이터 행은 불완전한 데이터를 나타낼 수 있는 일반 행으로 표시됩니다.
국가/지역 언어 Income 중국 ZH-CN 10000 (NULL) EN-US 999999 US EN-US 12000 EN-US 5000 “Sum/Max/Min/Avg/Count를 계산하여 데이터를 롤업하고 {some string}으로 표시하려면 Metrics Advisor가 필요합니다.”
Azure Cosmos DB 또는 Azure Blob Storage와 같은 일부 데이터 원본은 group by 또는 cube와 같은 특정 계산을 지원하지 않습니다. Metrics Advisor는 수집 중에 데이터 큐브를 자동으로 생성하는 롤업 옵션을 제공합니다. 이 옵션은 선택한 알고리즘을 사용하여 롤업을 계산하고 지정된 문자열을 사용하여 Metrics Advisor에서 롤업을 나타내기 위해 Metrics Advisor가 필요하다는 의미입니다. 데이터 원본의 데이터는 변경되지 않습니다. 예를 들어, 차원(국가, 지역)을 가진 판매 메트릭을 나타내는 시계열 집합이 있다고 가정합니다. 지정된 타임스탬프에 대해 다음과 같이 표시될 수 있습니다.
국가 지역 Sales Canada Alberta 100 Canada British Columbia 500 미국 Montana 100 Sum으로 자동 롤업을 사용하도록 설정하면 Metrics Advisor가 차원 조합을 계산하고 데이터 수집 중에 메트릭을 합산합니다. 결과는 다음과 같습니다.
국가 지역 Sales Canada Alberta 100 NULL Alberta 100 Canada British Columbia 500 NULL British Columbia 500 미국 Montana 100 NULL Montana 100 NULL NULL 700 Canada NULL 600 미국 NULL 100 (Country=Canada, Region=NULL, Sales=600)은 캐나다 판매량(모든 지역)의 합계가 600임을 의미합니다.SQL 언어로 변환하면 다음과 같습니다.
SELECT dimension_1, dimension_2, ... dimension_n, sum (metrics_1) AS metrics_1, sum (metrics_2) AS metrics_2, ... sum (metrics_n) AS metrics_n FROM each_timestamp_data GROUP BY CUBE (dimension_1, dimension_2, ..., dimension_n);자동 롤업 기능을 사용하기 전에 다음 사항을 고려하세요.
- SUM을 사용하여 데이터를 집계하려면 메트릭이 각 차원에서 가산적인지 확인합니다. 다음은 비가산 메트릭의 몇 가지 예입니다.
- 분수 기반 메트릭. 여기에는 비율, 백분율 등이 포함됩니다. 예를 들어, 국가/지역 전체의 실업률을 계산하기 위해 각 주의 실업률을 추가해서는 안 됩니다.
- 차원의 중복. 예를 들어, 스포츠를 좋아하는 사람의 수를 계산하기 위해 각 스포츠를 좋아하는 사람 수를 더하면 안 됩니다. 한 사람이 여러 스포츠를 좋아하여 겹치는 부분이 있을 수 있기 때문입니다.
- 전체 시스템의 상태를 보장하기 위해 큐브의 크기가 제한됩니다. 현재 제한은 100,000입니다. 데이터가 이 제한을 초과하면 해당 타임스탬프에 대한 수집이 실패합니다.
- SUM을 사용하여 데이터를 집계하려면 메트릭이 각 차원에서 가산적인지 확인합니다. 다음은 비가산 메트릭의 몇 가지 예입니다.
고급 설정
수집 오프셋 또는 동시성 지정과 같이 사용자 지정 방식으로 수집된 데이터를 활성화하기 위한 몇 가지 고급 설정이 있습니다. 자세한 내용은 데이터 피드 관리 문서의 고급 설정 섹션을 참조하세요.
데이터 피드 이름 지정 및 수집 진행률 확인
작업 영역에 표시될 데이터 피드의 사용자 지정 이름을 지정합니다. 그런 다음, 제출을 선택합니다. 데이터 피드 세부 정보 페이지에서 수집 진행률 표시줄을 사용하여 상태 정보를 볼 수 있습니다.

수집 오류 세부 정보를 확인하려면 다음을 수행하세요.
- 세부 정보 표시를 선택합니다.
- 상태를 선택한 다음 실패 또는 오류를 선택합니다.
- 실패한 수집 위로 마우스를 가져간 다음 표시된 세부 정보 메시지를 확인합니다.
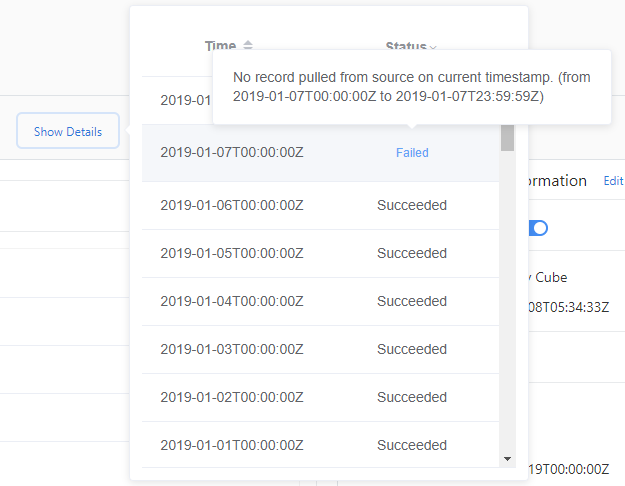
실패 상태는 이 데이터 원본에 대한 수집이 나중에 다시 시도됨을 나타냅니다. 오류 상태는 Metrics Advisor가 데이터 소스에 대해 다시 시도하지 않음을 나타냅니다. 데이터를 다시 로드하려면 백필/다시 로드를 수동으로 트리거해야 합니다.
진행률 새로 고침을 클릭하여 수집 진행률을 다시 로드할 수도 있습니다. 데이터 수집이 완료되면 언제든지 메트릭을 클릭하여 변칙 검색 결과를 확인할 수 있습니다.