미세 조정을 사용하여 모델 사용자 지정
Azure OpenAI Service를 사용하면 미세 조정이라는 프로세스를 사용하여 개인 데이터 세트에 맞게 모델을 조정할 수 있습니다. 이 사용자 지정 단계를 통해 다음을 제공하여 서비스를 최대한 활용할 수 있습니다.
- 프롬프트 엔지니어링에서 얻을 수 있는 것보다 더 높은 품질의 결과
- 모델의 최대 요청 컨텍스트 제한에 맞을 수 있는 것보다 더 많은 예제를 학습하는 기능입니다.
- 짧은 프롬프트로 인한 토큰 절약
- 특히 더 작은 모델을 사용하는 경우 대기 시간 요청이 낮습니다.
퓨샷 학습과 달리 미세 조정은 프롬프트에 맞는 것보다 더 많은 예를 학습하여 모델을 개선하므로 다양한 작업에서 더 나은 결과를 얻을 수 있습니다. 미세 조정은 기본 모델의 가중치를 튜닝하여 특정 작업의 성능을 개선하기 때문에 프롬프트에 많은 예나 지침을 포함할 필요가 없습니다. 따라서 전송되는 텍스트가 감소하고 모든 API 호출에서 처리되는 토큰이 감소하므로 비용이 절감되고 요청 대기 시간이 향상될 수 있습니다.
LoRA(낮은 순위 근사)를 사용하여 성능에 큰 영향을 주지 않으면서 복잡성을 줄이는 방식으로 모델을 미세 조정합니다. 이 메서드는 원래 상위 순위 매트릭스를 하위 순위 1로 근사화하여 감독 학습 단계 중에 더 작은 중요 매개 변수 하위 집합만 미세 조정하여 모델을 보다 관리 가능하고 효율적으로 만듭니다. 사용자의 경우 이는 다른 기술보다 더 빠르고 저렴한 학습을 제공합니다.
Azure AI Foundry 포털에는 두 가지 고유한 미세 조정 환경이 있습니다.
- 허브/프로젝트 뷰 - Azure OpenAI, Meta Llama, Microsoft Phi 등을 비롯한 여러 공급자의 미세 조정 모델을 지원합니다.
- Azure OpenAI 중심 뷰 - Azure OpenAI 모델의 미세 조정만 지원하지만 W&B(가중치 및 바이어스) 미리 보기 통합과 같은 추가 기능을 지원합니다.
Azure OpenAI 모델만 미세 조정하는 경우 Azure OpenAI 중심 미세 조정 환경으로 이동하여 https://oai.azure.com사용할 수 있는 것이 좋습니다.
필수 조건
- Azure OpenAI 미세 조정 가이드를 사용하는 경우를 읽어보세요.
- Azure 구독 체험 계정 만들기
- Azure OpenAI 모델의 미세 조정을 지원하는 지역에 있는 Azure OpenAI 리소스 지역 및 지원되는 기능별 사용 가능한 모델 목록은 모델 요약 표 및 지역 가용성을 확인하세요. 자세한 내용은 Azure OpenAI를 사용하여 리소스 만들기 및 모델 배포를 참조하세요.
- 액세스를 미세 조정하려면 Cognitive Services OpenAI 기여자가 필요합니다.
- 할당량을 보고 Azure AI Foundry 포털에서 모델을 배포할 수 있는 액세스 권한이 아직 없는 경우 추가 권한이 필요합니다.
모델
다음 모델은 미세 조정을 지원합니다.
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* 이 모델에 대한 미세 조정은 현재 공개 미리 보기로 제공됩니다.
또는 이전에 미세 조정된 모델을 base-model.ft-{jobid} 형식으로 미세 조정할 수 있습니다.
모델 페이지를 참조하여 현재 미세 조정을 지원하는 지역을 확인합니다.
Azure AI Foundry에 대한 워크플로 검토
잠시 시간을 내어 Azure AI Foundry 사용에 대한 미세 조정 워크플로를 검토합니다.
- 학습 및 유효성 검사 데이터를 준비합니다.
- Azure AI Foundry 포털에서 사용자 지정 모델 만들기 마법사를 사용하여 사용자 지정 모델을 학습합니다.
- 기본 모델을 선택합니다.
- 학습 데이터를 선택합니다.
- 필요에 따라 유효성 검사 데이터를 선택합니다.
- 필요에 따라 미세 조정 작업에 대한 작업 매개 변수 를 구성합니다.
- 선택한 내용을 검토하고 새로운 사용자 지정 모델을 학습시킵니다.
- 사용자 지정 미세 조정된 모델의 상태를 확인합니다.
- 사용할 사용자 지정 모델을 배포합니다.
- 사용자 지정 모델을 사용합니다.
- 필요에 따라 사용자 지정 모델의 성능 및 적합성을 분석합니다.
학습 및 유효성 검사 데이터 준비
학습 데이터 및 유효성 검사 데이터 세트는 원하는 모델 성능에 대한 입력 및 출력 예제로 구성됩니다.
모델 유형에 따라 학습 데이터의 형식이 다릅니다.
사용하는 학습 및 유효성 검사 데이터는 반드시 JSONL(JSON Lines) 문서로 서식을 지정해야 합니다. gpt-35-turbo(모든 버전), gpt-4, gpt-4o, 및 gpt-4o-mini의 경우 세부 조정 데이터 세트는 채팅 완료 API에서 사용되는 대화형 형식으로 서식을 지정해야 합니다.
gpt-4o-mini(2024-07-18) 모델을 미세 조정하는 단계별 연습은 Azure OpenAI 미세 조정 자습서를 참조하세요.
예제 파일 형식
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
다중 턴 채팅 파일 형식 Azure OpenAI
jsonl 학습 파일의 한 줄에 여러 번 대화하는 것도 지원됩니다. 특정 도우미 메시지에 대한 미세 조정을 건너뛰려면 선택적 weight 키 값 쌍을 추가합니다. 현재 weight는 0 또는 1로 설정할 수 있습니다.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
비전으로 채팅 완료
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
JSONL 형식 외에도, 학습 및 유효성 검사 데이터 파일은 UTF-8로 인코딩되어야 하고 BOM(바이트 순서 표시)을 포함해야 합니다. 파일 크기는 512MB 미만이어야 합니다.
학습 및 유효성 검사 데이터 세트 만들기
학습 사례가 많을수록 좋습니다. 10개 이상의 학습 예제가 없으면 미세 조정 작업이 진행되지 않지만 이러한 적은 수만으로는 모델 응답에 눈에 띄게 영향을 주지 않습니다. 성공하려면 수천 개는 아니더라도 수백 개의 학습 사례를 제공하는 것이 가장 좋습니다.
일반적으로 데이터 세트 크기가 두 배로 증가할 때마다 모델 품질이 선형적으로 증가할 수 있습니다. 그러나 저품질 예제는 성능에 부정적인 영향을 미칠 수 있습니다. 최고 품질의 예제에 대해서만 데이터 세트를 먼저 정리하지 않고 대량의 내부 데이터에서 모델을 학습하는 경우, 예상보다 훨씬 더 나쁜 성능을 발휘하는 모델이 될 수 있습니다.
사용자 지정 모델 만들기 마법사 사용
Azure AI Foundry는 사용자 지정 모델 만들기 마법사를 제공하므로 Azure 리소스에 대한 미세 조정된 모델을 대화형으로 만들고 학습할 수 있습니다.
Azure AI Foundry를 https://oai.azure.com/ 열고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. 로그인 워크플로 중에 적절한 디렉터리, Azure 구독 및 Azure OpenAI 리소스를 선택합니다.
Azure AI Foundry 포털에서 도구 미세 조정 창으로 이동하고 모델 미세 조정을 선택합니다.>


사용자 지정 모델 만들기 마법사가 열립니다.
기본 모델 선택
사용자 지정 모델을 만드는 첫 번째 단계는 기본 모델을 선택하는 것입니다. 기본 모델 창에서 사용자 지정 모델에 사용할 기본 모델을 선택할 수 있습니다. 선택하는 기본 모델은 모델의 성능과 비용 모두에 영향을 줍니다.
기본 모델 유형 드롭다운에서 기본 모델을 선택하고 다음을 선택하여 계속합니다.
사용 가능한 다음 기본 모델 중 하나로 사용자 지정 모델을 만들 수 있습니다.
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)또는 이전에 미세 조정된 모델을 base-model.ft-{jobid} 형식으로 미세 조정할 수 있습니다.

미세 조정할 수 있는 기본 모델에 대한 자세한 내용은 모델을 참조하세요.
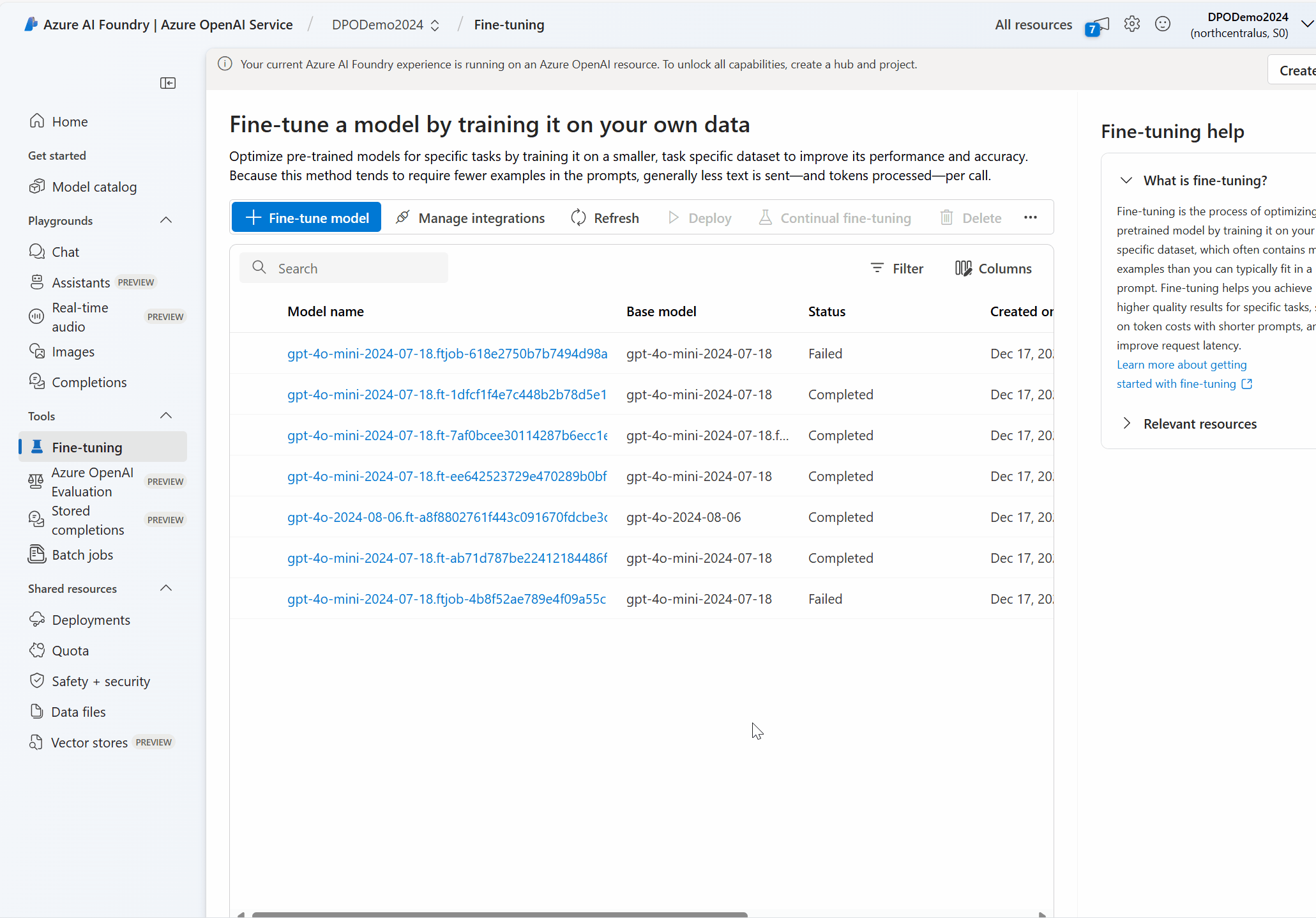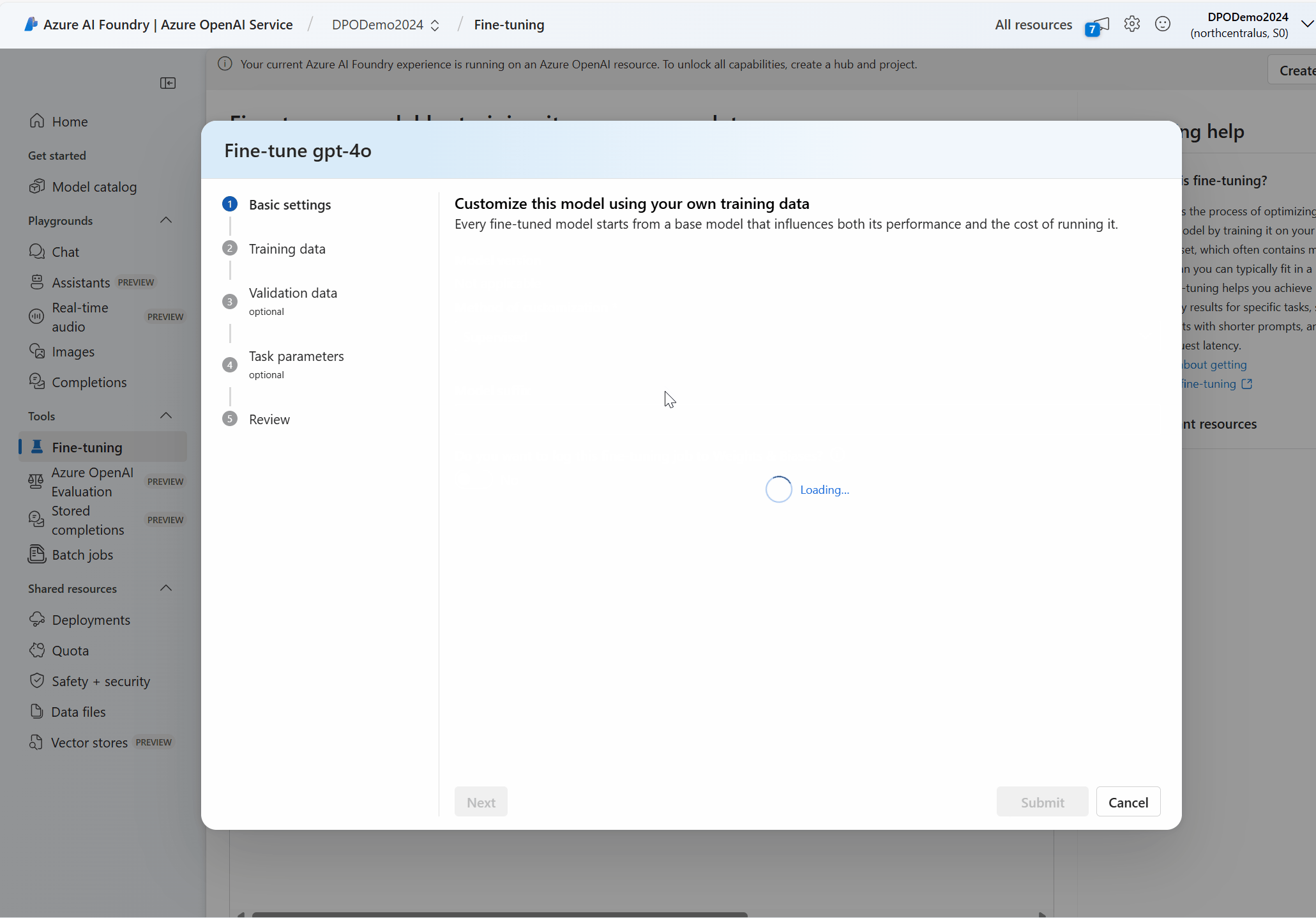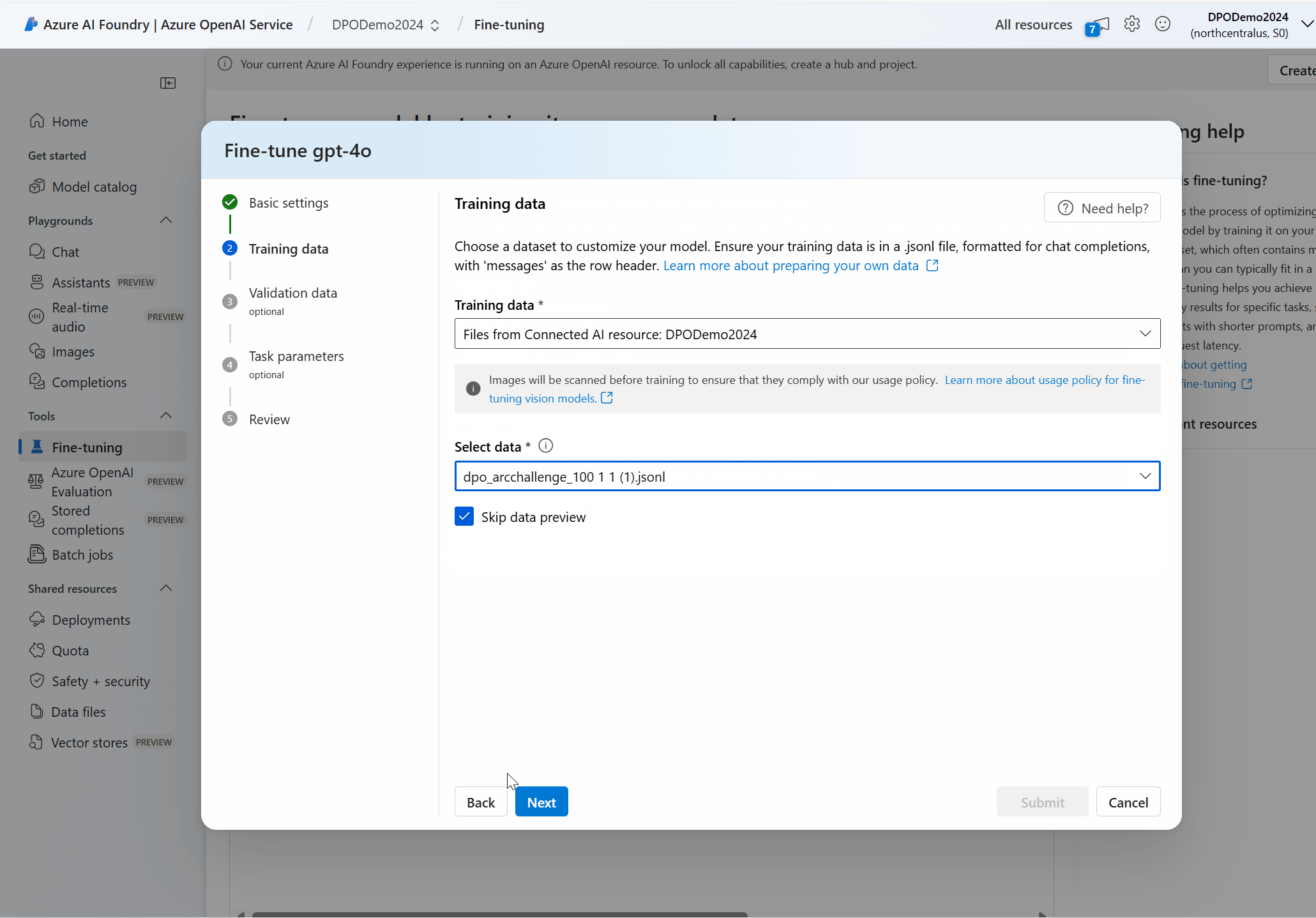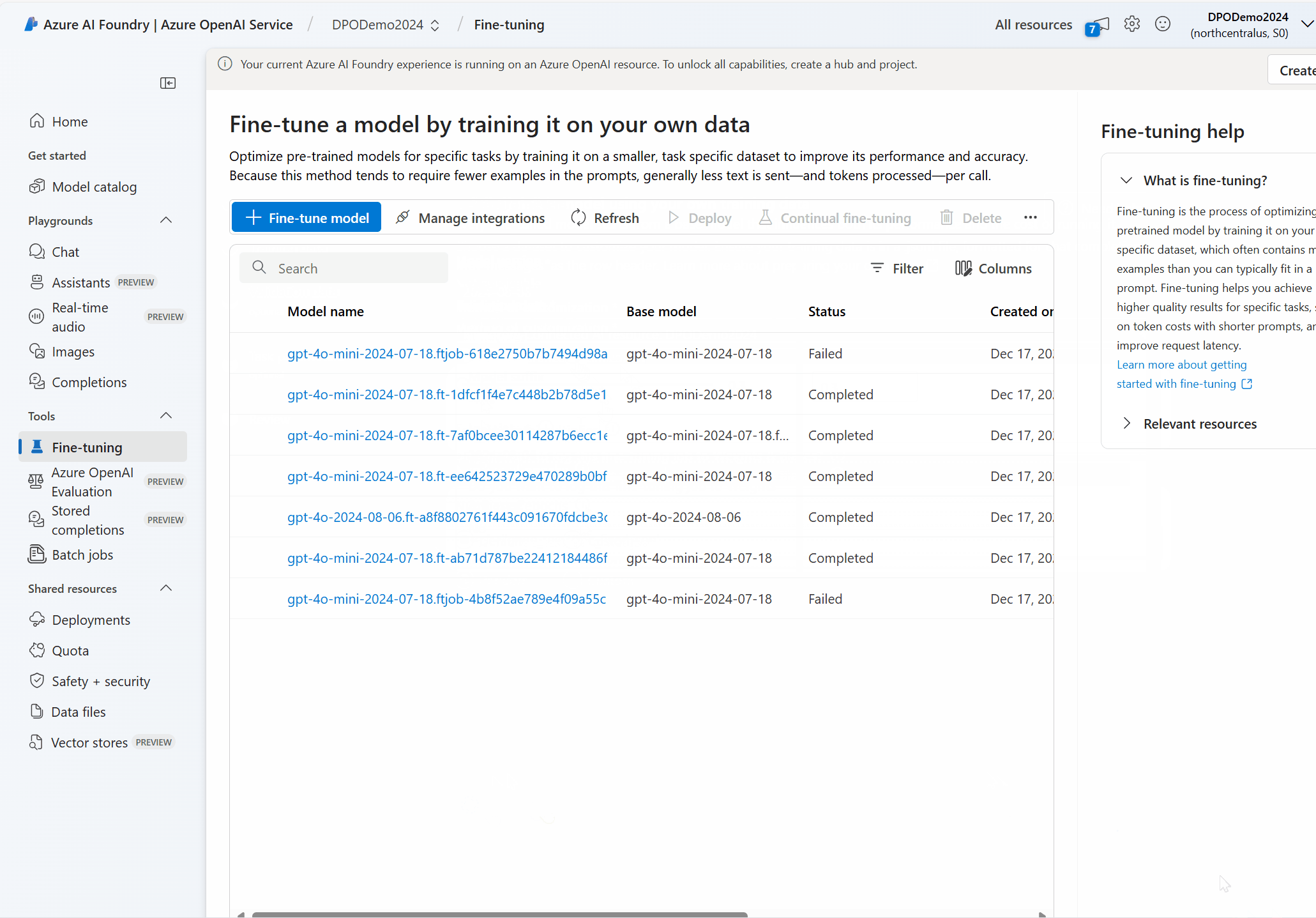
학습 데이터 선택
다음 단계는 모델을 사용자 지정할 때 사용할 준비된 기존 학습 데이터를 선택하거나 준비된 새 학습 데이터를 업로드하는 것입니다. 학습 데이터 창에는 이전에 업로드한 기존 데이터 세트가 표시되고, 새 학습 데이터를 업로드하는 옵션이 제공됩니다.

학습 데이터가 서비스에 이미 업로드된 경우 Azure OpenAI 연결에서 파일을 선택합니다.
- 표시된 드롭다운 목록에서 파일을 선택합니다.
새 학습 데이터를 업로드하려면 다음 옵션 중 하나를 사용합니다.
로컬 파일을 선택하여 로컬 파일에서 학습 데이터를 업로드합니다.
Azure Blob 또는 기타 공유 웹 위치를 선택하여 Azure Blob 또는 다른 공유 웹 위치에서 학습 데이터를 가져옵니다.
대용량 데이터 파일의 경우 Azure Blob 저장소에서 가져오는 것이 좋습니다. 요청이 원자성이어서 다시 시도하거나 다시 시작할 수 없기 때문에 대용량 파일은 멀티파트 양식을 통해 업로드할 때 불안정해질 수 있습니다. Azure Blob Storage에 대한 자세한 내용은 Azure Blob Storage란?을 참조하세요.
참고 항목
학습 데이터 파일은 JSONL 파일로 포맷되고 BOM(바이트 순서 표시)이 있는 UTF-8로 인코딩되어야 합니다. 파일 크기는 512MB 미만이어야 합니다.
로컬 파일에서 학습 데이터 업로드
다음 방법 중 하나를 사용하여 로컬 파일의 새 학습 데이터 세트를 서비스에 업로드할 수 있습니다.
학습 데이터 창의 클라이언트 영역으로 파일을 끌어서 놓은 다음, 파일 업로드를 선택합니다.
학습 데이터 창의 클라이언트 영역에서 파일 찾아보기를 선택하고 열기 대화 상자에서 업로드할 파일을 선택한 다음, 파일 업로드를 선택합니다.
학습 데이터 세트를 선택하고 업로드한 후 다음을 선택하여 계속합니다.

Azure Blob 저장소에서 학습 데이터 가져오기
파일의 이름과 위치를 입력하여 Azure Blob 또는 다른 공유 웹 위치에서 학습 데이터 세트를 가져올 수 있습니다.
파일의 파일 이름을 입력합니다.
파일 위치의 경우 Azure Blob URL, Azure Storage SAS(공유 액세스 서명) 또는 액세스 가능한 공유 웹 위치에 대한 기타 링크를 제공합니다.
가져오기를 선택하여 학습 데이터 세트를 서비스로 가져옵니다.
학습 데이터 세트를 선택하고 업로드한 후 다음을 선택하여 계속합니다.

유효성 검사 데이터 선택
다음 단계에서는 학습 프로세스에서 유효성 검사 데이터를 사용하도록 모델을 구성하는 옵션을 제공합니다. 유효성 검사 데이터를 사용하지 않으려는 경우 다음을 선택하고 모델에 대한 고급 옵션을 선택할 수 있습니다. 사용하려는 경우 유효성 검사 데이터 세트가 있으면 준비된 기존 유효성 검사 데이터를 선택하거나, 모델을 사용자 지정할 때 사용할 새로운 준비된 유효성 검사 데이터를 업로드할 수 있습니다.
유효성 검사 데이터 창에는 이전에 업로드한 기존 데이터 세트가 표시되고, 새 유효성 검사 데이터를 업로드할 수 있는 옵션이 제공됩니다.

유효성 검사 데이터가 서비스에 이미 업로드된 경우 데이터 세트 선택을 선택합니다.
- 유효성 검사 데이터 창에 표시된 목록에서 파일을 선택합니다.
새 유효성 검사 데이터를 업로드하려면 다음 옵션 중 하나를 사용합니다.
로컬 파일을 선택하여 로컬 파일에서 유효성 검사 데이터를 업로드합니다.
Azure Blob 또는 기타 공유 웹 위치를 선택하여 Azure Blob 또는 다른 공유 웹 위치에서 유효성 검사 데이터를 가져옵니다.
대용량 데이터 파일의 경우 Azure Blob 저장소에서 가져오는 것이 좋습니다. 요청이 원자성이어서 다시 시도하거나 다시 시작할 수 없기 때문에 대용량 파일은 멀티파트 양식을 통해 업로드할 때 불안정해질 수 있습니다.
참고 항목
학습 데이터 파일과 마찬가지로, 유효성 검사 파일은 JSONL 파일로 포맷되고 BOM(바이트 순서 표시)이 있는 UTF-8로 인코딩되어야 합니다. 파일 크기는 512MB 미만이어야 합니다.
로컬 파일에서 유효성 검사 데이터 업로드
다음 방법 중 하나를 사용하여 로컬 파일의 새 유효성 검사 데이터 세트를 서비스에 업로드할 수 있습니다.
유효성 검사 데이터 창의 클라이언트 영역으로 파일을 끌어서 놓은 다음, 파일 업로드를 선택합니다.
유효성 검사 데이터 창의 클라이언트 영역에서 파일 찾아보기를 선택하고 열기 대화 상자에서 업로드할 파일을 선택한 다음, 파일 업로드를 선택합니다.
유효성 검사 데이터 세트를 선택하고 업로드한 후 다음을 선택하여 계속합니다.

Azure Blob 저장소에서 유효성 검사 데이터 가져오기
파일의 이름과 위치를 입력하여 Azure Blob 또는 다른 공유 웹 위치에서 유효성 검사 데이터 세트를 가져올 수 있습니다.
파일의 파일 이름을 입력합니다.
파일 위치의 경우 Azure Blob URL, Azure Storage SAS(공유 액세스 서명) 또는 액세스 가능한 공유 웹 위치에 대한 기타 링크를 제공합니다.
가져오기를 선택하여 학습 데이터 세트를 서비스로 가져옵니다.
유효성 검사 데이터 세트를 선택하고 업로드한 후 다음을 선택하여 계속합니다.

작업 매개 변수 구성
사용자 지정 모델 만들기 마법사는 작업 매개 변수 창에서 미세 조정된 모델을 학습하기 위한 매개 변수를 보여 줍니다. 다음 매개 변수를 사용할 수 있습니다.
| 이름 | 타입 | 설명 |
|---|---|---|
batch_size |
정수 | 학습에 사용할 일괄 처리 크기입니다. 일괄 처리 크기는 단일 전진 및 후진 계산법을 학습하는 데 사용되는 학습 예의 수입니다. 일반적으로 일괄 처리 크기가 클수록 데이터 세트가 클수록 더 잘 작동하는 경향이 있습니다. 기본값과 이 속성의 최대값은 기본 모델과 관련이 있습니다. 일괄 처리 크기가 클수록 모델 매개 변수는 덜 자주 업데이트되지만 분산은 낮습니다. |
learning_rate_multiplier |
number | 학습에 사용할 학습 속도 승수입니다. 미세 조정 학습 속도는 사전 학습에 사용된 원래 학습 속도에 이 값을 곱한 값입니다. 학습률이 클수록 일괄 처리 크기가 클수록 성능이 더 좋은 경향이 있습니다. 0.02에서 0.2 사이의 값으로 실험하여 최상의 결과를 생성하는 값을 확인하는 것이 좋습니다. 학습률이 작을수록 과잉 맞춤을 방지하는 데 유용할 수 있습니다. |
n_epochs |
정수 | 모델을 학습할 Epoch의 수입니다. Epoch는 학습 데이터 세트를 통한 하나의 전체 주기를 나타냅니다. |
seed |
정수 | 시드는 작업의 재현성을 제어합니다. 동일한 시드 및 작업 매개 변수를 전달하면 동일한 결과가 생성되지만 드문 경우에 다를 수 있습니다. 시드를 지정하지 않으면 시드가 생성됩니다. |
Beta |
정수 | dpo 손실에 대한 온도 매개 변수(일반적으로 0.1~0.5 범위)입니다. 이렇게 하면 참조 모델에 얼마나 많은 주의를 기울여야 하는지 제어할 수 있습니다. 베타가 작을수록 모델이 참조 모델에서 멀어질수록 더 많이 허용됩니다. 베타가 작아질수록 참조 모델은 무시됩니다. |

기본값을 선택하여 미세 조정 작업에 기본값을 사용하거나 사용자 지정을 선택하여 하이퍼 매개 변수 값을 표시하고 편집합니다. 기본값을 선택하면 학습 데이터를 기반으로 알고리즘적으로 올바른 값을 결정합니다.
고급 옵션을 구성한 후에는 다음을 선택하여 선택한 내용을 검토하고 미세 조정된 모델을 학습시킵니다.
선택한 내용 검토 및 모델 학습
마법사의 검토 창에는 구성 선택에 대한 정보가 표시됩니다.

모델을 학습할 준비가 되면 학습 작업 시작을 선택하여 미세 조정 작업을 시작하고 모델 창으로 돌아갑니다.
사용자 지정 모델 상태 확인
모델 창에는 사용자 지정 모델 탭에 사용자 지정 모델에 대한 정보가 표시됩니다. 이 탭에는 사용자 지정 모델에 대한 미세 조정 작업의 상태 및 작업 ID 관련 정보가 포함됩니다. 작업이 완료되면 탭에 결과 파일의 파일 ID가 표시됩니다. 모델 학습 작업에 대한 업데이트된 상태를 보려면 새로 고침을 선택해야 할 수 있습니다.

미세 조정 작업을 시작한 후 완료하는 데 시간이 걸릴 수 있습니다. 사용자의 작업이 시스템의 다른 작업 뒤에 대기 중일 수 있습니다. 모델 및 데이터 세트 크기에 따라 모델을 학습하는 데 몇 분 또는 몇 시간이 걸릴 수 있습니다.
다음은 모델 창에서 수행할 수 있는 몇 가지 작업입니다.
사용자 지정 모델 탭의 상태 열에서 사용자 지정 모델에 대한 미세 조정 작업의 상태 확인합니다.
모델 이름 열에서 모델 이름을 선택하여 사용자 지정 모델에 대한 자세한 정보를 봅니다. 작업에 사용되는 미세 조정 작업, 학습 결과, 학습 이벤트 및 하이퍼 매개 변수의 상태를 확인할 수 있습니다.
학습 파일 다운로드를 선택하여 모델에 사용한 학습 데이터를 다운로드합니다.
결과 다운로드를 선택하여 모델의 미세 조정 작업에 연결된 결과 파일을 다운로드하고 사용자 지정 모델의 학습 및 유효성 검사 성능을 분석할 수도 있습니다.
새로 고침을 선택하여 페이지의 정보를 업데이트합니다.
검사점
각 학습 epoch가 완료되면 검사점이 생성됩니다. 검사점은 후속 미세 조정 작업을 위한 대상 모델로 배포 및 사용할 수 있는 모델의 완전한 기능 버전입니다. 검사점은 과잉 맞춤이 발생하기 전에 모델의 스냅샷을 제공할 수 있으므로 특히 유용할 수 있습니다. 미세 조정 작업이 완료되면 배포할 수 있는 최신 모델 버전 3개가 제공됩니다.
안전 평가 GPT-4, GPT-4o 및 GPT-4o-mini 미세 조정 - 공개 미리 보기
GPT-4o, GPT-4o-mini 및 GPT-4는 사용자의 요구 사항에 맞춰 미세 조정할 수 있는 가장 발전된 고급 모델입니다. 일반적으로 Azure OpenAI 모델과 마찬가지로 미세 조정된 모델의 고급 기능에는 유해한 콘텐츠, 조작, 인간과 유사한 동작, 개인 정보 보호 문제 등과 관련된 책임감 있는 AI가 해결해야 할 문제가 증가합니다. 책임감 있는 AI 사례 및 투명성 고지에서 위험, 기능, 제한 사항에 대해 자세히 알아봅니다. 미세 조정된 고급 모델과 관련된 위험을 완화하기 위해, 미세 조정된 모델의 학습 및 출력에서 유해한 콘텐츠를 감지하고 방지하는 데 도움이 되는 추가 평가 단계를 구현했습니다. 이러한 단계는 Microsoft의 책임감 있는 AI 표준 및 Azure OpenAI 서비스 콘텐츠 필터링에 근거합니다.
- 평가는 전용 고객별 프라이빗 작업 영역에서 수행됩니다.
- 평가 엔드포인트는 Azure OpenAI 리소스와 동일한 지역에 있습니다.
- 학습 데이터는 평가 수행과 관련하여 저장되지 않으며, 최종 모델 평가(배포 가능 또는 배포 불가능)만 유지됩니다.
GPT-4o GPT-4o-mini 및 GPT-4 미세 조정된 모델 평가 필터는 미리 정의된 임계값으로 설정되며 고객이 수정할 수 없습니다. 또한 사용자가 만들었을 수 있는 사용자 지정 콘텐츠 필터링 구성에 연결되지 않습니다.
데이터 평가
학습이 시작되기 전에 잠재적으로 유해한 콘텐츠(폭력, 성적인 내용, 혐오, 공정성, 자해 등, 여기에서 범주 정의 참조)가 있는지 데이터를 평가합니다. 지정된 심각도 수준 이상으로 유해한 콘텐츠가 감지되면 학습 작업이 실패하고 실패 범주를 알리는 메시지가 표시됩니다.
샘플 메시지:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
학습 데이터는 미세 조정 기능을 제공하는 일환으로 데이터 가져오기 작업 내에서 자동으로 평가됩니다.
학습 데이터의 유해한 콘텐츠가 감지되어 미세 조정 작업이 실패하는 경우 요금이 청구되지 않습니다.
모델 평가
학습이 완료되었지만 미세 조정된 모델을 배포할 수 있기 전에, 결과 모델은 Azure의 기본 제공 위험 및 안전 메트릭을 사용하여 잠재적으로 유해한 대응에 대해 평가됩니다. 기본 대형 언어 모델에 사용하는 테스트와 동일한 접근 방식을 사용하여 평가 기능은 지정된 유해한 콘텐츠 범주(폭력, 성적인 내용, 혐오, 공정성, 자해)를 사용하여 유해한 콘텐츠를 출력할 가능성을 평가하기 위해 미세 조정된 모델과의 대화를 시뮬레이션합니다.
허용 가능한 비율 이상으로 유해한 것으로 감지된 콘텐츠를 포함하는 출력을 모델이 생성하는 것으로 확인되면 배포에 해당 모델을 사용할 수 없다는 알림이 표시되고 특정 범주의 피해에 대한 정보가 표시됩니다.
샘플 메시지:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.

데이터 평가와 마찬가지로 모델은 미세 조정 기능 제공의 일환으로 미세 조정 작업 내에서 자동으로 평가됩니다. 결과 평가(배포 가능 또는 배포 불가능)만 서비스에서 기록합니다. 모델 출력에서 유해한 콘텐츠가 감지되어 미세 조정된 모델의 배포가 실패하는 경우 학습 실행에 대한 요금이 청구되지 않습니다.
미세 조정된 모델 배포
미세 조정 작업이 성공하면 모델 창에서 사용자 지정 모델을 배포할 수 있습니다. 완료 호출에 사용할 수 있도록 사용자 지정 모델을 배포해야 합니다.
Important
사용자 지정된 모델을 배포한 후 언제든지 배포가 15일 이상 비활성 상태로 유지되면 배포가 삭제됩니다. 모델이 배포된 지 15일이 넘었고 연속 15일 동안 모델에 대한 완료 또는 채팅 완료 호출이 이루어지지 않은 경우 맞춤형 모델 배포는 비활성 상태입니다.
비활성 배포를 삭제해도 기본 사용자 지정 모델은 삭제되거나 영향을 받지 않으며 사용자 지정 모델은 언제든지 다시 배포될 수 있습니다. Azure OpenAI Service 가격 책정에 설명된 대로 배포되는 각 사용자 지정(세밀 조정) 모델에는 완료 또는 채팅 완료 호출이 모델에 대해 수행되는지 여부에 관계없이 시간당 호스팅 비용이 발생합니다. Azure OpenAI를 사용하여 비용을 계획하고 관리하는 방법에 대한 자세한 내용은 Azure OpenAI Service 비용 관리 계획의 지침을 참조하세요.
참고 항목
하나의 사용자 지정 모델에는 하나의 배포만 허용됩니다. 이미 배포된 사용자 지정 모델을 선택하면 오류 메시지가 표시됩니다.
사용자 지정 모델을 배포하려면 배포할 사용자 지정 모델을 선택한 다음, 모델 배포를 선택합니다.

모델 배포 대화 상자가 열립니다. 대화 상자의 배포 이름에 이름을 입력한 다음, 만들기를 선택하여 사용자 지정 모델의 배포를 시작합니다.

Azure AI Foundry 포털의 배포 창에서 배포 진행률을 모니터링할 수 있습니다.
지역 간 배포
미세 조정은 모델이 원래 미세 조정된 지역과 다른 지역에 미세 조정된 모델을 배포하도록 지원합니다. 다른 구독/지역에 배포할 수도 있습니다.
유일한 제한 사항은 새 지역이 미세 조정도 지원해야 하며, 교차 구독을 배포할 때 배포에 대한 권한 부여 토큰을 생성하는 계정에는 원본 및 대상 구독 모두에 대한 액세스 권한이 있어야 한다는 것입니다.
구독/지역 간 배포는 Python 또는 REST를 통해 수행할 수 있습니다.
배포된 사용자 지정 모델 사용
사용자 지정 모델이 배포되었으면 배포된 다른 모델처럼 사용할 수 있습니다. Azure AI Foundry의 플레이그라운드를 사용하여 새 배포를 실험할 수 있습니다. 배포된 다른 모델과 마찬가지로 사용자 지정 모델에서 temperature 및 max_tokens와 같은 동일한 매개 변수를 계속 사용할 수 있습니다. 미세 조정된 babbage-002 모델 및 davinci-002 모델의 경우 완료 플레이그라운드 및 완료 API를 사용합니다. 미세 조정된 gpt-35-turbo-0613 모델의 경우 채팅 플레이그라운드 및 채팅 완료 API를 사용합니다.

사용자 지정 모델 분석
미세 조정 작업이 완료되면 Azure OpenAI는 results.csv라는 결과 파일을 각 미세 조정 작업에 연결합니다. 이 결과 파일을 사용하여 사용자 지정 모델의 학습 및 유효성 검사 성능을 분석할 수 있습니다. 결과 파일의 파일 ID는 Azure AI Foundry에 대한 모델 창의 결과 파일 ID 열에 있는 각 사용자 지정 모델에 대해 나열됩니다. 파일 ID를 사용하여 Azure AI Foundry의 데이터 파일 창에서 결과 파일을 식별하고 다운로드할 수 있습니다.
결과 파일은 미세 조정 작업에서 수행하는 각 학습 단계에 대한 머리글 행과 행을 포함하는 CSV 파일입니다. 결과 파일에는 다음 열이 포함되어 있습니다.
| 열 이름 | 설명 |
|---|---|
step |
학습 단계의 수입니다. 학습 단계는 학습 데이터 일괄 처리에 대한 정방향 및 역방향 단일 패스를 나타냅니다. |
train_loss |
학습 일괄 처리의 손실입니다. |
train_mean_token_accuracy |
모델에서 올바르게 예측한 학습 일괄 처리의 토큰 비율입니다. 예를 들어 일괄 처리 크기가 3으로 설정되고 데이터에 완료 [[1, 2], [0, 5], [4, 2]]가 포함된 경우 모델이 [[1, 1], [0, 5], [4, 2]]를 예측하면 이 값은 0.83(5/6)으로 설정됩니다. |
valid_loss |
유효성 검사 일괄 처리의 손실입니다. |
validation_mean_token_accuracy |
모델에서 올바르게 예측한 유효성 검사 일괄 처리의 토큰 비율입니다. 예를 들어 일괄 처리 크기가 3으로 설정되고 데이터에 완료 [[1, 2], [0, 5], [4, 2]]가 포함된 경우 모델이 [[1, 1], [0, 5], [4, 2]]를 예측하면 이 값은 0.83(5/6)으로 설정됩니다. |
full_valid_loss |
각 epoch의 끝에서 계산된 유효성 검사 손실입니다. 학습이 잘되면 손실이 줄어들 것입니다. |
full_valid_mean_token_accuracy |
각 epoch의 끝에서 계산된 유효한 평균 토큰 정확도입니다. 학습이 잘 진행되면 토큰 정확도가 높아져야 합니다. |
azure AI Foundry 포털에서 results.csv 파일의 데이터를 플롯으로 볼 수도 있습니다. 학습된 모델에 대한 링크를 선택하면 손실, 평균 토큰 정확도 및 토큰 정확도의 세 가지 차트가 표시됩니다. 유효성 검사 데이터를 제공한 경우 두 데이터 세트가 모두 동일한 플롯에 나타납니다.
시간이 지남에 따라 손실이 감소하고 정확도가 증가하는지 확인합니다. 학습 데이터와 유효성 검사 데이터 사이에 차이가 있는 경우 이는 과잉 맞춤을 의미할 수 있습니다. 더 적은 epoch 또는 더 작은 학습 속도 승수를 사용하여 학습을 시도합니다.
배포, 사용자 지정 모델 및 학습 파일 정리
사용자 지정 모델을 완료했으면 배포 및 모델을 삭제해도 됩니다. 원한다면 서비스에 업로드한 학습 및 유효성 검사 파일까지 삭제해도 됩니다.
모델 배포 삭제
Important
사용자 지정된 모델을 배포한 후 언제든지 배포가 15일 이상 비활성 상태로 유지되면 배포가 삭제됩니다. 모델이 배포된 지 15일이 넘었고 연속 15일 동안 모델에 대한 완료 또는 채팅 완료 호출이 이루어지지 않은 경우 맞춤형 모델 배포는 비활성 상태입니다.
비활성 배포를 삭제해도 기본 사용자 지정 모델은 삭제되거나 영향을 받지 않으며 사용자 지정 모델은 언제든지 다시 배포될 수 있습니다. Azure OpenAI Service 가격 책정에 설명된 대로 배포되는 각 사용자 지정(세밀 조정) 모델에는 완료 또는 채팅 완료 호출이 모델에 대해 수행되는지 여부에 관계없이 시간당 호스팅 비용이 발생합니다. Azure OpenAI를 사용하여 비용을 계획하고 관리하는 방법에 대한 자세한 내용은 Azure OpenAI Service 비용 관리 계획의 지침을 참조하세요.
Azure AI Foundry 포털의 배포 창에서 사용자 지정 모델에 대한 배포 를 삭제할 수 있습니다. 삭제할 배포를 선택한 다음, 삭제를 선택하여 배포를 삭제합니다.
사용자 지정 모델 삭제
Azure AI Foundry 포털의 모델 창에서 사용자 지정 모델을 삭제할 수 있습니다. 사용자 지정 모델 탭에서 삭제할 사용자 지정 모델을 선택한 다음, 삭제를 선택하여 사용자 지정 모델을 삭제합니다.
참고 항목
기존 배포가 있는 사용자 지정 모델은 삭제할 수 없습니다. 사용자 지정 모델을 삭제하려면 모델 배포부터 삭제해야 합니다.
학습 파일 삭제
학습을 위해 업로드한 학습 및 유효성 검사 파일과 학습 중에 생성된 결과 파일은 Azure AI Foundry 포털의 관리>데이터 파일 창에서 선택적으로 삭제할 수 있습니다. 삭제할 파일을 선택한 다음, 삭제를 선택하여 파일을 삭제합니다.
연속 미세 조정
미세 조정된 모델을 만든 후에는 추가 미세 조정을 통해 시간이 지남에 따라 모델을 계속 구체화할 수 있습니다. 지속적인 미세 조정은 이미 미세 조정된 모델을 기본 모델로 선택하고 새로운 학습 예제 집합에서 추가로 미세 조정하는 반복적인 프로세스입니다.
이전에 미세 조정한 모델에 대해 미세 조정을 수행하려면 사용자 지정 모델 만들기에 설명된 것과 동일한 프로세스를 사용하지만 일반 기본 모델의 이름을 지정하는 대신 이미 미세 조정된 모델을 지정합니다. 사용자 지정 미세 조정된 모델은 gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7과(와) 같습니다.

또한 suffix 매개 변수를 포함하여 미세 조정된 모델의 여러 반복을 더 쉽게 구분할 수 있도록 하는 것이 좋습니다. suffix은(는) 문자열을 사용하고 미세 조정된 모델을 식별하도록 설정됩니다. OpenAI Python API를 사용하면 미세 조정된 모델 이름에 추가될 최대 18자의 문자열이 지원됩니다.







필수 조건
- Azure OpenAI 미세 조정 가이드를 사용하는 경우를 읽어보세요.
- Azure 구독 체험 계정 만들기
- Azure OpenAI 리소스 자세한 내용은 Azure OpenAI를 사용하여 리소스 만들기 및 모델 배포를 참조하세요.
- 다음 Python 라이브러리:
os,json,requests,openai. - OpenAI Python 라이브러리는 버전 0.28.1 이상이어야 합니다.
- 액세스를 미세 조정하려면 Cognitive Services OpenAI 기여자가 필요합니다.
- 할당량을 보고 Azure AI Foundry 포털에서 모델을 배포할 수 있는 액세스 권한이 아직 없는 경우 추가 권한이 필요합니다.
모델
다음 모델은 미세 조정을 지원합니다.
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* 이 모델에 대한 미세 조정은 현재 공개 미리 보기로 제공됩니다.
또는 이전에 미세 조정한 모델을 base-model.ft-{jobid} 형식으로 미세 조정할 수 있습니다.
모델 페이지를 참조하여 현재 미세 조정을 지원하는 지역을 확인합니다.
Python SDK에 대한 워크플로 검토
잠시 시간을 내어 Azure OpenAI에서 Python SDK를 사용하기 위한 미세 조정 워크플로를 검토하세요.
- 학습 및 유효성 검사 데이터를 준비합니다.
- 기본 모델을 선택합니다.
- 학습 데이터를 업로드합니다.
- 새 사용자 지정 모델을 학습시킵니다.
- 사용자 지정 모델의 상태를 확인합니다.
- 사용할 사용자 지정 모델을 배포합니다.
- 사용자 지정 모델을 사용합니다.
- 필요에 따라 사용자 지정 모델의 성능 및 적합성을 분석합니다.
학습 및 유효성 검사 데이터 준비
학습 데이터 및 유효성 검사 데이터 세트는 원하는 모델 성능에 대한 입력 및 출력 예제로 구성됩니다.
모델 유형에 따라 학습 데이터의 형식이 다릅니다.
사용하는 학습 및 유효성 검사 데이터는 반드시 JSONL(JSON Lines) 문서로 서식을 지정해야 합니다. gpt-35-turbo-0613의 경우 세부 조정 데이터 세트는 채팅 완료 API에서 사용하는 대화 형식으로 서식을 지정해야 합니다.
gpt-35-turbo-0613 미세 조정을 단계별로 연습하려면 Azure OpenAI 미세 조정 자습서를 참조하세요.
예제 파일 형식
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
멀티 턴 채팅 파일 형식
jsonl 학습 파일의 한 줄에 여러 번 대화하는 것도 지원됩니다. 특정 도우미 메시지에 대한 미세 조정을 건너뛰려면 선택적 weight 키 값 쌍을 추가합니다. 현재 weight는 0 또는 1로 설정할 수 있습니다.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
비전으로 채팅 완료
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
JSONL 형식 외에도, 학습 및 유효성 검사 데이터 파일은 UTF-8로 인코딩되어야 하고 BOM(바이트 순서 표시)을 포함해야 합니다. 파일 크기는 512MB 미만이어야 합니다.
학습 및 유효성 검사 데이터 세트 만들기
학습 사례가 많을수록 좋습니다. 10개 이상의 학습 예제가 없으면 미세 조정 작업이 진행되지 않지만 이러한 적은 수만으로는 모델 응답에 눈에 띄게 영향을 주지 않습니다. 성공하려면 수천 개는 아니더라도 수백 개의 학습 사례를 제공하는 것이 가장 좋습니다.
일반적으로 데이터 세트 크기가 두 배로 증가할 때마다 모델 품질이 선형적으로 증가할 수 있습니다. 그러나 저품질 예제는 성능에 부정적인 영향을 미칠 수 있습니다. 최고 품질의 예제에 대해서만 데이터 세트를 먼저 정리하지 않고 대량의 내부 데이터에서 모델을 학습하는 경우, 예상보다 훨씬 더 나쁜 성능을 발휘하는 모델이 될 수 있습니다.
학습 데이터 업로드
다음 단계는 모델을 사용자 지정할 때 사용할 준비된 기존 학습 데이터를 선택하거나 준비된 새 학습 데이터를 업로드하는 것입니다. 학습 데이터를 준비한 후에는 파일을 서비스에 업로드할 수 있습니다. 학습 데이터를 업로드하는 두 가지 방법이 있습니다.
대용량 데이터 파일의 경우 Azure Blob 저장소에서 가져오는 것이 좋습니다. 요청이 원자성이어서 다시 시도하거나 다시 시작할 수 없기 때문에 대용량 파일은 멀티파트 양식을 통해 업로드할 때 불안정해질 수 있습니다. Azure Blob 스토리지에 대한 자세한 내용은 Azure Blob 스토리지란?을 참조하세요.
참고 항목
학습 데이터 파일은 JSONL 파일로 포맷되고 BOM(바이트 순서 표시)이 있는 UTF-8로 인코딩되어야 합니다. 파일 크기는 512MB 미만이어야 합니다.
다음 Python 예제에서는 Python SDK를 사용하여 로컬 학습 및 유효성 검사 파일을 업로드하고 반환된 파일 ID를 검색합니다.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
사용자 지정 모델 만들기
학습 및 유효성 검사 파일을 업로드하면 미세 조정 작업을 시작할 준비가 된 것입니다.
다음 Python 코드는 Python SDK를 사용하여 새 미세 조정 작업을 만드는 방법의 예를 보여줍니다.
이 예에서는 시드 매개 변수도 전달합니다. 시드는 작업의 재현성을 제어합니다. 동일한 시드 및 작업 매개 변수를 전달하면 동일한 결과가 생성되지만 드문 경우에 다를 수 있습니다. 시드를 지정하지 않으면 시드가 생성됩니다.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
또한 하이퍼 매개 변수와 같은 추가 선택적 매개 변수를 전달하여 미세 조정 프로세스를 보다 잘 제어할 수 있습니다. 초기 학습의 경우 이러한 매개 변수를 지정하지 않고 존재하는 자동 기본값을 사용하는 것이 좋습니다.
미세 조정을 위해 현재 지원되는 하이퍼 매개 변수는 다음과 같습니다.
| 이름 | 타입 | 설명 |
|---|---|---|
batch_size |
정수 | 학습에 사용할 일괄 처리 크기입니다. 일괄 처리 크기는 단일 전진 및 후진 계산법을 학습하는 데 사용되는 학습 예의 수입니다. 일반적으로 일괄 처리 크기가 클수록 데이터 세트가 클수록 더 잘 작동하는 경향이 있습니다. 기본값과 이 속성의 최대값은 기본 모델과 관련이 있습니다. 일괄 처리 크기가 클수록 모델 매개 변수는 덜 자주 업데이트되지만 분산은 낮습니다. |
learning_rate_multiplier |
number | 학습에 사용할 학습 속도 승수입니다. 미세 조정 학습 속도는 사전 학습에 사용된 원래 학습 속도에 이 값을 곱한 값입니다. 학습률이 클수록 일괄 처리 크기가 클수록 성능이 더 좋은 경향이 있습니다. 0.02에서 0.2 사이의 값으로 실험하여 최상의 결과를 생성하는 값을 확인하는 것이 좋습니다. 학습 속도가 작을수록 과잉 맞춤을 방지하는 데 유용할 수 있습니다. |
n_epochs |
정수 | 모델을 학습할 Epoch의 수입니다. Epoch는 학습 데이터 세트를 통한 하나의 전체 주기를 나타냅니다. |
seed |
정수 | 시드는 작업의 재현성을 제어합니다. 동일한 시드 및 작업 매개 변수를 전달하면 동일한 결과가 생성되지만 드문 경우에 다를 수 있습니다. 시드를 지정하지 않으면 시드가 생성됩니다. |
OpenAI Python API의 1.x 버전으로 사용자 지정 하이퍼 매개 변수를 설정하려면 다음을 수행합니다.
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01" # This API version or later is required to access fine-tuning for turbo/babbage-002/davinci-002
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
미세 조정 작업 상태 확인
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
미세 조정 이벤트 나열
학습 중에 생성된 개별 미세 조정 이벤트를 검사하려면 다음을 수행합니다.
이 명령을 실행하려면 OpenAI 클라이언트 라이브러리를 pip install openai --upgrade를 사용하여 최신 버전으로 업그레이드해야 할 수도 있습니다.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
검사점
각 학습 epoch가 완료되면 검사점이 생성됩니다. 검사점은 후속 미세 조정 작업을 위한 대상 모델로 배포 및 사용할 수 있는 모델의 완전한 기능 버전입니다. 검사점은 과잉 맞춤이 발생하기 전에 모델의 스냅샷을 제공할 수 있으므로 특히 유용할 수 있습니다. 미세 조정 작업이 완료되면 배포할 수 있는 최신 모델 버전 3개가 제공됩니다. 최종 epoch는 미세 조정된 모델로 표시되며 이전 두 epoch는 검사점으로 사용할 수 있습니다.
list checkpoints 명령을 실행하여 개별 미세 조정 작업과 관련된 검사점 목록을 검색할 수 있습니다.
이 명령을 실행하려면 OpenAI 클라이언트 라이브러리를 pip install openai --upgrade를 사용하여 최신 버전으로 업그레이드해야 할 수도 있습니다.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
안전 평가 GPT-4, GPT-4o, GPT-4o-mini 미세 조정 - 공개 미리 보기
GPT-4o, GPT-4o-mini 및 GPT-4는 사용자의 요구 사항에 맞춰 미세 조정할 수 있는 가장 발전된 고급 모델입니다. 일반적으로 Azure OpenAI 모델과 마찬가지로 미세 조정된 모델의 고급 기능에는 유해한 콘텐츠, 조작, 인간과 유사한 동작, 개인 정보 보호 문제 등과 관련된 책임감 있는 AI가 해결해야 할 문제가 증가합니다. 책임감 있는 AI 사례 및 투명성 고지에서 위험, 기능, 제한 사항에 대해 자세히 알아봅니다. 미세 조정된 고급 모델과 관련된 위험을 완화하기 위해, 미세 조정된 모델의 학습 및 출력에서 유해한 콘텐츠를 감지하고 방지하는 데 도움이 되는 추가 평가 단계를 구현했습니다. 이러한 단계는 Microsoft의 책임감 있는 AI 표준 및 Azure OpenAI 서비스 콘텐츠 필터링에 근거합니다.
- 평가는 전용 고객별 프라이빗 작업 영역에서 수행됩니다.
- 평가 엔드포인트는 Azure OpenAI 리소스와 동일한 지역에 있습니다.
- 학습 데이터는 평가 수행과 관련하여 저장되지 않으며, 최종 모델 평가(배포 가능 또는 배포 불가능)만 유지됩니다.
GPT-4o GPT-4o-mini 및 GPT-4 미세 조정된 모델 평가 필터는 미리 정의된 임계값으로 설정되며 고객이 수정할 수 없습니다. 또한 사용자가 만들었을 수 있는 사용자 지정 콘텐츠 필터링 구성에 연결되지 않습니다.
데이터 평가
학습이 시작되기 전에 잠재적으로 유해한 콘텐츠(폭력, 성적인 내용, 혐오, 공정성, 자해 등, 여기에서 범주 정의 참조)가 있는지 데이터를 평가합니다. 지정된 심각도 수준 이상으로 유해한 콘텐츠가 감지되면 학습 작업이 실패하고 실패 범주를 알리는 메시지가 표시됩니다.
샘플 메시지:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
학습 데이터는 미세 조정 기능을 제공하는 일환으로 데이터 가져오기 작업 내에서 자동으로 평가됩니다.
학습 데이터의 유해한 콘텐츠가 감지되어 미세 조정 작업이 실패하는 경우 요금이 청구되지 않습니다.
모델 평가
학습이 완료되었지만 미세 조정된 모델을 배포할 수 있기 전에, 결과 모델은 Azure의 기본 제공 위험 및 안전 메트릭을 사용하여 잠재적으로 유해한 대응에 대해 평가됩니다. 기본 대형 언어 모델에 사용하는 테스트와 동일한 접근 방식을 사용하여 평가 기능은 지정된 유해한 콘텐츠 범주(폭력, 성적인 내용, 혐오, 공정성, 자해)를 사용하여 유해한 콘텐츠를 출력할 가능성을 평가하기 위해 미세 조정된 모델과의 대화를 시뮬레이션합니다.
허용 가능한 비율 이상으로 유해한 것으로 감지된 콘텐츠를 포함하는 출력을 모델이 생성하는 것으로 확인되면 배포에 해당 모델을 사용할 수 없다는 알림이 표시되고 특정 범주의 피해에 대한 정보가 표시됩니다.
샘플 메시지:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
데이터 평가와 마찬가지로 모델은 미세 조정 기능 제공의 일환으로 미세 조정 작업 내에서 자동으로 평가됩니다. 결과 평가(배포 가능 또는 배포 불가능)만 서비스에서 기록합니다. 모델 출력에서 유해한 콘텐츠가 감지되어 미세 조정된 모델의 배포가 실패하는 경우 학습 실행에 대한 요금이 청구되지 않습니다.
미세 조정된 모델 배포
미세 조정 작업이 성공하면 응답 본문에 있는 fine_tuned_model 변수 값이 사용자 지정 모델의 이름으로 설정됩니다. 이제 모델 나열 API에서 모델을 검색할 수도 있습니다. 그러나 사용자 지정 모델이 배포되기 전에는 사용자 지정 모델에 대한 완료 호출을 실행할 수 없습니다. 완료 호출에 사용할 수 있도록 사용자 지정 모델을 배포해야 합니다.
Important
사용자 지정된 모델을 배포한 후 언제든지 배포가 15일 이상 비활성 상태로 유지되면 배포가 삭제됩니다. 모델이 배포된 지 15일이 넘었고 연속 15일 동안 모델에 대한 완료 또는 채팅 완료 호출이 이루어지지 않은 경우 맞춤형 모델 배포는 비활성 상태입니다.
비활성 배포를 삭제해도 기본 사용자 지정 모델은 삭제되거나 영향을 받지 않으며 사용자 지정 모델은 언제든지 다시 배포될 수 있습니다. Azure OpenAI Service 가격 책정에 설명된 대로 배포되는 각 사용자 지정(세밀 조정) 모델에는 완료 또는 채팅 완료 호출이 모델에 대해 수행되는지 여부에 관계없이 시간당 호스팅 비용이 발생합니다. Azure OpenAI를 사용하여 비용을 계획하고 관리하는 방법에 대한 자세한 내용은 Azure OpenAI Service 비용 관리 계획의 지침을 참조하세요.
Azure AI Foundry 또는 Azure CLI를 사용하여 사용자 지정 모델을 배포할 수도 있습니다.
참고 항목
하나의 사용자 지정 모델에는 하나의 배포만 허용됩니다. 이미 배포된 사용자 지정 모델을 선택하면 오류가 발생합니다.
이전 SDK 명령과 달리 별도의 권한 부여, 다른 API 경로 및 다른 API 버전이 필요한 컨트롤 플레인 API를 사용하여 배포를 수행해야 합니다.
| 변수 | 정의 |
|---|---|
| token | 권한 부여 토큰을 생성하는 방법에는 여러 가지가 있습니다. 초기 테스트를 위한 가장 쉬운 방법은 Azure Portal에서 Cloud Shell을 시작하는 것입니다. 그런 다음 az account get-access-token를 실행합니다. 이 토큰을 API 테스트를 위한 임시 권한 부여 토큰으로 사용할 수 있습니다. 새 환경 변수에 저장하는 것이 좋습니다. |
| 구독 | 연결된 Azure OpenAI 리소스에 대한 구독 ID. |
| resource_group | Azure OpenAI 리소스의 리소스 그룹 이름. |
| resource_name | Azure OpenAI 리소스 이름. |
| model_deployment_name | 미세 조정된 새 모델 배포의 사용자 지정 이름입니다. 채팅 완료 호출을 수행할 때 코드에서 참조되는 이름입니다. |
| fine_tuned_model | 이전 단계의 미세 조정 작업 결과에서 이 값을 검색합니다. gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83와 같이 표시됩니다. 해당 값을 deploy_data json에 추가해야 합니다. 또는 ftchkpt-e559c011ecc04fc68eaa339d8227d02d 형식으로 표시되는 검사점 ID를 전달하여 검사점을 배포할 수도 있습니다. |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
지역 간 배포
미세 조정은 모델이 원래 미세 조정된 지역과 다른 지역에 미세 조정된 모델을 배포하도록 지원합니다. 다른 구독/지역에 배포할 수도 있습니다.
유일한 제한 사항은 새 지역이 미세 조정도 지원해야 하며, 교차 구독을 배포할 때 배포에 대한 권한 부여 토큰을 생성하는 계정에는 원본 및 대상 구독 모두에 대한 액세스 권한이 있어야 한다는 것입니다.
다음은 한 구독/지역에서 세밀하게 조정된 모델을 다른 구독에 배포하는 예제입니다.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0613.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
동일한 구독 간에 배포하지만 다른 지역 간에 배포하려면 구독 및 리소스 그룹이 원본 변수와 대상 변수 모두에 대해 동일해야 하며 원본 및 대상 리소스 이름만 고유해야 합니다.
Azure CLI를 사용하여 모델 배포
다음 예제에서는 Azure CLI를 사용하여 사용자 지정 모델을 배포하는 방법을 보여줍니다. Azure CLI를 사용하면 사용자 지정 모델의 배포 이름을 지정해야 합니다. Azure CLI를 사용하여 사용자 지정된 모델을 배포하는 방법에 대한 자세한 내용은 az cognitiveservices account deployment을(를) 참조하세요.
콘솔 창에서 이 Azure CLI 명령을 실행하려면 다음 <자리 표시자>를 사용자 지정 모델에 해당하는 값으로 바꿔야 합니다.
| 자리 표시자 | 값 |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Azure 구독의 이름 또는 ID입니다. |
| <YOUR_RESOURCE_GROUP> | Azure 리소스 그룹의 이름입니다. |
| <YOUR_RESOURCE_NAME> | Azure OpenAI 리소스의 이름입니다. |
| <YOUR_DEPLOYMENT_NAME> | 모델 배포에 사용하려는 이름입니다. |
| <YOUR_FINE_TUNED_MODEL_ID> | 사용자 지정 모델의 이름입니다. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
배포된 사용자 지정 모델 사용
사용자 지정 모델이 배포되었으면 배포된 다른 모델처럼 사용할 수 있습니다. Azure AI Foundry의 플레이그라운드를 사용하여 새 배포를 실험할 수 있습니다. 배포된 다른 모델과 마찬가지로 사용자 지정 모델에서 temperature 및 max_tokens와 같은 동일한 매개 변수를 계속 사용할 수 있습니다. 미세 조정된 babbage-002 모델 및 davinci-002 모델의 경우 완료 플레이그라운드 및 완료 API를 사용합니다. 미세 조정된 gpt-35-turbo-0613 모델의 경우 채팅 플레이그라운드 및 채팅 완료 API를 사용합니다.
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response.choices[0].message.content)
사용자 지정 모델 분석
미세 조정 작업이 완료되면 Azure OpenAI는 results.csv라는 결과 파일을 각 미세 조정 작업에 연결합니다. 이 결과 파일을 사용하여 사용자 지정 모델의 학습 및 유효성 검사 성능을 분석할 수 있습니다. 결과 파일의 파일 ID는 각 사용자 지정 모델에 대해 나열되며, Python SDK를 사용하여 파일 ID를 검색하고 결과 파일을 다운로드하여 분석할 수 있습니다.
다음 Python 예제에서는 사용자 지정 모델의 미세 조정 작업에 연결된 첫 번째 결과 파일의 파일 ID를 검색한 다음, 파일을 분석할 수 있도록 Python SDK를 사용하여 파일을 작업 디렉터리에 다운로드합니다.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
결과 파일은 미세 조정 작업에서 수행하는 각 학습 단계에 대한 머리글 행과 행을 포함하는 CSV 파일입니다. 결과 파일에는 다음 열이 포함되어 있습니다.
| 열 이름 | 설명 |
|---|---|
step |
학습 단계의 수입니다. 학습 단계는 학습 데이터 일괄 처리에 대한 정방향 및 역방향 단일 패스를 나타냅니다. |
train_loss |
학습 일괄 처리의 손실입니다. |
train_mean_token_accuracy |
모델에서 올바르게 예측한 학습 일괄 처리의 토큰 비율입니다. 예를 들어 일괄 처리 크기가 3으로 설정되고 데이터에 완료 [[1, 2], [0, 5], [4, 2]]가 포함된 경우 모델이 [[1, 1], [0, 5], [4, 2]]를 예측하면 이 값은 0.83(5/6)으로 설정됩니다. |
valid_loss |
유효성 검사 일괄 처리의 손실입니다. |
validation_mean_token_accuracy |
모델에서 올바르게 예측한 유효성 검사 일괄 처리의 토큰 비율입니다. 예를 들어 일괄 처리 크기가 3으로 설정되고 데이터에 완료 [[1, 2], [0, 5], [4, 2]]가 포함된 경우 모델이 [[1, 1], [0, 5], [4, 2]]를 예측하면 이 값은 0.83(5/6)으로 설정됩니다. |
full_valid_loss |
각 epoch의 끝에서 계산된 유효성 검사 손실입니다. 학습이 잘되면 손실이 줄어들 것입니다. |
full_valid_mean_token_accuracy |
각 epoch의 끝에서 계산된 유효한 평균 토큰 정확도입니다. 학습이 잘 진행되면 토큰 정확도가 높아져야 합니다. |
azure AI Foundry 포털에서 results.csv 파일의 데이터를 플롯으로 볼 수도 있습니다. 학습된 모델에 대한 링크를 선택하면 손실, 평균 토큰 정확도 및 토큰 정확도의 세 가지 차트가 표시됩니다. 유효성 검사 데이터를 제공한 경우 두 데이터 세트가 모두 동일한 플롯에 나타납니다.
시간이 지남에 따라 손실이 감소하고 정확도가 증가하는지 확인합니다. 학습 데이터와 유효성 검사 데이터 사이에 차이가 있는 경우 이는 과잉 맞춤을 의미할 수 있습니다. 더 적은 epoch 또는 더 작은 학습 속도 승수를 사용하여 학습을 시도합니다.
배포, 사용자 지정 모델 및 학습 파일 정리
사용자 지정 모델을 완료했으면 배포 및 모델을 삭제해도 됩니다. 원한다면 서비스에 업로드한 학습 및 유효성 검사 파일까지 삭제해도 됩니다.
모델 배포 삭제
Important
사용자 지정된 모델을 배포한 후 언제든지 배포가 15일 이상 비활성 상태로 유지되면 배포가 삭제됩니다. 모델이 배포된 지 15일이 넘었고 연속 15일 동안 모델에 대한 완료 또는 채팅 완료 호출이 이루어지지 않은 경우 맞춤형 모델 배포는 비활성 상태입니다.
비활성 배포를 삭제해도 기본 사용자 지정 모델은 삭제되거나 영향을 받지 않으며 사용자 지정 모델은 언제든지 다시 배포될 수 있습니다. Azure OpenAI Service 가격 책정에 설명된 대로 배포되는 각 사용자 지정(세밀 조정) 모델에는 완료 또는 채팅 완료 호출이 모델에 대해 수행되는지 여부에 관계없이 시간당 호스팅 비용이 발생합니다. Azure OpenAI를 사용하여 비용을 계획하고 관리하는 방법에 대한 자세한 내용은 Azure OpenAI Service 비용 관리 계획의 지침을 참조하세요.
다음과 같은 다양한 방법으로 사용자 지정 모델의 배포를 삭제할 수 있습니다.
사용자 지정 모델 삭제
마찬가지로 다양한 방법으로 사용자 지정 모델을 삭제할 수 있습니다.
참고 항목
기존 배포가 있는 사용자 지정 모델은 삭제할 수 없습니다. 사용자 지정 모델을 삭제하려면 모델 배포부터 삭제해야 합니다.
학습 파일 삭제
필요에 따라 Azure OpenAI 구독에서 학습을 위해 업로드한 학습 및 유효성 검사 파일과 학습 중에 생성된 결과 파일을 삭제할 수 있습니다. 다음 방법을 사용하여 학습, 유효성 검사 및 결과 파일을 삭제할 수 있습니다.
- Azure AI Foundry
- REST API
- Python SDK
다음 Python 예제에서는 Python SDK를 사용하여 사용자 지정 모델의 학습, 유효성 검사 및 결과 파일을 삭제합니다.
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
연속 미세 조정
미세 조정된 모델을 만든 후에는 추가 미세 조정을 통해 시간이 지남에 따라 모델을 계속 구체화할 수 있습니다. 지속적인 미세 조정은 이미 미세 조정된 모델을 기본 모델로 선택하고 새로운 학습 예제 집합에서 추가로 미세 조정하는 반복적인 프로세스입니다.
이전에 미세 조정한 모델에 대해 미세 조정을 수행하려면 사용자 지정 모델 만들기에 설명된 것과 동일한 프로세스를 사용하지만 일반 기본 모델의 이름을 지정하는 대신 이미 미세 조정된 모델의 ID를 지정합니다. 미세 조정된 모델 ID는 gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7과(와) 같습니다.
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7" # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
또한 suffix 매개 변수를 포함하여 미세 조정된 모델의 여러 반복을 더 쉽게 구분할 수 있도록 하는 것이 좋습니다. suffix은(는) 문자열을 사용하고 미세 조정된 모델을 식별하도록 설정됩니다. OpenAI Python API를 사용하면 미세 조정된 모델 이름에 추가될 최대 18자의 문자열이 지원됩니다.
기존 미세 조정된 모델의 ID를 잘 모르는 경우 이 정보는 Azure AI Foundry의 모델 페이지에서 찾을 수 있거나 REST API를 사용하여 지정된 Azure OpenAI 리소스에 대한 모델 목록을 생성할 수 있습니다.
필수 조건
- Azure OpenAI 미세 조정 가이드를 사용하는 경우를 읽어보세요.
- Azure 구독 체험 계정 만들기
- Azure OpenAI 리소스 자세한 내용은 Azure OpenAI를 사용하여 리소스 만들기 및 모델 배포를 참조하세요.
- 액세스를 미세 조정하려면 Cognitive Services OpenAI 기여자가 필요합니다.
- 할당량을 보고 Azure AI Foundry 포털에서 모델을 배포할 수 있는 액세스 권한이 아직 없는 경우 추가 권한이 필요합니다.
모델
다음 모델은 미세 조정을 지원합니다.
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* 이 모델에 대한 미세 조정은 현재 공개 미리 보기로 제공됩니다.
또는 이전에 미세 조정된 모델을 base-model.ft-{jobid} 형식으로 미세 조정할 수 있습니다.
모델 페이지를 참조하여 현재 미세 조정을 지원하는 지역을 확인합니다.
REST API에 대한 워크플로 검토
잠시 시간을 내어 Azure OpenAI에서 REST API 및 Python을 사용하기 위한 미세 조정 워크플로를 검토합니다.
- 학습 및 유효성 검사 데이터를 준비합니다.
- 기본 모델을 선택합니다.
- 학습 데이터를 업로드합니다.
- 새 사용자 지정 모델을 학습시킵니다.
- 사용자 지정 모델의 상태를 확인합니다.
- 사용할 사용자 지정 모델을 배포합니다.
- 사용자 지정 모델을 사용합니다.
- 필요에 따라 사용자 지정 모델의 성능 및 적합성을 분석합니다.
학습 및 유효성 검사 데이터 준비
학습 데이터 및 유효성 검사 데이터 세트는 원하는 모델 성능에 대한 입력 및 출력 예제로 구성됩니다.
모델 유형에 따라 학습 데이터의 형식이 다릅니다.
사용하는 학습 및 유효성 검사 데이터는 반드시 JSONL(JSON Lines) 문서로 서식을 지정해야 합니다. gpt-35-turbo-0613 및 기타 관련 모델의 경우 미세 조정 데이터 세트는 채팅 완료 API에서 사용하는 대화형식으로 형식을 지정해야 합니다.
gpt-35-turbo-0613 미세 조정을 단계별로 연습하려면 Azure OpenAI 미세 조정 자습서를 참조하세요.
예제 파일 형식
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
멀티 턴 채팅 파일 형식
jsonl 학습 파일의 한 줄에 여러 번 대화하는 것도 지원됩니다. 특정 도우미 메시지에 대한 미세 조정을 건너뛰려면 선택적 weight 키 값 쌍을 추가합니다. 현재 weight는 0 또는 1로 설정할 수 있습니다.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
비전으로 채팅 완료
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
JSONL 형식 외에도, 학습 및 유효성 검사 데이터 파일은 UTF-8로 인코딩되어야 하고 BOM(바이트 순서 표시)을 포함해야 합니다. 파일 크기는 512MB 미만이어야 합니다.
학습 및 유효성 검사 데이터 세트 만들기
학습 사례가 많을수록 좋습니다. 10개 이상의 학습 예제가 없으면 미세 조정 작업이 진행되지 않지만 이러한 적은 수만으로는 모델 응답에 눈에 띄게 영향을 주지 않습니다. 성공하려면 수천 개는 아니더라도 수백 개의 학습 사례를 제공하는 것이 가장 좋습니다.
일반적으로 데이터 세트 크기가 두 배로 증가할 때마다 모델 품질이 선형적으로 증가할 수 있습니다. 그러나 저품질 예제는 성능에 부정적인 영향을 미칠 수 있습니다. 최고 품질의 예제에 대해서만 데이터 세트를 먼저 정리하지 않고 대량의 내부 데이터에서 모델을 학습하는 경우, 예상보다 훨씬 더 나쁜 성능을 발휘하는 모델이 될 수 있습니다.
기본 모델 선택
사용자 지정 모델을 만드는 첫 번째 단계는 기본 모델을 선택하는 것입니다. 기본 모델 창에서 사용자 지정 모델에 사용할 기본 모델을 선택할 수 있습니다. 선택하는 기본 모델은 모델의 성능과 비용 모두에 영향을 줍니다.
기본 모델 유형 드롭다운에서 기본 모델을 선택하고 다음을 선택하여 계속합니다.
사용 가능한 다음 기본 모델 중 하나로 사용자 지정 모델을 만들 수 있습니다.
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)gpt-4o(2024-08-06)gpt-4o-mini(2023-07-18)
또는 이전에 미세 조정된 모델을 base-model.ft-{jobid} 형식으로 미세 조정할 수 있습니다.
미세 조정할 수 있는 기본 모델에 대한 자세한 내용은 모델을 참조하세요.
학습 데이터 업로드
다음 단계는 모델을 미세 조정할 때 사용할 준비된 기존 학습 데이터를 선택하거나 준비된 새 학습 데이터를 업로드하는 것입니다. 학습 데이터를 준비한 후에는 파일을 서비스에 업로드할 수 있습니다. 학습 데이터를 업로드하는 두 가지 방법이 있습니다.
대용량 데이터 파일의 경우 Azure Blob 저장소에서 가져오는 것이 좋습니다. 요청이 원자성이어서 다시 시도하거나 다시 시작할 수 없기 때문에 대용량 파일은 멀티파트 양식을 통해 업로드할 때 불안정해질 수 있습니다. Azure Blob 스토리지에 대한 자세한 내용은 Azure Blob 스토리지란?을 참조하세요.
참고 항목
학습 데이터 파일은 JSONL 파일로 포맷되고 BOM(바이트 순서 표시)이 있는 UTF-8로 인코딩되어야 합니다. 파일 크기는 512MB 미만이어야 합니다.
학습 데이터 업로드
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
유효성 검사 데이터 업로드
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
사용자 지정 모델 만들기
학습 및 유효성 검사 파일을 업로드했으면 미세 조정 작업을 시작할 준비가 된 것입니다. 다음 코드는 REST API를 사용하여 새 미세 조정 작업을 만드는 방법의 예를 보여 줍니다.
이 예에서는 시드 매개 변수도 전달합니다. 시드는 작업의 재현성을 제어합니다. 동일한 시드 및 작업 매개 변수를 전달하면 동일한 결과가 생성되지만 드물게 다를 수 있습니다. 시드를 지정하지 않으면 시드가 생성됩니다.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
또한 하이퍼 매개 변수와 같은 추가 선택적 매개 변수를 전달하여 미세 조정 프로세스를 보다 잘 제어할 수 있습니다. 초기 학습의 경우 이러한 매개 변수를 지정하지 않고 존재하는 자동 기본값을 사용하는 것이 좋습니다.
미세 조정을 위해 현재 지원되는 하이퍼 매개 변수는 다음과 같습니다.
| 이름 | 타입 | 설명 |
|---|---|---|
batch_size |
정수 | 학습에 사용할 일괄 처리 크기입니다. 일괄 처리 크기는 단일 전진 및 후진 계산법을 학습하는 데 사용되는 학습 예의 수입니다. 일반적으로 일괄 처리 크기가 클수록 데이터 세트가 클수록 더 잘 작동하는 경향이 있습니다. 기본값과 이 속성의 최대값은 기본 모델과 관련이 있습니다. 일괄 처리 크기가 클수록 모델 매개 변수는 덜 자주 업데이트되지만 분산은 낮습니다. |
learning_rate_multiplier |
number | 학습에 사용할 학습 속도 승수입니다. 미세 조정 학습 속도는 사전 학습에 사용된 원래 학습 속도에 이 값을 곱한 값입니다. 학습률이 클수록 일괄 처리 크기가 클수록 성능이 더 좋은 경향이 있습니다. 0.02에서 0.2 사이의 값으로 실험하여 최상의 결과를 생성하는 값을 확인하는 것이 좋습니다. 학습 속도가 작을수록 과잉 맞춤을 방지하는 데 유용할 수 있습니다. |
n_epochs |
정수 | 모델을 학습할 Epoch의 수입니다. Epoch는 학습 데이터 세트를 통한 하나의 전체 주기를 나타냅니다. |
seed |
정수 | 시드는 작업의 재현성을 제어합니다. 동일한 시드 및 작업 매개 변수를 전달하면 동일한 결과가 생성되지만 드문 경우에 다를 수 있습니다. 시드를 지정하지 않으면 시드가 생성됩니다. |
사용자 지정 모델의 상태 확인
미세 조정 작업을 시작한 후 완료하는 데 시간이 걸릴 수 있습니다. 사용자의 작업이 시스템의 다른 작업 뒤에 대기 중일 수 있습니다. 모델 및 데이터 세트 크기에 따라 모델을 학습하는 데 몇 분 또는 몇 시간이 걸릴 수 있습니다. 다음 예제에서는 REST API를 사용하여 미세 조정 작업의 상태를 확인합니다. 이 예제에서는 이전 예제에서 반환된 작업 ID를 사용하여 작업 정보를 검색합니다.
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-05-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
미세 조정 이벤트 나열
학습 중에 생성된 개별 미세 조정 이벤트를 검사하려면 다음을 수행합니다.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
검사점
각 학습 epoch가 완료되면 검사점이 생성됩니다. 검사점은 후속 미세 조정 작업을 위한 대상 모델로 배포 및 사용할 수 있는 모델의 완전한 기능 버전입니다. 검사점은 과잉 맞춤이 발생하기 전에 모델의 스냅샷을 제공할 수 있으므로 특히 유용할 수 있습니다. 미세 조정 작업이 완료되면 배포할 수 있는 최신 모델 버전 3개가 제공됩니다. 최종 epoch는 미세 조정된 모델로 표시되며 이전 두 epoch는 검사점으로 사용할 수 있습니다.
list checkpoints 명령을 실행하여 개별 미세 조정 작업과 관련된 검사점 목록을 검색할 수 있습니다.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
안전 평가 GPT-4, GPT-4o, GPT-4o-mini 미세 조정 - 공개 미리 보기
GPT-4o, GPT-4o-mini 및 GPT-4는 사용자의 요구 사항에 맞춰 미세 조정할 수 있는 가장 발전된 고급 모델입니다. 일반적으로 Azure OpenAI 모델과 마찬가지로 미세 조정된 모델의 고급 기능에는 유해한 콘텐츠, 조작, 인간과 유사한 동작, 개인 정보 보호 문제 등과 관련된 책임감 있는 AI가 해결해야 할 문제가 증가합니다. 책임감 있는 AI 사례 및 투명성 고지에서 위험, 기능, 제한 사항에 대해 자세히 알아봅니다. 미세 조정된 고급 모델과 관련된 위험을 완화하기 위해, 미세 조정된 모델의 학습 및 출력에서 유해한 콘텐츠를 감지하고 방지하는 데 도움이 되는 추가 평가 단계를 구현했습니다. 이러한 단계는 Microsoft의 책임감 있는 AI 표준 및 Azure OpenAI 서비스 콘텐츠 필터링에 근거합니다.
- 평가는 전용 고객별 프라이빗 작업 영역에서 수행됩니다.
- 평가 엔드포인트는 Azure OpenAI 리소스와 동일한 지역에 있습니다.
- 학습 데이터는 평가 수행과 관련하여 저장되지 않으며, 최종 모델 평가(배포 가능 또는 배포 불가능)만 유지됩니다.
GPT-4o GPT-4o-mini 및 GPT-4 미세 조정된 모델 평가 필터는 미리 정의된 임계값으로 설정되며 고객이 수정할 수 없습니다. 또한 사용자가 만들었을 수 있는 사용자 지정 콘텐츠 필터링 구성에 연결되지 않습니다.
데이터 평가
학습이 시작되기 전에 잠재적으로 유해한 콘텐츠(폭력, 성적인 내용, 혐오, 공정성, 자해 등, 여기에서 범주 정의 참조)가 있는지 데이터를 평가합니다. 지정된 심각도 수준 이상으로 유해한 콘텐츠가 감지되면 학습 작업이 실패하고 실패 범주를 알리는 메시지가 표시됩니다.
샘플 메시지:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
학습 데이터는 미세 조정 기능을 제공하는 일환으로 데이터 가져오기 작업 내에서 자동으로 평가됩니다.
학습 데이터의 유해한 콘텐츠가 감지되어 미세 조정 작업이 실패하는 경우 요금이 청구되지 않습니다.
모델 평가
학습이 완료되었지만 미세 조정된 모델을 배포할 수 있기 전에, 결과 모델은 Azure의 기본 제공 위험 및 안전 메트릭을 사용하여 잠재적으로 유해한 대응에 대해 평가됩니다. 기본 대형 언어 모델에 사용하는 테스트와 동일한 접근 방식을 사용하여 평가 기능은 지정된 유해한 콘텐츠 범주(폭력, 성적인 내용, 혐오, 공정성, 자해)를 사용하여 유해한 콘텐츠를 출력할 가능성을 평가하기 위해 미세 조정된 모델과의 대화를 시뮬레이션합니다.
허용 가능한 비율 이상으로 유해한 것으로 감지된 콘텐츠를 포함하는 출력을 모델이 생성하는 것으로 확인되면 배포에 해당 모델을 사용할 수 없다는 알림이 표시되고 특정 범주의 피해에 대한 정보가 표시됩니다.
샘플 메시지:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
데이터 평가와 마찬가지로 모델은 미세 조정 기능 제공의 일환으로 미세 조정 작업 내에서 자동으로 평가됩니다. 결과 평가(배포 가능 또는 배포 불가능)만 서비스에서 기록합니다. 모델 출력에서 유해한 콘텐츠가 감지되어 미세 조정된 모델의 배포가 실패하는 경우 학습 실행에 대한 요금이 청구되지 않습니다.
미세 조정된 모델 배포
Important
사용자 지정된 모델을 배포한 후 언제든지 배포가 15일 이상 비활성 상태로 유지되면 배포가 삭제됩니다. 모델이 배포된 지 15일이 넘었고 연속 15일 동안 모델에 대한 완료 또는 채팅 완료 호출이 이루어지지 않은 경우 맞춤형 모델 배포는 비활성 상태입니다.
비활성 배포를 삭제해도 기본 사용자 지정 모델은 삭제되거나 영향을 받지 않으며 사용자 지정 모델은 언제든지 다시 배포될 수 있습니다. Azure OpenAI Service 가격 책정에 설명된 대로 배포되는 각 사용자 지정(세밀 조정) 모델에는 완료 또는 채팅 완료 호출이 모델에 대해 수행되는지 여부에 관계없이 시간당 호스팅 비용이 발생합니다. Azure OpenAI를 사용하여 비용을 계획하고 관리하는 방법에 대한 자세한 내용은 Azure OpenAI Service 비용 관리 계획의 지침을 참조하세요.
다음 Python 예제에서는 REST API를 사용하여 사용자 지정 모델의 모델 배포를 만드는 방법을 보여줍니다. REST API는 사용자 지정 모델의 배포 이름을 생성합니다.
| 변수 | 정의 |
|---|---|
| token | 권한 부여 토큰을 생성하는 방법에는 여러 가지가 있습니다. 초기 테스트를 위한 가장 쉬운 방법은 Azure Portal에서 Cloud Shell을 시작하는 것입니다. 그런 다음 az account get-access-token를 실행합니다. 이 토큰을 API 테스트를 위한 임시 권한 부여 토큰으로 사용할 수 있습니다. 새 환경 변수에 저장하는 것이 좋습니다. |
| 구독 | 연결된 Azure OpenAI 리소스에 대한 구독 ID. |
| resource_group | Azure OpenAI 리소스의 리소스 그룹 이름. |
| resource_name | Azure OpenAI 리소스 이름. |
| model_deployment_name | 미세 조정된 새 모델 배포의 사용자 지정 이름입니다. 채팅 완료 호출을 수행할 때 코드에서 참조되는 이름입니다. |
| fine_tuned_model | 이전 단계의 미세 조정 작업 결과에서 이 값을 검색합니다. gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83와 같이 표시됩니다. 해당 값을 deploy_data json에 추가해야 합니다. 또는 ftchkpt-e559c011ecc04fc68eaa339d8227d02d 형식으로 표시되는 검사점 ID를 전달하여 검사점을 배포할 수도 있습니다. |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
지역 간 배포
미세 조정은 모델이 원래 미세 조정된 지역과 다른 지역에 미세 조정된 모델을 배포하도록 지원합니다. 다른 구독/지역에 배포할 수도 있습니다.
유일한 제한 사항은 새 지역이 미세 조정도 지원해야 하며, 교차 구독을 배포할 때 배포에 대한 권한 부여 토큰을 생성하는 계정에는 원본 및 대상 구독 모두에 대한 액세스 권한이 있어야 한다는 것입니다.
다음은 한 구독/지역에서 세밀하게 조정된 모델을 다른 구독에 배포하는 예제입니다.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
동일한 구독이지만 다른 지역 간에 배포하려면 원본 및 대상 변수 모두에 대해 구독 및 리소스 그룹이 동일해야 하며 원본 및 대상 리소스 이름만 고유해야 합니다.
Azure CLI를 사용하여 모델 배포
다음 예제에서는 Azure CLI를 사용하여 사용자 지정 모델을 배포하는 방법을 보여줍니다. Azure CLI를 사용하면 사용자 지정 모델의 배포 이름을 지정해야 합니다. Azure CLI를 사용하여 사용자 지정된 모델을 배포하는 방법에 대한 자세한 내용은 az cognitiveservices account deployment을(를) 참조하세요.
콘솔 창에서 이 Azure CLI 명령을 실행하려면 다음 <자리 표시자>를 사용자 지정 모델에 해당하는 값으로 바꿔야 합니다.
| 자리 표시자 | 값 |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Azure 구독의 이름 또는 ID입니다. |
| <YOUR_RESOURCE_GROUP> | Azure 리소스 그룹의 이름입니다. |
| <YOUR_RESOURCE_NAME> | Azure OpenAI 리소스의 이름입니다. |
| <YOUR_DEPLOYMENT_NAME> | 모델 배포에 사용하려는 이름입니다. |
| <YOUR_FINE_TUNED_MODEL_ID> | 사용자 지정 모델의 이름입니다. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
배포된 사용자 지정 모델 사용
사용자 지정 모델이 배포되었으면 배포된 다른 모델처럼 사용할 수 있습니다. Azure AI Foundry의 플레이그라운드를 사용하여 새 배포를 실험할 수 있습니다. 배포된 다른 모델과 마찬가지로 사용자 지정 모델에서 temperature 및 max_tokens와 같은 동일한 매개 변수를 계속 사용할 수 있습니다. 미세 조정된 babbage-002 모델 및 davinci-002 모델의 경우 완료 플레이그라운드 및 완료 API를 사용합니다. 미세 조정된 gpt-35-turbo-0613 모델의 경우 채팅 플레이그라운드 및 채팅 완료 API를 사용합니다.
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2023-05-15 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure AI services support this too?"}]}'
사용자 지정 모델 분석
미세 조정 작업이 완료되면 Azure OpenAI는 results.csv라는 결과 파일을 각 미세 조정 작업에 연결합니다. 이 결과 파일을 사용하여 사용자 지정 모델의 학습 및 유효성 검사 성능을 분석할 수 있습니다. 결과 파일의 파일 ID는 각 사용자 지정 모델에 대해 나열되며, REST API를 사용하여 파일 ID를 검색하고 결과 파일을 다운로드하여 분석할 수 있습니다.
다음 Python 예제에서는 REST API를 사용하여 사용자 지정 모델의 미세 조정 작업에 연결된 첫 번째 결과 파일의 파일 ID를 검색한 다음, 파일을 분석할 수 있도록 파일을 작업 디렉터리에 다운로드합니다.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
결과 파일은 미세 조정 작업에서 수행하는 각 학습 단계에 대한 머리글 행과 행을 포함하는 CSV 파일입니다. 결과 파일에는 다음 열이 포함되어 있습니다.
| 열 이름 | 설명 |
|---|---|
step |
학습 단계의 수입니다. 학습 단계는 학습 데이터 일괄 처리에 대한 정방향 및 역방향 단일 패스를 나타냅니다. |
train_loss |
학습 일괄 처리의 손실입니다. |
train_mean_token_accuracy |
모델에서 올바르게 예측한 학습 일괄 처리의 토큰 비율입니다. 예를 들어 일괄 처리 크기가 3으로 설정되고 데이터에 완료 [[1, 2], [0, 5], [4, 2]]가 포함된 경우 모델이 [[1, 1], [0, 5], [4, 2]]를 예측하면 이 값은 0.83(5/6)으로 설정됩니다. |
valid_loss |
유효성 검사 일괄 처리의 손실입니다. |
validation_mean_token_accuracy |
모델에서 올바르게 예측한 유효성 검사 일괄 처리의 토큰 비율입니다. 예를 들어 일괄 처리 크기가 3으로 설정되고 데이터에 완료 [[1, 2], [0, 5], [4, 2]]가 포함된 경우 모델이 [[1, 1], [0, 5], [4, 2]]를 예측하면 이 값은 0.83(5/6)으로 설정됩니다. |
full_valid_loss |
각 epoch의 끝에서 계산된 유효성 검사 손실입니다. 학습이 잘되면 손실이 줄어들 것입니다. |
full_valid_mean_token_accuracy |
각 epoch의 끝에서 계산된 유효한 평균 토큰 정확도입니다. 학습이 잘 진행되면 토큰 정확도가 높아져야 합니다. |
azure AI Foundry 포털에서 results.csv 파일의 데이터를 플롯으로 볼 수도 있습니다. 학습된 모델에 대한 링크를 선택하면 손실, 평균 토큰 정확도 및 토큰 정확도의 세 가지 차트가 표시됩니다. 유효성 검사 데이터를 제공한 경우 두 데이터 세트가 모두 동일한 플롯에 나타납니다.
시간이 지남에 따라 손실이 감소하고 정확도가 증가하는지 확인합니다. 학습 데이터와 유효성 검사 데이터 사이에 차이가 있는 경우 이는 과잉 맞춤을 의미할 수 있습니다. 더 적은 epoch 또는 더 작은 학습 속도 승수를 사용하여 학습을 시도합니다.
배포, 사용자 지정 모델 및 학습 파일 정리
사용자 지정 모델을 완료했으면 배포 및 모델을 삭제해도 됩니다. 원한다면 서비스에 업로드한 학습 및 유효성 검사 파일까지 삭제해도 됩니다.
모델 배포 삭제
다음과 같은 다양한 방법으로 사용자 지정 모델의 배포를 삭제할 수 있습니다.
사용자 지정 모델 삭제
마찬가지로 다양한 방법으로 사용자 지정 모델을 삭제할 수 있습니다.
참고 항목
기존 배포가 있는 사용자 지정 모델은 삭제할 수 없습니다. 사용자 지정 모델을 삭제하려면 모델 배포부터 삭제해야 합니다.
학습 파일 삭제
필요에 따라 Azure OpenAI 구독에서 학습을 위해 업로드한 학습 및 유효성 검사 파일과 학습 중에 생성된 결과 파일을 삭제할 수 있습니다. 다음 방법을 사용하여 학습, 유효성 검사 및 결과 파일을 삭제할 수 있습니다.
연속 미세 조정
미세 조정된 모델을 만든 후에는 추가 미세 조정을 통해 시간이 지남에 따라 모델을 계속 구체화할 수 있습니다. 지속적인 미세 조정은 이미 미세 조정된 모델을 기본 모델로 선택하고 새로운 학습 예제 집합에서 추가로 미세 조정하는 반복적인 프로세스입니다.
이전에 미세 조정한 모델에 대해 미세 조정을 수행하려면 사용자 지정 모델 만들기에 설명된 것과 동일한 프로세스를 사용하지만 일반 기본 모델의 이름을 지정하는 대신 이미 미세 조정된 모델의 ID를 지정합니다. 미세 조정된 모델 ID는 gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7과(와) 같습니다.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
또한 suffix 매개 변수를 포함하여 미세 조정된 모델의 여러 반복을 더 쉽게 구분할 수 있도록 하는 것이 좋습니다. suffix은(는) 문자열을 사용하고 미세 조정된 모델을 식별하도록 설정됩니다. 접미사는 미세 조정된 모델 이름에 추가될 최대 40자(a-z, A-Z, 0-9 및 _)를 포함할 수 있습니다.
미세 조정된 모델의 ID를 잘 모르는 경우 이 정보는 Azure AI Foundry의 모델 페이지에서 찾을 수 있거나 REST API를 사용하여 지정된 Azure OpenAI 리소스에 대한 모델 목록을 생성할 수 있습니다.
글로벌 표준(미리 보기)
Azure OpenAI 미세 조정은 다음을 위해 미국 동부 2, 미국 중북부 및 스웨덴 중부에서 글로벌 표준 배포 를 지원합니다.
gpt-4o-mini-2024-07-18gpt-4o-2024-08-06(새 배포는 2025년 1월까지 사용할 수 없음)
글로벌 표준 미세 조정 배포는 비용 절감을 제공하지만 사용자 지정 모델 가중치는 Azure OpenAI 리소스의 지리 외부에 일시적으로 저장될 수 있습니다.

글로벌 표준 미세 조정 배포는 현재 비전 및 구조적 출력을 지원하지 않습니다.
비전 미세 조정
JSONL 파일의 이미지를 사용하여 미세 조정도 가능합니다. 하나 이상의 이미지 입력을 채팅 완료에 보낼 수 있는 것처럼 학습 데이터 내에 동일한 메시지 유형을 포함할 수 있습니다. 이미지는 공개적으로 액세스할 수 있는 URL 또는 base64로 인코딩된 이미지를 포함하는 데이터 URI로 제공할 수 있습니다.
이미지 데이터 세트 요구 사항
- 학습 파일에는 이미지가 포함된 최대 50,000개의 예제가 포함될 수 있습니다(텍스트 예제는 포함하지 않음).
- 각 예제에는 최대 64개의 이미지가 있을 수 있습니다.
- 각 이미지는 최대 10MB일 수 있습니다.
형식
이미지는 다음이어야 합니다.
- JPEG
- PNG
- WEBP
이미지는 RGB 또는 RGBA 이미지 모드여야 합니다.
도우미 역할이 있는 메시지의 출력으로 이미지를 포함할 수 없습니다.
Con텐트 모드ration policy
학습 전에 이미지를 검사하여 사용 정책 투명성 참고를 준수하는지 확인합니다. 이렇게 하면 미세 조정이 시작되기 전에 파일 유효성 검사에 대기 시간이 발생할 수 있습니다.
다음이 포함된 이미지는 데이터 세트에서 제외되며 학습에 사용되지 않습니다.
- 사람
- 얼굴
- CAPTCHA
Important
시력 미세 조정 얼굴 차단 프로세스의 경우: 얼굴/사람이 모델 학습에서 해당 이미지를 건너뛸 수 있도록 차단합니다. 스크리닝 기능은 얼굴 식별 없이 얼굴 감지를 활용하므로 얼굴 템플릿을 만들거나 특정 얼굴 기하 도형을 측정하지 않으며 얼굴을 선별하는 데 사용되는 기술은 개인을 고유하게 식별할 수 없습니다. 얼굴의 데이터 및 개인 정보 보호에 대한 자세한 내용은 Face의 데이터 및 개인 정보 - Azure AI 서비스 | Microsoft Learn.
프롬프트 캐싱
Azure OpenAI 미세 조정은 선택한 모델을 사용한 프롬프트 캐싱을 지원합니다. 프롬프트 캐싱을 사용하면 프롬프트 시작 시 콘텐츠가 동일한 긴 프롬프트에 대한 전체 요청 대기 시간과 비용을 줄일 수 있습니다. 프롬프트 캐싱에 대한 자세한 내용은 프롬프트 캐싱 시작을 참조 하세요.
DPO(직접 기본 설정 최적화)(미리 보기)
DPO(직접 기본 설정 최적화)는 큰 언어 모델에 대한 맞춤 기술로, 사람의 기본 설정에 따라 모델 가중치를 조정하는 데 사용됩니다. 보상 모델을 맞추지 않아도 되며 학습에 더 간단한 이진 데이터 기본 설정을 사용한다는 점에서 RLHF(사용자 피드백)의 보충 학습과는 다릅니다. 이는 RLHF보다 계산적으로 더 가볍고 빠르며 맞춤 시에도 동일하게 효과적입니다.
DPO가 유용한 이유는 무엇인가요?
DPO는 명확한 정답이 없고 톤, 스타일 또는 특정 콘텐츠 기본 설정과 같은 주관적인 요소가 중요한 시나리오에서 특히 유용합니다. 또한 이 방법을 사용하면 모델이 긍정적인 예제(정확하거나 이상적인 것으로 간주됨) 및 부정적인 예제(덜 원하거나 잘못된 것)에서 학습할 수 있습니다.
DPO는 고객이 고품질 학습 데이터 집합을 더 쉽게 생성할 수 있도록 하는 기술로 여겨지고 있습니다. 많은 고객이 감독된 미세 조정을 위해 충분한 대용량 데이터 집합을 생성하는 데 어려움을 겪고 있지만 사용자 로그, A/B 테스트 또는 더 작은 수동 주석 작업을 기반으로 이미 수집된 기본 설정 데이터가 있는 경우가 많습니다.
직접 기본 설정 최적화 데이터 세트 형식
직접 기본 설정 최적화 파일의 형식은 감독된 미세 조정과 다릅니다. 고객은 시스템 메시지와 초기 사용자 메시지가 포함된 "대화"를 제공한 다음 쌍을 이루는 기본 설정 데이터로 "완료"를 제공합니다. 사용자는 두 개의 완료만 제공할 수 있습니다.
세 가지 최상위 필드: inputpreferred_output 및non_preferred_output
- preferred_output/non_preferred_output 각 요소에는 하나 이상의 도우미 메시지가 포함되어야 합니다.
- preferred_output/non_preferred_output 각 요소에는 역할만 있을 수 있습니다(도우미, 도구).
{
"input": {
"messages": {"role": "system", "content": ...},
"tools": [...],
"parallel_tool_calls": true
},
"preferred_output": [{"role": "assistant", "content": ...}],
"non_preferred_output": [{"role": "assistant", "content": ...}]
}
학습 데이터 세트는 형식이어야 합니다.jsonl
{{"input": {"messages": [{"role": "system", "content": "You are a chatbot assistant. Given a user question with multiple choice answers, provide the correct answer."}, {"role": "user", "content": "Question: Janette conducts an investigation to see which foods make her feel more fatigued. She eats one of four different foods each day at the same time for four days and then records how she feels. She asks her friend Carmen to do the same investigation to see if she gets similar results. Which would make the investigation most difficult to replicate? Answer choices: A: measuring the amount of fatigue, B: making sure the same foods are eaten, C: recording observations in the same chart, D: making sure the foods are at the same temperature"}]}, "preferred_output": [{"role": "assistant", "content": "A: Measuring The Amount Of Fatigue"}], "non_preferred_output": [{"role": "assistant", "content": "D: making sure the foods are at the same temperature"}]}
}
직접 기본 설정 최적화 모델 지원
gpt-4o-2024-08-06는 각각의 미세 조정 지역에서 직접 기본 설정 최적화를 지원합니다. 모델 페이지에서 최신 지역 가용성이 업데이트됨
사용자는 지원되는 모델/버전인 경우 감독된 미세 조정을 사용하여 이미 미세 조정된 모델뿐만 아니라 기본 모델에서 기본 설정 미세 조정을 사용할 수 있습니다.
직접 기본 설정 최적화 미세 조정을 사용하는 방법
- 기본 설정 형식으로 데이터 세트를 준비
jsonl합니다. - 모델을 선택한 다음 직접 기본 설정 최적화를 사용자 지정하는 방법을 선택합니다.
- 데이터 세트 업로드 - 학습 및 유효성 검사. 필요에 따라 미리 보기.
- 하이퍼 매개 변수를 선택하면 초기 실험에 기본값이 권장됩니다.
- 선택 항목을 검토하고 미세 조정 작업을 만듭니다.
문제 해결
미세 조정을 사용하도록 설정하려면 어떻게 해야 하나요?
미세 조정에 성공적으로 액세스하려면 Cognitive Services OpenAI 기여자가 할당되어야 합니다. 고급 서비스 관리자 권한이 있는 사용자도 미세 조정에 액세스하기 위해 이 계정을 명시적으로 설정해야 합니다. 자세한 내용은 역할 기반 액세스 제어 지침을 검토하세요.
업로드가 실패한 이유는 무엇인가요?
Azure OpenAI Studio에서 파일 업로드가 실패하면 Azure OpenAI 스튜디오의 "데이터 파일"에서 오류 메시지를 볼 수 있습니다. "오류"라고 표시된 곳(상태 열 아래) 위에 마우스를 올리면 실패에 대한 설명이 표시됩니다.

미세 조정된 모델이 개선되지 않은 것 같습니다.
시스템 메시지 누락: 미세 조정 시 시스템 메시지를 제공해야 합니다. 미세 조정된 모델을 사용할 때 동일한 시스템 메시지를 제공하고 싶을 것입니다. 다른 시스템 메시지를 제공하면 미세 조정한 것과 다른 결과가 나타날 수 있습니다.
데이터가 충분하지 않음: 파이프라인을 실행하려면 최소 10개이지만 모델에 새로운 기술을 가르치려면 수십에서 수천 개의 데이터 포인트가 필요합니다. 데이터 포인트가 너무 적으면 과잉 맞춤이 발생하고 일반화가 제대로 이루어지지 않을 위험이 있습니다. 미세 조정된 모델은 학습 데이터에서는 좋은 성능을 보일 수 있지만 학습 패턴 대신 학습 예를 기억했기 때문에 다른 데이터에서는 성능이 좋지 않을 수 있습니다. 최상의 결과를 얻으려면 수백 또는 수천 개의 데이터 포인트가 포함된 데이터 세트를 준비하도록 계획합니다.
잘못된 데이터: 제대로 큐레이팅되지 않았거나 대표성이 없는 데이터 세트는 낮은 품질의 모델을 생성합니다. 모델은 데이터 세트에서 부정확하거나 바이어스된 패턴을 학습할 수 있습니다. 예를 들어, 고객 서비스를 위해 챗봇을 학습하지만 하나의 시나리오(예: 항목 반환)에 대한 학습 데이터만 제공하는 경우 다른 시나리오에 응답하는 방법을 알 수 없습니다. 또는 학습 데이터가 잘못된 경우(잘못된 응답 포함) 모델은 잘못된 결과를 제공하도록 학습합니다.
비전으로 미세 조정
이미지를 건너뛰는 경우 수행할 일
이미지는 다음과 같은 이유로 건너뛸 수 있습니다.
- 에는 CAPTCHA가 포함되어 있습니다.
- 에는 사용자 포함
- 얼굴 포함
이미지를 제거합니다. 지금은 이러한 엔터티가 포함된 이미지로 모델을 미세 조정할 수 없습니다.
일반적인 문제
| 문제 | 이유/해결 방법 |
|---|---|
| 건너뛴 이미지 | 이미지는 CAPTCHA, 사람 또는 얼굴을 포함하는 다음과 같은 이유로 건너뛸 수 있습니다. 이미지를 제거합니다. 지금은 이러한 엔터티가 포함된 이미지로 모델을 미세 조정할 수 없습니다. |
| 액세스할 수 없는 URL | 이미지 URL에 공개적으로 액세스할 수 있는지 확인합니다. |
| 이미지가 너무 큼 | 이미지가 데이터 세트 크기 제한에 속하는지 확인합니다. |
| 잘못된 이미지 형식 | 이미지가 데이터 세트 형식에 속하는지 확인합니다. |
큰 파일을 업로드하는 방법
학습 파일이 상당히 커질 수 있습니다. 최대 512MB의 파일 업로드만 허용하는 파일 API와 달리 업로드 API를 사용하여 여러 파트에서 최대 8GB의 파일을 업로드할 수 있습니다.
학습 비용 절감
이미지의 세부 정보 매개 변수를 낮게 설정하면 이미지의 크기가 512 x 512픽셀로 조정되고 크기에 관계없이 85개의 토큰으로만 표시됩니다. 이렇게 하면 학습 비용이 줄어듭니다.
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png",
"detail": "low"
}
}
비전 미세 조정에 대한 기타 고려 사항
이미지 이해의 충실도를 제어하려면 각 이미지에 image_url 대한 세부 정보 매개 변수를 low<auto&/A0>로 설정합니다. 이는 학습 시간 동안 모델이 보는 이미지당 토큰 수에도 영향을 미치며 학습 비용에 영향을 줍니다.
다음 단계
- Azure OpenAI 미세 조정 자습서에서 미세 조정 기능을 살펴봅니다.
- 모델 지역 가용성 미세 조정 검토
- Azure OpenAI 할당량에 대해 자세히 알아보기