Azure Analysis Services 규모 확장
스케일 아웃을 통해 클라이언트 쿼리를 쿼리 풀의 여러 쿼리 복제본 간에 분산시켜 높은 쿼리 워크로드 동안 응답 시간을 줄일 수 있습니다. 또한 클라이언트 쿼리가 작업 처리에 의해 부정적인 영향을 받지 않도록 쿼리 풀에서 처리가 구분될 수도 있습니다. Azure Portal 또는 Analysis Services REST API를 사용하여 규모 확장을 구성할 수 있습니다.
규모 확장은 표준 가격 책정 계층의 서버에서 사용할 수 있습니다. 각 쿼리 복제본은 서버와 동일한 요금으로 청구됩니다. 모든 쿼리 복제본은 서버와 동일한 지역에 만들어집니다. 사용자가 구성할 수 있는 쿼리 복제본 수는 서버가 있는 지역에 따라 제한됩니다. 자세히 알아보려면 지역별 가용성을 참조하세요. 스케일 아웃은 서버에 사용 가능한 메모리 양을 늘리지 않습니다. 메모리를 늘리려면 계획을 업그레이드해야 합니다.
규모를 확장하는 이유
일반적인 서버 배포에서는 한 서버가 처리 서버 및 쿼리 서버 역할을 모두 수행합니다. 서버 모델에 대한 클라이언트 쿼리 수가 서버 계획에 대한 QPU(쿼리 처리 단위)를 초과하거나 높은 쿼리 워크로드와 동시에 모델 처리가 발생하면 성능이 저하될 수 있습니다.
스케일 아웃을 사용하면 최대 7개의 추가 쿼리 복제본 리소스(기본 서버를 포함하여 총 8개)가 포함된 쿼리 풀을 만들 수 있습니다. 중요한 시간에 QPU 요구를 충족시키기 위해 쿼리 풀의 복제본 수를 확장하고 언제든지 처리 서버를 쿼리 풀에서 분리할 수 있습니다.
쿼리 풀에 있는 쿼리 복제본의 수와 관계없이 처리 워크로드는 쿼리 복제본 간에 분산되지 않습니다. 주 서버가 처리 서버 역할을 수행합니다. 쿼리 복제본은 쿼리 풀의 주 서버와 각 복제본 간에 동기화된 모델 데이터베이스에 대한 쿼리만 제공합니다.
스케일 아웃할 때 새 쿼리 복제본이 쿼리 풀에 증분식으로 추가되는 데 최대 5분이 걸릴 수 있습니다. 모든 새 쿼리 복제본이 구성되어 실행되면 새 클라이언트 연결에서 쿼리 풀 리소스에 걸쳐 부하가 분산됩니다. 기존 클라이언트 연결은 현재 연결되어 있는 리소스에서 변경되지 않습니다. 스케일 인하면 쿼리 풀에서 제거되는 쿼리 풀 리소스에 대한 기존 클라이언트 연결이 종료됩니다. 클라이언트는 나머지 쿼리 풀 리소스에 다시 연결할 수 있습니다.
작동 방식
처음으로 스케일 아웃을 구성하는 경우 주 서버의 model 데이터베이스가 새 쿼리 풀의 새 복제본과 자동으로 동기화됩니다. 자동 동기화는 한 번만 발생합니다. 자동 동기화를 수행하는 동안 주 서버의 데이터 파일(blob 스토리지의 미사용 암호화)은 두 번째 위치에 blob 스토리지의 미사용 암호화 상태로도 복사됩니다. 그런 다음, 쿼리 풀의 복제본은 두 번째 파일 세트의 데이터로 하이드레이션됩니다.
자동 동기화는 서버를 처음 스케일 아웃하는 경우에만 수행되지만 수동 동기화를 수행할 수도 있습니다. 동기화는 쿼리 풀의 복제본에 대한 데이터가 주 서버의 복제본과 일치함을 보장합니다. 주 서버에서 모델을 처리(새로 고침)하는 경우에는 처리 작업이 완료된 후 동기화를 수행해야 합니다. 이 동기화는 blob 스토리지의 주 서버 파일에서 두 번째 파일 세트로 업데이트된 데이터를 복사합니다. 그런 다음, 쿼리 풀의 복제본은 blob 스토리지의 두 번째 파일 세트의 업데이트된 데이터로 하이드레이션됩니다.
예를 들어 쿼리 풀의 복제본 수를 2에서 5로 늘려도 후속 스케일 아웃 작업을 수행할 때 새 복제본은 Blob 스토리지에 있는 두 번째 파일 세트의 데이터로 하이드레이션됩니다. 동기화가 없습니다. 스케일 아웃 후 동기화를 수행하는 경우 쿼리 풀의 새 복제본은 두 번 하이드레이션됩니다(중복 하이드레이션). 후속 스케일 아웃 작업을 수행할 때 다음 사항에 유의해야 합니다.
추가된 복제본의 중복 하이드레이션을 방지하기 위해 스케일 아웃 작업 전에 동기화를 수행합니다. 동시에 실행되는 작업의 동시 동기화와 스케일 아웃은 허용되지 않습니다.
처리 및 스케일 아웃 작업을 모두 자동화하는 경우 먼저 주 서버에서 데이터를 처리한 다음, 동기화를 수행하고 스케일 아웃을 수행하는 것이 중요합니다. 이 시퀀스는 QPU 및 메모리 리소스에 대한 최소한의 영향을 보장합니다.
스케일 아웃 작업 중에는 주 서버를 포함하여 쿼리 풀의 모든 서버가 일시적으로 오프라인 상태입니다.
쿼리 풀에 복제본이 없는 경우에도 동기화가 허용됩니다. 주 서버에서 처리 작업의 새 데이터를 사용하여 0에서 하나 이상의 복제본으로 확장하는 경우 쿼리 풀에서 복제본 없이 먼저 동기화를 수행한 다음, 스케일 아웃을 수행합니다. 스케일 아웃 전 동기화는 새로 추가된 복제본의 중복 하이드레이션을 방지합니다.
주 서버에서 model 데이터베이스를 삭제하면 쿼리 풀의 복제본에서 자동으로 삭제되지 않습니다. 복제본의 공유 blob 스토리지 위치에서 해당 데이터베이스의 파일을 제거한 다음, 쿼리 풀의 복제본에서 모델 데이터베이스를 삭제하는 Sync-AzAnalysisServicesInstance PowerShell 명령을 사용하여 동기화 작업을 수행해야 합니다. 모델 데이터베이스가 주 서버가 아닌 쿼리 풀의 복제본에 존재하는지 확인하려면 쿼리 풀에서 처리 서버를 분리 설정이 예인지 확인합니다. 그런 다음 SSMS(SQL Server Management Studio)를 사용하여
:rw한정자를 통해 주 서버에 연결하고 데이터베이스가 있는지 확인합니다. 그런 다음,:rw한정자 없이 연결하여 쿼리 풀의 복제본에 연결하여 동일한 데이터베이스가 있는지 확인합니다. 데이터베이스가 쿼리 풀의 복제본에 있지만 주 서버에 없는 경우에는 동기화 작업을 실행합니다.주 서버에서 데이터베이스 이름을 바꾸는 경우 데이터베이스가 모든 복제본과 적절하게 동기화되었는지 확인하는 데 필요한 다른 단계가 있습니다. 이름을 바꾼 후에는
-Database매개 변수를 데이터베이스 이름으로 지정하고 Sync-AzAnalysisServicesInstance 명령을 사용하여 동기화를 수행합니다. 이 동기화는 복제본에서 이전 이름의 데이터베이스와 파일을 제거합니다. 그런 다음,-Database매개 변수를 새 데이터베이스 이름으로 지정하고 다른 동기화를 수행합니다. 두 번째 동기화는 새로 명명된 데이터베이스를 두 번째 파일 세트에 복사하고 모든 복제본을 하이드레이션합니다. 이러한 동기화는 포털의 동기화 모델 명령을 사용하여 수행할 수 없습니다.
동기화 모드
기본적으로 쿼리 복제본은 증분 방식이 아닌 전체적으로 리하이드레이션됩니다. 리하이드레이션은 단계적으로 발생합니다. 한 번에 두 개의 복제본을 분리하고 연결하여(최소 3개의 복제본이 있다고 가정) 지정된 시간에 하나 이상의 복제본이 온라인 상태로 유지되도록 합니다. 경우에 따라 이 프로세스가 수행되는 동안 클라이언트를 온라인 복제본 중 하나에 다시 연결해야 할 수도 있습니다. 이제 ReplicaSyncMode 설정을 사용하면 쿼리 복제본 동기화가 병렬로 발생하도록 지정할 수 있습니다. 병렬 동기화는 다음과 같은 이점을 제공합니다.
- 동기화 시간이 크게 감소합니다.
- 복제본 간 데이터는 동기화 프로세스 동안 일관될 가능성이 높습니다.
- 동기화 프로세스 내내 모든 복제본에 대해 데이터베이스가 온라인 상태로 유지되므로 클라이언트가 다시 연결할 필요가 없습니다.
- 메모리 내 캐시는 변경된 데이터만으로 증분 방식으로 업데이트되며 모델을 완전히 리하이드레이션하는 것에 비해 속도가 더 빠를 수 있습니다.
ReplicaSyncMode 설정
SSMS를 사용하여 고급 속성에서 ReplicaSyncMode를 설정합니다. 가능한 값은 다음과 같습니다.
1(기본값): 단계별(증분) 전체 복제본 데이터베이스 리하이드레이션.2: 동기화가 병렬로 최적화됨.
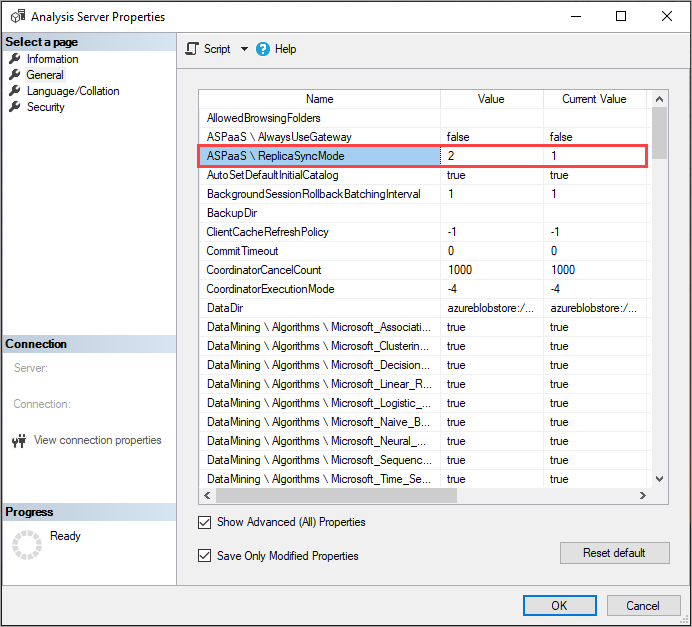
ReplicaSyncMode=2를 설정하면 업데이트해야 하는 캐시의 양에 따라 쿼리 복제본이 더 많은 메모리를 사용할 수 있습니다. 데이터베이스를 쿼리에 대해 온라인 및 사용 가능 상태로 유지하려면 이전 세그먼트와 새 세그먼트가 동시에 메모리에 유지되므로 변경된 데이터의 양에 따라 작업에는 복제본의 메모리가 최대 두 배 필요할 수도 있습니다. 복제본 노드의 메모리 할당은 주 노드와 동일하며, 일반적으로 새로 고침 작업을 위한 주 노드에 추가 메모리가 있으므로 복제본 메모리가 부족하지 않을 수 있습니다. 또한 일반적인 시나리오는 데이터베이스를 주 노드에서 증분 방식으로 업데이트하는 것이므로 메모리를 두 배로 늘리는 것은 드뭅니다. 동기화 작업에서 메모리 부족 오류가 발생하면 기본 기술(한 번에 두 개씩 연결/분리)을 사용하여 다시 시도합니다.
쿼리 풀에서 처리 구분
처리 및 쿼리 작업 모두에서 최대 성능을 내기 위해서는 쿼리 풀에서 처리 서버를 분리하도록 선택할 수 있습니다. 분리되면 새 클라이언트 연결이 쿼리 풀의 쿼리 복제본에만 할당됩니다. 처리 작업에만 약간의 시간이 걸리는 경우 처리 및 동기화 작업을 수행하는 데 걸리는 약간의 시간 동안 쿼리 풀에서 처리 서버를 분리한 다음, 쿼리 풀에 다시 포함시키도록 선택할 수 있습니다. 처리 서버를 쿼리 풀에서 분리하거나 쿼리 풀에 다시 추가하는 작업이 완료되는 데 최대 5분이 걸릴 수 있습니다.
QPU 사용량 모니터링
서버 스케일 아웃이 필요한지 확인하려면 Azure Portal에서 서버 메트릭을 모니터링합니다. QPU가 정기적으로 최대로 출력되는 지점까지 증가하는 경우 모델에 대한 쿼리 수가 계획의 QPU 한도를 초과하고 있음을 의미합니다. 쿼리 풀 작업 큐 길이 메트릭은 쿼리 스레드 풀 큐의 쿼리 수가 사용 가능한 QPU를 초과하면 증가합니다.
관찰할 또 다른 좋은 메트릭은 ServerResourceType의 평균 QPU입니다. 이 메트릭은 주 서버에 대한 평균 QPU를 쿼리 풀과 비교합니다.
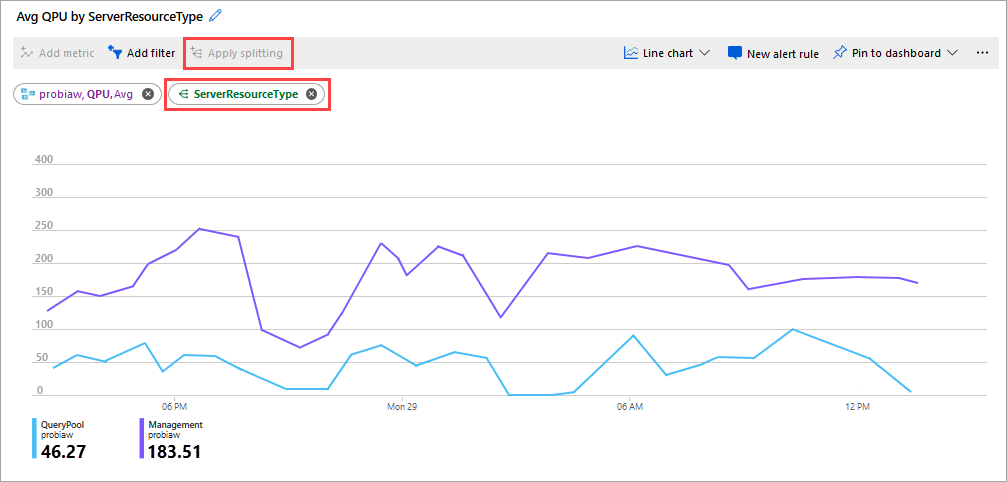
ServerResourceType에서 QPU을 구성하려면
- 메트릭 꺾은선형 차트에서 메트릭 추가를 클릭합니다.
- 리소스에서 서버를 선택한 다음, 메트릭 네임스페이스에서 Analysis Services 표준 메트릭을 선택한 다음, 메트릭에서 QPU를 선택한 다음, 집계에서 평균을 선택합니다.
- 분할 적용을 클릭합니다.
- 값에서 ServerResourceType을 선택합니다.
자세한 진단 로깅
규모가 확장된 서버 리소스의 자세한 진단을 보려면 Azure Monitor 로그를 사용합니다. 로그를 사용하면 Log Analytics 쿼리를 통해 서버 및 복제본별로 QPU 및 메모리를 중단할 수 있습니다. 자세한 내용은 Log Analytics 작업 영역에서 Log Analytics를 참조하세요. 쿼리 예는 샘플 Kusto 쿼리를 참조하세요.
규모 확장 구성
Azure Portal에서
Azure Portal에서 규모 확장을 클릭합니다. 슬라이더를 사용하여 쿼리 복제본 서버 수를 선택합니다. 선택한 복제본 수는 기존 서버에 추가됩니다.
쿼리 서버에서 처리 서버를 제외하려면 쿼리 풀에서 처리 서버 구분에서 [예]를 선택합니다. 기본 연결 문자열(
:rw없이)을 사용한 클라이언트 연결은 쿼리 풀에서 복제본으로 리디렉션됩니다.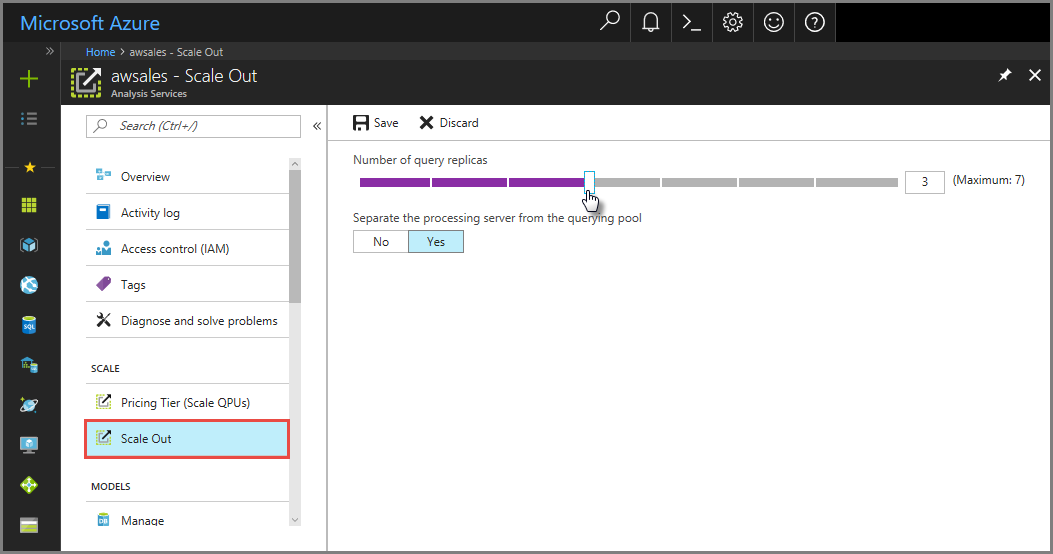
새 쿼리 복제본 서버를 프로비전하려면 저장을 클릭합니다.
처음으로 서버에 대한 스케일 아웃을 구성하는 경우 주 서버의 모델이 쿼리 풀의 복제본과 자동으로 동기화됩니다. 자동 동기화는 하나 이상의 복제본에 대한 스케일 아웃을 처음 구성할 때만 한 번 수행됩니다. 동일한 서버의 복제본 수에 대한 후속 변경은 다른 자동 동기화를 트리거하지 않습니다. 서버를 0개의 복제본으로 설정한 다음, 복제본을 원하는 수 만큼 다시 스케일 아웃하면 자동 동기화는 다시 발생하지 않습니다.
동기화
동기화 작업은 수동으로 수행하거나 REST API를 사용하여 수행해야 합니다.
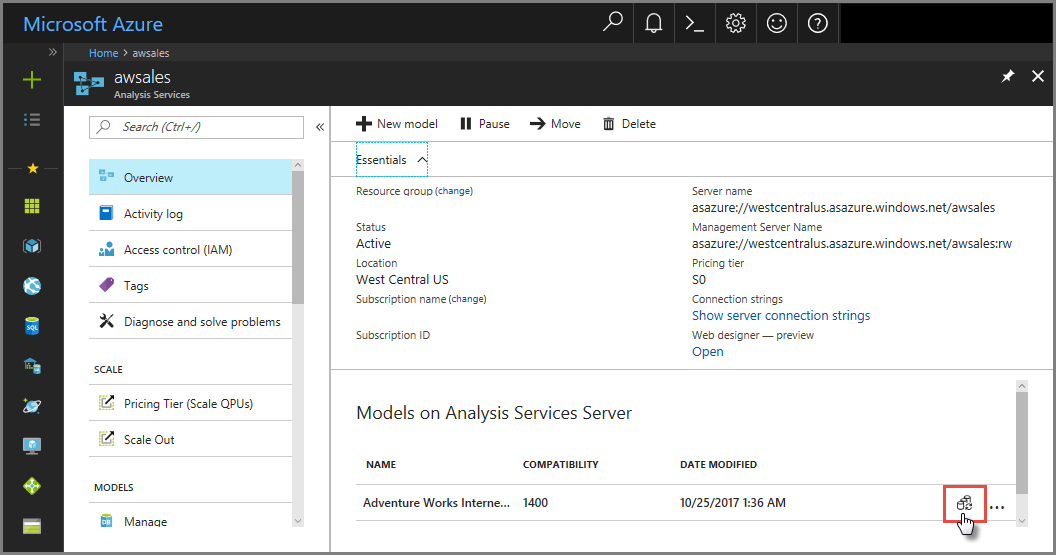
Azure Portal에서
개요> 모델 >모델 동기화에서.
REST API
동기화 작업을 사용합니다.
모델 동기화
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
동기화 상태 가져오기
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
반환 상태 코드:
| 코드 | 설명 |
|---|---|
| -1 | 잘못됨 |
| 0 | 복제 중 |
| 1 | 리하이드레이션 중 |
| 2 | Completed |
| 3 | 실패함 |
| 4 | 종료하는 중 |
PowerShell
참고 항목
Azure Az PowerShell 모듈을 사용하여 Azure와 상호 작용하는 것이 좋습니다. 시작하려면 Azure PowerShell 설치를 참조하세요. Az PowerShell 모듈로 마이그레이션하는 방법에 대한 자세한 내용은 Azure PowerShell을 AzureRM에서 Azure로 마이그레이션을 참조하세요.
PowerShell을 사용하기 전에 최신 Azure PowerShell 모듈을 설치하거나 업데이트합니다.
동기화를 실행하려면 Sync-AzAnalysisServicesInstance를 사용합니다.
쿼리 복제본 수를 설정하려면 Set-AzAnalysisServicesServer를 사용합니다. 선택적 -ReadonlyReplicaCount 매개 변수를 지정합니다.
쿼리 풀에서 처리 서버를 분리하려면 Set-AzAnalysisServicesServer를 사용합니다. Readonly를 사용하도록 선택적 -DefaultConnectionMode 매개 변수를 지정합니다.
자세한 내용은 Az.AnalysisServices 모듈을 사용한 서비스 주체 사용을 참조하세요.
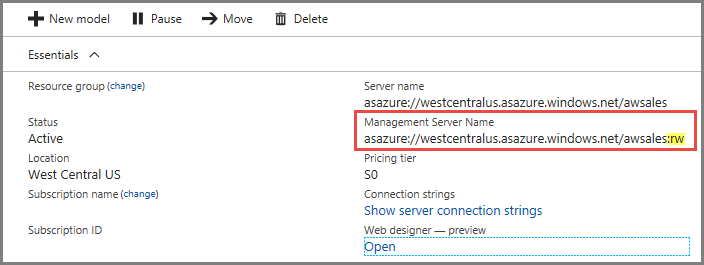
연결
서버의 [개요] 페이지에는 두 개의 서버 이름이 있습니다. 서버에 대한 규모 확장을 아직 구성하지 않은 경우 두 서버 이름은 동일하게 작동합니다. 서버에 대한 규모 확장을 구성한 후에는 연결 형식에 따라 적절한 서버 이름을 지정해야 합니다.
Power BI Desktop, Excel 및 사용자 지정 앱과 같은 최종 사용자 클라이언트 연결의 경우 서버 이름을 사용합니다.
SSMS, Visual Studio 및 PowerShell의 연결 문자열, Azure Function 앱 및 AMO의 경우 관리 서버 이름을 사용합니다. 관리 서버 이름에는 특별한 :rw(읽기/쓰기) 한정자가 포함됩니다. 모든 처리 작업은 (주) 관리 서버에서 수행됩니다.
스케일 업, 스케일 다운 및 스케일 아웃
여러 복제본이 있는 서버의 가격 책정 계층을 변경할 수 있습니다. 모든 복제본에 동일한 가격 책정 계층이 적용됩니다. 크기 조정 작업은 먼저 모든 복제본을 한 번에 가져온 다음 새 가격 책정 계층에 모든 복제본을 표시합니다.
문제 해결
문제: 사용자에게 'ReadOnly' 연결 모드에서 서버 '<서버 이름>' 인스턴스를 찾을 수 없다는 오류가 표시됩니다.
솔루션: 쿼리 풀에서 처리 서버 분리 옵션을 선택하면 기본 연결 문자열(:rw 없이)을 사용하는 클라이언트 연결은 쿼리 풀 복제본으로 리디렉션됩니다. 동기화가 완료되지 않았기 때문에 쿼리 풀의 복제본이 아직 온라인 상태가 아니면 리디렉션된 클라이언트 연결이 실패할 수 있습니다. 연결 실패를 방지하려면 동기화를 수행할 때 쿼리 풀에 두 개 이상의 서버가 있어야 합니다. 다른 서버가 온라인 상태로 유지되는 동안 각 서버는 개별적으로 동기화됩니다. 처리 중에 쿼리 풀에 처리 서버가 없도록 선택한 경우 처리를 위한 풀에서 처리 서버를 제거한 다음, 처리가 완료된 후 동기화되기 전, 다시 풀에 추가하도록 선택할 수 있습니다. 메모리 및 QPU 메트릭을 사용하여 동기화 상태를 모니터링할 수 있습니다.