RAG(Retrieval-Augmented Generation) 솔루션의 이전 단계에서는 문서를 청크로 나누고 청크를 보강했습니다. 이 단계에서는 해당 청크 및 벡터 검색을 수행하려는 메타데이터 필드에 대한 포함을 생성합니다.
이 문서는 시리즈의 일부입니다. 소개읽어보기.
포함은 텍스트와 같은 개체의 수학 표현입니다. 신경망을 학습하는 경우 개체의 많은 표현이 생성됩니다. 각 표현에는 네트워크의 다른 개체에 대한 연결이 있습니다. 포함은 개체의 의미 체계 의미를 캡처하기 때문에 중요합니다.
한 개체의 표현은 다른 개체의 표현과 연결되므로 개체를 수학적으로 비교할 수 있습니다. 다음 예제에서는 포함이 의미 체계 의미와 서로 간의 관계를 캡처하는 방법을 보여 줍니다.
embedding (king) - embedding (man) + embedding (woman) = embedding (queen)
포함은 유사성과 거리의 개념을 사용하여 서로 비교됩니다. 다음 표에서는 포함 항목의 비교를 보여 줍니다.
벡터 비교를 보여 주는 
RAG 솔루션에서는 청크와 동일한 포함 모델을 사용하여 사용자 쿼리를 포함하는 경우가 많습니다. 그런 다음 데이터베이스에서 관련 벡터를 검색하여 의미상 가장 의미 있는 청크를 반환합니다. 관련 청크의 원래 텍스트는 언어 모델에 접지 데이터로 전달됩니다.
메모
벡터는 수학 비교를 허용하는 방식으로 텍스트의 의미 체계 의미를 나타냅니다. 벡터 간의 수학적 근접성이 의미 체계 관련성을 정확하게 반영할 수 있도록 청크를 정리해야 합니다.
포함 모델의 중요성
선택한 포함 모델은 벡터 검색 결과의 관련성에 크게 영향을 줄 수 있습니다. 포함 모델의 어휘를 고려해야 합니다. 모든 포함 모델은 특정 어휘를 사용하여 학습됩니다. 예를 들어 BERT 모델 어휘 크기는 약 30,000단어입니다.
포함 모델의 어휘는 어휘에 없는 단어를 고유한 방식으로 처리하기 때문에 중요합니다. 모델의 어휘에 단어가 없으면 해당 단어에 대한 벡터가 계산됩니다. 이를 위해 많은 모델이 단어를 하위 단어로 구분합니다. 하위 단어를 고유 토큰으로 처리하거나 하위 단어에 대한 벡터를 집계하여 단일 포함을 만듭니다.
예를 들어 히스타민
히스토그램이라는 단어를 다음 하위 단어로 구분하여 보여 주는 
이러한 하위 단어의 의미 체계적 의미는 히스타민
포함 모델 선택
사용 사례에 적합한 포함 모델을 결정합니다. 포함 모델을 선택할 때 포함 모델의 어휘와 데이터 단어 간의 겹침을 고려합니다.
포함 모델을 선택하는 방법의 흐름을 보여 주는 
먼저 도메인별 콘텐츠가 있는지 확인합니다. 예를 들어 문서가 사용 사례, 조직 또는 산업과 관련이 있나요? 도메인의 특이성을 확인하는 좋은 방법은 인터넷에서 콘텐츠에서 엔터티 및 키워드를 찾을 수 있는지 여부를 확인하는 것입니다. 가능한 경우 일반적인 포함 모델도 가능할 수 있습니다.
일반 또는 비 도메인별 콘텐츠
일반 포함 모델을 선택하면 Hugging Face 순위표시작합니다. up-to-date 포함 모델 순위를 가져옵니다. 모델이 데이터에서 작동하는 방식을 평가하고 상위 순위 모델부터 시작합니다.
도메인별 콘텐츠
도메인별 콘텐츠의 경우 도메인별 모델을 사용할 수 있는지 여부를 결정합니다. 예를 들어 데이터가 생물 의학 도메인에 있을 수 있으므로 BioGPT 모델사용할 수 있습니다. 이 언어 모델은 생물 의학 문헌의 큰 컬렉션에 미리 학습된다. 생체 의학 텍스트 마이닝 및 생성에 사용할 수 있습니다. 도메인별 모델을 사용할 수 있는 경우 이러한 모델이 데이터에서 작동하는 방식을 평가합니다.
도메인별 모델이 없거나 도메인별 모델이 잘 수행되지 않는 경우 도메인별 어휘를 사용하여 일반 포함 모델을 미세 조정할 수 있습니다.
중요하다
선택한 모델의 경우 라이선스가 요구 사항에 맞는지 확인하고 모델이 필요한 언어 지원을 제공하는지 확인해야 합니다.
포함 모델 평가
포함 모델을 평가하려면 포함을 시각화하고 질문과 청크 벡터 사이의 거리를 평가합니다.
포함 시각화
t-SNE와 같은 라이브러리를 사용하여 청크의 벡터와 질문을 X-Y 그래프에 그릴 수 있습니다. 그런 다음 청크가 서로 얼마나 멀리 떨어져 있는지, 그리고 질문에서 얼마나 멀리 떨어져 있는지 확인할 수 있습니다. 다음 그래프는 그려진 청크 벡터를 보여 줍니다. 서로 가까운 두 개의 화살표는 두 개의 청크 벡터를 나타냅니다. 다른 화살표는 질문 벡터를 나타냅니다. 이 시각화를 사용하여 청크에서 질문이 얼마나 멀리 떨어져 있는지 이해할 수 있습니다.
포함의 시각화를 보여 주는 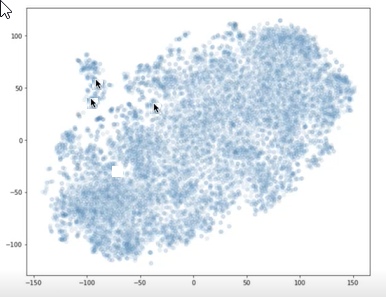
두 개의 화살표는 서로 가까운 점을 가리키고 다른 화살표는 다른 두 화살표에서 멀리 떨어진 플롯 점을 표시합니다.
포함 거리 계산
프로그래밍 방식을 사용하여 포함 모델이 질문 및 청크에서 얼마나 잘 작동하는지 평가할 수 있습니다. 질문 벡터와 청크 벡터 사이의 거리를 계산합니다. 유클리드 거리 또는 맨해튼 거리를 사용할 수 있습니다.
경제 포함
포함 모델을 선택하는 경우 성능과 비용 간의 장차를 탐색해야 합니다. 대용량 포함 모델은 일반적으로 벤치마킹 데이터 세트의 성능이 향상됩니다. 그러나 성능이 향상되면 비용이 추가됩니다. 큰 벡터는 벡터 데이터베이스에 더 많은 공간이 필요합니다. 또한 포함을 비교하려면 더 많은 계산 리소스와 시간이 필요합니다. 작은 포함 모델은 일반적으로 동일한 벤치마크에서 성능이 낮습니다. 벡터 데이터베이스에 공간이 더 적게 필요하고 포함을 비교하는 컴퓨팅 및 시간이 줄어듭니다.
시스템을 디자인할 때 스토리지, 컴퓨팅 및 성능 요구 사항 측면에서 포함 비용을 고려해야 합니다. 실험을 통해 모델의 성능에 대한 유효성을 검사해야 합니다. 공개적으로 사용할 수 있는 벤치마크는 주로 학술 데이터 세트이며 비즈니스 데이터 및 사용 사례에 직접 적용되지 않을 수 있습니다. 요구 사항에 따라 비용보다 성능을 선호하거나 낮은 비용으로 충분한 성능의 절충을 허용할 수 있습니다.