자습서: Azure Monitor에서 KQL 기계 학습 기능을 사용하여 변칙 검색 및 분석
KQL(Kusto 쿼리 언어)에는 시계열 분석, 변칙 검색, 예측 및 근본 원인 분석을 위한 기계 학습 연산자, 함수 및 플러그 인이 포함됩니다. 이러한 KQL 기능을 사용하여 외부 기계 학습 도구로 데이터를 내보내는 오버헤드 없이 Azure Monitor에서 고급 데이터 분석을 수행합니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- 시계열 만들기
- 시계열에서 변칙 식별
- 변칙 검색 설정을 조정하여 결과 구체화
- 변칙의 근본 원인 분석
참고 항목
이 자습서에서는 KQL 쿼리 예제를 실행할 수 있는 Log Analytics 데모 환경에 대한 링크를 제공합니다. 데모 환경의 데이터는 동적이므로 쿼리 결과는 이 문서에 나타난 쿼리 결과와 같지 않습니다. 하지만 사용자 환경 및KQL을 사용하는 모든 Azure Monitor 도구에서 동일한 KQL 쿼리 및 보안 주체를 구현할 수 있습니다.
필수 조건
- 활성 구독이 있는 Azure 계정. 체험 계정을 만듭니다.
- 로그 데이터가 있는 작업 영역입니다.
필수 사용 권한
예를 들어 Log Analytics 읽기 권한자 기본 제공 역할에서 제공하는 것처럼 쿼리하는 Log Analytics 작업 영역에 대한 Microsoft.OperationalInsights/workspaces/query/*/read 권한이 있어야 합니다.
시계열 만들기
KQL make-series 연산자를 사용하여 시계열을 만듭니다.
사용량 테이블의 로그를 기반으로 하는 시계열을 만들겠습니다. 여기에는 청구 가능 데이터와 청구 불가 데이터를 포함하여 작업 영역의 각 테이블이 매시간 수집하는 데이터의 양에 대한 정보가 포함됩니다.
이 쿼리는 를 사용하여 make-series 지난 21일 동안 매일 작업 영역의 각 테이블에서 수집한 청구 가능한 데이터의 총 양을 차트로 작성합니다.
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
결과 차트에서 AzureDiagnostics 및 SecurityEvent 데이터 형식과 같은 몇 가지 변칙을 명확하게 볼 수 있습니다.
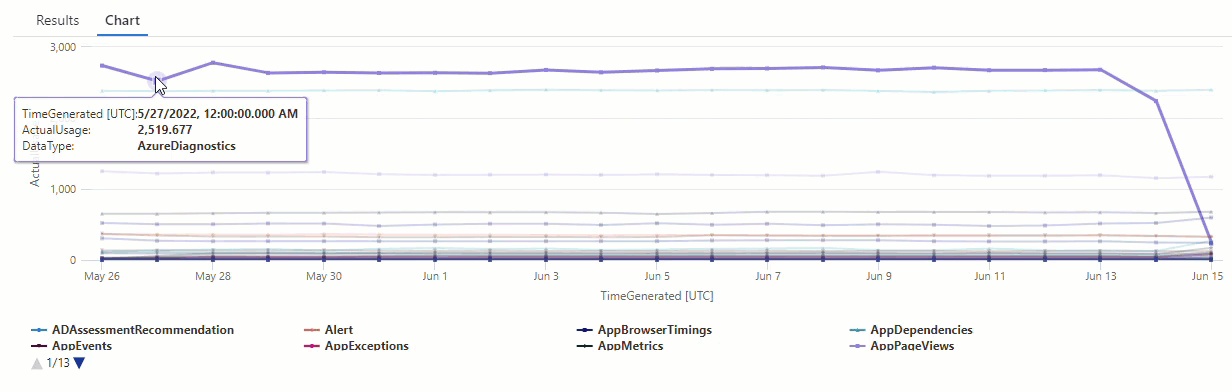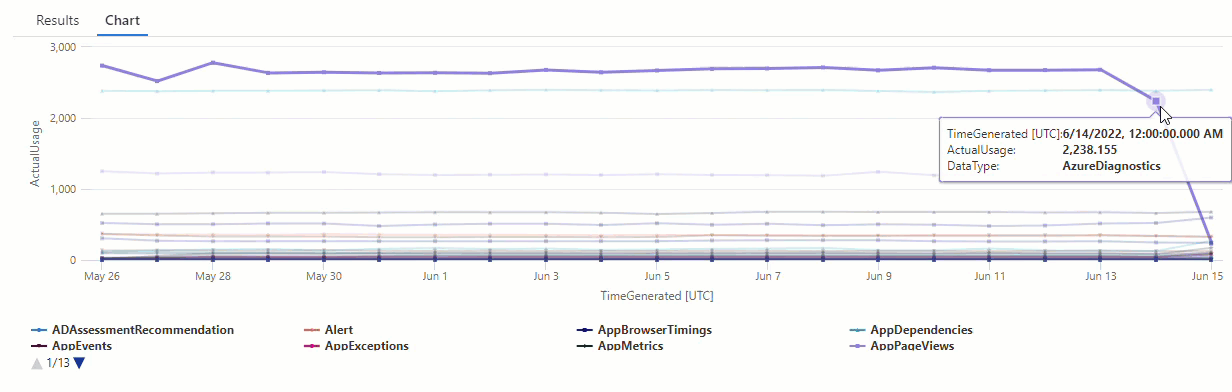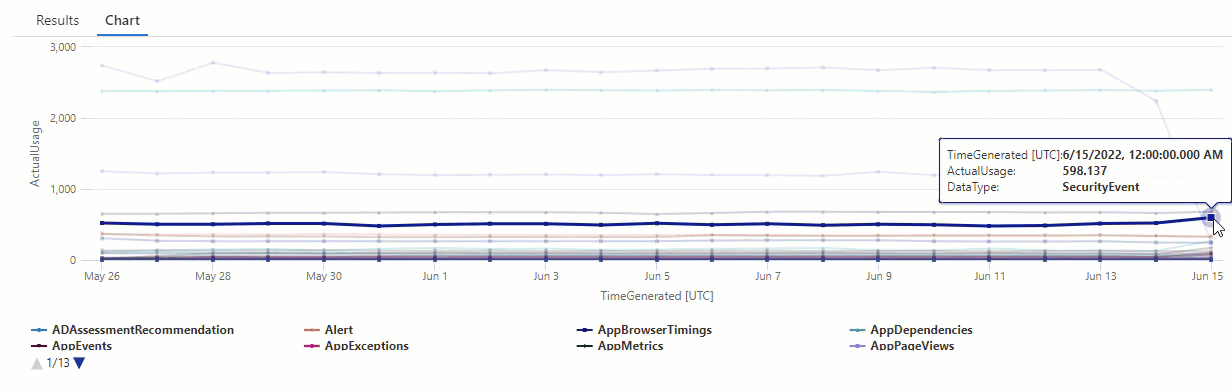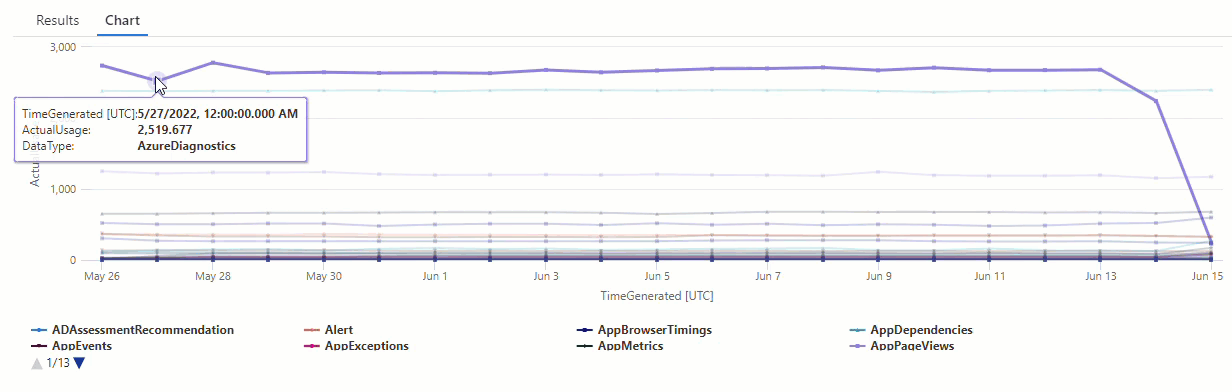
다음으로, KQL 함수를 사용하여 시계열의 모든 변칙을 나열합니다.
참고 항목
make-series 구문 및 사용에 대한 자세한 내용은 make-series 연산자를 참조하세요.
시계열에서 변칙 식별
series_decompose_anomalies() 함수는 일련의 값을 입력으로 사용하고 변칙을 추출합니다.
시계열 쿼리의 결과 집합을 series_decompose_anomalies() 함수에 대한 입력으로 제공해 보겠습니다.
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
이 쿼리는 지난 3주 동안의 모든 테이블에 대한 모든 사용 변칙을 반환합니다.

쿼리 결과를 보면 함수를 확인할 수 있습니다.
- 각 테이블에 대해 예상되는 일일 사용량을 계산합니다.
- 실제 일일 사용량을 예상 사용량과 비교합니다.
- 각 데이터 요소에 변칙 점수를 할당하여 예상 사용량과 실제 사용량의 편차 범위를 나타냅니다.
- 각 테이블의 양수(
1) 및 음수(-1) 변칙을 식별합니다.
참고 항목
series_decompose_anomalies() 구문 및 사용에 대한 자세한 내용은 series_decompose_anomalies()를 참조하세요.
변칙 검색 설정을 조정하여 결과 구체화
필요한 경우 초기 쿼리 결과를 검토하고 쿼리를 조정하는 것이 좋습니다. 입력 데이터의 이상값은 함수의 학습에 영향을 줄 수 있으며 보다 정확한 결과를 얻으려면 함수의 변칙 검색 설정을 조정해야 할 수 있습니다.
AzureDiagnostics 데이터 형식의 변칙에 대한 series_decompose_anomalies() 쿼리 결과를 필터링합니다.

결과는 6월 14일과 6월 15일에 두 가지 변칙을 보여줍니다. 5월 27일과 28일에 다른 변칙을 볼 수 있는 첫 번째 make-series 쿼리의 차트와 이러한 결과를 비교합니다.

결과 차이는 series_decompose_anomalies() 함수가 예상 사용량 값을 기준으로 변칙 점수를 지정하기 때문에 발생하며, 함수는 입력 계열의 전체 값 범위를 기준으로 계산합니다.
함수에서 더 구체화된 결과를 얻으려면 함수의 학습 프로세스에서 계열의 다른 값에 비해 이상값인 6월 15일의 사용량을 제외합니다.
series_decompose_anomalies()함수의 구문은 다음과 같습니다.
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points은(는) 학습(회귀) 프로세스에서 제외할 계열의 끝에 있는 점 수를 지정합니다.
마지막 데이터 포인트를 제외하려면 Test_points을(를) 1(으)로 설정합니다.
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
AzureDiagnostics 데이터 형식에 대한 결과를 필터링합니다.

이제 첫 번째 make-series 쿼리의 차트에 있는 모든 변칙이 결과 집합에 표시됩니다.
변칙의 근본 원인 분석
예상 값을 비정상적인 값과 비교하면 두 집합 간의 차이점의 원인을 이해하는 데 도움이 됩니다.
KQL diffpatterns() 플러그인은 같은 구조의 두 데이터 세트를 비교하여 두 데이터 세트 간 차이를 특성화하는 패턴을 찾습니다.
이 쿼리는 예제의 극단적인 이상값인 6월 15일의 AzureDiagnostics 사용량을 다른 날짜의 테이블 사용량과 비교합니다.
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
쿼리는 테이블의 각 항목이 AnomalyDate(6월 15일) 또는 OtherDates에서 발생하는 것으로 식별합니다. 그런 다음 diffpatterns() 플러그인은 A(예제의 OtherDates) 및 B(예제의 AnomalyDate)라고 하는 이러한 데이터 세트를 분할하고 두 세트의 차이점에 영향을 주는 몇 가지 패턴을 반환합니다.

쿼리 결과를 보면 다음과 같은 차이점을 확인할 수 있습니다.
- 쿼리 시간 범위의 다른 모든 날에 CH1-GEARAMAAKS 리소스에서 24,892,147개의 수집 인스턴스가 있으며 6월 15일에 이 리소스에서 데이터를 수집하지 않습니다. CH1-GEARAMAAKS 리소스의 데이터는 쿼리 시간 범위에서 다른 날의 총 수집의 73.36%와 6월 15일의 총 수집의 0%를 차지합니다.
- 쿼리 시간 범위의 다른 모든 날에 NSG-TESTSQLMI519 리소스에서 2,168,448개의 수집 인스턴스가 있으며, 6월 15일에는 이 리소스에서 110,544개의 수집 인스턴스가 있습니다. NSG-TESTSQLMI519 리소스의 데이터는 쿼리 시간 범위의 다른 날짜에 대한 총 수집의 6.39%, 6월 15일 수집의 25.61%를 차지합니다.
평균적으로 다른 날 기간을 구성하는 20일 동안 NSG-TESTSQLMI519 리소스에서 수집되는 인스턴스는 108,422개입니다(2,168,448을 20으로 나눕니다). 따라서 6월 15일 NSG-TESTSQLMI519 리소스의 수집은 다른 날 이 리소스의 수집과 크게 다르지 않습니다. 그러나 6월 15일에 CH1-GEARAMAAKS에서 수집되지 않으므로 NSG-TESTSQLMI519의 수집은 다른 날짜에 비해 변칙 날짜에 대한 총 수집의 훨씬 더 큰 비율을 차지합니다.
PercentDiffAB 열은 A와 B(|PercentA - PercentB|) 사이의 절대 백분율 포인트 차이를 표시합니다. 이는 두 집합 간의 차이에 대한 주요 측정값입니다. 기본적으로 diffpatterns() 플러그인은 두 데이터 세트 간에 5% 이상의 차이를 반환하지만 이 임계값을 조정할 수 있습니다. 예를 들어 두 데이터 세트 간에 20% 이상의 차이만 반환하려면 위의 쿼리에서 | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20)을(를) 설정할 수 있습니다. 이제 쿼리는 하나의 결과만 반환합니다.

참고 항목
diffpatterns() 구문 및 사용에 대한 자세한 내용은 diff 패턴 플러그인을 참조하세요.
다음 단계
자세히 알아보기: