지능형 애플리케이션
적용 대상:![]() Fabric의 Azure SQL Database
Fabric의 Azure SQL Database![]() SQL 데이터베이스
SQL 데이터베이스
이 문서에서는 OpenAI 및 벡터와 같은 AI(인공 지능) 옵션을 사용하여 Azure SQL Database 및 Azure SQL Database의 이러한 많은 기능을 공유하는 Fabric SQL Database를 사용하여 지능형 애플리케이션을 빌드하는 방법에 대해 간략하게 설명합니다.
샘플 및 예시는 SQL AI 샘플 리포지토리에서 확인하세요.
AI 지원 애플리케이션 빌드에 대한 간략한 개요는 Azure SQL 데이터베이스 필수 시리즈의 이 비디오를 시청하세요.
개요
LLM(대규모 언어 모델)을 사용하면 개발자가 친숙한 사용자 환경을 통해 AI 기반 애플리케이션을 만들 수 있습니다.
애플리케이션에서 LLM을 사용하면 모델이 애플리케이션 데이터베이스에서 적시에 적절한 데이터에 액세스할 수 있을 경우 더 큰 가치와 향상된 사용자 환경이 제공됩니다. 이 프로세스를 RAG(검색 증강 세대)라고 하며 Azure SQL Database 및 패브릭 SQL 데이터베이스에는 이 새로운 패턴을 지원하는 많은 기능이 있어 지능형 애플리케이션을 빌드하는 데 유용한 데이터베이스입니다.
다음 링크는 지능형 애플리케이션을 빌드하기 위한 다양한 옵션의 샘플 코드를 제공합니다.
| AI 옵션 | 설명 |
|---|---|
| Azure OpenAI | RAG에 대한 임베딩을 생성하고 Azure OpenAI에서 지원하는 모든 모델과 통합합니다. |
| 벡터 | 데이터베이스를 저장하고 벡터를 쿼리하는 방법을 알아봅니다. |
| Azure AI 검색 | Azure AI Search와 함께 데이터베이스를 사용하여 데이터에 대한 LLM을 학습합니다. |
| 지능형 애플리케이션 | 어떤 상황에서든 복제할 수 있는 일반적인 패턴을 사용하여 엔드투엔드 솔루션을 만드는 방법을 알아봅니다. |
| Azure SQL 데이터베이스의 Copilot 기술 | Azure SQL 데이터베이스 기반 애플리케이션의 설계, 운영, 최적화 및 상태를 간소화하도록 설계된 AI 지원 환경 세트에 대해 알아보세요. |
| 패브릭 SQL 데이터베이스의 부조종사 기술 | 패브릭 SQL 데이터베이스 기반 애플리케이션의 디자인, 작업, 최적화 및 상태를 간소화하도록 설계된 AI 지원 환경 집합에 대해 알아봅니다. |
Azure OpenAI를 사용하여 RAG를 구현하기 위한 주요 개념
이 섹션에는 Azure SQL Database 또는 패브릭 SQL 데이터베이스에서 Azure OpenAI를 사용하여 RAG를 구현하는 데 중요한 주요 개념이 포함되어 있습니다.
RAG(검색 증강 생성)
RAG는 외부 원본에서 추가 데이터를 검색하여 관련 정보 응답을 생성하는 LLM의 기능을 향상시키는 기술입니다. 예를 들어 RAG는 사용자의 질문 또는 프롬프트와 관련된 기본 관련 지식이 포함된 문서 또는 문서를 쿼리합니다. LLM은 응답을 생성할 때 이 검색된 데이터를 참조로 사용할 수 있습니다. 다음은 Azure SQL 데이터베이스을 사용하는 간단한 RAG 패턴의 예시입니다.
- 테이블에 데이터를 삽입합니다.
- Azure Synapse Link에 Azure SQL 데이터베이스 연결.
- Azure OpenAI GPT4 모델 만들기 및 Azure AI Search에 연결.
- 애플리케이션 및 Azure SQL 데이터베이스에서 학습된 Azure OpenAI 모델을 사용하여 데이터에 대해 채팅 및 질문.
프롬프트 엔지니어링을 사용하는 RAG 패턴은 모델에 더 많은 컨텍스트 정보를 제공하여 응답 품질을 향상시키는 용도로 사용됩니다. RAG를 사용하면 모델이 생성 프로세스에 관련 외부 원본을 통합하여 보다 광범위한 기술 자료를 적용할 수 있으므로 보다 포괄적이고 정보에 입각한 응답을 제공합니다. LLM 그라운딩에 대한 자세한 내용은 LLM 그라운딩 - Microsoft 커뮤니티 허브를 참조하세요.
프롬프트 및 프롬프트 엔지니어링
프롬프트는 LLM에 대한 명령 또는 LLM이 빌드할 수 있는 컨텍스트 데이터로 사용할 수 있는 특정 텍스트 또는 정보를 나타냅니다. 프롬프트는 질문, 문 또는 코드 조각과 같은 다양한 형식을 사용할 수 있습니다.
LLM에서 응답을 생성하는 데 사용할 수 있는 프롬프트:
- 지침: LLM에 지시문을 제공합니다.
- 기본 콘텐츠: 처리를 위해 LLM에 정보를 제공합니다.
- 예: 모델을 특정 작업 또는 프로세스로 조건부에 맞게 조정하는 데 도움을 줍니다.
- 큐: LLM의 출력을 올바른 방향으로 지시합니다.
- 콘텐츠 지원: LLM이 출력을 생성하는 데 사용할 수 있는 추가 정보를 나타냅니다.
시나리오에 대한 좋은 프롬프트를 만드는 프로세스를 프롬프트 엔지니어링이라고 합니다. 프롬프트 엔지니어링에 대한 프롬프트 및 모범 사례에 대한 자세한 내용은 Azure OpenAI 서비스를 참조하세요.
토큰
토큰은 입력 텍스트를 더 작은 세그먼트로 분할하여 생성된 작은 텍스트 청크입니다. 이러한 세그먼트는 단어 또는 문자 그룹일 수 있으며 한 문자에서 전체 단어까지 길이가 다를 수 있습니다. 예를 들어 단어 hamburger는 ham, bur, ger 등의 토큰으로 나뉘며, pear와 같은 짧고 일반적인 단어는 단일 토큰으로 간주됩니다.
Azure OpenAI에서 API에 제공된 입력 텍스트는 토큰(토큰화됨)으로 전환됩니다. 각 API 요청에서 처리되는 토큰 수는 입력, 출력 및 요청 매개 변수의 길이와 같은 요소에 따라 달라집니다. 처리 중인 토큰의 수량은 모델의 응답 시간과 처리량에도 영향을 줍니다. 각 모델이 Azure OpenAI의 단일 요청/응답에서 사용할 수 있는 토큰 양에는 제한이 있습니다. 자세한 내용은 Azure OpenAI 서비스 할당량 및 제한을 참조하세요.
벡터
벡터는 일부 데이터에 대한 정보를 나타낼 수 있는 정렬된 숫자 배열(일반적으로 부동 소수)입니다. 예를 들어 이미지를 픽셀 값의 벡터로 표시하거나 텍스트 문자열을 벡터 또는 ASCII 값으로 나타낼 수 있습니다. 데이터를 벡터로 변환하는 프로세스를 벡터화라고 합니다. 자세한 내용은 벡터를 참조 하세요.
포함
포함은 데이터의 중요한 기능을 나타내는 벡터입니다. 포함은 딥 러닝 모델을 사용하여 학습되는 경우가 많으며, 기계 학습 및 AI 모델은 이를 기능으로 활용했습니다. 포함은 유사한 개념 간의 의미 체계 유사성을 캡처할 수도 있습니다. 예를 들어 단어 person 및 human에 대한 포함을 생성할 때 단어가 의미상 유사하므로 해당 포함(벡터 표현)이 값에서 유사할 것으로 예상합니다.
Azure OpenAI는 텍스트 데이터에서 포함을 만들기 위한 모델을 제공합니다. 서비스는 텍스트를 토큰으로 나누고 OpenAI에서 미리 학습한 모델을 사용하여 포함을 생성합니다. 자세한 내용은 Azure OpenAI를 사용하여 임베드 만들기를 참조하세요.
벡터 검색
벡터 검색은 특정 쿼리 벡터와 의미상 유사한 데이터 세트의 모든 벡터를 찾는 프로세스를 나타냅니다. 따라서 단어 human은 전체 사전에서 의미상 유사한 단어를 검색하며, 단어 person(을)를 일치하는 단어로 찾습니다. 이 근접성 또는 거리는 코사인 유사성과 같은 유사성 메트릭을 사용하여 측정됩니다. 벡터가 비슷할수록 벡터 사이의 거리가 작아집니다.
수백만 개의 문서에 대한 쿼리가 있고 데이터에서 가장 유사한 문서를 찾으려는 시나리오를 떠올려 보세요. Azure OpenAI를 사용하여 데이터 및 쿼리 문서에 대한 포함을 만들 수 있습니다. 그런 다음 벡터 검색을 수행하여 데이터 세트에서 가장 유사한 문서를 찾을 수 있습니다. 그러나 몇 가지 예시에서 벡터 검색을 수행하는 것은 간단합니다. 수천 또는 수백만 개의 데이터 요소에서 이러한 검색을 수행하는 것은 어려울 수 있습니다. 또한 전체 검색과 대기 시간, 처리량, 정확도 및 비용을 비롯한 ANN(가장 인접한 항목) 검색 방법 간에 장단점이 있으며, 모두 애플리케이션의 요구 사항에 따라 달라질 수 있습니다.
Azure SQL Database의 벡터는 다음 섹션에 설명된 대로 효율적으로 저장 및 쿼리할 수 있으므로 성능이 뛰어난 가장 가까운 인접 항목을 정확하게 검색할 수 있습니다. 정확도와 속도 중에서 결정할 필요가 없습니다. 둘 다 사용할 수 있습니다. 통합 솔루션에 데이터와 함께 벡터 포함을 저장하면 데이터 동기화를 관리할 필요가 최소화되고 AI 앱 개발을 위한 시장 출시 시간이 가속화됩니다.
Azure OpenAI
임베딩은 실제 세계를 데이터로 나타내는 프로세스입니다. 텍스트, 이미지 또는 소리를 포함으로 변환할 수 있습니다. Azure OpenAI 모델은 실제 정보를 포함으로 변환할 수 있습니다. 모델은 REST 엔드포인트로 사용할 수 있으므로 sp_invoke_external_rest_endpoint 시스템 저장 프로시저를 사용하여 Azure SQL 데이터베이스에서 쉽게 사용할 수 있습니다.
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
REST 서비스에 대한 호출을 사용하여 포함을 가져오는 것은 SQL Database 및 OpenAI를 사용할 때 사용하는 통합 옵션 중 하나일 뿐입니다. 사용 가능한 모든 모델이 Azure SQL 데이터베이스에 저장된 데이터에 액세스하여 다음 예시와 같이 사용자가 데이터와 상호 작용할 수 있는 솔루션을 만들 수 있습니다.
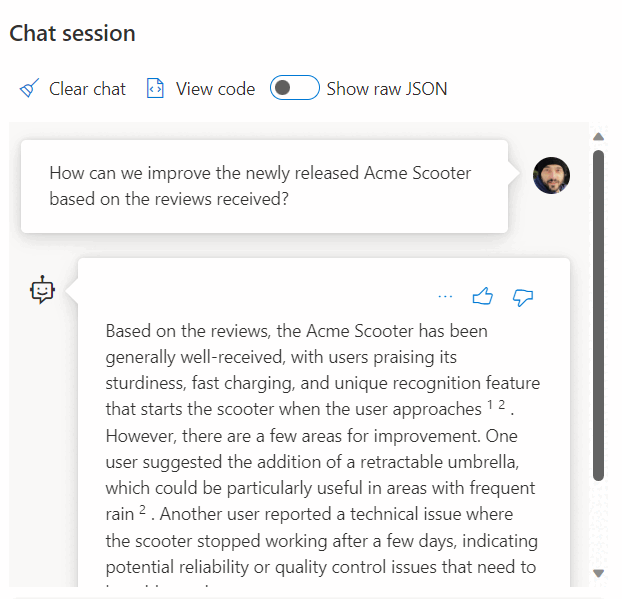
SQL Database 및 OpenAI 사용에 대한 추가 예시는 다음 문서를 참조하세요.
- Azure OpenAI Service(DALL-E) 및 Azure SQL 데이터베이스를 사용하여 이미지 생성하기
- Azure SQL 데이터베이스에서 OpenAI REST 엔드포인트 사용하기
벡터
벡터 데이터 형식
2024년 11월에 새 벡터 데이터 형식이 Azure SQL Database에 도입되었습니다.
전용 벡터 형식을 사용하면 벡터 데이터의 효율적이고 최적화된 저장이 가능하며 개발자가 벡터 및 유사성 검색 구현을 간소화하는 데 도움이 되는 함수 집합이 제공됩니다. 새 VECTOR_DISTANCE 함수를 사용하여 코드 한 줄에서 두 벡터 간의 거리를 계산할 수 있습니다. 벡터 데이터 형식 및 관련 함수에 대한 자세한 내용은 SQL 데이터베이스 엔진 벡터 개요를 참조하세요.
예시:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
이전 버전의 SQL Server의 벡터
SQL Server 2022까지의 이전 버전의 SQL Server 엔진에는 네이티브 벡터 형식이 없지만 벡터는 순서가 지정된 튜플에 지나지 않으며 관계형 데이터베이스는 튜플을 관리하는 데 탁월합니다. 튜플은 테이블의 행에 대한 공식 용어입니다.
Azure SQL 데이터베이스는 columnstore 인덱스 및 일괄 처리 모드 실행도 지원합니다. 벡터 기반 접근 방식은 일괄 처리 모드 처리에 사용됩니다. 즉, 일괄 처리의 각 열에는 벡터로 저장되는 고유한 메모리 위치가 있습니다. 이렇게 하면 일괄 처리에서 데이터를 더 빠르고 효율적으로 처리할 수 있습니다.
다음 예에서는 SQL Database에 벡터를 저장할 수 있는 방법을 보여줍니다.
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
OpenAI를 사용하여 이미 생성된 포함 항목과 함께 Wikipedia 문서의 일반적인 하위 집합을 사용하는 예시는 Azure SQL 데이터베이스 및 OpenAI를 사용한 벡터 유사성 검색을 참조하세요.
Azure SQL 데이터베이스에서 벡터 검색을 활용하는 또 다른 옵션은 통합된 벡터화 기능을 사용하여 Azure AI와 통합하는 것입니다. Azure SQL 데이터베이스 및Azure AI Search를 사용한 벡터 검색
Azure AI 검색
Azure SQL 데이터베이스 및 Azure AI Search를 사용하여 RAG 패턴을 구현합니다. Azure OPENAI 및 Azure SQL 데이터베이스와 Azure AI Search를 통합하여 모델을 학습하거나 미세 조정할 필요 없이 Azure SQL 데이터베이스에 저장된 데이터에서 지원되는 채팅 모델을 실행할 수 있습니다. 데이터에 대해 모델을 실행하면 더욱 정확하고 빠르게 데이터를 기반으로 채팅하고 분석할 수 있습니다.
지능형 애플리케이션
Azure SQL 데이터베이스를 사용하여 다음 다이어그램과 같이 추천 및 RAG(검색 보강 세대)와 같은 AI 기능을 포함하는 지능형 애플리케이션을 빌드할 수 있습니다.

세션 추상을 샘플 데이터 세트로 사용하여 AI 지원 애플리케이션을 빌드하는 엔드투엔드 샘플은 다음을 참조하세요.
LangChain 통합
LangChain은 언어 모델을 통해 구동되는 애플리케이션을 개발하기 위한 잘 알려진 프레임워크입니다. LangChain을 사용하여 사용자 고유의 데이터에 챗봇을 만드는 방법을 보여 주는 예제는 다음을 참조하세요.
- langchain-sqlserver PyPI 패키지
LangChain에서 Azure SQL을 사용하는 방법에 대한 몇 가지 샘플:
엔드 투 엔드 예제:
- Azure SQL, Langchain 및 Chainlit를 사용하여 1시간 만에 사용자 고유의 데이터에 챗봇 빌드: UI에 대한 LLM 호출 및 Chainlit를 오케스트레이션하기 위해 Langchain을 사용하여 사용자 고유의 데이터에 RAG 패턴을 사용하여 챗봇을 빌드합니다.
- Azure OpenAI GPT-4를 사용하여 Azure SQL용 DB Copilot 빌드: 자연어를 사용하여 데이터베이스를 쿼리하는 부조종사와 유사한 환경을 구축합니다.
의미 체계 커널 통합
의미 체계 커널은 기존 코드를 호출할 수 있는 에이전트를 쉽게 빌드할 수 있는 오픈 소스 SDK입니다. 확장성이 뛰어난 SDK로서 OpenAI, Azure OpenAI, Hugging Face 등의 모델에서 의미 체계 커널을 사용할 수 있습니다. 기존 C#, Python 및 Java 코드를 이러한 모델과 결합하여 질문에 답변하고 프로세스를 자동화하는 에이전트를 빌드할 수 있습니다.
의미 체계 커널이 AI 지원 솔루션을 쉽게 빌드하는 데 도움이 되는 방법의 예는 다음과 같습니다.
- 궁극적인 챗봇?: 궁극적인 사용자 환경을 위해 NL2SQL 및 RAG 패턴을 모두 사용하여 사용자 고유의 데이터에 챗봇을 빌드합니다.
Azure SQL 데이터베이스의 Microsoft Copilot 기술
Azure SQL 데이터베이스의 Microsoft Copilot 기술(미리 보기)은 Azure SQL 데이터베이스 기반 애플리케이션의 설계, 운영, 최적화 및 상태를 간소화하도록 설계된 AI 지원 환경 세트입니다. Copilot은 자연어를 SQL로 변환하고 데이터베이스 관리를 위한 자가 진단을 제공하여 생산성을 향상시킬 수 있습니다.
Copilot은 사용자 질문에 대한 관련 답변을 제공하고 데이터베이스 컨텍스트, 설명서, 동적 관리 뷰, 쿼리 저장소 및 기타 기술 자료를 활용하여 데이터베이스 관리를 간소화합니다. 예시:
- 데이터베이스 관리자는 독립적으로 데이터베이스를 관리하고 문제를 해결하거나 데이터베이스의 성능과 기능에 대해 자세히 알아볼 수 있습니다.
- 개발자는 T-SQL 쿼리를 생성하기 위해 텍스트나 대화에서 하듯이 데이터에 대해 질문할 수 있습니다. 또한 개발자는 생성된 쿼리에 대한 자세한 설명을 통해 보다 빠르게 쿼리를 작성하는 방법을 배울 수 있습니다.
참고 항목
Azure SQL 데이터베이스의 Microsoft Copilot 기술은 현재 제한된 수의 얼리어답터를 위한 미리 보기로 제공됩니다. 이 프로그램에 등록하려면 Azure SQL 데이터베이스의 Copilot에 대한 액세스 요청: 미리 보기를 방문하세요.
Azure SQL 데이터베이스용 Copilot의 미리 보기에는 두 가지 Azure Portal 환경이 포함되어 있습니다.
| 포털 위치 | 환경 |
|---|---|
| Azure Portal 쿼리 편집기 | 자연어를 SQL로 변환: Azure SQL 데이터베이스에 대한 Azure Portal 쿼리 편집기 내의 이 환경은 자연어 쿼리를 SQL로 변환하여 데이터베이스 상호 작용을 보다 직관적으로 만듭니다. 자연어를 SQL로 변환하는 기능에 대한 자습서 및 예제를 보려면 Azure 포털 쿼리 편집기(미리 보기)에서 자연어를 SQL로을 참조하세요. |
| Azure용 Microsoft Copilot | Azure Copilot 통합: 이 환경은 Azure용 Microsoft Copilot에 Azure SQL 기술을 추가하여 자체 안내 지원을 제공하고 고객이 독립적으로 데이터베이스를 관리하고 문제를 해결할 수 있도록 지원합니다. |
자세한 내용은 Azure SQL 데이터베이스의 Microsoft Copilot 기술(미리 보기)에 대한 자주 묻는 질문을 참조하세요.
Fabric SQL 데이터베이스의 Microsoft Copilot 기술(미리 보기)
Microsoft Fabric(미리 보기) 의 SQL 데이터베이스에 대한 부조종사에는 다음 기능에 대한 통합 AI 지원이 포함되어 있습니다.
코드 완성: SQL 쿼리 편집기에서 T-SQL 작성을 시작하고 Copilot는 쿼리를 완료하는 데 도움이 되는 코드 제안을 자동으로 생성합니다. Tab 키는 코드 제안을 수락하거나 계속 입력하여 제안을 무시합니다.
빠른 작업: SQL 쿼리 편집 기의 리본에서 수정 및 설명 옵션은 빠른 작업입니다. 선택한 SQL 쿼리를 강조 표시하며, 빠른 작업 버튼 중 하나를 선택하여 쿼리에서 선택한 작업을 수행할 수 있습니다.
수정: Copilot는 오류 메시지가 발생하면 코드의 오류를 수정할 수 있습니다. 오류 시나리오에는 올바르지 않거나 지원되지 않는 T-SQL 코드, 잘못된 맞춤법 등이 포함될 수 있습니다. 또한 Copilot은 변경 내용을 설명하고 SQL 모범 사례를 제안하는 주석을 제공합니다.
설명: 부조종사에서는 SQL 쿼리 및 데이터베이스 스키마에 대한 자연어 설명을 주석 형식으로 제공할 수 있습니다.
채팅 창: 채팅 창을 사용하여 자연어를 통해 코필로트에 질문을 합니다. 부조종사에서는 질문된 질문에 따라 생성된 SQL 쿼리 또는 자연어로 응답합니다.
자연어에서 SQL로: 일반 텍스트 요청에서 T-SQL 코드를 생성하고 워크플로를 가속화하기 위해 질문할 질문을 받습니다.
문서 기반 Q&A: 일반적인 SQL 데이터베이스 기능에 대한 부조종사 질문을 하고 자연어로 응답합니다. 부조종사도 요청과 관련된 설명서를 찾는 데 도움이 됩니다.
SQL 데이터베이스의 부조종사에서는 테이블 및 뷰 이름, 열 이름, 기본 키 및 외래 키 메타데이터를 활용하여 T-SQL 코드를 생성합니다. SQL Database용 Copilot에서는 T-SQL 제안을 생성하는 데 테이블의 데이터를 사용하지 않습니다.