Azure Cosmos DB에서 Azure Data Explorer로 데이터 수집
Azure Data Explorer는 변경 피드를 사용하여 Azure Cosmos DB for NoSql에서 데이터 수집을 지원합니다. Cosmos DB 변경 피드 데이터 연결은 Cosmos DB 변경 피드를 수신 대기하고 데이터를 Data Explorer 테이블에 수집하는 수집 파이프라인입니다. 변경 피드는 새 문서와 업데이트된 문서를 수신하지만 삭제를 로그하지는 않습니다. Azure Data Explorer의 데이터 수집에 대한 일반적인 정보는 Azure Data Explorer 데이터 수집 개요를 참조하세요.
각 데이터 연결은 특정 Cosmos DB 컨테이너를 수신 대기하고 데이터를 지정된 테이블로 수집합니다(둘 이상의 연결은 단일 테이블에서 수집할 수 있습니다). 수집 메서드는 스트리밍 수집(사용하도록 설정된 경우) 및 대기 중인 수집을 지원합니다.
이 문서에서는 System Managed Identity를 사용하여 데이터를 Azure Data Explorer로 수집하기 위해 Cosmos DB 변경 피드 데이터 연결을 설정하는 방법을 알아봅니다. 시작하기 전에 고려 사항을 검토합니다.
커넥터를 설정하려면 다음 단계를 따릅니다.
1단계: Azure Data Explorer 테이블 선택 및 해당 테이블 매핑 구성
2단계: Cosmos DB 데이터 연결 만들기
3단계: 데이터 연결 테스트
사전 요구 사항
- Azure 구독 평가판 Azure 계정을 만듭니다.
- Azure Data Explorer 클러스터 및 데이터베이스. 클러스터 및 데이터베이스를 만듭니다.
- NoSQL에 대한 Cosmos DB 계정의 컨테이너입니다.
- 예를 들어 프라이빗 엔드포인트를 사용하여 Cosmos DB 계정이 네트워크 액세스를 차단하는 경우 Cosmos DB 계정에 대한 관리형 프라이빗 엔드포인트를 만들어야 합니다. 클러스터에서 변경 피드 API를 호출하려면 이 작업이 필요합니다.
1단계: Azure Data Explorer 테이블 선택 및 해당 테이블 매핑 구성
데이터 연결을 만들기 전에 수집된 데이터를 저장할 테이블을 만들고 원본 Cosmos DB 컨테이너의 스키마와 일치하는 매핑을 적용합니다. 시나리오에 단순한 필드 매핑 이상이 필요한 경우 업데이트 정책을 사용하여 변경 피드에서 수집된 데이터를 변환하고 매핑할 수 있습니다.
다음은 Cosmos DB 컨테이너에 있는 항목의 샘플 스키마를 보여 줍니다.
{
"id": "17313a67-362b-494f-b948-e2a8e95e237e",
"name": "Cousteau",
"_rid": "pL0MAJ0Plo0CAAAAAAAAAA==",
"_self": "dbs/pL0MAA==/colls/pL0MAJ0Plo0=/docs/pL0MAJ0Plo0CAAAAAAAAAA==/",
"_etag": "\"000037fc-0000-0700-0000-626a44110000\"",
"_attachments": "attachments/",
"_ts": 1651131409
}
다음 단계에서 테이블을 만들고 테이블 매핑을 적용합니다.
Azure Data Explorer 웹 UI의 왼쪽 탐색 메뉴에서 쿼리를 선택한 다음 테이블을 만들 데이터베이스를 선택합니다.
다음 명령을 실행하여 TestTable이라는 테이블을 만듭니다.
.create table TestTable(Id:string, Name:string, _ts:long, _timestamp:datetime)다음 명령을 실행하여 테이블 매핑을 만듭니다.
이 명령은 다음과 같이 Cosmos DB JSON 문서의 사용자 지정 속성을 TestTable 테이블의 열에 매핑합니다.
Cosmos DB 속성 테이블 열 변환 id Id None name Name None _ts _ts None _ts _timestamp _ts(UNIX 초)를 _timestamp()로 datetime변환 하는 데 사용됩니다DateTimeFromUnixSeconds.참고 항목
다음 타임스탬프 열을 사용하는 것이 좋습니다.
- _ts: 이 열을 사용하여 Cosmos DB와 데이터를 조정합니다.
- _timestamp: Kusto 쿼리에서 효율적인 시간 필터를 실행하려면 이 열을 사용합니다. 자세한 내용은 쿼리 모범 사례를 참조하세요.
.create table TestTable ingestion json mapping "DocumentMapping" ``` [ {"column":"Id","path":"$.id"}, {"column":"Name","path":"$.name"}, {"column":"_ts","path":"$._ts"}, {"column":"_timestamp","path":"$._ts", "transform":"DateTimeFromUnixSeconds"} ] ```
업데이트 정책으로 데이터 변환 및 매핑
시나리오에 단순한 필드 매핑 이상이 필요한 경우 업데이트 정책을 사용하여 변경 피드에서 수집된 데이터를 변환하고 매핑할 수 있습니다.
업데이트 정책은 데이터가 테이블에 수집될 때 데이터를 변환하는 방법입니다. Kusto 쿼리 언어로 작성되었으며 수집 파이프라인에서 실행됩니다. 다음 시나리오와 같이 Cosmos DB 변경 피드 수집에서 데이터를 변환하는 데 사용할 수 있습니다.
- 문서에는
mv-expand연산자를 사용하여 여러 행에서 변환되는 경우 쿼리하기가 더 쉬운 배열이 포함되어 있습니다. - 문서를 필터링하려고 합니다. 예를 들어,
where연산자를 사용하여 형식별로 문서를 필터링할 수 있습니다. - 테이블 매핑으로 표현할 수 없는 복잡한 논리가 있습니다.
업데이트 정책을 만들고 관리하는 방법에 대한 자세한 내용은 업데이트 정책 개요를 참조하세요.
2단계: Cosmos DB 데이터 연결 만들기
다음 방법을 사용하여 데이터 커넥터를 만들 수 있습니다.
Azure Portal에서 클러스터 개요 페이지로 이동한 다음 시작 탭을 선택합니다.
데이터 수집 타일에서 데이터 연결 만들기>Cosmos DB를 선택합니다.
Cosmos DB 데이터 연결 만들기 창에서 테이블의 정보로 양식을 작성합니다.
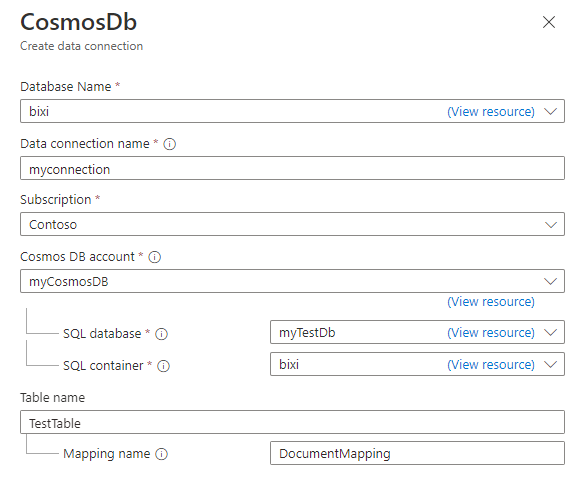
필드 Description 데이터베이스 이름 데이터를 수집하려는 Azure Data Explorer 데이터베이스를 선택합니다. 데이터 연결 이름 데이터 연결의 이름을 지정합니다. 구독 Cosmos DB NoSQL 계정이 포함된 구독을 선택합니다. Cosmos DB 계정 데이터를 수집하려는 Cosmos DB 계정을 선택합니다. SQL 데이터베이스 데이터를 수집하려는 Cosmos DB 데이터베이스를 선택합니다. SQL 컨테이너 데이터를 수집하려는 Cosmos DB 컨테이너를 선택합니다. 테이블 이름 데이터를 수집하려는 Azure Data Explorer 테이블 이름을 지정합니다. 매핑 이름 선택적으로 데이터 연결에 사용할 매핑 이름을 지정합니다. 필요한 경우 고급 설정 섹션에서 다음을 수행합니다.
이벤트 검색 시작 날짜를 지정합니다. 커넥터가 데이터 수집을 시작하는 시간입니다. 시간을 지정하지 않으면 커넥터는 데이터 연결을 만든 시간부터 데이터 수집을 시작합니다. 권장 날짜 형식은
yyyy-MM-ddTHH:mm:ss.fffffffZ로 지정된 ISO 8601 UTC 표준입니다.사용자 할당을 선택한 다음 ID를 선택합니다. 기본적으로 연결에는 시스템 할당 관리 ID가 사용됩니다. 필요한 경우 사용자 할당 ID를 사용할 수 있습니다.
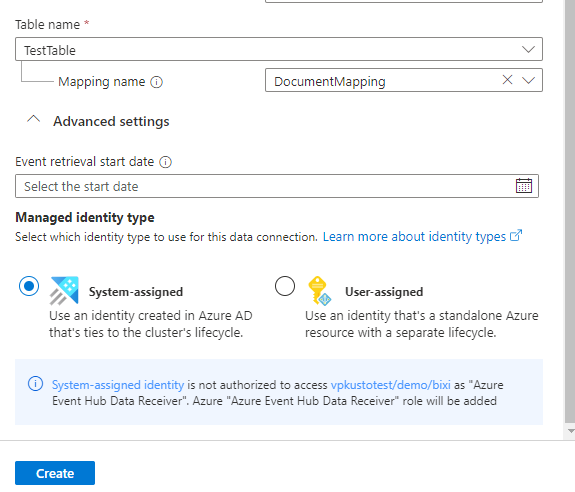
만들기를 선택하여 데이터 연결을 만듭니다.
3단계: 데이터 연결 테스트
Cosmos DB 컨테이너에서 다음 문서를 삽입합니다.
{ "name":"Cousteau" }Azure Data Explorer 웹 UI에서 다음 쿼리를 실행합니다.
TestTable결과 집합은 다음 이미지와 같이 표시됩니다.

참고 항목
Azure Data Explorer에는 수집 프로세스를 최적화하도록 설계된 큐에 대기 중인 데이터 수집에 대한 집계(일괄 처리) 정책이 있습니다. 기본 일괄 처리 정책은 일괄 처리에 대해 최대 지연 시간 5분, 총 크기 1G 또는 1000개의 Blob 중 하나가 충족되면 일괄 처리를 봉인하도록 구성됩니다. 따라서 대기 시간이 발생할 수 있습니다. 자세한 내용은 일괄 처리 정책을 참조하세요. 대기 시간을 줄이려면 스트리밍을 지원하도록 테이블을 구성합니다. 스트리밍 정책을 참조하세요.
고려 사항
다음 고려 사항은 Cosmos DB 변경 피드에 적용됩니다.
변경 피드는 삭제 이벤트를 노출하지 않습니다.
Cosmos DB 변경 피드에는 새 문서와 업데이트된 문서만 포함됩니다. 삭제된 문서에 대해 알아야 하는 경우 피드에서 소프트 마커를 사용하여 Cosmos DB 문서를 삭제된 것으로 표시하도록 구성할 수 있습니다. 문서가 삭제되었는지 여부를 나타내는 업데이트 이벤트에 속성이 추가되었습니다. 그런 다음 쿼리에서
where연산자를 사용하여 필터링할 수 있습니다.예를 들어, 삭제된 속성을 IsDeleted라는 테이블 열에 매핑하는 경우 다음 쿼리를 사용하여 삭제된 문서를 필터링할 수 있습니다.
TestTable | where not(IsDeleted)변경 피드는 문서의 최신 업데이트만 노출합니다.
두 번째 고려 사항의 결과를 이해하려면 다음 시나리오를 검토합니다.
Cosmos DB 컨테이너에는 A 및 B 문서가 포함되어 있습니다. foo라는 속성에 대한 변경 내용은 다음 표에 나와 있습니다.
문서 ID 속성 foo 이벤트 문서 타임스탬프(_ts) A 빨강 만들기 10 b 파랑 만들기 20 A 주황색 업데이트 30 변수를 잠그기 위한 분홍색 Update 40 b 보라색 업데이트 50 A 암적색 업데이트 50 b 네온블루 업데이트 70 변경 피드 API는 정기적인 간격(일반적으로 몇 초마다)으로 데이터 커넥터에 의해 폴링됩니다. 각 설문에는 호출 사이에 컨테이너에서 발생한 변경 내용이 포함되지만 문서당 최신 버전의 변경 내용만 포함됩니다.
이 문제를 설명하기 위해 다음 표와 같이 타임스탬프가 15, 35, 55 및 75인 API 호출 시퀀스를 고려합니다.
API 호출 타임스탬프 문서 ID 속성 foo 문서 타임스탬프(_ts) 15 A 빨강 10 35 b 파랑 20 35 A 주황색 30 55 b 보라색 50 55 A 암적색 60 75 b 네온블루 70 API 결과를 Cosmos DB 문서의 변경 내용 목록과 비교하면 일치하지 않는다는 것을 알 수 있습니다. 타임스탬프 40의 변경 테이블에서 강조 표시된 A 문서에 대한 업데이트 이벤트는 API 호출 결과에 나타나지 않습니다.
이벤트가 표시되지 않는 이유를 이해하기 위해 타임스탬프 35와 55에서 API 호출 사이의 문서 A에 대한 변경 내용을 조사합니다. 이 두 호출 사이에 A 문서가 다음과 같이 두 번 변경되었습니다.
문서 ID 속성 foo 이벤트 문서 타임스탬프(_ts) A 분홍색 업데이트 40 A 암적색 업데이트 50 타임스탬프 55에서 API 호출이 이루어지면 변경 피드 API가 문서의 최신 버전을 반환합니다. 이 경우 문서 A의 최신 버전은 타임스탬프 50에서의 업데이트이며, 이 분홍색에서 암적색으로의 foo 속성에 대한 업데이트입니다.
이 시나리오로 인해 데이터 커넥터에서 일부 중간 문서 변경 내용이 누락될 수 있습니다. 예를 들어, 데이터 연결 서비스가 몇 분 동안 중단되거나 문서 변경 빈도가 API 폴링 빈도보다 높은 경우 일부 이벤트가 누락될 수 있습니다. 그러나 각 문서의 최신 상태가 캡처됩니다.
Cosmos DB 컨테이너 삭제 및 다시 만들기는 지원되지 않습니다.
Azure Data Explorer는 피드에서의 "위치"를 검사하여 변경 피드를 추적합니다. 이 작업은 컨테이너의 각 물리적 파티션에서 연속 토큰을 사용하여 수행됩니다. 컨테이너가 삭제/다시 만들어지면 이러한 연속 토큰이 유효하지 않으며 초기화되지 않습니다. 따라서 데이터 연결을 삭제하고 다시 만들어야 합니다.
예상 비용
Cosmos DB 데이터 연결을 사용하는 것이 Cosmos DB 컨테이너의 RU(요청 단위) 사용량에 얼마나 영향을 주나요?
커넥터는 컨테이너의 각 물리적 파티션에서 Cosmos DB 변경 피드 API를 최대 1초까지 호출합니다. 다음 비용은 이러한 호출과 관련이 있습니다.
| 비용 | 설명 |
|---|---|
| 고정 비용 | 고정 비용은 1초마다 실제 파티션당 약 2RU입니다. |
| 가변 비용 | 가변 비용은 문서를 작성하는 데 사용되는 RU의 약 2%이지만 시나리오에 따라 달라질 수 있습니다. 예를 들어 Cosmos DB 컨테이너에 100개의 문서를 작성하는 경우 해당 문서를 작성하는 데 드는 비용은 1,000RU입니다. 커넥터를 사용하여 해당 문서를 읽는 데 드는 해당 비용은 약 2%의 쓰기 비용(약 20RU)입니다. |