Apache Kafka에서 Azure Data Explorer로 데이터 수집
Apache Kafka는 시스템 또는 애플리케이션 간에 데이터를 신뢰성 있게 이동시키는 실시간 스트리밍 데이터 파이프라인을 빌드하기 위한 분산 스트리밍 플랫폼입니다. Kafka Connect는 Apache Kafka와 기타 데이터 시스템 간에 측정 가능하면서 안정적으로 데이터를 스트리밍하기 위한 도구입니다. Kusto Kafka 싱크는 Kafka의 커넥터 역할을 하며 코드를 사용할 필요가 없습니다. Git 리포지토리 또는 Confluent 커넥터 허브에서 싱크 커넥터 jar를 다운로드합니다.
이 문서에서는 Kafka 클러스터 및 Kafka 커넥터 클러스터 설정을 단순화하기 위해 자체 포함된 Docker 설정을 사용하여 Kafka로 데이터를 수집하는 방법을 보여 줍니다.
자세한 내용은 커넥터 Git 리포지토리 및 버전별 정보를 참조하세요.
사전 요구 사항
- Azure 구독 무료 Azure 계정을 만듭니다.
- 기본 캐시 및 보존 정책을 사용하는 Azure Data Explorer 클러스터 및 데이터베이스 입니다.
- Azure CLI
- Docker 및 Docker Compose
Microsoft Entra 서비스 주체를 만듭니다.
Microsoft Entra 서비스 주체는 다음 예제와 같이 Azure Portal을 통하거나 프로그래밍 방식으로 만들 수 있습니다.
이 서비스 주체는 Kusto의 테이블에 데이터를 쓰기 위해 커넥터가 사용하는 ID입니다. Kusto 리소스에 액세스할 수 있는 권한을 이 서비스 주체에 부여합니다.
Azure CLI를 통해 Azure 구독에 로그인합니다. 그런 다음 브라우저에서 인증합니다.
az login서비스 주체를 호스트하는 구독을 선택합니다. 이 단계는 여러 구독이 있는 경우에 필요합니다.
az account set --subscription YOUR_SUBSCRIPTION_GUID서비스 주체를 만듭니다. 이 예시에서는 서비스 주체를
my-service-principal이라고 합니다.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}반환된 JSON 데이터에서 나중에 사용할 수 있도록
appId,password,tenant를 복사합니다.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Microsoft Entra 애플리케이션과 서비스 주체를 만들었습니다.
대상 테이블 만들기
쿼리 환경에서 다음 명령을 사용하여
Storms라는 테이블을 만듭니다..create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)다음 명령을 사용하여 수집된 데이터에 해당하는 테이블 매핑
Storms_CSV_Mapping을 만듭니다..create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'구성 가능한 대기 상태의 수집 대기 시간을 위해 테이블에 수집 일괄 처리 정책을 만듭니다.
팁
수집 일괄 처리 정책은 성능 최적화 도구이며 세 가지 매개 변수를 포함합니다. 첫 번째 조건이 충족되면 테이블로의 수집이 트리거됩니다.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Microsoft Entra 서비스 주체 만들기의 서비스 주체를 사용하여 데이터베이스 작업 권한을 부여합니다.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
랩 실행
다음 랩은 데이터 만들기 시작, Kafka 커넥터 설정 및 이 데이터를 스트리밍하는 환경을 제공하도록 디자인되었습니다. 그런 다음 수집된 데이터를 볼 수 있습니다.
Git 리포지토리 복제
랩의 Git 리포지토리를 복제합니다.
컴퓨터에 로컬 디렉터리를 만듭니다.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-hol리포지토리를 복제합니다.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
복제된 리포지토리의 내용
다음 명령을 실행하여 복제된 리포지토리의 내용을 나열합니다.
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
이 검색 결과는 다음과 같습니다.
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
복제된 리포지토리의 파일 검토
다음 섹션에서는 파일 트리에 있는 파일의 중요한 부분에 대해 설명합니다.
adx-sink-config.json
이 파일에는 특정 구성 세부 정보를 업데이트하는 Kusto 싱크 속성 파일이 포함되어 있습니다.
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
설정에 따라 aad.auth.authority, aad.auth.appid, aad.auth.appkey, kusto.tables.topics.mapping(데이터베이스 이름), kusto.ingestion.url 및 kusto.query.url 특성 값을 바꿉니다.
커넥터 - Dockerfile
이 파일에는 커넥터 인스턴스에 대한 Docker 이미지를 생성하는 명령이 있습니다. 여기에는 Git 리포지토리 릴리스 디렉터리에서 다운로드한 커넥터가 포함됩니다.
Storm-events-Producer 디렉터리
이 디렉터리에는 로컬 "StormEvents.csv" 파일을 읽고 데이터를 Kafka 토픽에 게시하는 Go 프로그램이 있습니다.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
컨테이너 시작
터미널에서 컨테이너를 시작합니다.
docker-compose up생산자 애플리케이션은
storm-events주제에 이벤트를 보내기 시작합니다. 다음 로그와 유사한 로그가 표시되어야 합니다..... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....로그를 확인하려면 별도의 터미널에서 다음 명령을 실행합니다.
docker-compose logs -f | grep kusto-connect
커넥터 시작
Kafka Connect REST 호출을 사용하여 커넥터를 시작합니다.
별도의 터미널에서 다음 명령을 사용하여 싱크 작업을 시작합니다.
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectors상태를 확인하려면 별도의 터미널에서 다음 명령을 실행합니다.
curl http://localhost:8083/connectors/storm/status
커넥터가 수집 프로세스 큐에 들어가기 시작합니다.
참고 항목
로그 커넥터 문제가 있는 경우 문제를 만듭니다.
관리 ID
기본적으로 Kafka 커넥터는 수집 중에 인증에 애플리케이션 방법을 사용합니다. 관리 ID를 사용하여 인증하려면 다음을 수행합니다.
클러스터에 관리 ID를 할당하고 스토리지 계정에 읽기 권한을 부여합니다. 자세한 내용은 관리 ID 인증을 사용하여 데이터 수집을 참조하세요.
adx-sink-config.json 파일에서 관리 ID 클라이언트(애플리케이션) ID로 설정되어
managed_identityaad.auth.strategy있는지 확인aad.auth.appid합니다.
참고 항목
관리 ID appId tenant 를 사용하는 경우 호출 사이트의 컨텍스트에서 추론되며 password 필요하지 않습니다.
데이터 쿼리 및 검토
데이터 수집 확인
데이터가
Storms테이블에 도착하면 행 수를 확인하여 데이터 전송을 확인합니다.Storms | count수집 프로세스에 오류가 없는지 확인합니다.
.show ingestion failures데이터가 표시되면 몇 가지 쿼리를 시도합니다.
데이터 쿼리
모든 레코드를 보려면 다음 쿼리를 실행합니다.
Storms | take 10where및project를 사용하여 특정 데이터를 필터링합니다.Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdsummarize연산자 사용:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart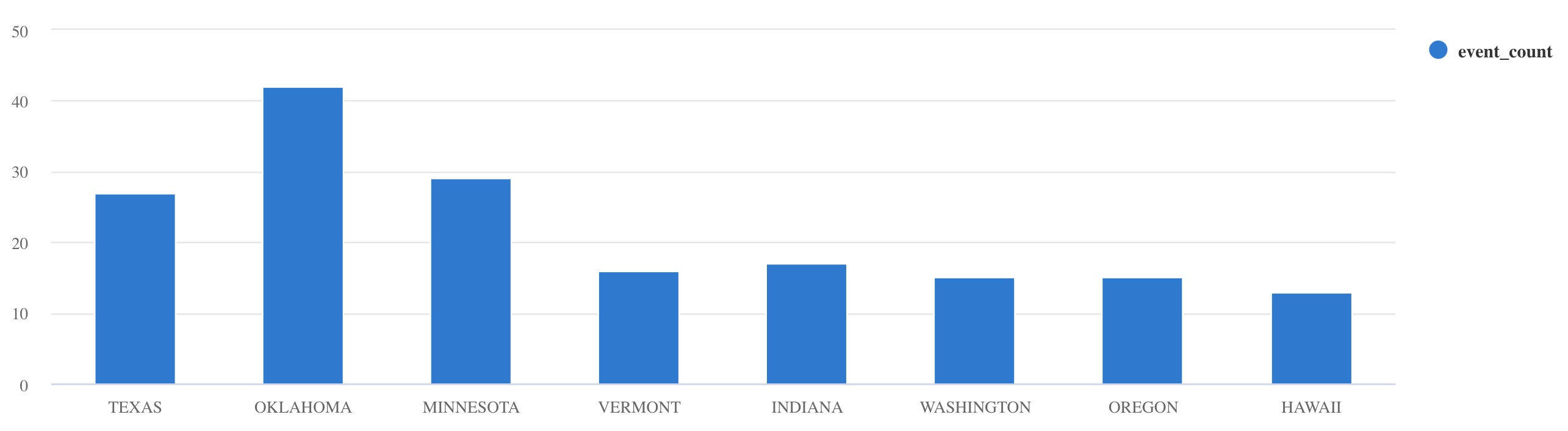
더 많은 쿼리 예제 및 지침은 KQL에서 쿼리 작성 및 Kusto 쿼리 언어 설명서를 참조하세요.
다시 설정
재설정하려면 다음 단계를 수행합니다.
- 컨테이너 중지(
docker-compose down -v) - 삭제(
drop table Storms) Storms테이블 다시 만들기- 테이블 매핑 다시 만들기
- 컨테이너 다시 시작(
docker-compose up)
리소스 정리
Azure Data Explorer 리소스를 삭제하려면 az kusto cluster delete(kusto extension) 또는 az kusto database delete(kusto extension)를 사용합니다.
az kusto cluster delete --name "<cluster name>" --resource-group "<resource group name>"
az kusto database delete --cluster-name "<cluster name>" --database-name "<database name>" --resource-group "<resource group name>"
Azure Portal을 통해 클러스터 및 데이터베이스를 삭제할 수도 있습니다. 자세한 내용은 Azure Data Explorer 클러스터 삭제 및 Azure Data Explorer에서 데이터베이스 삭제를 참조하세요.
Kafka 싱크 커넥터 튜닝
수집 일괄 처리 정책과 함께 작동하도록 Kafka 싱크 커넥터를 튜닝합니다.
- Kafka 싱크
flush.size.bytes크기 제한을 1MB에서 시작하여 10MB 또는 100MB 단위로 튜닝합니다. - Kafka 싱크를 사용하는 경우 데이터는 두 번 집계됩니다. 커넥터 쪽에서 데이터는 플러시 설정에 따라, 서비스 쪽에서는 배치 처리 정책에 따라 집계됩니다. 배치 처리 시간이 너무 짧아 커넥터와 서비스 모두에서 데이터를 수집할 수 없는 경우 배치 처리 시간을 늘려야 합니다. 일괄 처리 크기를 1GB로 설정하고 필요에 따라 100MB씩 늘리거나 줄입니다. 예를 들어 플러시 크기가 1MB이고 배치 처리 정책 크기가 100MB인 경우 Kafka 싱크 커넥터는 데이터를 100MB 배치로 집계합니다. 그런 다음, 서비스에서 해당 배치를 수집합니다. 배치 처리 정책 시간이 20초이고 Kafka 싱크 커넥터가 20초 동안 50MB를 플러시하는 경우 서비스는 50MB 배치를 수집합니다.
- 인스턴스와 Kafka 파티션을 추가하여 확장할 수 있습니다.
tasks.max를 파티션 수로 늘립니다.flush.size.bytes설정의 Blob 크기를 생성하기에 충분한 데이터가 있는 경우 파티션을 만듭니다. Blob이 더 작은 경우, 시간 제한에 도달했을 때 배치가 처리되므로 파티션이 충분한 처리량을 수신하지 못합니다. 파티션 수가 많으면 처리 오버헤드가 증가합니다.
관련 콘텐츠
- 빅 데이터 아키텍처에 대해 자세히 알아봅니다.
- JSON 형식의 샘플 데이터를 Azure Data Explorer로 수집하는 방법을 알아봅니다.
- Kafka 랩을 사용하여 자세히 알아보세요.