Apache Spark용 Azure Data Explorer 커넥터
Apache Spark는 대규모 데이터를 처리하기 위한 통합 분석 엔진입니다. Azure Data Explorer는 대량의 데이터를 실시간으로 분석할 수 있는 빠르고 완전히 관리되는 데이터 분석 서비스입니다.
Spark용 Kusto 커넥터는 모든 Spark 클러스터에서 실행할 수 있는 오픈 소스 프로젝트입니다. Azure Data Explorer 및 Spark 클러스터에서 데이터를 이동하기 위한 데이터 원본 및 데이터 싱크를 구현합니다. Azure Data Explorer 및 Apache Spark를 사용하여 데이터 기반 시나리오를 대상으로 하는 빠르고 확장 가능한 애플리케이션을 구축할 수 있습니다. 예를 들어 ML(기계 학습), ETL(추출-변환-로드) 및 Log Analytics가 있습니다. 커넥터를 사용하여 Azure Data Explorer는 쓰기, 읽기 및 writeStream과 같은 표준 Spark 원본 및 싱크 작업에 대한 유효한 데이터 저장소가 됩니다.
대기 중인 수집 또는 스트리밍 수집을 통해 Azure Data Explorer에 쓸 수 있습니다. Azure Data Explorer에서 읽기는 열 정리 및 조건자 푸시다운을 지원하며, 이는 Azure Data Explorer에서 데이터를 필터링하여 전송된 데이터의 양을 줄입니다.
참고
Azure Data Explorer용 Synapse Spark 커넥터를 사용하는 방법에 대한 자세한 내용은 Azure Synapse Analytics용 Apache Spark를 사용하여 Azure Data Explorer에 연결을 참조하세요.
이 항목에서는 Azure Data Explorer Spark 커넥터를 설치 및 구성하고 Azure Data Explorer와 Apache Spark 클러스터 간에 데이터를 이동하는 방법을 설명합니다.
참고
아래 예 중 일부는 Azure Databricks Spark 클러스터를 참조하지만 Azure Data Explorer Spark 커넥터에는 Databricks 또는 기타 Spark 배포에 대한 직접적인 종속성이 있지 않습니다.
사전 요구 사항
- Azure 구독 평가판 Azure 계정을 만듭니다.
- Azure Data Explorer 클러스터 및 데이터베이스. 클러스터 및 데이터베이스를 만듭니다.
- Spark 클러스터.
- 다음과 같이 커넥터 라이브러리를 설치합니다.
- Spark 2.4+Scala 2.11 또는 Spark 3+scala 2.12에 대한 미리 빌드된 라이브러리
- Maven 리포지토리
- Maven 3.x 설치됨
팁
Spark 2.3.x 버전도 지원되지만 pom.xml 종속성을 일부 변경해야 할 수 있습니다.
Spark 커넥터를 구축하는 방법
버전 2.3.0부터 새 아티팩트 ID를 도입했습니다. 이때 Spark 3.x 및 Scala 2.12를 대상으로 하는 spark-kusto-connector(kusto-spark_3.0_2.12)를 바꿉니다.
참고 항목
2.5.1 이전 버전을 사용하여 기존 테이블에 더 이상 수집할 수 없습니다. 이후 버전으로 업데이트하세요. 이 단계는 선택 사항입니다. Maven과 같이 미리 빌드된 라이브러리를 사용하는 경우 Spark 클러스터 설정을 참조하세요.
빌드 필수 조건
Spark 커넥터를 빌드하려면 이 원본을 참조하세요.
Maven 프로젝트 정의를 사용하는 Scala/Java 애플리케이션의 경우 애플리케이션을 최신 아티팩트에 연결합니다. Maven Central에서 최신 아티팩트를 찾습니다.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).미리 빌드된 라이브러리를 사용하지 않는 경우 다음 Kusto Java SDK 라이브러리를 포함하여 종속성에 나열된 라이브러리를 설치해야 합니다. 설치할 올바른 버전을 찾으려면 관련 릴리스의 pom을 확인하세요.
jar를 빌드하고 모든 테스트를 실행하려면:
mvn clean package -DskipTestsjar를 빌드하고 모든 테스트를 실행하고 jar를 로컬 Maven 리포지토리에 설치하려면:
mvn clean install -DskipTests
자세한 내용은 커넥터 사용을 참조하세요.
Spark 클러스터 설정
참고 항목
다음 단계를 수행할 때 최신 Kusto Spark 커넥터 릴리스를 사용하는 것이 좋습니다.
Azure Databricks 클러스터 Spark 3.0.1 및 Scala 2.12에 기반하여 다음 Spark 클러스터 설정을 구성합니다.
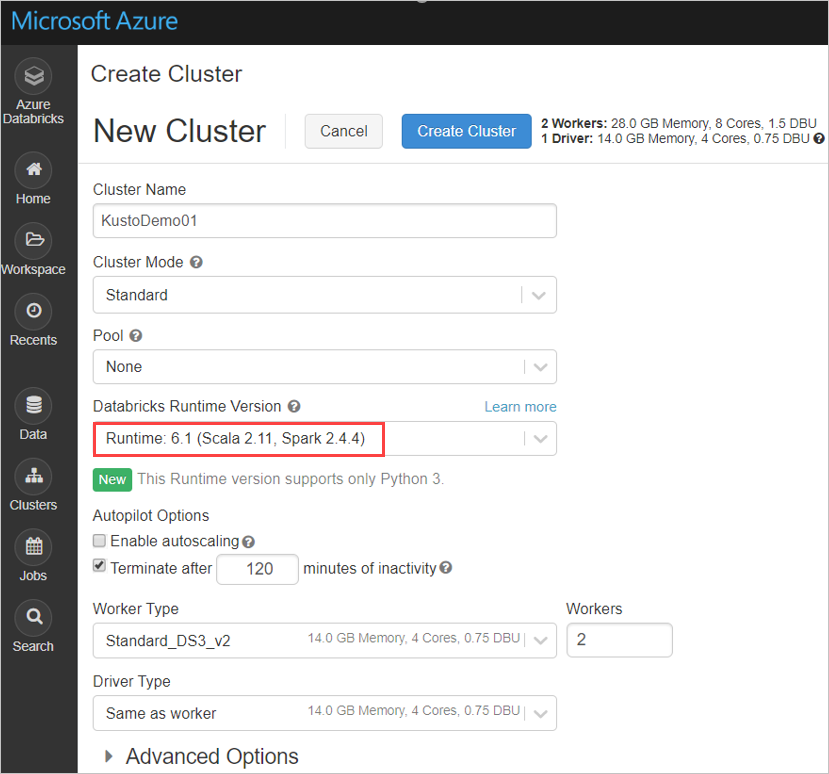
Maven에서 최신 spark-kusto-connector 라이브러리를 설치합니다.
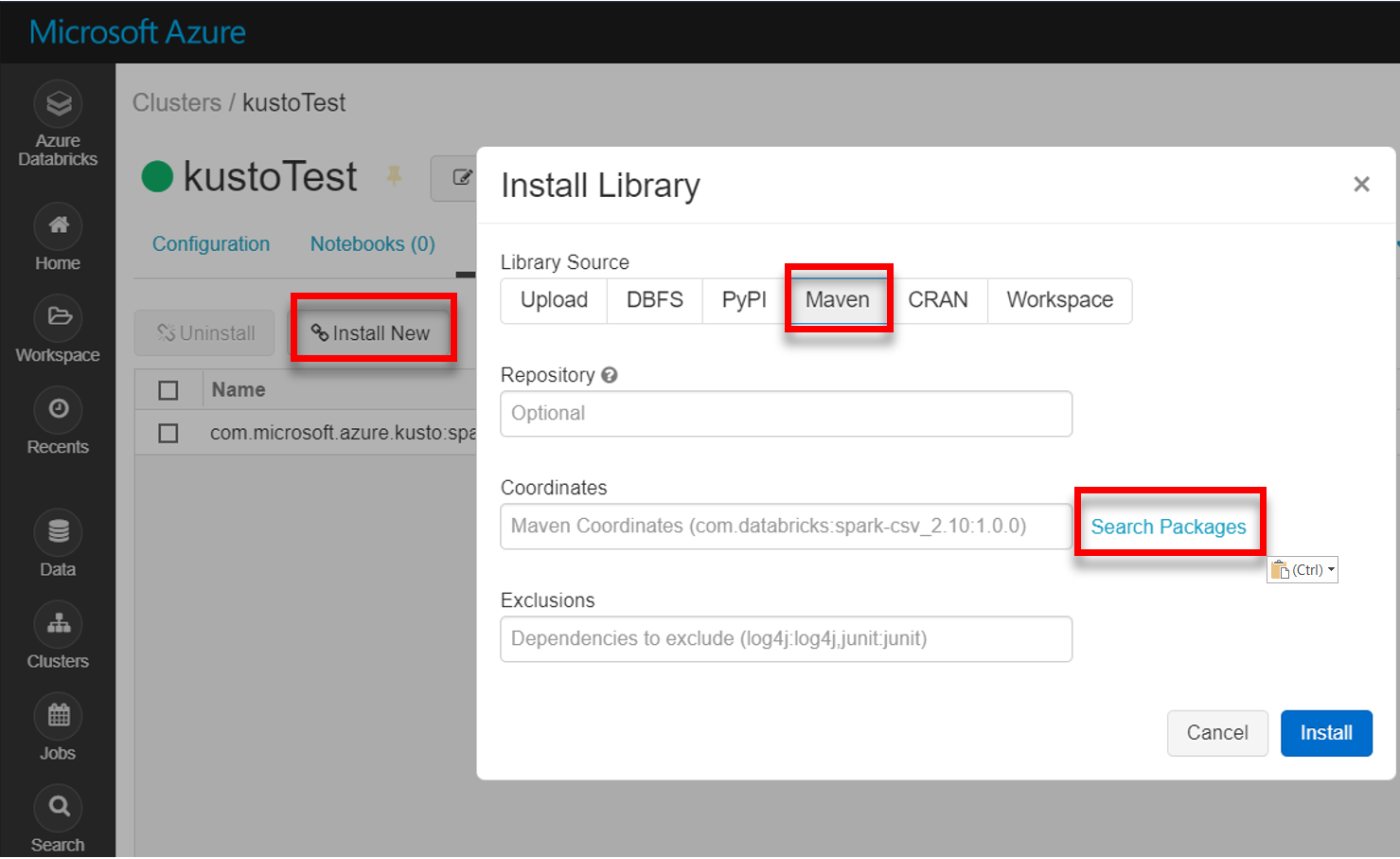
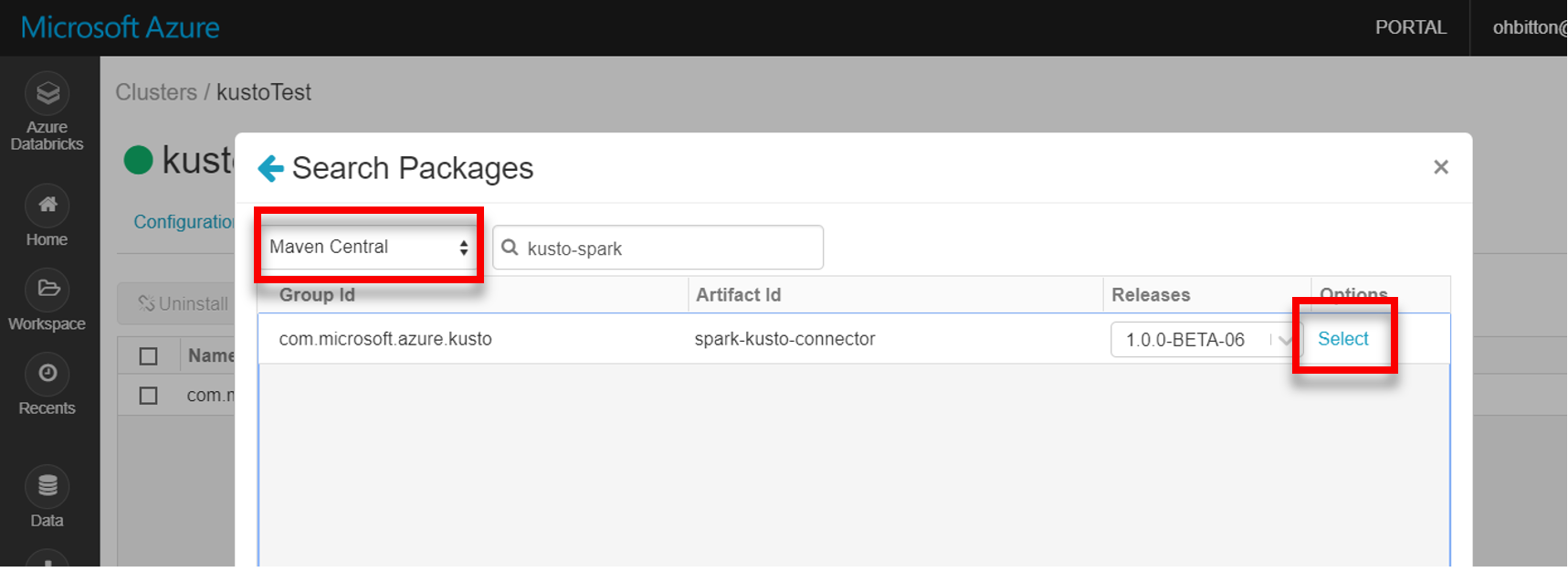
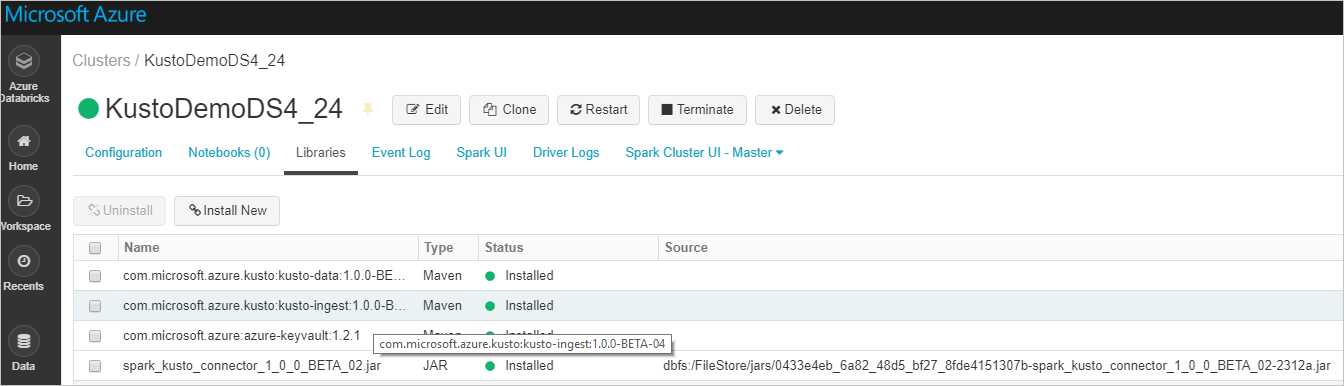
필요한 모든 라이브러리가 설치되었는지 확인합니다.
JAR 파일을 사용하여 설치하는 경우 추가 종속성이 설치되었는지 확인합니다.
인증
Kusto Spark 커넥터를 사용하면 다음 방법 중 하나를 사용하여 Microsoft Entra ID로 인증할 수 있습니다.
- Microsoft Entra 애플리케이션
- Microsoft Entra 액세스 토큰
- 디바이스 인증(비프로덕션 시나리오용)
- Azure Key Vault Key Vault 리소스에 액세스하려면 azure-keyvault 패키지를 설치하고 애플리케이션 자격 증명을 제공합니다.
Microsoft Entra 애플리케이션 인증
Microsoft Entra 애플리케이션 인증은 가장 간단하고 일반적인 인증 방법이며, Kusto Spark 커넥터에 권장됩니다.
Azure CLI를 통해 Azure 구독에 로그인합니다. 그런 다음 브라우저에서 인증합니다.
az login서비스 주체를 호스트하는 구독을 선택합니다. 이 단계는 여러 구독이 있는 경우에 필요합니다.
az account set --subscription YOUR_SUBSCRIPTION_GUID서비스 주체를 만듭니다. 이 예시에서는 서비스 주체를
my-service-principal이라고 합니다.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}반환된 JSON 데이터에서 나중에 사용할 수 있도록
appId,password,tenant를 복사합니다.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Microsoft Entra 애플리케이션과 서비스 주체를 만들었습니다.
Spark 커넥터는 인증에 다음 Entra 앱 속성을 사용합니다.
| 속성 | 옵션 문자열 | Description |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra 애플리케이션(클라이언트) ID. |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra 인증 권한. Microsoft Entra 디렉터리(테넌트) ID. 선택 사항 - 기본값은 microsoft.com입니다. 자세한 내용은 Microsoft Entra 권한을 참조하세요. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | 클라이언트에 대한 Microsoft Entra 애플리케이션 키. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Kusto에 대한 액세스 권한으로 만든 accessToken이 이미 있는 경우 이를 커넥터에 전달하고 인증하는 데 사용할 수 있습니다. |
참고 항목
이전 API 버전(2.0.0 미만)의 이름은 "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"입니다.
Kusto 권한
수행하려는 Spark 작업에 따라 kusto 쪽에서 다음 권한을 부여합니다.
| Spark 작업 | 권한 |
|---|---|
| 읽기 - 단일 모드 | 판독기 |
| 읽기 – 강제 분산 모드 | 판독기 |
| 쓰기 – CreateTableIfNotExist 테이블 만들기 옵션을 포함하는 큐 대기 모드 | 관리자 |
| 쓰기 – FailIfNotExist 테이블 만들기 옵션을 포함하는 큐 대기 모드 | 수집자 |
| 쓰기 – TransactionalMode | 관리자 |
보안 주체 역할에 대한 자세한 내용은 역할 기반 액세스 제어를 참조하세요. 보안 역할 관리는 보안 역할 관리를 참조하세요.
Spark 싱크: Kusto에 쓰기
싱크 매개 변수 설정:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Spark DataFrame을 Kusto 클러스터에 배치로 쓰기:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()또는 단순화된 구문을 사용합니다.
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)스트리밍 데이터 쓰기:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark 원본: Kusto에서 읽기
소량의 데이터를 읽을 때 데이터 쿼리를 정의합니다.
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)선택 사항: 사용자가 임시 Blob Storage(Kusto가 아님)를 제공하는 경우 Blob이 호출자의 책임하에 만들어집니다. 여기에는 스토리지 프로비저닝, 액세스 키 순환, 임시 아티팩트 삭제가 포함됩니다. KustoBlobStorageUtils 모듈에는 계정 및 컨테이너 좌표와 계정 자격 증명 또는 쓰기, 읽기 및 나열 권한이 있는 전체 SAS URL을 기반으로 Blob을 삭제하기 위한 도우미 함수가 포함되어 있습니다. 해당 RDD가 더 이상 필요하지 않으면 각 트랜잭션은 임시 Blob 아티팩트를 별도의 디렉터리에 저장합니다. 이 디렉터리는 Spark 드라이버 노드에 보고된 읽기-트랜잭션 정보 로그의 일부로 캡처됩니다.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")위의 예에서 커넥터 인터페이스를 사용하여 Key Vault에 액세스하지 않습니다. Databricks 비밀을 사용하는 더 간단한 방법이 사용됩니다.
Kusto에서 읽습니다.
사용자가 임시 Blob Storage를 제공하는 경우 다음과 같이 Kusto에서 읽습니다.
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Kusto가 임시 Blob Storage를 제공하는 경우 다음과 같이 Kusto에서 읽습니다.
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)