Azure Data Factory 또는 Synapse Analytics를 사용하여 Cassandra에서 데이터 복사
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
이 문서에서는 Azure Data Factory 및 Synapse Analytics 파이프라인에서 복사 작업을 사용하여 Cassandra 데이터베이스에서 데이터를 복사하는 방법을 간략하게 설명합니다. 이 문서는 복사 작업에 대한 일반적인 개요를 제공하는 복사 작업 개요 문서를 기반으로 합니다.
지원되는 기능
이 Cassandra 커넥터는 다음 기능에 대해 지원됩니다.
| 지원되는 기능 | IR |
|---|---|
| 복사 작업(원본/-) | 3,4 |
| 조회 작업 | 3,4 |
① Azure 통합 런타임 ② 자체 호스팅 통합 런타임
원본/싱크로 지원되는 데이터 저장소 목록은 지원되는 데이터 저장소 표를 참조하세요.
특히 이 Cassandra 커넥터는 다음을 지원합니다.
- Cassandra 버전 2.x 및 3.x.
- Basic 또는 Anonymous 인증을 사용하여 데이터를 복사합니다.
참고 항목
자체 호스팅 Integration Runtime에서 활동 실행의 경우 Cassandra 3.x는 IR 버전 3.7 이상에서 지원됩니다.
필수 조건
데이터 저장소가 온-프레미스 네트워크, Azure 가상 네트워크 또는 Amazon Virtual Private Cloud 내에 있는 경우 자체 호스팅된 통합 런타임을 구성하여 연결해야 합니다.
데이터 저장소가 관리형 클라우드 데이터 서비스인 경우 Azure Integration Runtime을 사용할 수 있습니다. 액세스가 방화벽 규칙에서 승인된 IP로 제한되는 경우 허용 목록에 Azure Integration Runtime IP를 추가할 수 있습니다.
또한 Azure Data Factory의 관리형 가상 네트워크 통합 런타임 기능을 사용하면 자체 호스팅 통합 런타임을 설치하고 구성하지 않고도 온-프레미스 네트워크에 액세스할 수 있습니다.
Data Factory에서 지원하는 네트워크 보안 메커니즘 및 옵션에 대한 자세한 내용은 데이터 액세스 전략을 참조하세요.
통합 런타임은 기본 제공 Cassandra 드라이버를 제공하므로 Cassandra 간에 데이터를 복사할 때 수동으로 드라이버를 설치할 필요가 없습니다.
시작하기
파이프라인에 복사 작업을 수행하려면 다음 도구 또는 SDK 중 하나를 사용하면 됩니다.
UI를 사용하여 Cassandra에 연결된 서비스 만들기
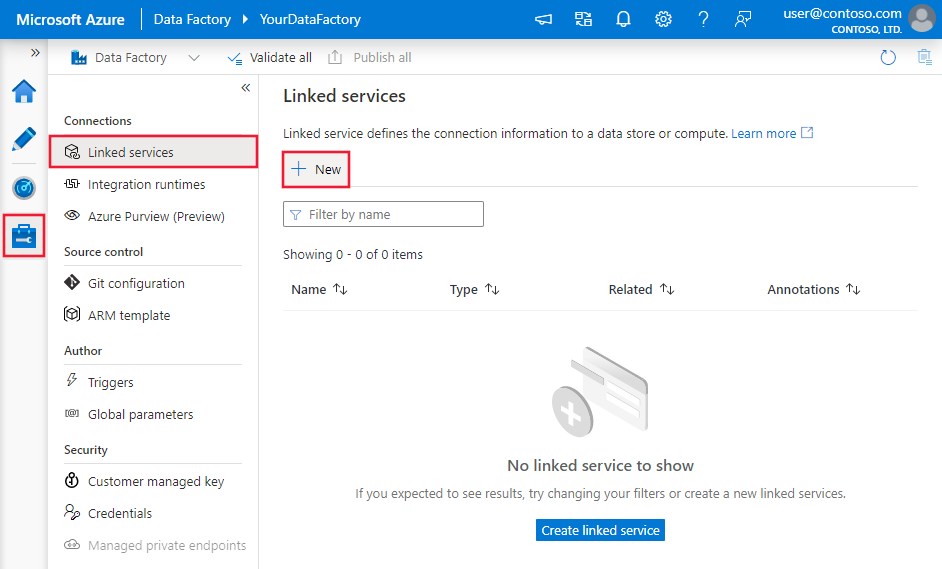
다음 단계를 사용하여 Azure Portal UI에서 Cassandra에 연결된 서비스를 만듭니다.
Azure Data Factory 또는 Synapse 작업 영역에서 관리 탭으로 이동하여 연결된 서비스를 선택하고 새로 만들기를 클릭합니다.
Cassandra를 검색하고 Cassandra 커넥터를 선택합니다.
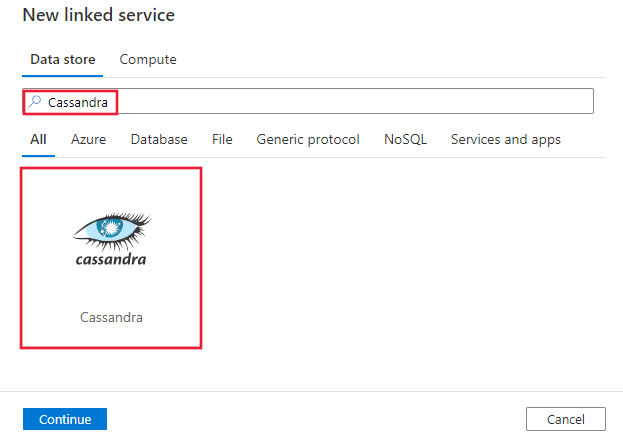
서비스 세부 정보를 구성하고, 연결을 테스트하고, 새로운 연결된 서비스를 만듭니다.

커넥터 구성 세부 정보
다음 섹션에서는 Cassandra 커넥터에 한정된 Data Factory 엔터티를 정의하는 데 사용되는 속성에 대해 자세히 설명합니다.
연결된 서비스 속성
Cassandra 연결된 서비스에 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 형식 속성은 Cassandra로 설정해야 합니다. | 예 |
| host | Cassandra 서버에 대한 하나 이상의 IP 주소 또는 호스트 이름. 모든 서버에 동시에 연결하려면 쉼표로 구분된 IP 주소 또는 호스트 이름 목록을 지정합니다. |
예 |
| port | Cassandra 서버가 클라이언트 연결을 수신하는 데 사용하는 TCP 포트입니다. | 아니요(기본값: 9042) |
| authenticationType | Cassandra 데이터베이스에 연결하는 데 사용되는 인증 형식입니다. 허용되는 값은 Basic 및 Anonymous입니다. |
예 |
| 사용자 이름 | 사용자 계정의 사용자 이름을 지정합니다. | 예. authenticationType은 Basic으로 설정됩니다. |
| password | 사용자 계정으로 password를 지정합니다. 이 필드를 SecureString으로 표시하여 안전하게 저장하거나, Azure Key Vault에 저장된 비밀을 참조합니다. | 예. authenticationType은 Basic으로 설정됩니다. |
| connectVia | 데이터 저장소에 연결하는 데 사용할 Integration Runtime입니다. 필수 구성 요소 섹션에서 자세히 알아보세요. 지정하지 않으면 기본 Azure Integration Runtime을 사용합니다. | 아니요 |
참고 항목
현재, TLS를 사용한 Cassandra 연결은 지원되지 않습니다.
예제:
{
"name": "CassandraLinkedService",
"properties": {
"type": "Cassandra",
"typeProperties": {
"host": "<host>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
데이터 세트 속성
데이터 세트 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 데이터 세트 문서를 참조하세요. 이 섹션에서는 Cassandra 데이터 세트에서 지원하는 속성의 목록을 제공합니다.
Cassandra에서 데이터를 복사하려면 데이터 세트의 type 속성을 CassandraTable로 설정합니다. 다음과 같은 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 데이터 세트의 type 속성을 CassandraTable로 설정해야 합니다. | 예 |
| keyspace | Cassandra 데이터베이스의 키스페이스 또는 스키마의 이름입니다. | 아니요("CassandraSource"에 대해 "query"가 지정되지 않은 경우) |
| tableName | Cassandra 데이터베이스에 있는 테이블의 이름입니다. | 아니요("CassandraSource"에 대해 "query"가 지정되지 않은 경우) |
예제:
{
"name": "CassandraDataset",
"properties": {
"type": "CassandraTable",
"typeProperties": {
"keySpace": "<keyspace name>",
"tableName": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Cassandra linked service name>",
"type": "LinkedServiceReference"
}
}
}
복사 작업 속성
작업 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 파이프라인 문서를 참조하세요. 이 섹션에서는 Cassandra 원본에서 지원하는 속성의 목록을 제공합니다.
Cassandra를 원본으로
Cassandra에서 데이터를 복사하려면 복사 작업의 원본 형식을 CassandraSource로 설정합니다. 복사 작업 source 섹션에서 다음 속성이 지원됩니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 작업 원본의 type 속성을 CassandraSource로 설정해야 합니다. | 예 |
| query | 사용자 지정 쿼리를 사용하여 데이터를 읽습니다. SQL-92 쿼리 또는 CQL 쿼리입니다. CQL 참조를 참조하세요. SQL 쿼리를 사용할 경우 keyspace name.table name 을 지정하여 쿼리하려는 테이블을 나타냅니다. |
아니요(데이터 세트의 "tableName" 및 "keyspace"가 정의된 경우). |
| consistencyLevel | 일관성 수준은 클라이언트 애플리케이션에 데이터를 반환하기 전에 읽기 요청에 응답해야 하는 복제본 수를 지정합니다. Cassandra는 데이터의 지정된 수의 복제본이 읽기 요청을 충족하는지 확인합니다. 자세한 내용은 데이터 일관성 구성 을 참조하세요. 허용되는 값은 ONE, TWO, THREE, QUORUM, ALL, LOCAL_QUORUM, EACH_QUORUM 및 LOCAL_ONE입니다. |
아니요(기본값: ONE) |
예제:
"activities":[
{
"name": "CopyFromCassandra",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cassandra input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CassandraSource",
"query": "select id, firstname, lastname from mykeyspace.mytable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Cassandra에 대한 데이터 형식 매핑
Cassandra에서 데이터를 복사할 때 Cassandra 데이터 형식에서 서비스 내에 내부적으로 사용되는 중간 데이터 형식으로 다음 매핑이 사용됩니다. 복사 작업에서 원본 스키마 및 데이터 형식을 싱크에 매핑하는 방법에 대한 자세한 내용은 스키마 및 데이터 형식 매핑을 참조하세요.
| Cassandra 데이터 형식 | 중간 서비스 데이터 형식 |
|---|---|
| ASCII | 문자열 |
| BIGINT | Int64 |
| BLOB | Byte[] |
| BOOLEAN | 부울 |
| DECIMAL | Decimal |
| DOUBLE | 두 배 |
| FLOAT | 단일 |
| INET | 문자열 |
| INT | Int32 |
| TEXT | 문자열 |
| TIMESTAMP | DateTime |
| TIMEUUID | GUID |
| UUID | GUID |
| VARCHAR | 문자열 |
| VARINT | 소수 |
참고 항목
컬렉션 형식(맵, 집합, 목록 등)에 대해서는 가상 테이블을 사용하여 Cassandra 컬렉션 형식으로 작업 섹션을 참조하세요.
사용자 정의 형식은 지원되지 않습니다.
이진 열의 길이와 문자열 열 길이는 4000보다 클 수 없습니다.
가상 테이블을 사용하여 컬렉션으로 작업
서비스는 기본 제공 ODBC 드라이버를 사용하여 Cassandra 데이터베이스에 연결하고 데이터를 복사합니다. 맵, 집합 및 목록을 포함하는 컬렉션 형식의 경우 드라이버는 데이터를 해당 가상 테이블로 다시 정규화합니다. 특히, 테이블에 컬렉션 열이 포함되어 있으면 드라이버는 다음 가상 테이블을 생성합니다.
- 기본 테이블: 컬렉션 열을 제외하고 실제 테이블과 동일한 데이터가 포함되어 있습니다. 기본 테이블은 나타내는 실제 테이블과 동일한 이름을 사용합니다.
- 가상 테이블 : 컬렉션 열에 대해 생성되며, 중첩된 데이터를 확장합니다. 컬렉션을 나타내는 가상 테이블 이름은 실제 테이블의 이름, 구분 기호 "vt" 및 열 이름을 사용하여 지정합니다.
가상 테이블은 실제 테이블의 데이터를 나타내며, 드라이버가 정규화되지 않은 데이터에 액세스할 수 있도록 합니다. 자세한 내용은 예제 섹션을 참조하세요. 가상 테이블을 쿼리 및 조인하여 Cassandra 컬렉션의 콘텐츠에 액세스할 수 있습니다.
예시
예를 들어 다음 "ExampleTable"은 "pk_int"라는 정수 기본 키 열, value라는 텍스트 열, 목록 열, 맵 열, 집합 열("StringSet")을 포함하는 Cassandra 데이터베이스 테이블입니다.
| pk_int | 값 | List | 지도 | StringSet |
|---|---|---|---|---|
| 1 | "sample value 1" | ["1", "2", "3"] | {"S1": "a", "S2": "b"} | {"A", "B", "C"} |
| 3 | "sample value 3" | ["100", "101", "102", "105"] | {"S1": "t"} | {"A", "E"} |
드라이버는 이 단일 테이블을 나타내는 여러 개의 가상 테이블을 생성합니다. 가상 테이블의 외래 키 열은 실제 테이블의 기본 키 열을 참조하고, 가상 테이블 행에 해당하는 실제 테이블 행을 나타냅니다.
첫 번째 가상 테이블은 다음 테이블에 표시된 "ExampleTable"이라는 기본 테이블입니다.
| pk_int | 값 |
|---|---|
| 1 | "sample value 1" |
| 3 | "sample value 3" |
기본 테이블에는 컬렉션을 제외하고 원래 데이터베이스 테이블과 동일한 데이터가 포함됩니다. 컬렉션은 테이블에서 생략된 후 다른 가상 테이블에서 확장됩니다.
다음 표에서는 List, Map 및 StringSet 열의 데이터를 다시 정규화하는 가상 테이블을 보여 줍니다. 이름이 "_index" 또는 "_key"로 끝나는 열은 원본 목록이나 맵 내의 데이터 위치를 나타냅니다. 이름이 "_value"로 끝나는 열에는 컬렉션에서 확장된 데이터가 포함됩니다.
테이블 "ExampleTable_vt_List":
| pk_int | List_index | List_value |
|---|---|---|
| 1 | 0 | 1 |
| 1 | 6 | 2 |
| 1 | 2 | 3 |
| 3 | 0 | 100 |
| 3 | 1 | 101 |
| 3 | 2 | 102 |
| 3 | 3 | 103 |
테이블 "ExampleTable_vt_Map":
| pk_int | Map_key | Map_value |
|---|---|---|
| 1 | S1 | A |
| 1 | S2 | b |
| 3 | S1 | t |
테이블 "ExampleTable_vt_StringSet":
| pk_int | StringSet_value |
|---|---|
| 1 | A |
| 1 | b |
| 1 | C |
| 3 | A |
| 3 | E |
조회 작업 속성
속성에 대한 자세한 내용을 보려면 조회 작업을 확인하세요.
관련 콘텐츠
복사 작업에서 원본 및 싱크로 지원되는 데이터 저장소 목록은 지원되는 데이터 저장소를 참조하세요.