매핑 데이터 흐름의 선택 변환
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
데이터 흐름은 Azure Data Factory 및 Azure Synapse Pipelines 모두에서 사용할 수 있습니다. 이 문서는 매핑 데이터 흐름에 적용됩니다. 변환을 처음 사용하는 경우 매핑 데이터 흐름을 사용하여 데이터 변환 소개 문서를 참조하세요.
선택 변환을 사용하여 열의 이름을 바꾸거나, 열을 삭제하거나, 열 순서를 변경합니다. 이 변환은 행 데이터를 변경하지 않지만 다운스트림으로 전파되는 열을 선택합니다.
선택 변환에서 사용자는 고정 매핑을 지정하거나, 패턴을 사용하여 규칙 기반 매핑을 수행하거나, 자동 매핑을 사용하도록 설정할 수 있습니다. 동일한 선택 변환 내에서 고정 매핑과 규칙 기반 매핑을 둘 다 사용할 수 있습니다. 정의된 매핑 중 하나와 일치하지 않는 열은 삭제됩니다.
고정 매핑
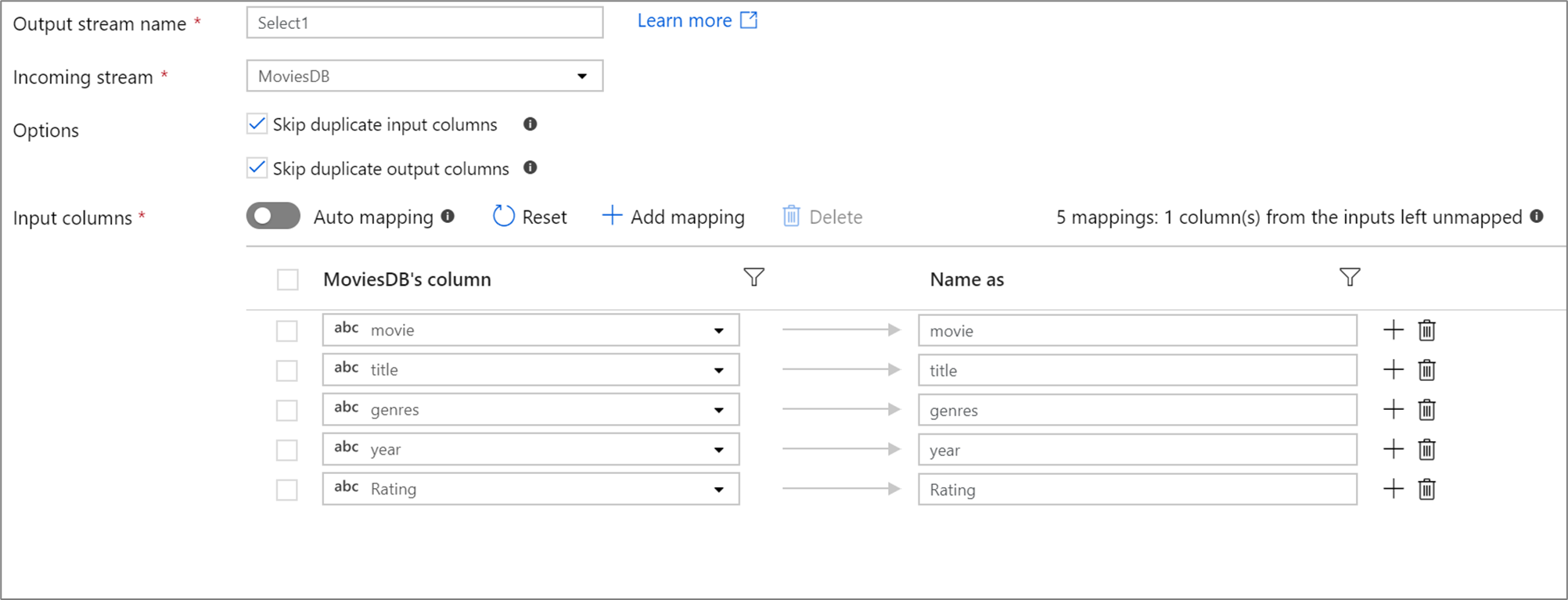
프로젝션에 정의된 열이 50개 미만인 경우 정의된 모든 열에는 기본적으로 고정된 매핑이 있습니다. 고정 매핑은 정의된 들어오는 열을 사용하고 정확한 이름으로 매핑합니다.
참고 항목
고정 매핑을 사용하여 드리프트된 열을 매핑하거나 이름을 바꿀 수 없습니다.
계층 구조 열 매핑
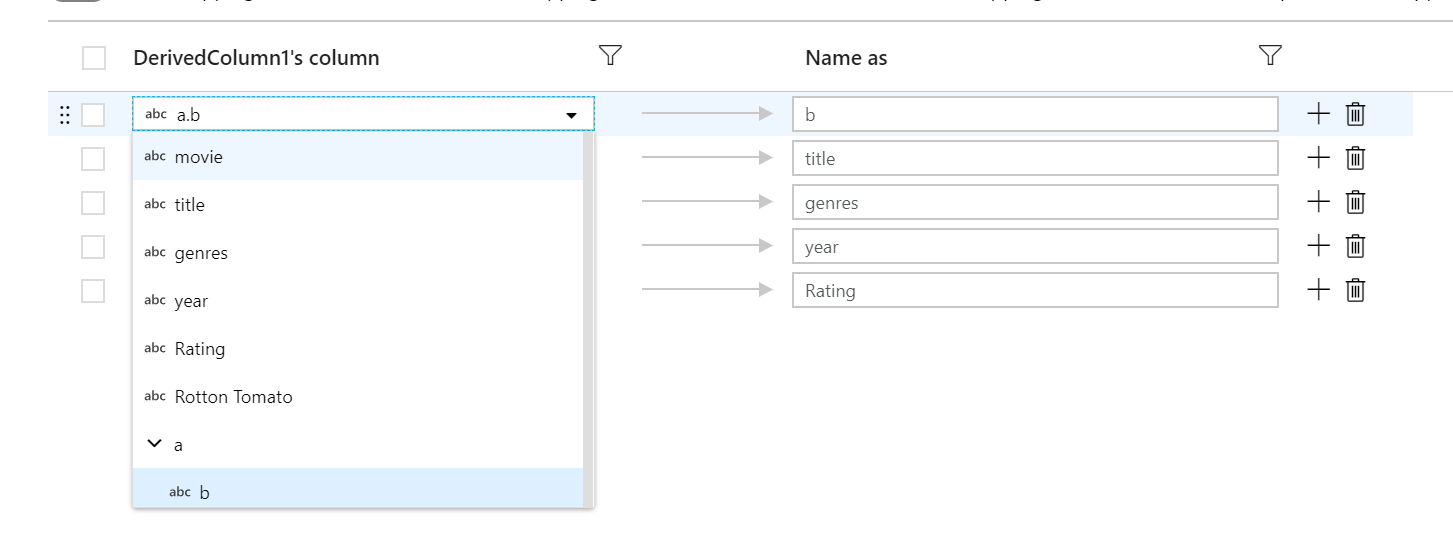
고정 매핑을 사용하여 계층 구조 열의 하위 열을 최상위 열에 매핑할 수 있습니다. 정의된 계층 구조가 있는 경우 열 드롭다운을 사용하여 하위 열을 선택합니다. 선택 변환은 하위 열의 값과 데이터 형식을 사용하여 새 열을 만듭니다.
규칙 기반 매핑
한 번에 많은 열을 매핑하거나 드리프트된 열을 다운스트림으로 전달하려면 규칙 기반 매핑을 사용하여 열 패턴을 통해 매핑을 정의합니다. 열의 name, type, stream, position을 기준으로 일치합니다. 고정 및 규칙 기반 매핑의 모든 조합을 사용할 수 있습니다. 기본값으로 50개 이상의 열을 포함하는 모든 프로젝션은 모든 열에서 일치하는 규칙 기반 매핑으로 기본설정되며, 입력 이름을 출력합니다.
규칙 기반 매핑을 추가하려면, 매핑 추가를 클릭하고 규칙 기반 매핑을 선택합니다.

각 규칙 기반 매핑에는 일치 조건과 각 매핑된 열의 이름을 입력해야 합니다. 두 값은 모두 식 작성기를 통해 입력됩니다. 왼쪽 식 상자에 부울 일치 조건을 입력합니다. 오른쪽 식 상자에서 일치하는 열을 매핑할 대상을 지정합니다.

$$ 구문을 사용하여 일치하는 열의 입력 이름을 참조합니다. 위의 이미지를 예로 들 수 있습니다. 예를 들어, 사용자는 이름이 6개 문자보다 짧은 모든 문자열 열에 대해 일치시키려 합니다. 하나의 들어오는 열의 이름이 test로 지정된 경우, 식 $$ + '_short'에서 열 test_short의 이름을 바꿉니다. 이 매핑이 사용할 수 있는 유일한 매핑이면, 해당 조건을 충족하지 않는 모든 열이 출력된 데이터에서 삭제됩니다.
패턴은 드리프트된 열과 정의된 열 모두와 일치합니다. 규칙에 따라 매핑되는 정의된 열을 확인하려면, 규칙 옆에 있는 안경 아이콘을 클릭합니다. 데이터 미리 보기를 사용하여 출력을 확인합니다.
Regex 매핑
아래쪽 펼침 단추 아이콘을 클릭하면, regex 매핑 조건을 지정할 수 있습니다. Regex 매핑 조건은 지정된 regex 조건과 일치하는 모든 열 이름과 일치합니다. 이것을 표준 규칙 기반 매핑과 함께 사용할 수 있습니다.

위의 예제는 regex 패턴 (r)이나 소문자 r을 포함하는 모든 열 이름에서 일치합니다. 표준 규칙 기반 매핑과 유사하게, 일치하는 모든 열은 $$ 구문을 사용하여 오른쪽의 조건에 따라 변경됩니다.
열 이름에 regex 일치 항목이 여러 개 있는 경우 $n을 사용하여 특정 일치 항목을 참조할 수 있습니다. 여기서 ‘n’은 일치하는 항목을 나타냅니다. 예를 들어, ‘$2’는 열 이름 내의 두 번째 일치 항목을 나타냅니다.
규칙 기반 계층
정의된 프로젝션에 계층이 있는 경우, 규칙 기반 매핑을 사용하여 계층 하위 열을 매핑할 수 있습니다. 일치 조건 및 하위 열을 매핑하려는 복합 열을 지정합니다. 오른쪽에 지정된 규칙으로서 ‘이름’을 사용하여 일치하는 모든 하위 열이 출력됩니다.
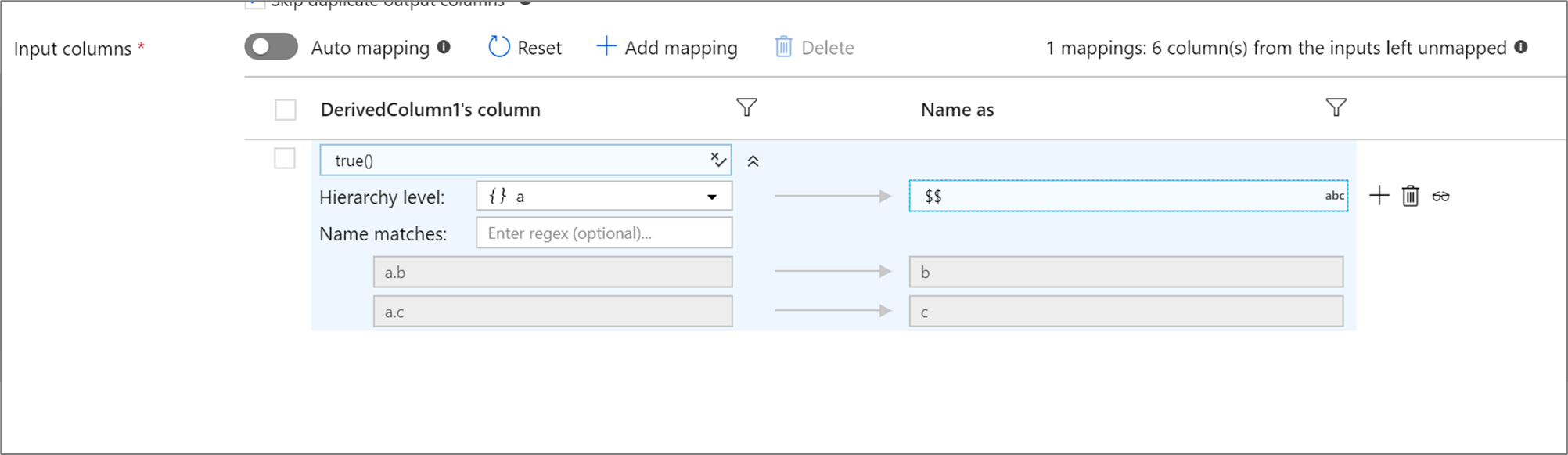
위의 예는 복합 열의 모든 하위 열 a에서 일치합니다. a은 하위 열 b와 c을 포함합니다. 조건으로서 '이름'이 $$이되므로, 출력 스키마는 두 개의 열 b과 c를 포함합니다.
매개 변수화
규칙 기반 매핑을 사용하여 열 이름을 매개 변수화할 수 있습니다. 키워드 name을 사용하여 들어오는 매개 변수에 대해 열 이름을 일치시킵니다. 예를 들어, 데이터 흐름 매개 변수 mycolumn이 있는 경우 mycolumn과 같은 열 이름과 일치하는 규칙을 만들 수 있습니다. 일치하는 열의 이름을 ‘business key’와 같은 하드 코드된 문자열로 바꾸고 명시적으로 참조할 수 있습니다. 이 예제에서 일치 조건은 name == $mycolumn이고 이름 조건은 ‘business key’입니다.
자동 매핑
선택 변환을 추가할 때 자동 매핑 슬라이더를 전환하여 자동 매핑을 사용하도록 설정할 수 있습니다. 자동 매핑을 사용하면 선택 변환은 중복을 제외한 모든 들어오는 열을 입력과 동일한 이름으로 매핑합니다. 여기에는 드리프트된 열이 포함됩니다. 즉, 출력 데이터에 스키마에 정의되지 않은 열이 포함될 수 있습니다. 드리프트된 열에 관한 자세한 내용은 스키마 드리프트를 참조하세요.
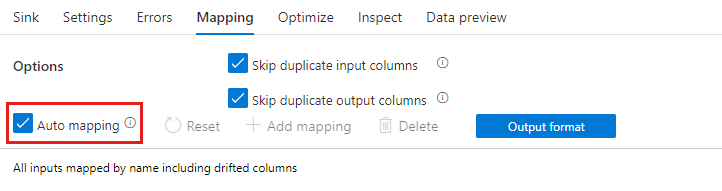
자동 매핑을 켜면 선택 변환은 중복 건너뛰기 설정을 적용하고 기존 열에 새 별칭을 제공합니다. 별칭 지정은 동일한 스트림과 셀프 조인 시나리오에서 여러 조인이나 조회를 수행하는 경우에 유용합니다.
중복 열
기본적으로 선택 변환은 입력 및 출력 프로젝션에서 둘 다 중복 열을 삭제합니다. 중복 입력 열은 종종 열 이름이 조인의 양쪽에서 중복되는 조인 및 조회 변환에서 생성됩니다. 중복 출력 열은 서로 다른 두 입력 열을 같은 이름에 매핑하는 경우 발생할 수 있습니다. 확인란을 토글하여 중복 열을 삭제하거나 전달할지 여부를 선택합니다.
열 순서 지정
매핑 순서에 따라 출력 열의 순서가 결정됩니다. 입력 열이 여러 번 매핑되면 첫 번째 매핑만 적용됩니다. 중복 열을 삭제하는 경우 첫 번째 일치 항목이 유지됩니다.
데이터 흐름 스크립트
구문
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
예시
다음은 선택 매핑과 해당 데이터 흐름 스크립트의 예제입니다.
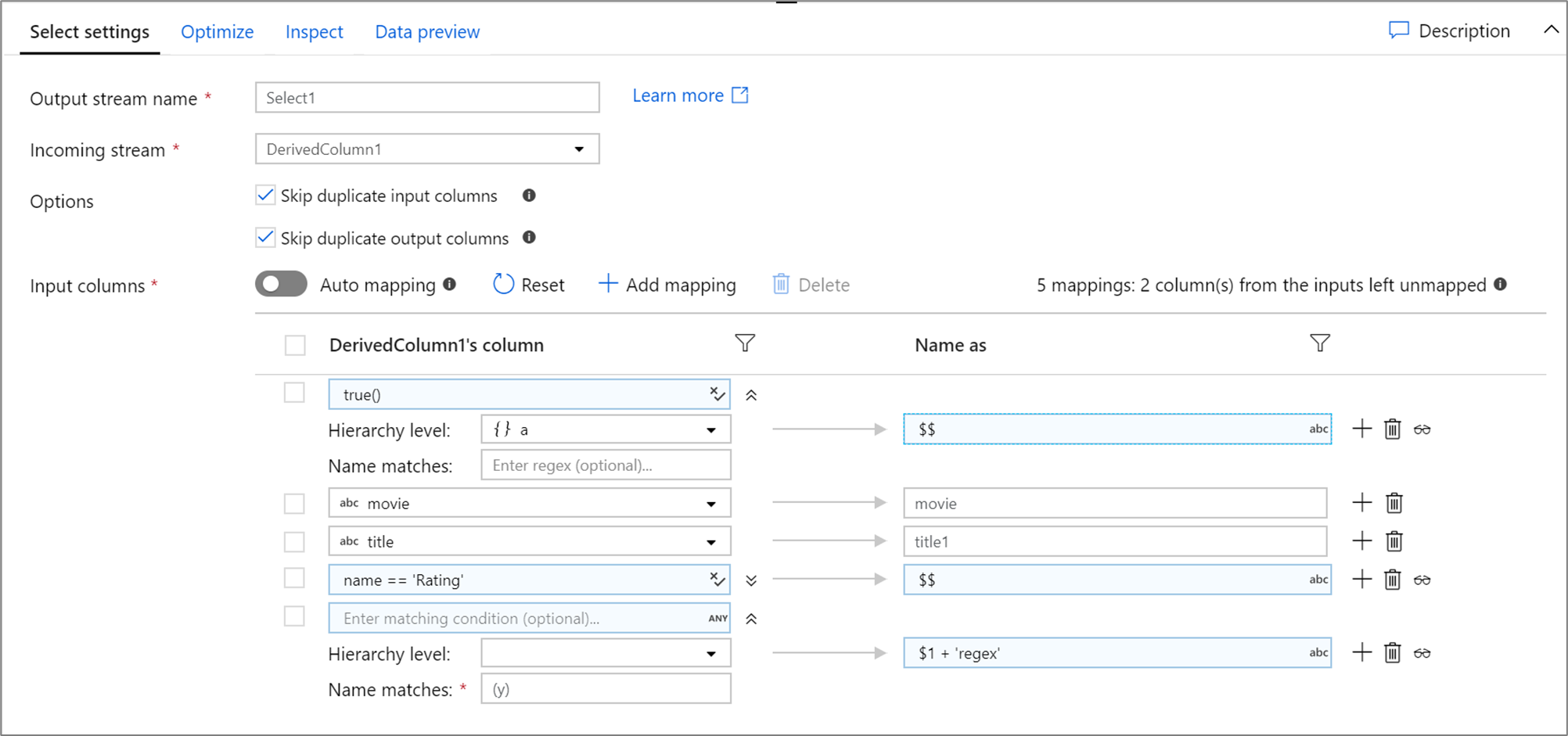
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
관련 콘텐츠
- 선택을 사용하여 열 이름을 바꾸고, 열 순서를 변경하고, 열에 별칭을 지정한 후 싱크 변환을 사용하여 데이터를 데이터 저장소에 저장합니다.