Azure Data Factory 및 Azure Synapse Analytics의 JSON 형식
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
JSON 파일을 구문 분석하거나 데이터를 JSON 형식으로 쓰려면 이 문서의 내용을 따르세요.
JSON 형식은 다음 커넥터에 대해 지원됩니다.
- Amazon S3
- Amazon S3 호환 스토리지
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure 파일
- 파일 시스템
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
데이터 세트 속성
데이터 세트 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 데이터 세트 문서를 참조하세요. 이 섹션에서는 JSON 데이터 세트에서 지원하는 속성의 목록을 제공합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 데이터 세트의 type 속성을 Json으로 설정해야 합니다. | 예 |
| location | 파일의 위치 설정입니다. 각 파일 기반 커넥터에는 location의 고유한 위치 형식 및 지원되는 속성이 있습니다. 자세한 내용은 커넥터 문서 -> 데이터 세트 속성 섹션을 참조하세요. |
예 |
| encodingName | 테스트 파일을 읽고 쓰는 데 사용되는 인코딩 형식입니다. 허용되는 값: "UTF-8","UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
아니요 |
| 압축 | 파일 압축을 구성하는 속성 그룹입니다. 작업 실행 중 압축/압축 풀기를 수행하려는 경우 이 섹션을 구성합니다. | 아니요 |
| type ( compression 아래) |
JSON 파일을 읽고 쓰는 데 사용되는 압축 코덱입니다. 허용되는 값은 bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy 또는 lz4입니다. 기본값은 압축되지 않음입니다. 참고 현재 복사 작업은 "snappy" 및 "lz4"를 지원하지 않으며 매핑 데이터 흐름은 "ZipDeflate", "TarGzip", "Tar"을 지원하지 않습니다. 참고 복사 작업을 통해 ZipDeflate / TarGzip / Tar 파일의 압축을 풀고 파일 기반 싱크 데이터 저장소에 쓸 때, 기본적으로 파일은 <path specified in dataset>/<folder named as source compressed file>/과 같이 폴더로 추출됩니다. 즉, 복사 작업 원본에서 preserveZipFileNameAsFolder / preserveCompressionFileNameAsFolder를 사용하여 압축된 파일의 이름을 폴더 구조로 유지할지 여부를 제어합니다. |
아니요. |
| level ( compression 아래) |
압축 비율입니다. 허용되는 값은 최적 또는 가장 빠름입니다. - 가장 빠름: 결과 파일이 최적으로 압축되지 않은 경우에도 압축 작업을 최대한 빨리 완료해야 합니다. - 최적: 작업이 완료되는데 시간이 오래 걸리더라도 압축 작업이 최적으로 압축되어야 합니다. 자세한 내용은 압축 수준 항목을 참조하세요. |
아니요 |
다음은 Azure Blob Storage에 대한 JSON 데이터 세트의 예입니다.
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
복사 작업 속성
작업 정의에 사용할 수 있는 섹션 및 속성의 전체 목록은 파이프라인 문서를 참조하세요. 이 섹션에서는 JSON 원본 및 싱크에서 지원하는 속성 목록을 제공합니다.
JSON 파일에서 데이터를 추출하고 스키마 매핑에서 싱크 데이터 저장소/형식에 매핑하거나 그 반대로 매핑하는 방법에 대해 알아봅니다.
소스로서의 JSON
복사 작업 *source* 섹션에서 지원되는 속성은 다음과 같습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 작업 원본의 type 속성을 JSONSource로 설정해야 합니다. | 예 |
| formatSettings | 속성 그룹입니다. 아래의 JSON 읽기 설정 표를 참조하세요. | 아니요 |
| storeSettings | 데이터 저장소에서 데이터를 읽는 방법에 대한 속성 그룹입니다. 각 파일 기반 커넥터에는 storeSettings 아래에 고유의 지원되는 읽기 설정이 있습니다. 자세한 내용은 커넥터 문서 -> 복사 작업 속성 섹션을 참조하세요. |
아니요 |
formatSettings에서 지원되는 JSON 읽기 설정:
| 속성 | 설명 | 필수 |
|---|---|---|
| type | formatSettings의 형식을 JsonReadSettings로 설정해야 합니다. | 예 |
| compressionProperties | 지정된 압축 코덱에 대한 데이터의 압축을 푸는 방법에 대한 속성 그룹입니다. | 아니요 |
| preserveZipFileNameAsFolder ( compressionProperties->type 아래 ZipDeflateReadSettings으로) |
ZipDeflate 압축을 사용하여 입력 데이터 세트를 구성할 때 적용됩니다. 원본 zip 파일 이름을 복사 중에 폴더 구조로 유지할지 여부를 나타냅니다. - true(기본값)로 설정하면, 서비스가 압축을 푼 파일을 <path specified in dataset>/<folder named as source zip file>/에 씁니다.- false로 설정하면, 서비스가 압축을 푼 파일을 <path specified in dataset>에 직접 씁니다. 경합 또는 예기치 않은 동작을 방지하기 위해, 다른 원본 zip 파일에 중복된 파일 이름이 없는지 확인합니다. |
아니요 |
| preserveCompressionFileNameAsFolder ( compressionProperties->type 아래 TarGZipReadSettings 또는 TarReadSettings으로) |
입력 데이터 세트가 TarGzip/Tar 압축을 사용하여 구성될 때 적용됩니다. 원본 압축 파일 이름을 복사 중에 폴더 구조로 유지할지 여부를 나타냅니다. - true(기본값)로 설정하면, 서비스가 압축 해제한 파일을 <path specified in dataset>/<folder named as source compressed file>/에 씁니다. - false로 설정하면, 서비스가 압축 해제한 파일을 <path specified in dataset>에 직접 씁니다. 경합 또는 예기치 않은 동작을 방지하기 위해 다른 원본 파일에 중복된 파일 이름이 없는지 확인합니다. |
아니요 |
싱크로서의 JSON
복사 작업 *sink* 섹션에서 지원되는 속성은 다음과 같습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| type | 복사 활동 소스의 유형 특성은 JSONSink로 설정되어야 합니다. | 예 |
| formatSettings | 속성 그룹입니다. 아래의 JSON 쓰기 설정 표를 참조하세요. | 아니요 |
| storeSettings | 데이터 저장소에 데이터를 쓰는 방법에 대한 속성 그룹입니다. 각 파일 기반 커넥터에는 storeSettings 아래에 고유의 지원되는 쓰기 설정이 있습니다. 자세한 내용은 커넥터 문서 -> 복사 작업 속성 섹션을 참조하세요. |
아니요 |
formatSettings에서 지원되는 JSON 쓰기 설정:
| 속성 | 설명 | 필수 |
|---|---|---|
| type | formatSettings의 type을 JsonWriteSettings로 설정해야 합니다. | 예 |
| filePattern | 각 JSON 파일에 저장된 데이터의 패턴을 나타냅니다. 허용되는 값은 setOfObjects(JSON 라인) 및 arrayOfObjects입니다. 기본값은 setOfObjects입니다. 이러한 패턴에 대한 자세한 내용은 JSON 파일 패턴 섹션을 참조하세요. | 아니요 |
JSON 파일 패턴
JSON 파일에서 데이터를 복사하는 경우 복사 작업은 다음과 같은 JSON 파일 패턴을 자동으로 검색하고 구문 분석할 수 있습니다. JSON 파일에 데이터를 쓸 때 복사 작업 싱크에서 파일 패턴을 구성할 수 있습니다.
유형 I: setOfObjects
각 파일에는 단일 개체, JSON 줄 또는 연결된 개체가 포함됩니다.
단일 개체 JSON 예제
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }JSON 라인(싱크 기본값)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}연결된 JSON 예제
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
유형 II: arrayOfObjects
각 파일에 개체 배열이 포함됩니다.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
매핑 데이터 흐름 속성
매핑 데이터 흐름에서는 Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 및 SFTP와 같은 데이터 저장소에서 JSON 형식을 읽고 쓸 수 있으며 Amazon S3에서 JSON 형식을 읽을 수 있습니다.
원본 속성
다음 표에는 json 원본에서 지원하는 속성이 나열되어 있습니다. 이러한 속성은 원본 옵션 탭에서 편집할 수 있습니다.
| 이름 | 설명 | 필수 | 허용된 값 | 데이터 흐름 스크립트 속성 |
|---|---|---|---|---|
| 와일드 카드 경로 | 와일드 카드 경로와 일치하는 모든 파일이 처리됩니다. 데이터 세트에 설정된 폴더 및 파일 경로를 재정의합니다. | 아니요 | String[] | wildcardPaths |
| 파티션 루트 경로 | 분할된 파일 데이터의 경우 분할된 폴더를 열로 읽기 위해 파티션 루트 경로를 입력할 수 있습니다. | 아니요 | 문자열 | partitionRootPath |
| 파일 목록 | 원본이 처리할 파일을 나열하는 문자 파일을 가리키고 있는지 여부. | 아니요 | true 또는 false |
fileList |
| 파일 이름을 저장할 열 | 원본 파일 이름 및 경로를 사용하여 새 열을 만듭니다. | 아니요 | 문자열 | rowUrlColumn |
| 완료 후 | 처리 후 파일을 삭제하거나 이동합니다. 컨테이너 루트에서 파일 경로가 시작됩니다. | 아니요 | 삭제: true 또는 false 이동: ['<from>', '<to>'] |
purgeFiles moveFiles |
| 마지막으로 수정한 시간으로 필터링 | 마지막으로 수정된 시간에 따라 파일을 필터링하도록 선택합니다. | 아니요 | 타임스탬프 | modifiedAfter modifiedBefore |
| 단일 문서 | 매핑 데이터 흐름은 각 파일에서 하나의 JSON 문서를 읽습니다. | 아니요 | true 또는 false |
singleDocument |
| 따옴표로 묶여 있지 않은 열 이름 | 따옴표가 없는 열 이름을 선택하면 매핑 데이터 흐름에서 따옴표로 묶지 않은 JSON 열을 읽습니다. | 아니요 | true 또는 false |
unquotedColumnNames |
| 주석 있음 | JSON 데이터에 C 또는 C++ 스타일 주석이 있는 경우 주석 있음을 선택합니다. | 아니요 | true 또는 false |
asComments |
| 작은따옴표 | 따옴표로 묶여 있지 않은 JSON 열을 읽습니다. | 아니요 | true 또는 false |
singleQuoted |
| 백슬래시가 이스케이프되었습니다. | JSON 데이터에서 문자를 이스케이프하는 데 백슬래시를 사용하는 경우 백슬래시 이스케이프를 선택합니다. | 아니요 | true 또는 false |
backslashEscape |
| 파일을 찾을 수 없음 허용 | true이면 파일이 없는 경우 오류가 throw되지 않습니다. | 아니요 | true 또는 false |
ignoreNoFilesFound |
인라인 데이터 세트
매핑 데이터 흐름은 원본 및 싱크를 정의하기 위한 옵션으로 "인라인 데이터 세트"를 지원합니다. 인라인 JSON 데이터 세트는 원본 및 싱크 변환 내부에서 직접 정의되며 정의된 데이터 흐름 외부에서는 공유되지 않습니다. 이는 데이터 흐름 내에서 직접 데이터 세트 속성을 매개 변수화하는 데 유용하며 공유 ADF 데이터 세트에 비해 개선된 성능의 이점을 활용할 수 있습니다.
많은 수의 원본 폴더 및 파일을 읽는 경우 프로젝션 | 내에서 프로젝션 | 스키마 옵션 대화 상자 내에서 "사용자 프로젝션 스키마" 옵션을 설정하여 데이터 흐름 파일 검색 성능을 개선할 수 있습니다. 이 옵션은 ADF의 기본 스키마 자동 검색을 끄고 파일 검색 성능을 크게 개선합니다. 이 옵션을 설정하기 전에 ADF에 프로젝션을 위한 기존 스키마가 있도록 JSON 프로젝션을 가져와야 합니다. 이 옵션은 스키마 드리프트에는 작동하지 않습니다.
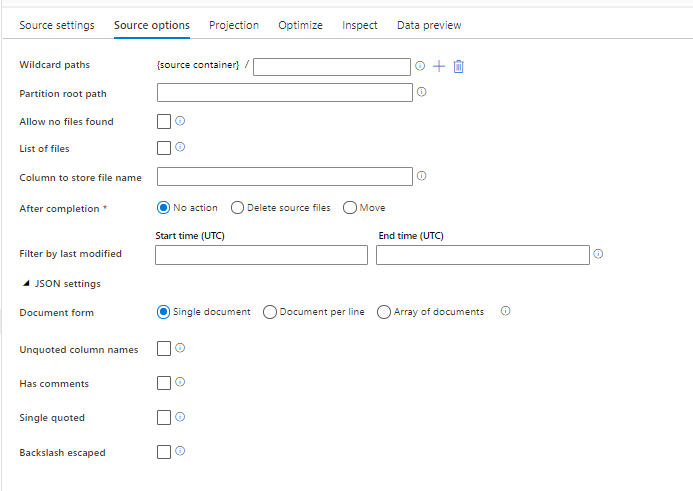
원본 형식 옵션
데이터 흐름에서 JSON 데이터 세트를 원본으로 사용하면 5개의 추가 설정을 설정할 수 있습니다. 이러한 설정은 원본 옵션 탭의 JSON 설정 아코디언에서 찾을 수 있습니다. 문서 양식 설정의 경우 단일 문서, 줄당 문서 및 문서 배열 유형 중 하나를 선택할 수 있습니다.
기본값
기본적으로 JSON 데이터는 다음 형식으로 읽습니다.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
단일 문서
단일 문서를 선택한 경우 매핑 데이터 흐름은 각 파일에서 하나의 JSON 문서를 읽습니다.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
줄당 문서를 선택한 경우 매핑 데이터 흐름은 파일의 각 줄에서 하나의 JSON 문서를 읽습니다.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
문서 배열을 선택한 경우 매핑 데이터 흐름은 파일에서 문서 배열 하나를 읽습니다.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
참고 항목
데이터 흐름에서 JSON 데이터를 미리 볼 때 "corrupt_record"라는 오류가 발생하는 경우 데이터에 JSON 파일에 단일 문서가 포함되어 있을 가능성이 있습니다. "단일 문서"를 설정하면 해당 오류가 해결됩니다.
따옴표로 묶여 있지 않은 열 이름
따옴표가 없는 열 이름을 선택하면 매핑 데이터 흐름에서 따옴표로 묶지 않은 JSON 열을 읽습니다.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
주석 있음
JSON 데이터에 C 또는 C++ 스타일 주석이 있는 경우 주석 있음을 선택합니다.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
작은따옴표
JSON 필드 및 값이 큰따옴표 대신 작은따옴표를 사용하는 경우 작은따옴표를 선택합니다.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
백슬래시가 이스케이프되었습니다.
JSON 데이터에서 문자를 이스케이프하는 데 백슬래시를 사용하는 경우 백슬래시 이스케이프를 선택합니다.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
싱크 속성
다음 표에는 json 싱크에서 지원하는 속성이 나열되어 있습니다. 이러한 속성은 설정 탭에서 편집할 수 있습니다.
| 이름 | 설명 | 필수 | 허용된 값 | 데이터 흐름 스크립트 속성 |
|---|---|---|---|---|
| 폴더 지우기 | 쓰기 전에 대상 폴더를 지운 경우 | 아니요 | true 또는 false |
truncate |
| 파일 이름 옵션 | 작성된 데이터의 명명 형식입니다. 기본적으로 파티션당 파일 하나이고 형식은 part-#####-tid-<guid>입니다. |
아니요 | 패턴: String 파티션당: String[] 열의 데이터로: String 단일 파일로 출력: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
파생 열에서 JSON 구조 만들기
파생 열 식 작성기를 통해 데이터 흐름에 복잡한 열을 추가할 수 있습니다. 파생 열 변환에서 새 열을 추가하고 파란색 상자를 클릭하여 식 작성기를 엽니다. 열을 복잡하게 만들려면 JSON 구조를 수동으로 입력하거나 UX를 사용하여 하위 열을 대화형으로 추가할 수 있습니다.
식 작성기 UX 사용
출력 스키마 쪽 창에서 열 위로 마우스를 이동하고 더하기 아이콘을 클릭합니다. 열을 복합 유형으로 만들려면 하위 열 추가를 선택합니다.
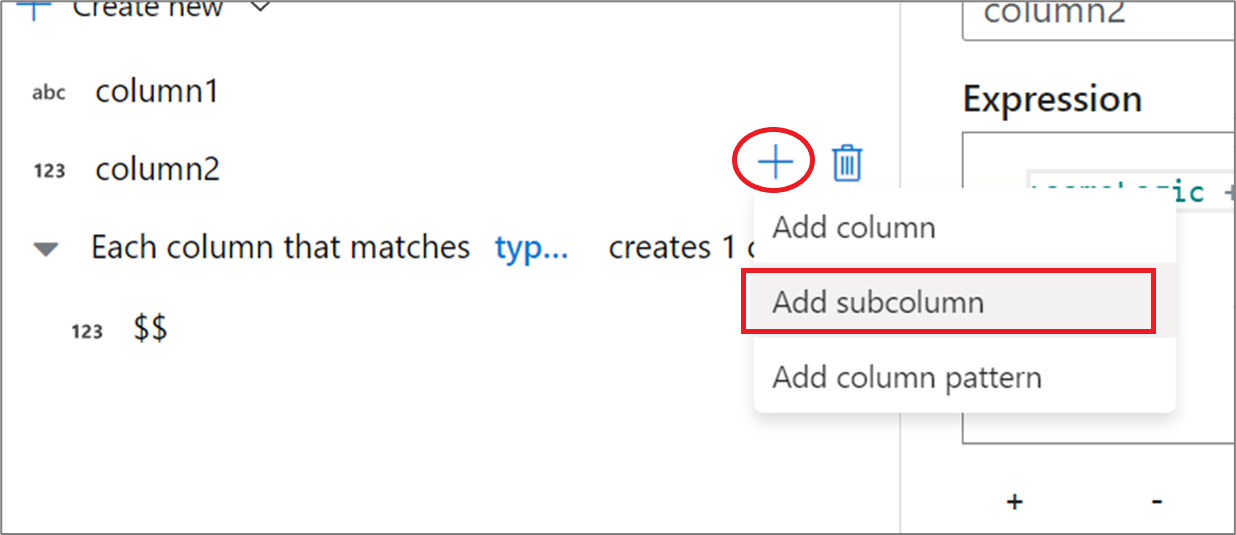
동일한 방식으로 열 및 하위 열을 더 추가할 수 있습니다. 복합 필드가 아닌 각 필드에 대해 식 편집기의 오른쪽에 식을 추가할 수 있습니다.
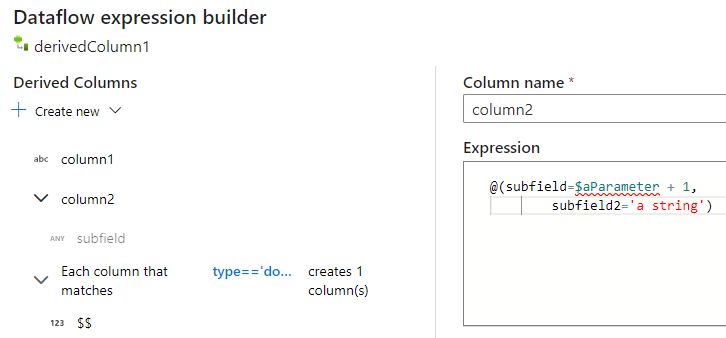
수동으로 JSON 구조 입력
JSON 구조를 수동으로 추가하려면 새 열을 추가하고 편집기에 식을 입력합니다. 표현식은 다음과 같은 일반 형식을 따릅니다.
@(
field1=0,
field2=@(
field1=0
)
)
이 표현식이 "complexColumn"이라는 열에 입력된 경우 다음 JSON으로 싱크에 기록됩니다.
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
전체 계층 정의에 대한 수동 스크립트 예
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
관련 커넥터 및 형식
다음은 JSON 형식과 관련된 몇 가지 일반적인 커넥터 및 형식입니다.