작업 시스템 테이블 참조
참고 항목
스키마는 lakeflow 이전에 .로 workflow알려져 있었습니다. 두 스키마의 콘텐츠는 동일합니다. 스키마를 lakeflow 표시하려면 스키마를 별도로 사용하도록 설정해야 합니다.
이 문서는 lakeflow 시스템 테이블을 사용하여 계정의 작업을 모니터링하는 방법에 대한 참조입니다. 이러한 테이블에는 동일한 클라우드 지역에 배포된 계정의 모든 작업 영역 레코드가 포함됩니다. 다른 지역의 레코드를 보려면 해당 지역에 배포된 작업 영역에서 테이블을 확인해야 합니다.
요구 사항
- 계정 관리자가
스키마를 사용하도록 설정해야 합니다. 시스템 테이블 스키마사용 참조하세요. - 이러한 시스템 테이블에 액세스하려면 사용자는 다음 중 하나를 수행해야 합니다.
- metastore 관리자이거나 계정 관리자이거나, 또는
- 시스템 스키마에 대한
USE및SELECT권한이 있습니다. 시스템 테이블대한 액세스 권한 부여를 참조하세요.
사용 가능한 작업 테이블
모든 작업 관련 시스템 테이블은 스키마에 system.lakeflow 있습니다. 현재 스키마는 다음 네 개의 테이블을 호스팅합니다.
| 테이블 | 설명 | 스트리밍 지원 | 무료 보존 기간 | 전역 또는 지역 데이터 포함 |
|---|---|---|---|---|
| 작업(공개 미리 보기) | 계정에서 만든 모든 작업을 추적합니다. | 예 | 365일 | 지역의 |
| job_tasks (공개 미리보기) | 계정에서 실행되는 모든 작업을 추적합니다. | 예 | 365일 | 지역의 |
| job_run_timeline (공개 미리 보기) | 작업 실행 및 관련 메타데이터 추적 | 예 | 365일 | 지역의 |
| job_task_run_timeline(공개 미리 보기) | 작업 실행 및 관련 메타데이터 추적 | 예 | 365일 | 지역의 |
세부적인 스키마 참조
다음 섹션에서는 각 작업 관련 시스템 테이블에 대한 스키마 참조를 제공합니다.
작업 테이블 스키마
jobs 테이블은 SCD2(느린 변경 차원 테이블)입니다. 행이 변경되면 새 행이 내보내집니다. 논리적으로 이전 행을 대체합니다.
테이블 경로: system.lakeflow.jobs
| 열 이름 | 데이터 형식 | 설명 | 노트 |
|---|---|---|---|
account_id |
string | 이 작업이 속한 계정의 ID | |
workspace_id |
string | 이 작업이 속한 작업 영역의 ID | |
job_id |
string | 작업의 ID입니다. | 단일 작업 영역 내에서만 고유 |
name |
string | 사용자가 제공한 작업의 이름 | |
description |
string | 사용자가 제공한 작업에 대한 설명입니다. | 2024년 8월 말 이전에 내보낸 행에 대해 데이터가 입력되지 않음 |
creator_id |
string | 작업을 만든 주체의 ID입니다. | |
tags |
string | 이 작업과 연결된 사용자가 제공한 사용자 지정 태그 | |
change_time |
timestamp | 작업이 마지막으로 수정된 시간 | +00:00(UTC)로 기록된 표준 시간대 |
delete_time |
timestamp | 사용자가 작업을 삭제한 시간입니다. | +00:00(UTC)로 기록된 표준 시간대 |
run_as |
string | 작업 실행에 사용 권한이 사용되는 사용자 또는 서비스 주체의 ID입니다. |
예제 쿼리
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
작업 작업 테이블 스키마
작업 테이블은 느리게 변하는 차원 테이블(SCD2)입니다. 행이 변경되면 새 행이 내보내집니다. 논리적으로 이전 행을 대체합니다.
테이블 경로: system.lakeflow.job_tasks
| 열 이름 | 데이터 형식 | 설명 | 노트 |
|---|---|---|---|
account_id |
string | 이 작업이 속한 계정의 ID | |
workspace_id |
string | 이 작업이 속한 작업 영역의 ID | |
job_id |
string | 작업의 ID입니다. | 단일 작업 영역 내에서만 고유 |
task_key |
string | 작업 내 작업에 대한 참조 키입니다. | 단일 작업 내에서만 고유 |
depends_on_keys |
배열 | 이 작업의 모든 상위 종속성의 태스크 키 | |
change_time |
timestamp | 작업이 마지막으로 수정된 시간 | +00:00(UTC)로 기록된 표준 시간대 |
delete_time |
timestamp | 사용자가 작업을 삭제한 시간입니다. | +00:00(UTC)로 기록된 표준 시간대 |
예제 쿼리
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
작업 실행 타임라인 테이블 스키마
작업 실행 타임라인 테이블은 변경할 수 없으며 생성될 때 완료됩니다.
테이블 경로: system.lakeflow.job_run_timeline
| 열 이름 | 데이터 형식 | 설명 | 노트 |
|---|---|---|---|
account_id |
string | 이 작업이 속한 계정의 ID | |
workspace_id |
string | 이 작업이 속한 작업 영역의 ID | |
job_id |
string | 작업의 ID입니다. | 이 키는 단일 작업 영역 내에서만 고유합니다. |
run_id |
string | 작업 실행의 ID | |
period_start_time |
timestamp | 달리기나 기간의 시작 시간 | 표준 시간대 정보는 UTC를 나타내는 +00:00 사용하여 값의 끝에 기록됩니다. |
period_end_time |
timestamp | 실행의 종료 시간 또는 기간의 종료 시간 | 표준 시간대 정보는 UTC를 나타내는 +00:00 사용하여 값의 끝에 기록됩니다. |
trigger_type |
string | 실행할 수 있는 트리거의 유형입니다. | 가능한 값은 트리거 형식 값을 참조 하세요. |
run_type |
string | 작업 실행 유형 | 가능한 값은 실행 형식 값 참조하세요. |
run_name |
string | 이 작업 실행과 연결된 사용자 제공 실행 이름 | |
compute_ids |
배열 | 부모 작업 실행에 해당하는 작업 컴퓨팅 ID를 포함하는 배열 |
SUBMIT_RUN 및 WORKFLOW_RUN 실행 형식에서 사용하는 작업 클러스터를 식별하는 데 사용합니다. 다른 컴퓨팅 정보는 테이블을 참조하세요 job_task_run_timeline .2024년 8월 말 이전에 내보낸 행에 대해 데이터가 입력되지 않음 |
result_state |
string | 작업 실행의 결과 | 가능한 값은 결과 상태 값 참조하세요. |
termination_code |
string | 작업 실행의 종료 코드 | 가능한 값은 종료 코드 값을 참조 하세요. 2024년 8월 말 이전에 내보낸 행에 대해 데이터가 입력되지 않음 |
job_parameters |
map | 작업 실행에 사용되는 작업 수준 매개 변수 | 사용되지 않는 notebook_params 설정은 이 필드에 포함되지 않습니다. 2024년 8월 말 이전에 내보낸 행에 대해 데이터가 입력되지 않음 |
예제 쿼리
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name={run_name}
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
작업 작업 실행 타임라인 테이블 스키마
작업 작업 실행 타임라인 테이블은 변경할 수 없으며 생성될 때 완료됩니다.
테이블 경로: system.lakeflow.job_task_run_timeline
| 열 이름 | 데이터 형식 | 설명 | 노트 |
|---|---|---|---|
account_id |
string | 이 작업이 속한 계정의 ID | |
workspace_id |
string | 이 작업이 속한 작업 영역의 ID | |
job_id |
string | 작업의 ID입니다. | 단일 작업 영역 내에서만 고유 |
run_id |
string | 작업 실행의 ID | |
job_run_id |
string | 작업 실행의 ID | 2024년 8월 말 이전에 내보낸 행에 대해 데이터가 입력되지 않음 |
parent_run_id |
string | 부모 실행의 ID | 2024년 8월 말 이전에 내보낸 행에 대해 데이터가 입력되지 않음 |
period_start_time |
timestamp | 작업 또는 기간의 시작 시간입니다. | 표준 시간대 정보는 UTC를 나타내는 +00:00 사용하여 값의 끝에 기록됩니다. |
period_end_time |
timestamp | 작업 또는 기간의 종료 시간 | 표준 시간대 정보는 UTC를 나타내는 +00:00 사용하여 값의 끝에 기록됩니다. |
task_key |
string | 작업 내 작업에 대한 참조 키입니다. | 이 키는 단일 작업 내에서만 고유합니다. |
compute_ids |
배열 | compute_ids 배열에는 작업 태스크에서 사용하는 작업 클러스터, 대화형 클러스터 및 SQL 웨어하우스의 ID가 포함됩니다. | |
result_state |
string | 작업 실행의 결과 | 가능한 값은 결과 상태 값 참조하세요. |
termination_code |
string | 작업 실행의 종료 코드 | 가능한 값은 종료 코드 값을 참조 하세요. 2024년 8월 말 이전에 내보낸 행에 대해 데이터가 입력되지 않음 |
일반적인 조인 패턴
다음 섹션에서는 작업 시스템 테이블에 일반적으로 사용되는 조인 패턴을 강조하는 샘플 쿼리를 제공합니다.
작업 및 작업 실행 타임라인 테이블 조인
작업 이름을 사용하여 작업 실행을 강화하기
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
작업 이름으로 사용량 보강
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
usage.*,
coalesce(usage_metadata.job_name, jobs.name) as job_name
FROM system.billing.usage
LEFT JOIN jobs ON usage.workspace_id=jobs.workspace_id AND usage.usage_metadata.job_id=jobs.job_id
WHERE
billing_origin_product="JOBS"
작업 실행 타임라인 및 사용 현황 테이블 조인
작업 실행 메타데이터로 각 청구 로그를 풍부하게 하다
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
작업 실행당 비용 계산
이 쿼리는 billing.usage 시스템 테이블과 조인하여 작업 실행당 비용을 계산합니다.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
작업 실행 타임라인 및 클러스터 테이블 조인
작업 실행을 클러스터 메타데이터로 강화하기
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
다목적 컴퓨팅에서 실행되는 작업 찾기
이 쿼리는 시스템 테이블과 compute.clusters 조인되어 작업 컴퓨팅 대신 다목적 컴퓨팅에서 실행 중인 최근 작업을 반환합니다.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
작업 모니터링 대시보드
다음 대시보드는 시스템 테이블을 사용하여 작업 및 운영 상태 모니터링을 시작하는 데 도움이 됩니다. 여기에는 작업 성능 추적, 오류 모니터링 및 리소스 사용률과 같은 일반적인 사용 사례가 포함됩니다.
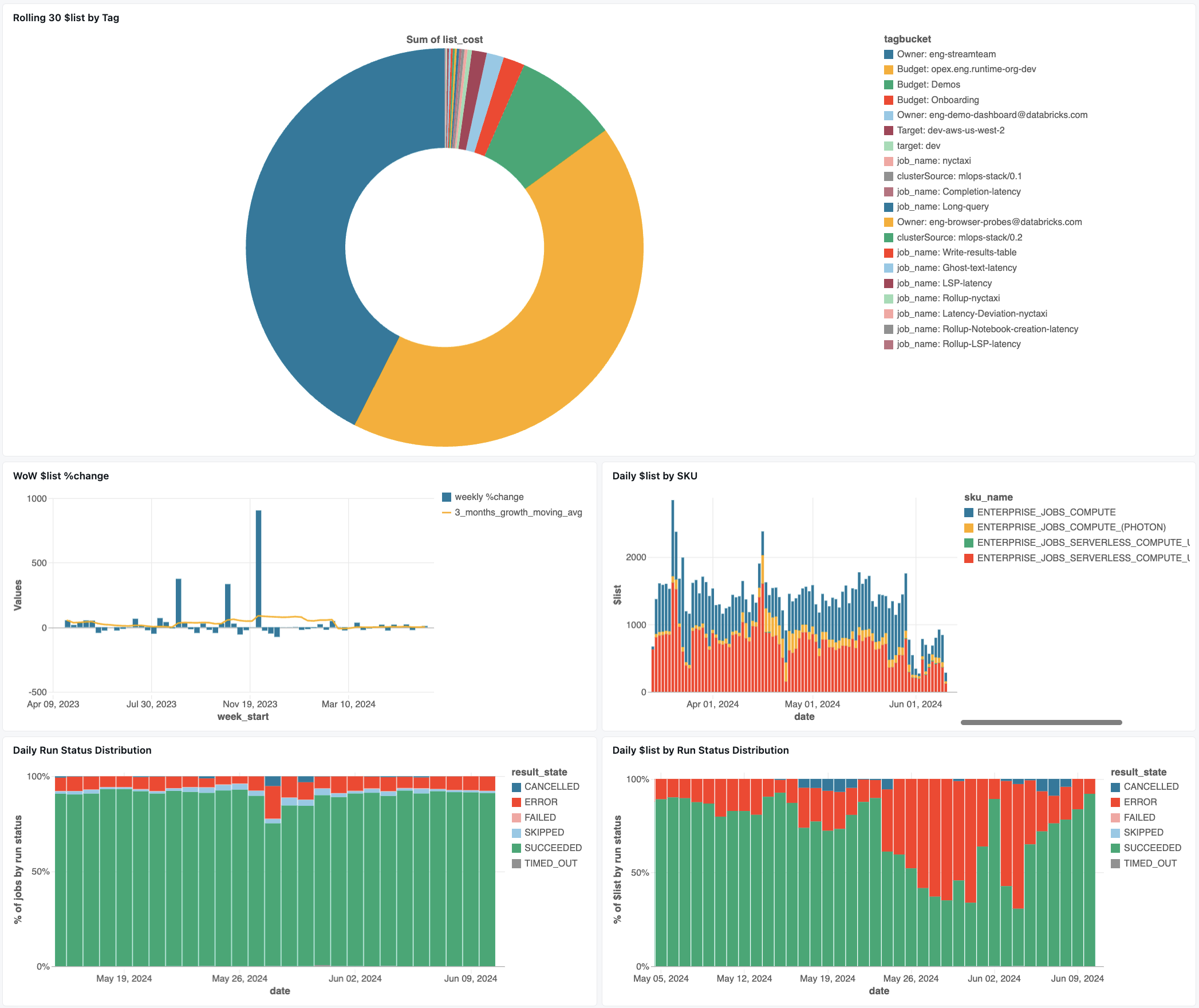
대시보드 다운로드에 대한 자세한 내용은 시스템 테이블 사용하여 작업 비용 & 성능 모니터링을 참조하세요.
문제 해결
작업이 lakeflow.jobs 테이블에 기록되지 않음
시스템 테이블에 작업이 표시되지 않는 경우:
- 지난 365일 동안 작업이 수정되지 않았습니다.
- 작업이 다른 지역에 생성되었습니다.
- 최근 작업 생성(테이블 지연 시간)
job_run_timeline 테이블에 표시된 작업을 찾을 수 없습니다.
모든 작업 실행이 어디에나 표시되는 것은 아닙니다.
JOB_RUN 항목은 모든 작업 관련 테이블에 나타나지만 WORKFLOW_RUN(Notebook 워크플로 실행) 및 SUBMIT_RUN(일회성 제출 실행)는 모두 job_run_timeline 테이블에만 기록됩니다. 이러한 실행은 jobs 또는 job_tasks같은 다른 작업 시스템 테이블에 채워지지 않습니다.
각 실행 유형이 표시되고 액세스할 수 있는 위치에 대한 자세한 내용은 아래 실행 형식 표를 참조하세요.
billing.usage 테이블에 작업 실행이 표시되지 않음
system.billing.usage에서는 작업 컴퓨팅 또는 서버리스 컴퓨팅에서 실행되는 작업에 대해서만 usage_metadata.job_id이 채워집니다.
또한 WORKFLOW_RUN 작업에는 usage_metadata.job_id에서 자신만의 usage_metadata.job_run_id 또는 system.billing.usage 속성이 없습니다.
대신, 컴퓨팅 사용량은 해당 컴퓨팅을 실행시킨 부모 노트북에 귀속됩니다.
즉, Notebook이 워크플로 실행을 시작할 때 모든 컴퓨팅 비용은 별도의 워크플로 작업으로 나타나는 것이 아니라 부모 Notebook의 사용량 아래에 표시됩니다.
자세한 내용은 사용량 메타데이터 분석을 참조하세요.
다목적 컴퓨팅에서 실행되는 작업의 비용 계산
100개의% 정확도로는 의도적인 컴퓨팅을 실행하는 작업에 대한 정확한 비용 계산이 불가능합니다. 작업이 대화형(다목적) 컴퓨팅에서 실행되는 경우 Notebook, SQL 쿼리 또는 기타 작업과 같은 여러 워크로드가 동일한 컴퓨팅 리소스에서 동시에 실행되는 경우가 많습니다. 클러스터 리소스는 공유되므로 컴퓨팅 비용과 개별 작업 실행 간에 직접 1:1 매핑이 없습니다.
정확한 작업 비용 추적을 위해, Databricks는 전용 작업 컴퓨팅이나 서버리스 컴퓨팅에서 작업을 실행할 것을 권장합니다. 여기에서 usage_metadata.job_id 및 usage_metadata.job_run_id은 정확한 비용 특성을 부여합니다.
다목적 컴퓨팅을 사용해야 하는 경우 다음을 수행할 수 있습니다.
-
system.billing.usage을 기준으로 하여usage_metadata.cluster_id전체 클러스터 사용량 및 비용을 모니터링합니다. - 작업 런타임 메트릭을 별도로 추적합니다.
- 공유 리소스로 인한 예상 비용은 대략적인 것입니다.
비용 할당에 대한 자세한 내용은 분석 사용량 메타데이터을 참조하세요.
참조 값
다음 섹션에는 작업 관련 테이블의 선택 열에 대한 참조가 포함되어 있습니다.
트리거 형식 값
열에 사용할 수 있는 trigger_type 값은 다음과 같습니다.
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
실행 형식 값
열에 사용할 수 있는 run_type 값은 다음과 같습니다.
| 유형 | 설명 | UI 위치 | API 엔드포인트 | 시스템 테이블 |
|---|---|---|---|---|
JOB_RUN |
표준 작업 실행 | 작업 & 작업 실행 UI | /jobs 및 /jobs/runs 엔드포인트 | 작업, 작업_업무, 작업_수행_타임라인, 작업_업무_수행_타임라인 |
SUBMIT_RUN |
POST를 통한 일회성 실행 /jobs/runs/submit | 작업 실행 UI 전용 | /jobs/runs 엔드포인트만 사용하세요 | 작업 실행 일정 |
WORKFLOW_RUN |
노트북 워크플로에서 실행됨 | 표시되지 않음 | 액세스할 수 없음 | 작업 실행 일정 |
결과 상태 값
열에 사용할 수 있는 result_state 값은 다음과 같습니다.
| 상태 | 설명 |
|---|---|
SUCCEEDED |
실행이 성공적으로 완료되었습니다. |
FAILED |
오류와 함께 실행이 완료되었습니다. |
SKIPPED |
조건이 충족되지 않아 실행되지 않았습니다. |
CANCELLED |
사용자의 요청에 따라 실행이 취소되었습니다. |
TIMED_OUT |
시간 제한에 도달한 후 실행이 중지되었습니다. |
ERROR |
오류와 함께 실행이 완료되었습니다. |
BLOCKED |
업스트림 종속성에서 실행이 차단되었습니다. |
종료 코드 값
열에 사용할 수 있는 termination_code 값은 다음과 같습니다.
| 종료 코드 | 설명 |
|---|---|
SUCCESS |
실행이 성공적으로 완료되었습니다. |
CANCELLED |
Databricks 플랫폼에서 실행하는 동안 실행이 취소되었습니다. 예를 들어 최대 실행 기간을 초과한 경우 |
SKIPPED |
예를 들어 업스트림 태스크 실행이 실패하거나 종속성 유형 조건이 충족되지 않았거나 실행할 재질 작업이 없는 경우 실행이 실행되지 않았습니다. |
DRIVER_ERROR |
Spark 드라이버와 통신하는 동안 실행 중 오류가 발생했습니다. |
CLUSTER_ERROR |
클러스터 오류로 인해 실행이 실패했습니다. |
REPOSITORY_CHECKOUT_FAILED |
타사 서비스와 통신할 때 오류로 인해 체크 아웃을 완료하지 못했습니다. |
INVALID_CLUSTER_REQUEST |
클러스터를 시작하라는 잘못된 요청을 실행했기 때문에 실행이 실패했습니다. |
WORKSPACE_RUN_LIMIT_EXCEEDED |
작업 영역이 최대 동시 활성 실행 수 할당량에 도달했습니다. 실행 일정을 더 넓은 시간대에 걸쳐 잡는 것이 좋습니다. |
FEATURE_DISABLED |
작업 영역에 사용할 수 없는 기능에 액세스하려고 했기 때문에 실행이 실패했습니다. |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
클러스터 만들기, 시작 및 크기 조정 요청 수가 할당된 속도 제한을 초과했습니다. 실행을 더 긴 시간 동안 분산하는 것이 좋습니다. |
STORAGE_ACCESS_ERROR |
고객 Blob Storage에 액세스할 때 오류로 인해 실행이 실패했습니다. |
RUN_EXECUTION_ERROR |
작업이 실패하여 실행이 완료되었습니다. |
UNAUTHORIZED_ERROR |
리소스에 액세스하는 동안 권한 문제로 인해 실행이 실패했습니다. |
LIBRARY_INSTALLATION_ERROR |
사용자가 요청한 라이브러리를 설치하는 동안 실행이 실패했습니다. 원인에는 제공된 라이브러리가 유효하지 않고 라이브러리를 설치할 수 있는 권한이 부족하기 때문에 다음이 포함될 수 있지만 제한되지는 않습니다. |
MAX_CONCURRENT_RUNS_EXCEEDED |
예약된 실행이 작업에 대해 설정된 최대 동시 실행 제한을 초과합니다. |
MAX_SPARK_CONTEXTS_EXCEEDED |
실행은 만들도록 구성된 최대 컨텍스트 수에 이미 도달한 클러스터에서 예약됩니다. |
RESOURCE_NOT_FOUND |
실행에 필요한 리소스가 존재하지 않습니다. |
INVALID_RUN_CONFIGURATION |
잘못된 구성으로 인해 실행이 실패했습니다. |
CLOUD_FAILURE |
클라우드 공급자 문제로 인해 실행이 실패했습니다. |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
작업 수준 큐 크기 제한에 도달하여 실행을 건너뛰었다. |