엔드포인트를 제공하는 모델에서 AI 게이트웨이 구성
이 문서에서는 엔드포인트를 제공하는 모델에서 Mosaic AI Gateway를 구성하는 방법에 대해 알아봅니다.
요구 사항
- 지원되는 외부 모델의 Databricks 작업 영역입니다.
- 엔드포인트를 제공하는 외부 모델 만들기의 1단계와 2단계를 완료합니다.
UI를 사용하여 AI 게이트웨이 구성
이 섹션에서는 서비스 UI를 사용하여 엔드포인트를 만드는 동안 AI 게이트웨이를 구성하는 방법을 보여 줍니다.
프로그래밍 방식으로 이 작업을 수행하려면 Notebook 예제를 참조하세요.
엔드포인트 만들기 페이지의 AI 게이트웨이 섹션에서 다음 AI 게이트웨이 기능을 개별적으로 구성할 수 있습니다.
| 기능 | 사용 방법 | 세부 정보 |
|---|---|---|
| 사용 추적 | 사용량 추적 사용을 선택하여 데이터 사용 메트릭 추적 및 모니터링을 사용하도록 설정합니다. | - Unity 카탈로그를 사용하도록 설정해야 합니다. - 계정 관리자는 system.serving.endpoint_usage 시스템 테이블을 사용하기 전에 서비스 시스템 테이블 스키마를 사용하도록 설정해야 합니다. 이 스키마 테이블은 엔드포인트 및 system.serving.served_entities에 대한 각 요청에 대한 토큰 수를 캡처하고 각 외부 모델에 대한 메타데이터를 저장합니다.- 사용량 추적 테이블 스키마 참조 - 엔드포인트를 관리하는 사용자가 사용량 추적을 사용하도록 설정해야 하더라도 계정 관리자만 served_entities 테이블 또는 endpoint_usage 테이블을 보거나 쿼리할 수 있는 권한이 있습니다. 시스템 테이블에 대한 액세스 권한 부여 참조- 입력 및 출력 토큰 수는 모델에서 토큰 수를 반환하지 않는 경우 ( text_length+1)/4로 추정됩니다. |
| 페이로드 로깅 | 유추 테이블 사용을 선택하여 엔드포인트의 요청 및 응답을 Unity 카탈로그에서 관리하는 델타 테이블에 자동으로 기록합니다. | - Unity 카탈로그가 활성화되어 있어야 하며 지정된 카탈로그 스키마에서 CREATE_TABLE 권한을 가지고 있어야 합니다.- AI Gateway에서 사용하도록 설정된 유추 테이블에는 사용자 지정 모델을 제공하는 엔드포인트를 제공하는 모델을 위해 만든 유추 테이블과 다른 스키마가 있습니다. AI 게이트웨이 사용 유추 테이블 스키마를 참조하세요. - 페이로드 로깅 데이터는 엔드포인트를 쿼리한 후 1시간 이내에 이러한 테이블을 채웁니다. - 1MB보다 큰 페이로드는 기록되지 않습니다. - 응답 페이로드는 반환된 모든 청크의 응답을 집계합니다. - 스트리밍이 지원됩니다. 스트리밍 시나리오에서 응답 페이로드는 반환된 청크의 응답을 집계합니다. |
| AI 가드레일 | UI에서 AI 가드레일 구성을 참조하세요. | - 가드레일은 모델이 모델 입력 및 출력에서 감지된 안전하지 않고 유해한 콘텐츠와 상호 작용하는 것을 방지합니다. - 출력 가드레일은 포함 모델 또는 스트리밍에 지원되지 않습니다. |
| 트래픽률 제한 | 요청 트래픽률 제한을 적용하여 사용자별 및 엔드포인트별로 엔드포인트에 대한 트래픽을 관리할 수 있습니다 | - 트래픽률 제한은 분당 쿼리(QPM)에 정의됩니다. - 기본값은 사용자당 및 엔드포인트당 제한 없음입니다. |
| 트래픽 라우팅 | 엔드포인트에서 트래픽 라우팅을 구성하려면 엔드포인트에 여러 외부 모델 제공을 참조하세요. |
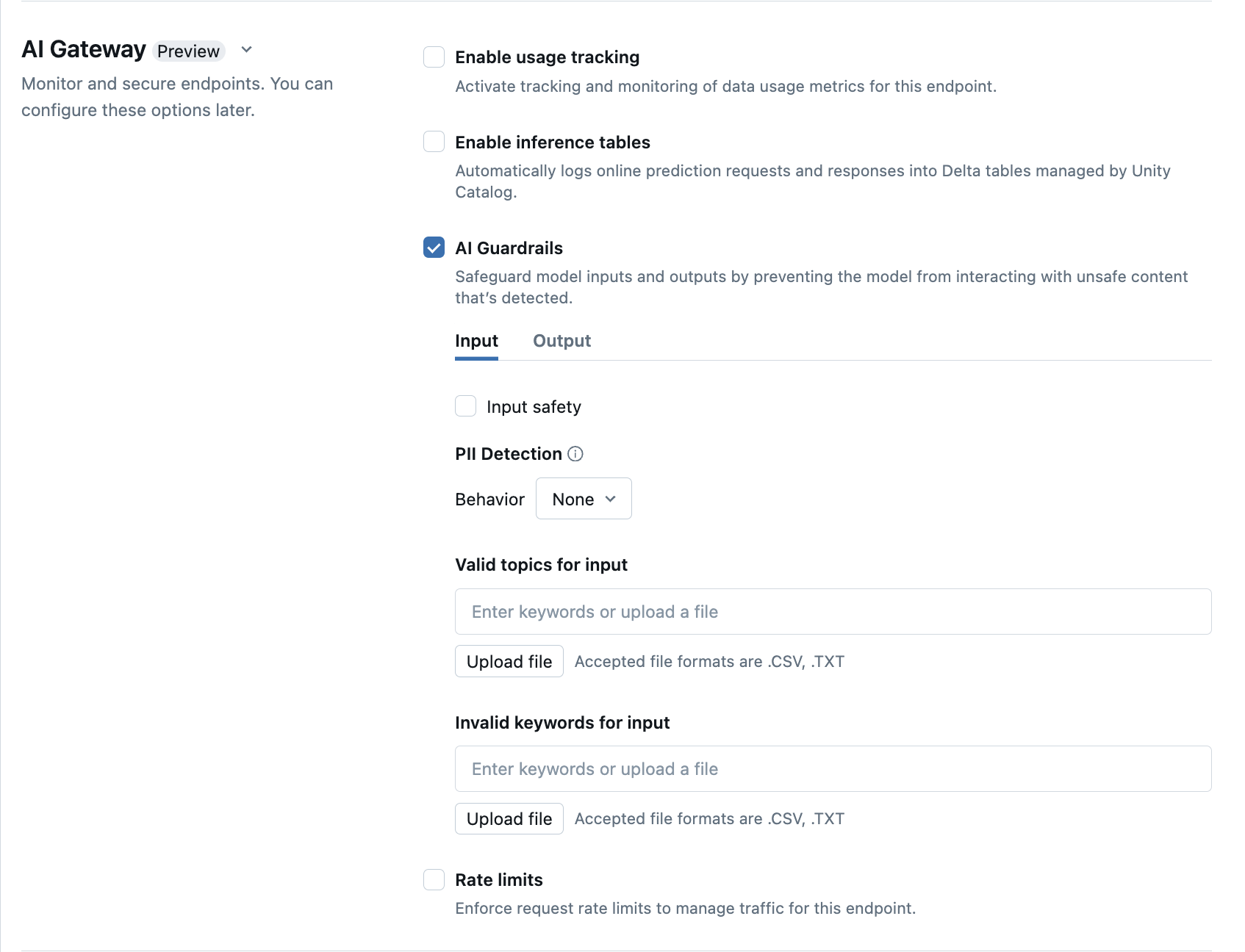
UI에서 AI 가드레일 구성을 참조하세요
다음 표에서는 지원되는 가드레일을 구성하는 방법을 보여 줍니다.
| 가드레일 | 사용 방법 | 세부 정보 |
|---|---|---|
| 안전 | 안전을 선택하여 모델이 안전하지 않고 유해한 콘텐츠와 상호 작용하지 않도록 안전 장치를 사용합니다. | |
| PII(개인 식별 정보) 검색 | PII 검색을 선택하여 이름, 주소, 신용 카드 번호와 같은 PII 데이터를 검색합니다. | |
| 유효한 항목 | 이 필드에 직접 항목을 입력할 수 있습니다. 항목이 여러 개 있는 경우 각 항목 뒤의 Enter 키를 눌러야 합니다. 또는 .csv 또는 .txt 파일을 업로드할 수 있습니다. |
최대 50개의 유효한 토픽을 지정할 수 있습니다. 각 토픽은 100자를 초과할 수 없습니다 |
| 잘못된 키워드 | 이 필드에 직접 항목을 입력할 수 있습니다. 항목이 여러 개 있는 경우 각 항목 뒤의 Enter 키를 눌러야 합니다. 또는 .csv 또는 .txt 파일을 업로드할 수 있습니다. |
최대 50개의 잘못된 키워드를 지정할 수 있습니다. 각 키워드는 100자를 초과할 수 없습니다. |
사용량 추적 테이블 스키마
system.serving.served_entities 사용량 추적 시스템 테이블에는 다음 스키마가 있습니다.
| 열 이름 | 설명 | Type |
|---|---|---|
served_entity_id |
제공된 엔터티의 고유 ID입니다. | STRING |
account_id |
델타 공유의 고객 계정 ID입니다. | STRING |
workspace_id |
제공 엔드포인트의 고객 작업 영역 ID입니다. | STRING |
created_by |
크리에이터의 ID입니다. | STRING |
endpoint_name |
제공 엔드포인트의 이름입니다. | STRING |
endpoint_id |
제공 엔드포인트의 고유 ID입니다. | STRING |
served_entity_name |
제공된 엔터티의 이름입니다. | STRING |
entity_type |
제공되는 엔터티의 형식입니다. FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODEL 또는 CUSTOM_MODEL일 수 있습니다 |
STRING |
entity_name |
엔터티의 기본 이름입니다. 사용자가 제공한 이름인 served_entity_name과 다릅니다. 예를 들어 entity_name은 Unity 카탈로그 모델의 이름입니다. |
STRING |
entity_version |
제공된 엔터티의 버전입니다. | STRING |
endpoint_config_version |
엔드포인트 구성의 버전입니다. | INT |
task |
작업 종류입니다. llm/v1/chat, llm/v1/completions 또는 llm/v1/embeddings일 수 있습니다. |
STRING |
external_model_config |
외부 모델에 대한 구성입니다. 예를 들어 {Provider: OpenAI} |
STRUCT |
foundation_model_config |
기본 모델에 대한 구성입니다. 예를 들어{min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUCT |
custom_model_config |
사용자 지정 모델에 대한 구성입니다. 예: { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
기능 사양에 대한 구성입니다. 예를 들어 { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
제공된 엔터티에 대한 변경 타임스탬프입니다. | TIMESTAMP |
endpoint_delete_time |
엔터티 삭제 타임스탬프입니다. 엔드포인트는 제공된 엔터티에 대한 컨테이너입니다. 엔드포인트가 삭제되면 제공된 엔터티도 삭제됩니다. | TIMESTAMP |
system.serving.endpoint_usage 사용량 추적 시스템 테이블에는 다음 스키마가 있습니다.
| 열 이름 | 설명 | Type |
|---|---|---|
account_id |
고객 계정 ID. | STRING |
workspace_id |
제공 엔드포인트의 고객 작업 영역 ID입니다. | STRING |
client_request_id |
사용자가 요청 본문을 제공하는 모델에 지정할 수 있는 요청 식별자를 제공했습니다. | STRING |
databricks_request_id |
요청을 제공하는 모든 모델에 연결된 Azure Databricks 생성 요청 식별자입니다. | STRING |
requester |
서비스 엔드포인트의 호출 요청에 사용 권한이 사용되는 사용자 또는 서비스 주체의 ID입니다. | STRING |
status_code |
모델에서 반환된 HTTP 상태 코드입니다. | INTEGER |
request_time |
서버가 요청을 받은 타임스탬프. | TIMESTAMP |
input_token_count |
입력의 토큰 수입니다. | LONG |
output_token_count |
출력의 토큰 수입니다. | LONG |
input_character_count |
입력 문자열 또는 프롬프트의 문자 수입니다. | LONG |
output_character_count |
응답 출력 문자열의 문자 수입니다. | LONG |
usage_context |
엔드포인트를 호출하는 최종 사용자 또는 고객 애플리케이션의 식별자를 포함하는 맵을 사용자에게 제공했습니다. usage_context 사용한 추가 정의 사용을 참조하세요. | MAP |
request_streaming |
요청이 스트림 모드인지 여부입니다. | BOOLEAN |
served_entity_id |
차원 테이블과 조인하여 엔드포인트 및 제공된 엔터티에 대한 정보를 조회하기 위해 system.serving.served_entities 차원 테이블과 조인하는 데 사용되는 고유 ID입니다. |
STRING |
usage_context를 사용하여 사용량 정의
사용량 추적을 사용하도록 설정된 외부 모델을 쿼리할 때 usage_context 매개 변수에 Map[String, String] 형식을 제공할 수 있습니다. 사용 현황 컨텍스트 매핑은 usage_context 열의 사용량 추적 테이블에 표시됩니다. 지도 크기는 usage_context 10KiB를 초과할 수 없습니다.
계정 관리자는 사용 컨텍스트에 따라 다른 행을 집계하여 인사이트를 얻을 수 있으며 이 정보를 페이로드 로깅 테이블의 정보와 조인할 수 있습니다. 예를 들어 최종 사용자의 비용 특성 추적을 위해 end_user_to_charge을 usage_context에 추가할 수 있습니다.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
AI 게이트웨이 사용 유추 테이블 스키마
AI Gateway를 사용하여 사용하도록 설정된 유추 테이블에는 다음 스키마가 있습니다.
| 열 이름 | 설명 | Type |
|---|---|---|
request_date |
모델 제공 요청이 수신된 UTC 날짜입니다. | DATE |
databricks_request_id |
요청을 제공하는 모든 모델에 연결된 Azure Databricks 생성 요청 식별자입니다. | STRING |
client_request_id |
모델을 제공하는 요청 본문에서 지정할 수 있는 선택적 클라이언트 생성 요청 식별자입니다. | STRING |
request_time |
서버가 요청을 받은 타임스탬프. | TIMESTAMP |
status_code |
모델에서 반환된 HTTP 상태 코드입니다. | INT |
sampling_fraction |
요청이 다운샘플링된 경우에 사용되는 샘플링 추출률. 이 값은 0에서 1 사이입니다. 여기서 1은 수신 요청의 100%가 포함됨을 나타냅니다. | DOUBLE |
execution_duration_ms |
모델이 유추를 수행한 시간(밀리초)입니다. 여기에는 오버헤드 네트워크 대기 시간이 포함되지 않으며 모델이 예측을 생성하는 데 걸린 시간만 나타냅니다. | BIGINT |
request |
모델 제공 엔드포인트로 모델로 전송된 원시 요청 JSON 본문입니다. | STRING |
response |
모델 지원 엔드포인트에서 반환한 원시 응답 JSON 본문. | STRING |
served_entity_id |
제공된 엔터티의 고유 ID입니다. | STRING |
logging_error_codes |
ARRAY | |
requester |
서비스 엔드포인트의 호출 요청에 사용 권한이 사용되는 사용자 또는 서비스 주체의 ID입니다. | STRING |
엔드포인트에서 AI 게이트웨이 기능 업데이트
이전에 사용하도록 설정한 엔드포인트와 사용하지 않은 엔드포인트를 제공하는 모델에서 AI 게이트웨이 기능을 업데이트할 수 있습니다. AI 게이트웨이 구성에 대한 업데이트는 적용하는 데 약 20-40초가 걸리지만 속도 제한 업데이트에는 최대 60초가 걸릴 수 있습니다.
다음은 서비스 UI를 사용하여 엔드포인트를 제공하는 모델의 AI 게이트웨이 기능을 업데이트하는 방법을 보여 줍니다.
엔드포인트 페이지의 게이트웨이 섹션에서 사용하도록 설정된 기능을 확인할 수 있습니다. 이러한 기능을 업데이트하려면 AI 게이트웨이편집을 클릭합니다.

Notebook 예제
다음 Notebook에서는 프로그래밍 방식으로 Databricks Mosaic AI Gateway 기능을 사용하도록 설정하고 사용하여 공급자의 모델을 관리하고 관리하는 방법을 보여 줍니다. REST API 세부 정보는 다음을 참조하세요.