컴퓨팅 구성(레거시)
참고 항목
레거시 클러스터 만들기 UI에 대한 지침이며 기록 정확도에 대해서만 포함됩니다. 모든 고객은 업데이트된 클러스터 만들기 UI를 사용해야 합니다.
이 문서에서는 Azure Databricks 클러스터를 만들고 편집할 때 사용할 수 있는 구성 옵션에 대해 설명합니다. 여기서는 UI를 사용하여 클러스터를 만들고 편집하는 데 중점을 둡니다. 다른 방법은 Databricks CLI, 클러스터 API 및 Databricks Terraform 공급자를 참조하세요.
요구 사항에 가장 적합한 구성 옵션 조합을 결정하는 데 도움이 필요하면 클러스터 구성 모범 사례를 참조하세요.
클러스터 정책
클러스터 정책은 규칙 세트에 따라 클러스터를 구성하는 기능을 제한합니다. 정책 규칙은 클러스터를 만드는 데 사용할 수 있는 특성 또는 특성 값을 제한합니다. 클러스터 정책에는 특정 사용자 및 그룹에서 사용하도록 제한하는 ACL이 있습니다. 이를 통해 클러스터를 만들 때 선택할 수 있는 정책을 제한할 수 있습니다.
클러스터 정책을 구성하려면 정책 드롭다운에서 클러스터 정책을 선택합니다.
참고 항목
작업 영역에 만든 정책이 없으면 정책 드롭다운이 표시되지 않습니다.
다음과 같은 권한이 있는 경우:
- 클러스터 만들기 권한이 있는 경우 제한 없음 정책을 선택하고 완전히 구성 가능한 클러스터를 만들 수 있습니다. 제한 없음 정책은 클러스터 특성 또는 특성 값을 제한하지 않습니다.
- 클러스터 만들기 권한 및 클러스터 정책에 대한 액세스 권한이 모두 있는 경우 제한 없음 정책과 액세스할 수 있는 정책을 선택할 수 있습니다.
- 클러스터 정책에 대한 액세스 권한만 있는 경우 액세스할 수 있는 정책을 선택할 수 있습니다.
클러스터 모드
참고 항목
이 문서에서는 레거시 클러스터 UI에 대해 설명합니다. 새 클러스터 UI(미리 보기)에 대한 자세한 내용은 컴퓨팅 구성 참조를 참조하세요. 여기에는 클러스터 액세스 유형 및 모드에 대한 몇 가지 용어 변경이 포함됩니다. 새 클러스터 유형과 레거시 클러스터 유형을 비교하려면 클러스터 UI 변경 내용 및 클러스터 액세스 모드를 참조하세요. 미리 보기 UI에서:
- 이제 표준 모드 클러스터를 격리 공유 액세스 모드 클러스터라고 합니다.
- 테이블 ACL을 사용하는 높은 동시성을 이제 공유 액세스 모드 클러스터라고 합니다.
Azure Databricks는 표준, 높은 동시성 및 단일 노드의 세 가지 클러스터 모드를 지원합니다. 기본 클러스터 모드는 표준입니다.
Important
- 작업 영역이 Unity Catalog 메타스토어에 할당된 경우 높은 동시성 클러스터를 사용할 수 없습니다. 대신 액세스 모드를 사용하여 액세스 제어의 무결성을 보장하고 강력한 격리 보장을 적용합니다. 액세스 모드도 참조하세요.
- 클러스터가 만들어지면 클러스터 모드를 변경할 수 없습니다. 다른 클러스터 모드를 원하는 경우 새 클러스터를 만들어야 합니다.
클러스터 구성에는 기본값이 클러스터 모드에 따라 달라지는 자동 종료 설정이 포함됩니다.
- 표준 및 단일 노드 클러스터는 기본적으로 120분 후에 자동으로 종료됩니다.
- 높은 동시성 클러스터는 기본적으로 자동으로 종료되지 않습니다.
표준 클러스터
Warning
표준 모드 클러스터(격리 공유 클러스터 없음이라고도 함)는 사용자 간에 격리 없이 여러 사용자가 공유할 수 있습니다. 테이블 ACL 또는 자격 증명 통과와 같은 추가 보안 설정 없이 높은 동시성 클러스터 모드를 사용하는 경우 동일한 설정이 표준 모드 클러스터로 사용됩니다. 계정 관리자는 이러한 유형의 클러스터에서 Databricks 작업 영역 관리자에 대해 내부 자격 증명이 자동으로 생성되지 않도록 방지할 수 있습니다. 보다 안전한 옵션을 위해 Databricks는 테이블 ACL을 사용하는 높은 동시성 클러스터와 같은 대안을 권장합니다.
표준 클러스터는 단일 사용자에게만 권장됩니다. 표준 클러스터는 Python, SQL, R, Scala에서 개발된 워크로드를 실행할 수 있습니다.
높은 동시성 클러스터
높은 동시성 클러스터는 관리형 클라우드 리소스입니다. 높은 동시성 클러스터의 주요 이점은 리소스 사용률을 최대화하고 쿼리 대기 시간을 최소화하기 위해 세분화된 공유를 제공한다는 것입니다.
높은 동시성 클러스터는 SQL, Python, R에서 개발된 워크로드를 실행할 수 있습니다. 높은 동시성 클러스터의 성능 및 보안은 Scala에서 불가능한 별도의 프로세스에서 사용자 코드를 실행하여 제공됩니다.
또한 높은 동시성 클러스터만 테이블 액세스 제어를 지원합니다.
높은 동시성 클러스터를 만들려면 클러스터 모드를 높은 동시성으로 설정합니다.
단일 노드 클러스터
단일 노드 클러스터에는 작업자가 없으며 Spark 작업이 드라이버 노드에서 실행됩니다.
반면, 표준 클러스터에는 Spark 작업을 실행하기 위해 드라이버 노드 외에 하나 이상의 Spark 작업자 노드가 필요합니다.
단일 노드 클러스터를 만들려면 클러스터 모드를 단일 노드로 설정합니다.
단일 노드 클러스터 작업에 대한 자세한 내용은 단일 노드 또는 다중 노드 컴퓨팅을 참조 하세요.
풀
클러스터 시작 시간을 줄이기 위해 드라이버 및 작업자 노드에 대해 미리 정의된 유휴 인스턴스 풀에 클러스터를 연결할 수 있습니다. 클러스터는 풀의 인스턴스를 사용하여 만들어집니다. 풀에 요청된 드라이버 또는 작업자 노드를 만드는 데 충분한 유휴 리소스가 없는 경우 인스턴스 공급자에서 새 인스턴스를 할당하여 풀이 확장됩니다. 연결된 클러스터가 종료되면 사용된 인스턴스가 풀로 반환되고 다른 클러스터에서 다시 사용할 수 있습니다.
작업자 노드에 대한 풀을 선택하지만 드라이버 노드에 대해서는 선택하지 않는 경우 드라이버 노드는 작업자 노드 구성에서 풀을 상속합니다.
Important
작업자 노드가 아닌 드라이버 노드에 대한 풀을 선택하려고 하면 오류가 발생하고 클러스터가 만들어지지 않습니다. 이 요구 사항은 드라이버 노드에서 작업자 노드가 만들어질 때까지 기다려야 하거나 그 반대의 경우도 마찬가지인 상황을 방지합니다.
Azure Databricks에서 풀 작업에 대한 자세한 내용은 풀 구성 참조를 참조하세요.
Databricks Runtime
Databricks 런타임은 클러스터에서 실행되는 핵심 구성 요소 세트입니다. 모든 Databricks 런타임에는 Apache Spark가 포함되며, 유용성, 성능 및 보안을 향상시키는 구성 요소 및 업데이트가 추가됩니다. 자세한 내용은 Databricks 런타임 릴리스 정보 버전 및 호환성을 참조 하세요.
Azure Databricks는 클러스터를 만들거나 편집할 때 Databricks Runtime 버전 드롭다운에서 여러 유형의 런타임 및 이러한 런타임 유형의 여러 버전을 제공합니다.
Photon 가속
Photon은 Databricks Runtime 9.1 LTS 이상을 실행하는 클러스터에서 사용할 수 있습니다.
광자 가속을 사용하도록 설정하려면 광자 가속 사용 확인란을 선택합니다.
원하는 경우 작업자 유형 및 드라이버 유형 드롭다운에서 인스턴스 유형을 지정할 수 있습니다.
최적의 가격과 성능을 위해 Databricks에서 권장하는 인스턴스 유형은 다음과 같습니다.
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
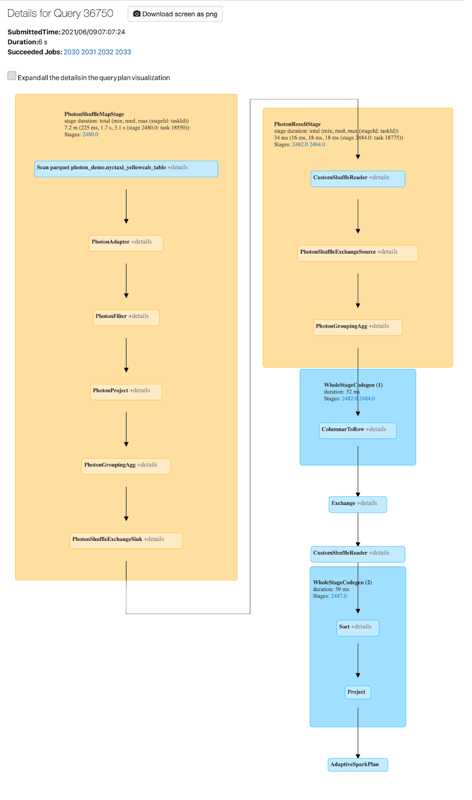
Photon 작업은 Spark UI에서 볼 수 있습니다. 다음 스크린샷에서는 쿼리 세부 정보 DAG를 보여 줍니다. DAG에는 Photon에 대한 두 가지 표시가 있습니다. 먼저 Photon 연산자는 "Photon"으로 시작합니다(예: PhotonGroupingAgg). 다음으로 DAG에서 Photon 연산자와 스테이지는 살구색이고 비 Photon 연산자는 파란색입니다.
Docker 이미지
일부 Databricks Runtime 버전의 경우 클러스터를 만들 때 Docker 이미지를 지정할 수 있습니다. 사용 사례의 예로 라이브러리 사용자 지정, 변경되지 않는 골든 컨테이너 환경 및 Docker CI/CD 통합이 있습니다.
또한 Docker 이미지를 사용하여 GPU 디바이스가 있는 클러스터에서 사용자 지정 딥 러닝 환경을 만들 수 있습니다.
지침은 GPU 컴퓨팅에서 Databricks Container Services 및 Databricks Container Services를 사용하여 컨테이너 사용자 지정을 참조하세요.
클러스터 노드 유형
클러스터는 하나의 드라이버 노드 및 0개 이상의 작업자 노드로 구성됩니다.
기본적으로 드라이버 노드에서 작업자 노드와 동일한 인스턴스 유형을 사용하지만, 드라이버 및 작업자 노드에 대해 별도의 클라우드 공급자 인스턴스 유형을 선택할 수 있습니다. 다양한 인스턴스 유형 제품군은 메모리 집약적 또는 컴퓨팅 집약적 워크로드와 같은 다양한 사용 사례에 적합합니다.
참고 항목
보안 요구 사항에 컴퓨팅 격리가 포함되는 경우 작업자 유형으로 Standard_F72s_V2 인스턴스를 선택합니다. 이러한 인스턴스 유형은 전체 물리적 호스트를 사용하고 예를 들어 워크로드(예: 미국 국방부 IL5(영향 수준 5) 워크로드)를 지원하는 데 필요한 격리 수준을 제공하는 격리된 가상 머신을 나타냅니다.
드라이버 노드
드라이버 노드는 클러스터에 연결된 모든 Notebook의 상태 정보를 유지 관리합니다. 또한 드라이버 노드는 SparkContext를 유지 관리하고, 클러스터의 Notebook 또는 라이브러리에서 실행하는 모든 명령을 해석하고, Spark 실행기와 조정되는 Apache Spark 마스터를 실행합니다.
드라이버 노드 유형의 기본값은 작업자 노드 유형과 동일합니다. Spark 작업자에서 많은 데이터를 수집하고(collect()) 이를 Notebook에서 분석하려는 경우 더 많은 메모리가 있는 더 큰 드라이버 노드 유형을 선택할 수 있습니다.
팁
드라이버 노드는 연결된 Notebook의 모든 상태 정보를 유지 관리하므로 드라이버 노드에서 사용하지 않는 Notebook을 분리해야 합니다.
작업자 노드
Azure Databricks 작업자 노드는 클러스터가 적절하게 작동하는 데 필요한 Spark 실행기 및 기타 서비스를 실행합니다. Spark를 사용하여 워크로드를 배포하면 모든 분산 처리가 작업자 노드에서 수행됩니다. Azure Databricks는 작업자 노드당 하나의 실행기를 실행합니다. 따라서 실행기 및 작업자라는 용어는 Azure Databricks 아키텍처의 컨텍스트에서 서로 바꿔서 사용됩니다.
팁
Spark 작업을 실행하려면 하나 이상의 작업자 노드가 필요합니다. 클러스터에 작업자가 없는 경우 드라이버 노드에서 비 Spark 명령을 실행할 수 있지만 Spark 명령은 실패합니다.
GPU 인스턴스 유형
딥 러닝과 관련된 작업과 같이 고성능을 요구하는 계산적으로 까다로운 작업의 경우 Azure Databricks는 GPU(그래픽 처리 장치)로 가속화되는 클러스터를 지원합니다. 자세한 내용은 GPU 사용 컴퓨팅을 참조하세요.
스폿 인스턴스
비용을 절약하기 위해 스폿 인스턴스 확인란을 선택하여 Azure 스폿 VM이라고도 하는 스폿 인스턴스를 사용하도록 선택할 수 있습니다.

첫 번째 인스턴스는 항상 주문형이고(드라이버 노드가 항상 주문형) 후속 인스턴스는 스폿 인스턴스가 됩니다. 사용 불가로 인해 스폿 인스턴스가 제거되는 경우 제거된 인스턴스를 대체하기 위해 주문형 인스턴스가 배포됩니다.
클러스터 크기 및 자동 스케일링
Azure Databricks 클러스터를 만들 때 클러스터에 고정된 수의 작업자를 제공하거나 클러스터에 대한 최소 및 최대 작업자 수를 제공할 수 있습니다.
고정 크기 클러스터를 제공하는 경우 Azure Databricks에서 클러스터에 지정된 수의 작업자가 있는지 확인합니다. 작업자 수에 대한 범위를 제공하는 경우 Databricks에서 작업을 실행하는 데 필요한 적절한 작업자 수를 선택합니다. 이를 자동 크기 조정이라고 합니다.
자동 크기 조정을 사용하면 Azure Databricks에서 작업 특성을 고려하여 작업자를 동적으로 다시 할당합니다. 파이프라인의 특정 부분은 다른 부분보다 더 많은 계산을 요구할 수 있으며, Databricks는 이러한 작업 단계에서 추가 작업자를 자동으로 추가하고 더 이상 필요하지 않은 경우 제거합니다.
자동 크기 조정 기능을 사용하면 클러스터 사용률을 더 쉽게 높일 수 있습니다. 워크로드와 일치하는 클러스터를 프로비전할 필요가 없기 때문입니다. 특히 이는 시간이 지남에 따라 요구 사항이 변경되는 워크로드(예: 하루 중 데이터 세트 검색)에 적용되지만 프로비전 요구 사항을 알 수 없는 짧은 일회성 워크로드에도 적용될 수 있습니다. 따라서 자동 크기 조정에서 제공하는 두 가지 이점은 다음과 같습니다.
- 워크로드는 일정한 크기의 과소 프로비전된 클러스터에 비해 더 빠르게 실행할 수 있습니다.
- 자동 크기 조정 클러스터는 정적 크기의 클러스터에 비해 전체 비용을 줄일 수 있습니다.
클러스터 및 워크로드의 일정한 크기에 따라 자동 크기 조정은 이러한 이점 중 하나 또는 둘 다를 동시에 제공합니다. 클러스터 크기는 클라우드 공급자가 인스턴스를 종료할 때 선택한 최소 작업자 수 미만으로 낮아질 수 있습니다. 이 경우 Azure Databricks는 최소 작업자 수를 유지하기 위해 인스턴스를 다시 프로비전하려고 지속적으로 다시 시도합니다.
참고 항목
자동 크기 조정은 spark-submit 작업에 사용할 수 없습니다.
자동 크기 조정 동작 방법
- 최소에서 최대로 2단계로 스케일 업합니다
- 클러스터가 유휴 상태가 아닌 경우에도 순서 섞기 파일 상태를 확인하여 스케일 다운할 수 있습니다.
- 현재 노드의 백분율에 따라 스케일 다운합니다.
- 작업 클러스터에서 클러스터가 지난 40초 동안 미달 사용되면 스케일 다운합니다.
- 다목적 클러스터에서 클러스터가 지난 150초 동안 미달 사용되면 스케일 다운합니다.
spark.databricks.aggressiveWindowDownSSpark 구성 속성은 클러스터에서 스케일 다운을 결정하는 빈도를 초 단위로 지정합니다. 값을 늘리면 클러스터가 더 느리게 스케일 다운합니다. 최댓값은 600입니다.
자동 크기 조정 사용 및 구성
Azure Databricks에서 클러스터 크기를 자동으로 조정할 수 있도록 하려면 자동 크기 조정을 클러스터에 사용하도록 설정하고 최소 및 최대 작업자 범위를 제공합니다.
자동 크기 조정을 사용합니다.
다목적 클러스터 - [클러스터 만들기] 페이지의 Autopilot 옵션 상자에서 자동 크기 조정 사용 확인란을 선택합니다.

작업 클러스터 - [클러스터 구성] 페이지의 Autopilot 옵션 상자에서 자동 크기 조정 사용 확인란을 선택합니다.

최소 및 최대 작업자 수를 구성합니다.

클러스터가 실행되면 클러스터 세부 정보 페이지에 할당된 작업자 수가 표시됩니다. 할당된 작업자 수를 작업자 구성과 비교하고 필요에 따라 조정할 수 있습니다.
Important
인스턴스 풀을 사용하는 경우 다음을 수행합니다.
- 요청된 클러스터 크기가 풀의 최소 유휴 인스턴스 수보다 작거나 같은지 확인합니다. 더 크면 클러스터 시작 시간은 풀을 사용하지 않는 클러스터와 동일합니다.
- 최대 클러스터 크기가 풀의 최대 용량보다 작거나 같은지 확인합니다. 더 크면 클러스터 만들기가 실패합니다.
자동 크기 조정 예
정적 클러스터를 자동 크기 조정 클러스터로 다시 구성하면 Azure Databricks에서 클러스터 크기를 최소 및 최대 범위 내에서 즉시 조정한 다음, 자동 크기 조정을 시작합니다. 예를 들어 다음 표에서는 5~10개 노드 간에 자동 크기 조정하도록 클러스터를 다시 구성하는 경우 특정 초기 크기의 클러스터에서 수행되는 상황을 보여 줍니다.
| 처음 크기 | 재구성 후 크기 |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
로컬 스토리지 자동 크기 조정
특정 작업에 필요한 디스크 공간을 예측하기 어려울 수 있는 경우가 많습니다. 만들 때 클러스터에 연결할 관리 디스크의 기가바이트 수를 예측할 필요가 없도록 Azure Databricks는 자동으로 모든 Azure Databricks 클러스터에서 로컬 스토리지의 자동 크기 조정을 사용하도록 설정합니다.
로컬 스토리지 자동 크기 조정을 사용하면 Azure Databricks에서 클러스터의 Spark 작업자에서 사용할 수 있는 디스크 여유 공간의 양을 모니터링합니다. 작업자가 디스크에서 너무 느리게 실행되기 시작하면 Databricks에서 디스크 공간이 부족하기 전에 새 관리 디스크를 작업자에 자동으로 연결합니다. 디스크는 가상 머신의 초기 로컬 저장소를 포함하여 가상 머신당 총 디스크 공간의 최대 5TB까지 연결됩니다.
가상 머신이 Azure로 반환되는 경우에만 가상 머신에 연결된 관리 디스크가 분리됩니다. 즉, 관리 디스크는 실행되는 클러스터의 일부인 경우 가상 머신에서 분리되지 않습니다. 관리 디스크 사용량을 축소하기 위해 Azure Databricks는 클러스터 크기 및 자동 크기 조정 또는 예기치 않은 종료로 구성된 클러스터에서 이 기능을 사용하는 것이 좋습니다.
로컬 디스크 암호화
Important
이 기능은 공개 미리 보기 상태입니다.
클러스터를 실행하는 데 사용하는 일부 인스턴스 유형에는 로컬로 연결된 디스크가 있을 수 있습니다. Azure Databricks는 순서 섞기 데이터 또는 임시 데이터를 이러한 로컬로 연결된 디스크에 저장할 수 있습니다. 클러스터의 로컬 디스크에 임시로 저장된 순서 섞기 데이터를 포함하여 모든 스토리지 유형에 대해 모든 미사용 데이터가 암호화되도록 하려면 로컬 디스크 암호화를 사용하도록 설정할 수 있습니다.
Important
로컬 볼륨에서 암호화된 데이터 읽기 및 쓰기의 성능 영향으로 인해 워크로드가 더 느리게 실행될 수 있습니다.
로컬 디스크 암호화를 사용하도록 설정하면 Azure Databricks에서 각 클러스터 노드에 고유하고 로컬 디스크에 저장된 모든 데이터를 암호화하는 데 사용되는 암호화 키를 로컬로 생성합니다. 키의 범위는 각 클러스터 노드로 한정되며 클러스터 노드 자체와 함께 제거됩니다. 수명 동안 키는 암호화 및 암호 해독을 위해 메모리에 상주하며 암호화된 상태로 디스크에 저장됩니다.
로컬 디스크 암호화를 사용하려면 클러스터 API를 사용해야 합니다. 클러스터를 만들거나 편집하는 동안 다음과 같이 설정합니다.
{
"enable_local_disk_encryption": true
}
이러한 API를 호출하는 방법에 대한 예제는 클러스터 API를 참조하세요.
로컬 디스크 암호화를 사용하도록 설정하는 클러스터 만들기 호출의 예제는 다음과 같습니다.
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
보안 모드
작업 영역이 Unity Catalog 메타스토어에 할당된 경우 높은 동시성 클러스터 모드 대신 보안 모드를 사용하여 액세스 제어의 무결성을 보장하고 강력한 격리 보장을 적용합니다. Unity 카탈로그에서는 높은 동시성 클러스터 모드를 사용할 수 없습니다.
고급 옵션에서 다음 클러스터 보안 모드 중에서 선택합니다.
- 없음: 격리 없음. workspace-local 테이블 액세스 제어 또는 자격 증명 통과를 적용하지 않습니다. Unity 카탈로그 데이터에 액세스할 수 없습니다.
- 단일 사용자: 단일 사용자(기본적으로 클러스터를 만든 사용자)만 사용할 수 있습니다. 다른 사용자는 클러스터에 연결할 수 없습니다. 단일 사용자 보안 모드를 사용하여 클러스터에서 보기에 액세스할 때 보기는 사용자의 권한으로 실행됩니다. 단일 사용자 클러스터는 Python, Scala 및 R을 사용하여 워크로드를 지원합니다. Init 스크립트, 라이브러리 설치 및 DBFS 탑재는 단일 사용자 클러스터에서 지원됩니다. 자동화된 작업은 단일 사용자 클러스터를 사용해야 합니다.
- 사용자 격리: 여러 사용자가 공유할 수 있습니다. SQL 워크로드만 지원됩니다. 라이브러리 설치, init 스크립트, DBFS 탑재는 클러스터 사용자 간에 엄격한 격리를 적용하기 위해 사용하지 않도록 설정됩니다.
- 테이블 ACL만(레거시): workspace-local 테이블 액세스 제어를 적용하지만 Unity 카탈로그 데이터에 액세스할 수 없습니다.
- 통과만(레거시): workspace-local 자격 증명 통과를 적용하지만 Unity 카탈로그 데이터에 액세스할 수 없습니다.
Unity 카탈로그 워크로드를 지원하는 유일한 보안 모드는 단일 사용자 및 사용자 격리입니다.
자세한 내용은 액세스 모델을 참조하세요.
Spark 구성
Spark 작업을 미세 조정하려면 클러스터 구성에서 사용자 지정 Spark 구성 속성을 제공할 수 있습니다.
클러스터 구성 페이지에서 고급 옵션 토글을 클릭합니다.
Spark 탭을 클릭합니다.
Spark 구성에서 구성 속성을 줄당 하나의 키-값 쌍으로 입력합니다.
클러스터 API를 사용하여 클러스터를 구성하는 경우 새 클러스터 만들기 API 또는 업데이트 클러스터 구성 API의 필드에서 Spark 속성을 spark_conf 설정합니다.
Databricks는 전역 init 스크립트를 사용하지 않는 것이 좋습니다.
모든 클러스터에 대한 Spark 속성을 설정하려면 글로벌 init 스크립트를 만듭니다.
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
비밀에서 Spark 구성 속성 검색
Databricks는 암호와 같은 중요한 정보를 일반 텍스트 대신 비밀로 저장하도록 권장합니다. Spark 구성에서 비밀을 참조하려면 다음 구문을 사용합니다.
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
예를 들어 다음과 같이 password라는 Spark 구성 속성을 secrets/acme_app/password에 저장된 비밀 값으로 설정합니다.
spark.password {{secrets/acme-app/password}}
자세한 내용은 비밀 관리를 참조 하세요.
환경 변수
클러스터에서 실행되는 init 스크립트에서 액세스할 수 있는 사용자 지정 환경 변수를 구성할 수 있습니다. Databricks는 또한 init 스크립트에서 사용할 수 있는 미리 정의된 환경 변수를 제공합니다. 이러한 미리 정의된 환경 변수는 재정의할 수 없습니다.
클러스터 구성 페이지에서 고급 옵션 토글을 클릭합니다.
Spark 탭을 클릭합니다.
환경 변수 필드에서 환경 변수를 설정합니다.
새 클러스터 만들기 API 또는 업데이트 클러스터 구성 API의 필드를 사용하여 spark_env_vars 환경 변수를 설정할 수도 있습니다.
클러스터 태그
클러스터 태그를 사용하면 조직의 다양한 그룹에서 사용하는 클라우드 리소스의 비용을 쉽게 모니터링할 수 있습니다. 클러스터를 만들 때 태그를 키-값 쌍으로 지정할 수 있으며, Azure Databricks는 이러한 태그를 VM 및 디스크 볼륨과 같은 클라우드 리소스와 DBU 사용 현황 보고서에 적용합니다.
풀에서 시작된 클러스터의 경우 사용자 지정 클러스터 태그는 DBU 사용 현황 보고서에만 적용되며 클라우드 리소스에 전파되지 않습니다.
풀 및 클러스터 태그 유형이 함께 작동하는 방법에 대한 자세한 내용은 태그를 사용하여 사용 모니터링을 참조 하세요.
편의를 위해 Azure Databricks는 Vendor, Creator, ClusterName 및 ClusterId의 4가지 기본 태그를 각 클러스터에 적용합니다.
또한 작업 클러스터에서 Azure Databricks는 RunName 및 JobId의 두 가지 기본 태그를 적용합니다.
Databricks SQL에서 사용하는 리소스에서 Azure Databricks는 SqlWarehouseId 기본 태그도 적용합니다.
Warning
Name 키가 있는 사용자 지정 태그를 클러스터에 할당하지 마세요. 모든 클러스터에는 Azure Databricks에서 값을 설정하는 Name 태그가 있습니다. Name 키와 연결된 값을 변경하면 Azure Databricks에서 클러스터를 더 이상 추적할 수 없습니다. 따라서 유휴 상태가 되면 클러스터가 종료되지 않을 수 있으며 사용 비용이 계속 발생합니다.
사용자 지정 태그는 클러스터를 만들 때 추가할 수 있습니다. 클러스터 태그를 구성하려면 다음을 수행합니다.
클러스터 구성 페이지에서 고급 옵션 토글을 클릭합니다.
페이지 아래쪽에서 태그 탭을 클릭합니다.

각 사용자 지정 태그에 대한 키-값 쌍을 추가합니다. 최대 43개의 사용자 지정 태그를 추가할 수 있습니다.
클러스터에 대한 SSH 액세스
보안상의 이유로 Azure Databricks에서 SSH 포트는 기본적으로 닫힙니다. Spark 클러스터에 대한 SSH 액세스를 사용하도록 설정하려면 Azure Databricks 지원에 문의하세요.
참고 항목
작업 영역이 사용자 고유의 Azure 가상 네트워크에 배포되는 경우에만 SSH를 사용하도록 설정할 수 있습니다.
클러스터 로그 전달
클러스터를 만들 때 Spark 드라이버 노드, 작업자 노드 및 이벤트에 대한 로그를 전달할 위치를 지정할 수 있습니다. 로그는 5분마다 선택한 대상에 전달됩니다. 클러스터가 종료되면 Azure Databricks에서 클러스터가 종료될 때까지 생성된 모든 로그를 전달하도록 보장합니다.
로그의 대상은 클러스터 ID에 따라 달라집니다. 지정된 대상이 dbfs:/cluster-log-delivery이면 0630-191345-leap375에 대한 클러스터 로그가 dbfs:/cluster-log-delivery/0630-191345-leap375에 전달됩니다.
로그 전달 위치를 구성하려면 다음을 수행합니다.
클러스터 구성 페이지에서 고급 옵션 토글을 클릭합니다.
로깅 탭을 클릭합니다.
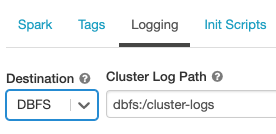
대상 유형을 선택합니다.
클러스터 로그 경로를 입력합니다.
참고 항목
이 기능은 REST API에서도 사용할 수 있습니다. 클러스터 API를 참조하세요.
Init 스크립트
클러스터 노드 초기화(또는 init) 스크립트는 Spark 드라이버 또는 작업자 JVM이 시작되기 전에 각 클러스터 노드를 시작하는 동안 실행되는 셸 스크립트입니다. init 스크립트를 사용하여 Databricks 런타임에 포함되지 않은 패키지 및 라이브러리를 설치하거나, JVM 시스템 클래스 경로를 수정하거나, JVM에서 사용하는 시스템 속성 및 환경 변수를 설정하거나, 다른 구성 작업 중에서 Spark 구성 매개 변수를 수정할 수 있습니다.
init 스크립트는 고급 옵션 섹션을 펼치고 init 스크립트 탭을 클릭하여 클러스터에 연결할 수 있습니다.
자세한 지침은 init 스크립트란?을 참조하세요.