단일 사용자 컴퓨팅에 대한 세분화된 액세스 제어
이 문서에서는 단일 사용자 컴퓨팅에서 실행되는 쿼리(모든 용도 또는 단일 사용자 액세스 모드로 구성된 작업 컴퓨팅)에서 세분화된 액세스 제어를 가능하게 하는 데이터 필터링 기능을 소개합니다. 액세스 모드를 참조하세요.
이 데이터 필터링은 서버리스 컴퓨팅을 사용하여 백그라운드에서 수행됩니다.
단일 사용자 컴퓨팅에 대한 일부 쿼리에 데이터 필터링이 필요한 이유는 무엇인가요?
Unity 카탈로그를 사용하면 다음 기능을 사용하여 열 및 행 수준(세분화된 액세스 제어라고도 함)에서 테이블 형식 데이터에 대한 액세스를 제어할 수 있습니다.
참조된 테이블 또는 필터 및 마스크를 적용하는 쿼리 테이블에서 데이터를 제외하는 뷰를 쿼리하는 사용자는 다음 컴퓨팅 리소스를 제한 없이 사용할 수 있습니다.
- SQL Warehosue
- 공유 컴퓨팅
그러나 단일 사용자 컴퓨팅을 사용하여 이러한 쿼리를 실행하는 경우 컴퓨팅 및 작업 영역이 특정 요구 사항을 충족해야 합니다.
단일 사용자 컴퓨팅 리소스는 Databricks Runtime 15.4 LTS 이상에 있어야 합니다.
작업, Notebook 및 Delta Live Tables에 대해 서버리스 컴퓨팅에 대해 작업 영역을 사용하도록 설정해야 합니다.
작업 영역 지역에서 서버리스 컴퓨팅을 지원하는지 확인하려면 지역 가용성이 제한된 기능을 참조 하세요.
단일 사용자 컴퓨팅 리소스 및 작업 영역이 이러한 요구 사항을 충족하는 경우 세분화된 액세스 제어를 사용하는 뷰 또는 테이블을 쿼리할 때마다 데이터 필터링이 자동으로 실행됩니다.
구체화된 뷰, 스트리밍 테이블 및 표준 뷰 지원
동적 보기, 행 필터 및 열 마스크 외에도 데이터 필터링을 사용하면 Databricks Runtime 15.3 이하를 실행하는 단일 사용자 컴퓨팅에서 지원되지 않는 다음 보기 및 테이블에 대한 쿼리를 사용할 수 있습니다.
-
Databricks Runtime 15.3 이하를 실행하는 단일 사용자 컴퓨팅에서 뷰에서 쿼리를 실행하는 사용자는 뷰에서 참조하는 테이블 및 뷰에 있어야 합니다
SELECT. 즉, 뷰를 사용하여 세분화된 액세스 제어를 제공할 수 없습니다. 데이터 필터링을 사용하는 Databricks Runtime 15.4에서 뷰를 쿼리하는 사용자는 참조된 테이블 및 뷰에 액세스할 필요가 없습니다.
단일 사용자 컴퓨팅에서 데이터 필터링은 어떻게 작동하나요?
쿼리가 다음 데이터베이스 개체에 액세스할 때마다 단일 사용자 컴퓨팅 리소스는 서버리스 컴퓨팅에 쿼리를 전달하여 데이터 필터링을 수행합니다.
- 사용자에게 권한이 없는
SELECT테이블을 통해 빌드된 뷰 - 동적 보기
- 행 필터 또는 열 마스크가 정의된 테이블
- 구체화된 뷰 및 스트리밍 테이블
다음 다이어그램에서 사용자는 SELECT table_1view_2행 필터가 적용된 , 및 table_w_rls를 사용합니다. 에 의해 참조되는 사용자가 없습니다 SELECT table_2.view_2

쿼리 table_1 는 필터링이 필요하지 않으므로 단일 사용자 컴퓨팅 리소스에 의해 완전히 처리됩니다. 쿼리를 수행하고 view_2 table_w_rls 사용자가 액세스할 수 있는 데이터를 반환하려면 데이터 필터링이 필요합니다. 이러한 쿼리는 서버리스 컴퓨팅의 데이터 필터링 기능에 의해 처리됩니다.
어떤 비용이 발생합니까?
고객에게는 데이터 필터링 작업을 수행하는 데 사용되는 서버리스 컴퓨팅 리소스에 대한 요금이 청구됩니다. 가격 책정 정보는 플랫폼 계층 및 추가 기능을 참조 하세요.
시스템 청구 사용 현황 테이블을 쿼리하여 청구된 요금을 확인할 수 있습니다. 예를 들어 다음 쿼리는 사용자별 컴퓨팅 비용을 분류합니다.
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
데이터 필터링이 사용 중일 때 쿼리 성능 보기
단일 사용자 컴퓨팅용 Spark UI는 쿼리의 성능을 이해하는 데 사용할 수 있는 메트릭을 표시합니다. 컴퓨팅 리소스 에서 실행하는 각 쿼리에 대해 SQL/데이터 프레임 탭에 쿼리 그래프 표현이 표시됩니다. 쿼리가 데이터 필터링에 관련된 경우 UI는 그래프 아래쪽에 RemoteSparkConnectScan 연산자 노드를 표시합니다. 이 노드는 쿼리 성능을 조사하는 데 사용할 수 있는 메트릭을 표시합니다. Apache Spark UI에서 컴퓨팅 정보 보기를 참조하세요.
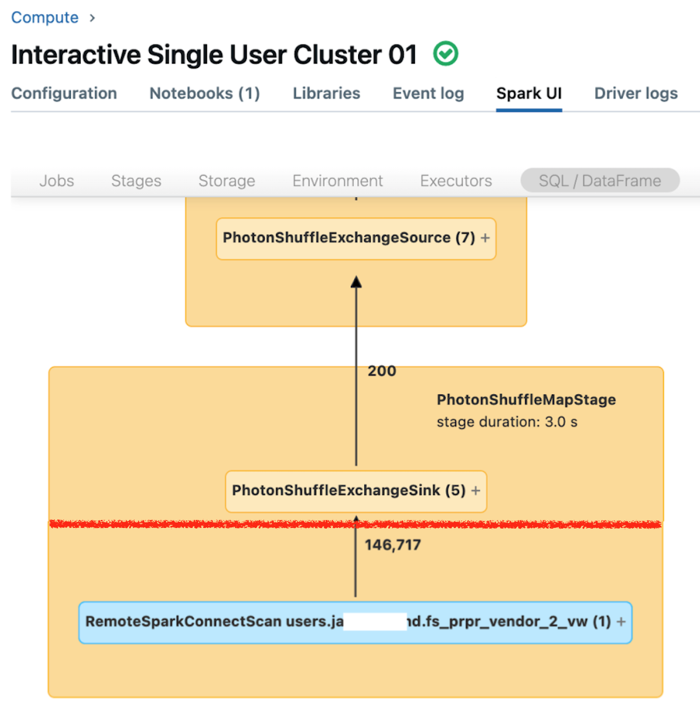
RemoteSparkConnectScan 연산자 노드를 확장하여 다음과 같은 질문을 해결하는 메트릭을 확인합니다.
- 데이터 필터링에 얼마나 많은 시간이 소요되나요? "총 원격 실행 시간"을 봅니다.
- 데이터 필터링 후 남은 행은 몇 개입니까? "행 출력"을 봅니다.
- 데이터 필터링 후 반환된 데이터(바이트)는 얼마나 되나요? "행 출력 크기"를 봅니다.
- 파티션 정리를 수행하고 스토리지에서 읽을 필요가 없는 데이터 파일은 몇 개입니까? "정리된 파일" 및 "정리된 파일 크기"를 봅니다.
- 얼마나 많은 데이터 파일을 정리할 수 없었고 스토리지에서 읽어야 했나요? "파일 읽기" 및 "읽은 파일 크기"를 봅니다.
- 읽어야 하는 파일 중 캐시에 이미 있는 파일 수는 몇 개입니까? "캐시 적수 크기" 및 "캐시 누락 크기"를 봅니다.
제한 사항
행 필터 또는 열 마스크가 적용된 테이블에서는 테이블 쓰기 또는 새로 고침 작업이 지원되지 않습니다.
특히 DML 작업(예:
INSERT,DELETE,UPDATEREFRESH TABLE및MERGE)은 지원되지 않습니다. 이러한 테이블에서만 (SELECT) 읽을 수 있습니다.자체 조인은 데이터 필터링이 호출될 때 기본적으로 차단되지만 이러한 명령을 실행하는 컴퓨팅에서 false로 설정
spark.databricks.remoteFiltering.blockSelfJoins하여 허용할 수 있습니다.단일 사용자 컴퓨팅 리소스에서 자체 조인을 사용하도록 설정하기 전에 데이터 필터링 기능에서 처리하는 자체 조인 쿼리가 동일한 원격 테이블의 다른 스냅샷을 반환할 수 있다는 점에 유의하세요.