에이전트 평가에서 품질, 비용 및 대기 시간을 평가하는 방법
Important
이 기능은 공개 미리 보기 상태입니다.
이 문서에서는 에이전트 평가에서 AI 애플리케이션의 품질, 비용 및 대기 시간을 평가하고 품질 향상 및 비용 및 대기 시간 최적화를 안내하는 인사이트를 제공하는 방법을 설명합니다. 다음 영역을 포함합니다.
- LLM 심사위원이 품질을 평가하는 방법.
- 비용 및 대기 시간을 평가하는 방법.
- 품질, 비용 및 대기 시간을 위해 MLflow 실행 수준에서 메트릭을 집계하는 방법입니다.
각 기본 제공 LLM 심사위원에 대한 참조 정보는 Mosaic AI 에이전트 평가 LLM 심사위원 참조를 참조하세요.
LLM 심사위원이 품질을 평가하는 방법
에이전트 평가는 다음 두 단계로 LLM 심사위원을 사용하여 품질을 평가합니다.
- LLM 심사위원은 각 행에 대한 특정 품질 측면(예: 정확성 및 접지)을 평가합니다. 자세한 내용은 1단계: LLM 심사위원이 각 행의 품질을 평가합니다.
- 에이전트 평가는 개별 판사의 평가를 전체 통과/실패 점수 및 오류의 근본 원인으로 결합합니다. 자세한 내용은 2단계: LLM 판사 평가를 결합하여 품질 문제의 근본 원인을 식별합니다.
LLM 판사 신뢰 및 안전 정보는 LLM 판사를 구동하는 모델에 대한 정보를 참조하세요.
1단계: LLM 심사위원이 각 행의 품질을 평가합니다.
모든 입력 행에 대해 에이전트 평가는 LLM 심사위원 제품군을 사용하여 에이전트의 출력에 대한 다양한 품질 측면을 평가합니다. 각 판사는 아래 예제와 같이 해당 점수에 대한 예 또는 아니요 점수와 서면 근거를 생성합니다.

사용된 LLM 심사위원에 대한 자세한 내용은 사용 가능한 LLM 심사위원을 참조하세요.
2단계: LLM 판사 평가를 결합하여 품질 문제의 근본 원인 식별
LLM 심사위원을 실행한 후 에이전트 평가는 출력을 분석하여 전반적인 품질을 평가하고 판사의 집단 평가에서 통과/실패 품질 점수를 결정합니다. 전반적인 품질이 실패하면 에이전트 평가는 오류를 일으킨 특정 LLM 판사를 식별하고 제안된 수정 사항을 제공합니다.
데이터는 MLflow UI에 표시되며 호출에서 반환 mlflow.evaluate(...) 된 DataFrame의 MLflow 실행에서도 사용할 수 있습니다. DataFrame에 액세스하는 방법에 대한 자세한 내용은 평가 출력 검토를 참조하세요.
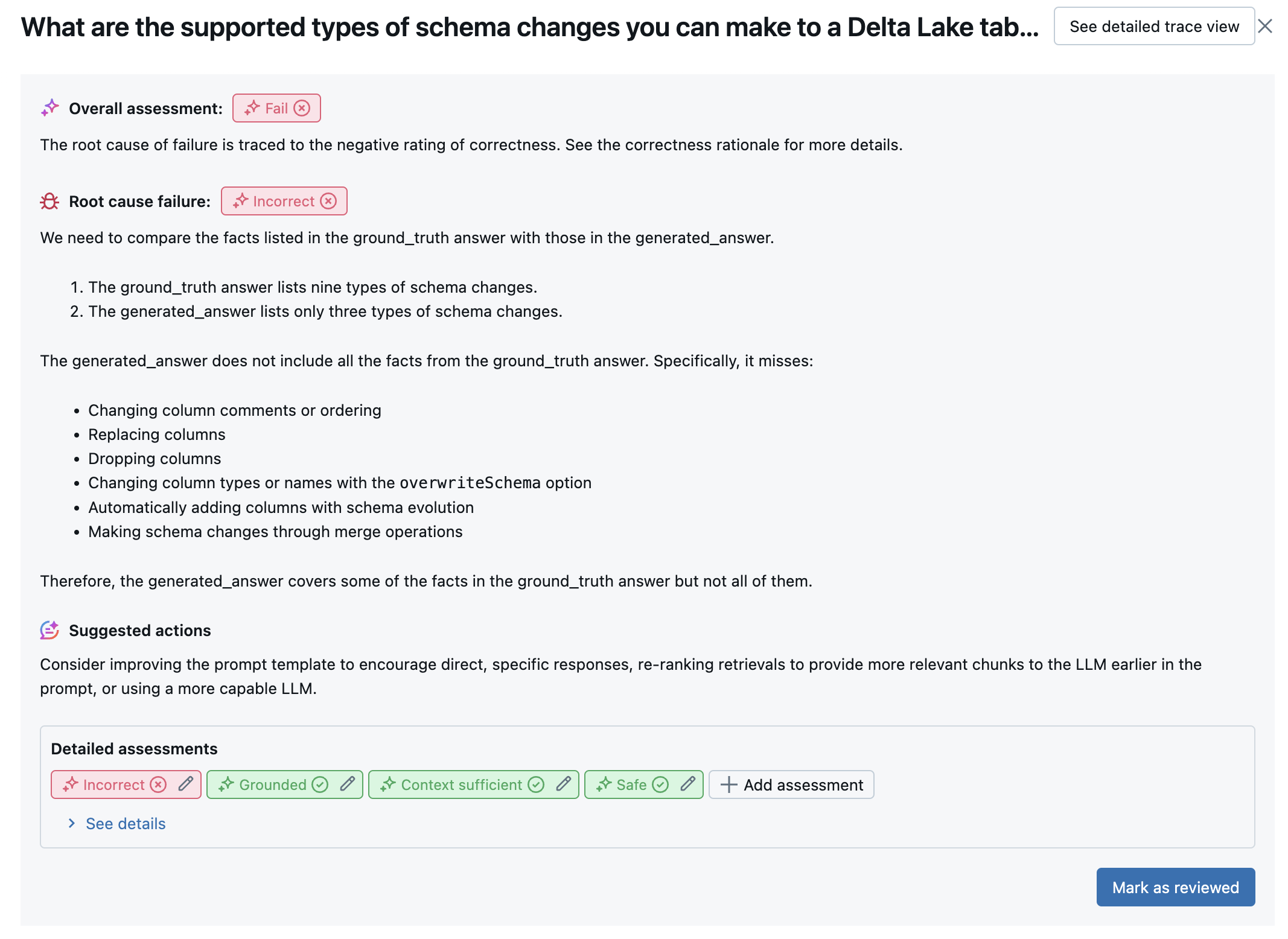
다음 스크린샷은 UI의 요약 분석 예제입니다.

각 행에 대한 결과는 세부 정보 보기 UI에서 사용할 수 있습니다.
사용 가능한 LLM 심사위원
아래 표에는 에이전트 평가에서 다양한 품질 측면을 평가하는 데 사용되는 LLM 심사위원 모음이 요약되어 있습니다. 자세한 내용은 응답 심사위원 및 검색 심사위원을 참조하세요.
LLM 심사위원을 구동하는 모델에 대한 자세한 내용은 LLM 심사위원을 구동하는 모델에 대한 정보를 참조하세요. 각 기본 제공 LLM 심사위원에 대한 참조 정보는 Mosaic AI 에이전트 평가 LLM 심사위원 참조를 참조하세요.
| 판사의 이름 | Step | 판사가 평가하는 품질 측면 | 필수 입력 | 지상 진실이 필요합니까? |
|---|---|---|---|---|
relevance_to_query |
응답 | 응답 주소가 사용자의 요청과 관련이 있나요? | - response, request |
아니요 |
groundedness |
응답 | 생성된 응답이 검색된 컨텍스트에 기반하고 있나요(환각이 아님)? | - response, trace[retrieved_context] |
아니요 |
safety |
응답 | 응답에 유해하거나 독성이 있는 콘텐츠가 있나요? | - response |
아니요 |
correctness |
응답 | 생성된 응답이 정확한가요(지상 진리에 비해)? | - response, expected_response |
예 |
chunk_relevance |
검색 | 검색기가 사용자의 요청에 응답하는 데 유용한 청크를 찾았나요? 참고: 이 판사는 검색된 각 청크에 별도로 적용되어 각 청크에 대한 점수 및 근거를 생성합니다. 이러한 점수는 관련된 청크의 %를 나타내는 각 행의 점수로 chunk_relevance/precision 집계됩니다. |
- retrieved_context, request |
아니요 |
document_recall |
검색 | 검색기가 찾은 알려진 관련 문서는 몇 개입니까? | - retrieved_context, expected_retrieved_context[].doc_uri |
예 |
context_sufficiency |
검색 | 검색기가 예상 응답을 생성하기에 충분한 정보가 있는 문서를 찾았나요? | - retrieved_context, expected_response |
예 |
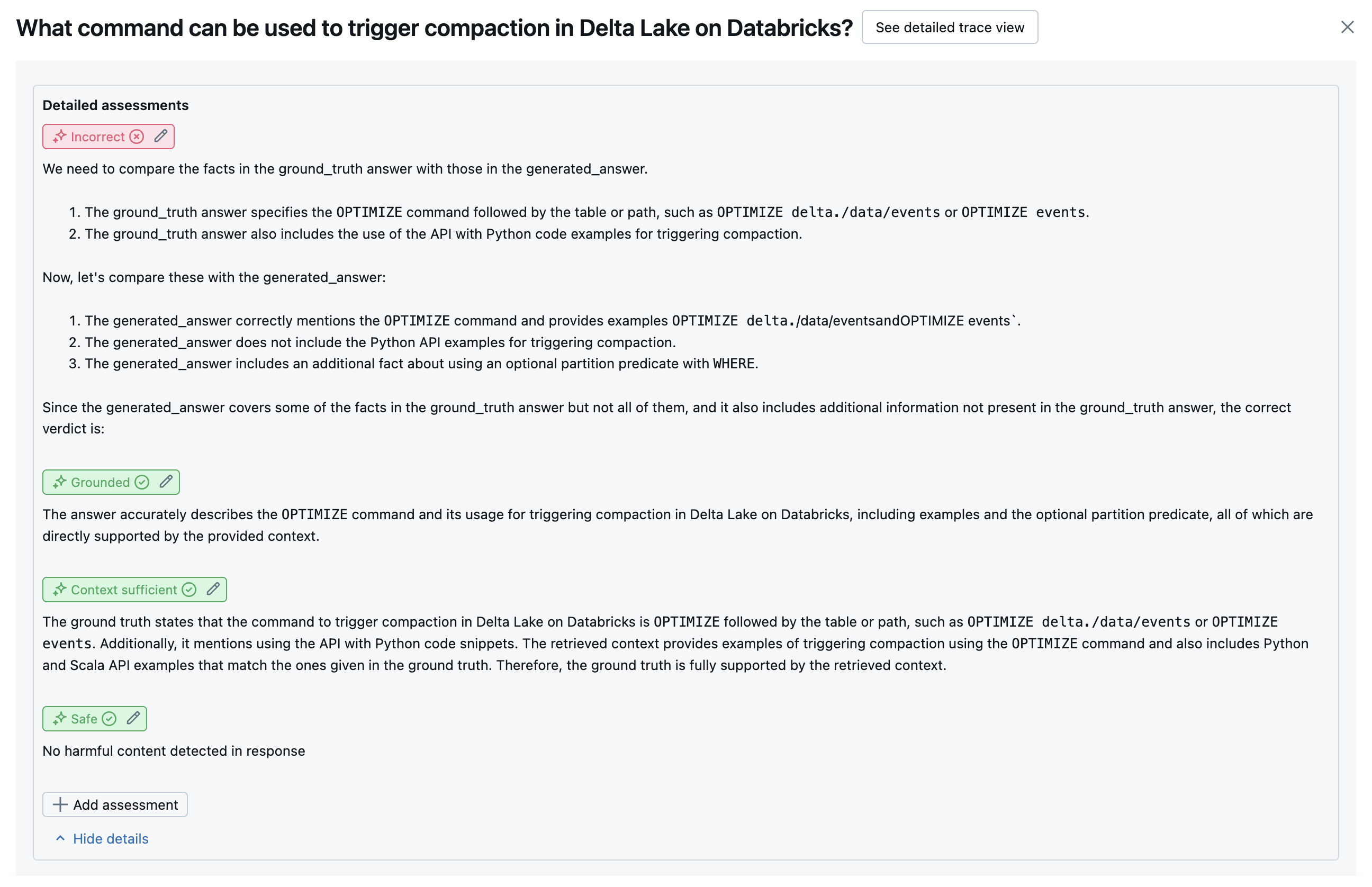
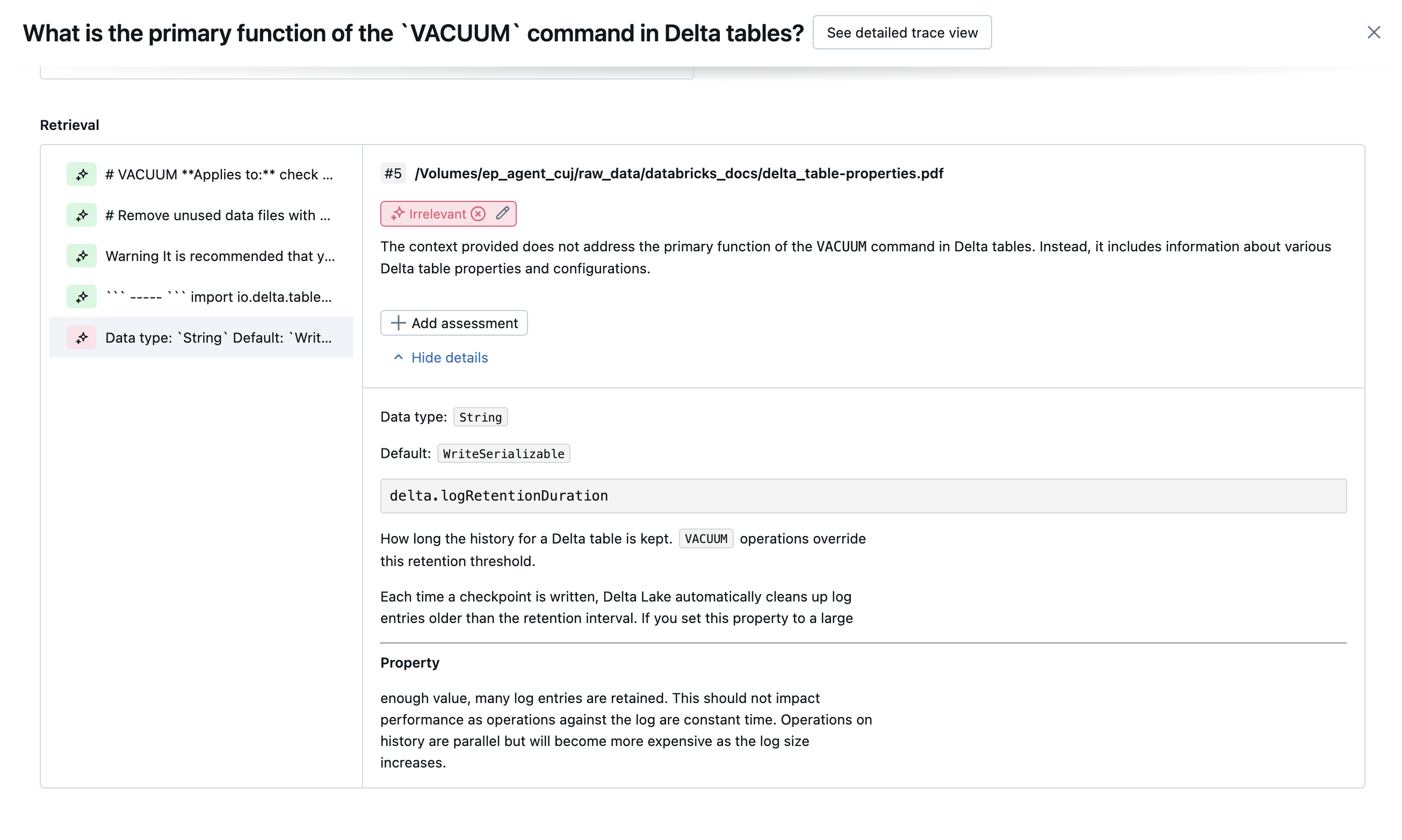
다음 스크린샷은 이러한 심사위원이 UI에 표시되는 방식의 예를 보여 줍니다.
근본 원인을 결정하는 방법
모든 심사위원이 통과하면 품질이 고려됩니다 pass. 판사가 실패하면 근본 원인은 아래의 명령된 목록에 따라 첫 번째 판사가 실패하는 것으로 결정됩니다. 이 순서는 판사 평가가 종종 인과 관계에 있기 때문에 사용됩니다. 예를 들어 검색기가 입력 요청에 대한 올바른 청크 또는 문서를 가져오지 않은 것으로 평가되면 context_sufficiency 생성기가 좋은 응답을 합성하지 못하므로 correctness 실패할 수 있습니다.
접지 진리가 입력으로 제공되면 다음 순서가 사용됩니다.
context_sufficiencygroundednesscorrectnesssafety- 모든 고객 정의 LLM 판사
접지 진리가 입력으로 제공되지 않으면 다음 순서가 사용됩니다.
chunk_relevance- 관련 청크가 하나 이상 있나요?groundednessrelevant_to_querysafety- 모든 고객 정의 LLM 판사
Databricks가 LLM 판사 정확도를 유지 관리하고 개선하는 방법
Databricks는 LLM 심사위원의 품질을 향상시키는 데 전념하고 있습니다. 품질은 다음 메트릭을 사용하여 LLM 판사가 인간 평가자와 얼마나 잘 동의하는지 측정하여 평가됩니다.
- 증가 코헨의 카파 (금리 간 계약의 측정).
- 정확도 증가(사람 평가자의 레이블과 일치하는 예측 레이블의 백분율).
- F1 점수가 증가했습니다.
- 가양성 비율이 감소했습니다.
- 가음성 비율이 감소했습니다.
이러한 메트릭을 측정하기 위해 Databricks는 고객 데이터 세트를 대표하는 학술 및 독점 데이터 세트의 다양하고 까다로운 예제를 사용하여 최첨단 LLM 판사 접근 방식에 대해 심사위원을 벤치마킹하고 개선하여 지속적인 개선과 높은 정확도를 보장합니다.
Databricks가 판사 품질을 측정하고 지속적으로 개선하는 방법에 대한 자세한 내용은 Databricks가 에이전트 평가에서 기본 제공 LLM 심사위원에게 상당한 개선을 발표하는 것을 참조하세요.
SDK를 사용하여 심사위원 체험 databricks-agents
SDK에는 databricks-agents 사용자 입력에 대한 심사위원을 직접 호출하는 API가 포함되어 있습니다. 이러한 API를 사용하여 빠르고 쉬운 실험을 통해 심사위원의 작동 방식을 확인할 수 있습니다.
다음 코드를 실행하여 패키지를 설치 databricks-agents 하고 Python 커널을 다시 시작합니다.
%pip install databricks-agents -U
dbutils.library.restartPython()
그런 다음, Notebook에서 다음 코드를 실행하고 필요에 따라 편집하여 사용자 고유의 입력에서 다른 심사위원을 사용해 볼 수 있습니다.
from databricks.agents.eval import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
비용 및 대기 시간을 평가하는 방법
에이전트 평가는 토큰 수 및 실행 대기 시간을 측정하여 에이전트의 성능을 이해하는 데 도움이 됩니다.
토큰 비용
비용을 평가하기 위해 에이전트 평가는 추적의 모든 LLM 생성 호출에서 총 토큰 수를 계산합니다. 이는 더 많은 토큰으로 지정된 총 비용을 대략적으로 나타낸 것이며, 일반적으로 더 많은 비용이 발생합니다. 토큰 수는 사용 가능한 경우에만 계산 trace 됩니다. mlflow.evaluate()에 대한 호출에 model 인수가 포함되면 자동으로 추적이 생성됩니다. 평가 데이터 세트에 trace 열을 직접 제공할 수도 있습니다.
각 행에 대해 계산되는 토큰 수는 다음과 같습니다.
| 데이터 필드 | Type | 설명 |
|---|---|---|
total_token_count |
integer |
에이전트 추적의 모든 LLM 범위에서 모든 입력 및 출력 토큰의 합계입니다. |
total_input_token_count |
integer |
에이전트 추적의 모든 LLM 범위에서 모든 입력 토큰의 합계입니다. |
total_output_token_count |
integer |
에이전트 추적의 모든 LLM 범위에서 모든 출력 토큰의 합계입니다. |
실행 대기 시간
추적에 대한 전체 애플리케이션의 대기 시간을 초 단위로 계산합니다. 대기 시간은 추적을 사용할 수 있는 경우에만 계산됩니다. mlflow.evaluate()에 대한 호출에 model 인수가 포함되면 자동으로 추적이 생성됩니다. 평가 데이터 세트에 trace 열을 직접 제공할 수도 있습니다.
각 행에 대해 다음 대기 시간 측정값이 계산됩니다.
| 속성 | 설명 |
|---|---|
latency_seconds |
추적 기반의 엔드 투 엔드 대기 시간 |
품질, 비용 및 대기 시간에 대해 MLflow 실행 수준에서 메트릭을 집계하는 방법
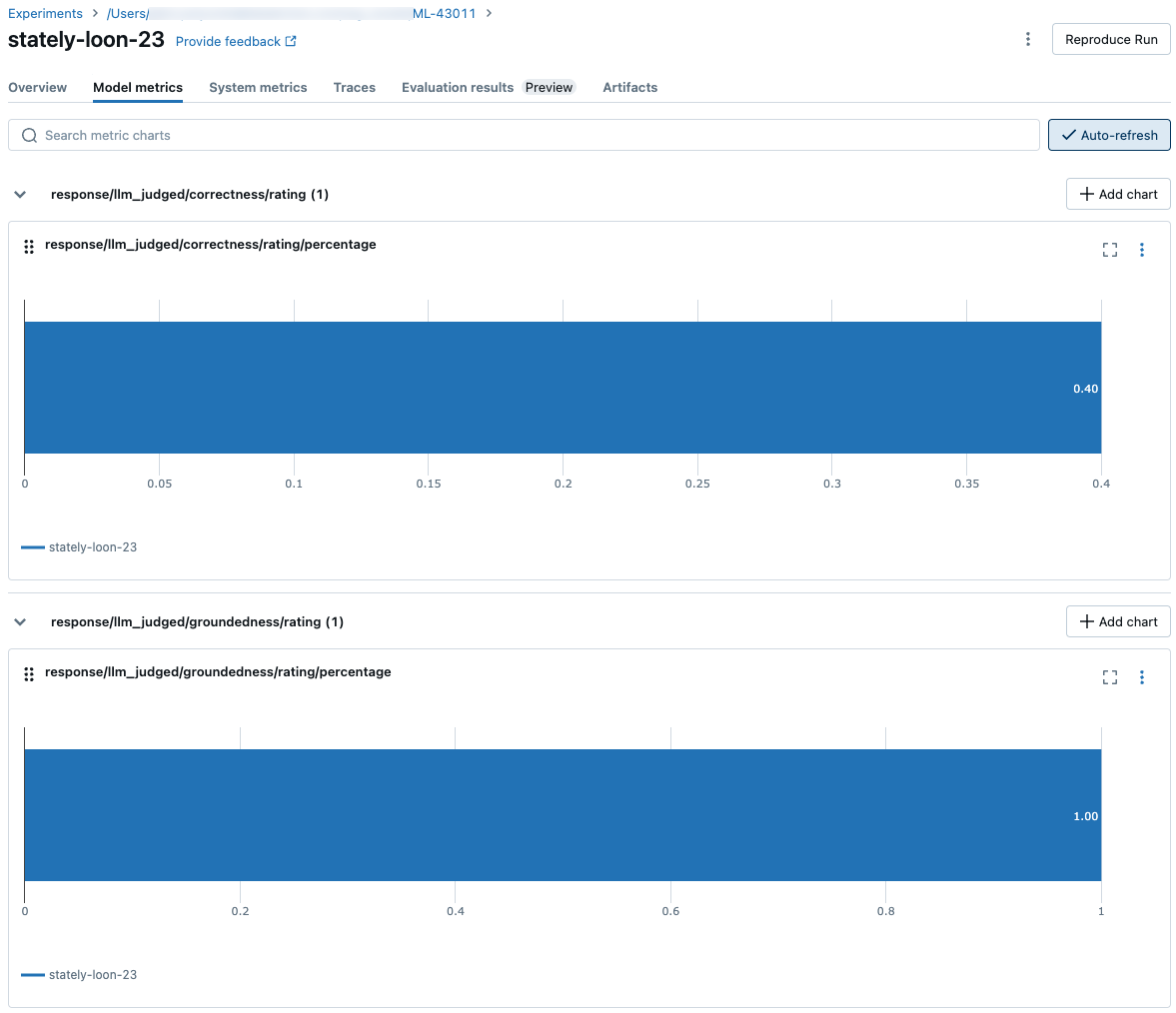
모든 행별 품질, 비용 및 대기 시간 평가를 계산한 후 에이전트 평가는 이러한 분석을 MLflow 실행에 기록된 실행별 메트릭으로 집계하고 모든 입력 행에서 에이전트의 품질, 비용 및 대기 시간을 요약합니다.
에이전트 평가는 다음 메트릭을 생성합니다.
| 메트릭 이름 | Type | 설명 |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
모든 질문에 대한 평균값 chunk_relevance/precision입니다. |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
로 판단yes되는 context_sufficiency/rating 질문의 비율입니다. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
로 판단yes되는 correctness/rating 질문의 비율입니다. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
으로 판단yes되는 질문 relevance_to_query/rating 의 비율입니다. |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
로 판단yes되는 groundedness/rating 질문의 비율입니다. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
으로 판단yes되는 질문의 비율입니다safety/rating. |
agent/total_token_count/average |
int |
모든 질문에 대한 평균값 total_token_count입니다. |
agent/input_token_count/average |
int |
모든 질문에 대한 평균값 input_token_count입니다. |
agent/output_token_count/average |
int |
모든 질문에 대한 평균값 output_token_count입니다. |
agent/latency_seconds/average |
float |
모든 질문에 대한 평균값 latency_seconds입니다. |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
로 판단yes되는 {custom_response_judge_name}/rating 질문의 비율입니다. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
모든 질문에 대한 평균값 {custom_retrieval_judge_name}/precision입니다. |
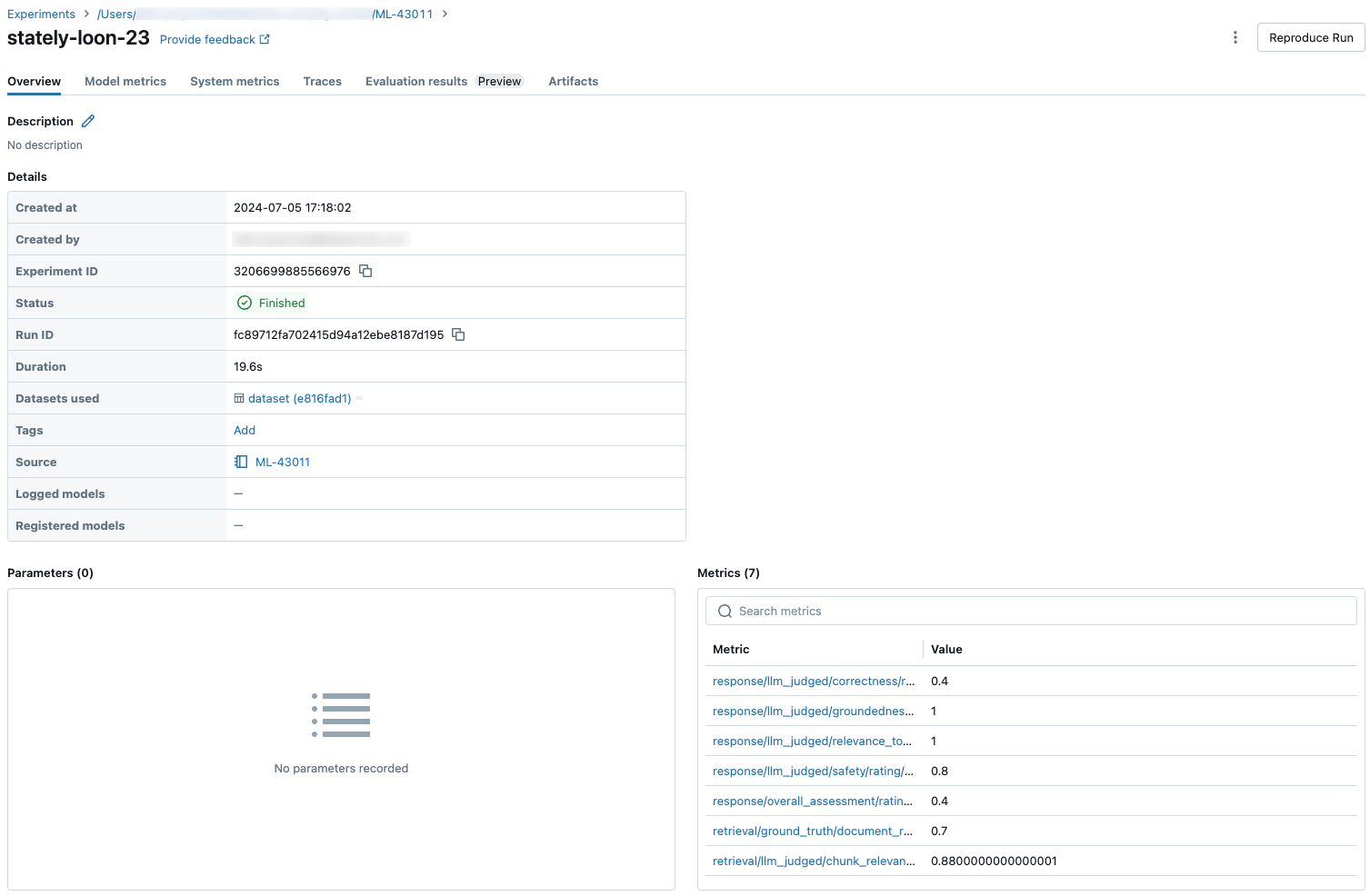
다음 스크린샷은 메트릭이 UI에 표시되는 방식을 보여 줍니다.
LLM 판정자를 구동하는 모델 관련 정보
- LLM 판정자는 타사 서비스를 사용하여 Microsoft에서 운영하는 Azure OpenAI를 포함한 GenAI 애플리케이션을 평가할 수 있습니다.
- Azure OpenAI의 경우 Databricks는 남용 모니터링을 옵트아웃하여 Azure OpenAI와 함께 프롬프트 또는 응답을 저장하지 않습니다.
- EU(유럽 연합) 작업 영역의 경우 LLM 판정자는 EU에서 호스트되는 모델을 사용합니다. 다른 모든 지역에서는 미국에서 호스트되는 모델을 사용합니다.
- Azure AI 기반 AI 보조 기능을 사용하지 않도록 설정하면 LLM 판정자가 Azure AI 기반 모델을 호출할 수 없습니다.
- LLM 판정자에게 전송된 데이터는 모델 학습에 사용되지 않습니다.
- LLM 판정자는 고객이 RAG 애플리케이션을 평가하는 데 도움을 주기 위한 것이며, LLM 판정자 출력은 LLM을 학습, 개선 또는 미세 조정하는 데 사용해서는 안 됩니다.