RAG 데이터 파이프라인 품질 향상
이 문서에서는 데이터 파이프라인 변경 사항을 구현하는 실용적인 관점에서 데이터 파이프라인 선택을 실험하는 방법을 설명합니다.
데이터 파이프라인의 주요 구성 요소
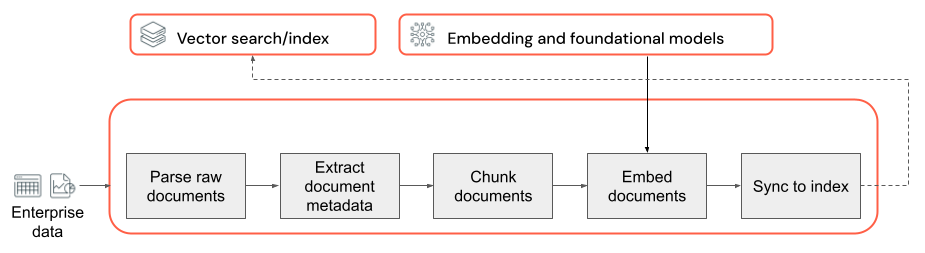
비정형 데이터를 사용하는 모든 RAG 애플리케이션의 기본은 데이터 파이프라인입니다. 이 파이프라인은 RAG 애플리케이션에서 효과적으로 활용할 수 있는 형식으로 비정형 데이터를 준비하는 역할을 담당합니다. 이 데이터 파이프라인은 임의로 복잡해질 수 있지만 RAG 애플리케이션을 처음 빌드할 때 고려해야 하는 주요 구성 요소는 다음과 같습니다.
- 말뭉치 작성: 특정 사용 사례에 따라 올바른 데이터 원본 및 콘텐츠 선택.
- 구문 분석: 적절한 구문 분석 기술을 사용하여 원시 데이터에서 관련 정보 추출.
- 청크 분할: 효율적인 검색을 위해 구문 분석된 데이터를 더 작고 관리하기 쉬운 청크로 분할.
- 포함: 청크 분할된 텍스트 데이터를 의미 체계의 의미를 캡처하는 숫자 벡터 표현으로 변환.
말뭉치 작성
올바른 데이터 말뭉치가 없으면 RAG 애플리케이션이 사용자 쿼리에 응답하는 데 필요한 정보를 검색할 수 없습니다. 올바른 데이터는 애플리케이션의 특정 요구 사항 및 목표에 전적으로 의존하므로 사용 가능한 데이터의 뉘앙스를 이해하는 데 시간을 할애하는 것이 중요합니다(이에 대한 지침은 요구 사항 수집 섹션 참조).
예를 들어 고객 지원 봇을 빌드할 때 다음도 고려할 수 있습니다.
- 기술 자료 문서
- FAQ(질문과 대답)
- 제품 설명서 및 사양
- 문제 해결 가이드
모든 프로젝트의 처음부터 분야 전문가 및 이해관계자를 참여시켜 데이터 말뭉치의 품질과 범위를 향상시킬 수 있는 관련 콘텐츠를 식별하고 큐레이팅할 수 있습니다. 사용자가 제출할 가능성이 있는 쿼리 유형에 대한 인사이트를 제공하고 포함할 가장 중요한 정보의 우선순위를 지정하는 데 도움이 될 수 있습니다.
구문 분석
RAG 애플리케이션의 데이터 원본을 식별했으면, 다음 단계는 원시 데이터에서 필요한 정보를 추출하는 것입니다. 구문 분석이라고 하는 이 프로세스에는 비정형 데이터를 RAG 애플리케이션에서 효과적으로 활용할 수 있는 형식으로 변환하는 작업이 포함됩니다.
사용하는 특정 구문 분석 기술 및 도구는 작업 중인 데이터 유형에 따라 달라집니다. 예시:
- 텍스트 문서(PDF, Word 문서): 비정형 및 PyPDF2와 같은 기존 라이브러리는 다양한 파일 형식을 처리하고 구문 분석 프로세스를 사용자 지정하기 위한 옵션을 제공할 수 있습니다.
- HTML 문서: BeautifulSoup와 같은 HTML 구문 분석 라이브러리를 사용하여 웹 페이지에서 관련 콘텐츠를 추출할 수 있습니다. 이를 통해 HTML 구조를 탐색하고, 특정 요소를 선택하며, 원하는 텍스트 또는 특성을 추출할 수 있습니다.
- 이미지 및 스캔한 문서: 일반적으로 이미지에서 텍스트를 추출하려면 OCR(광학 인식) 기술이 필요합니다. 인기 있는 OCR 라이브러리로, Tesseract, Amazon Textract, Azure AI Vision OCR, Google Cloud Vision API가 있습ㄴ디ㅏ.
데이터 구문 분석을 위한 모범 사례
데이터를 구문 분석할 때 다음 모범 사례를 고려하세요.
- 데이터 정리: 추출된 텍스트를 전처리하여 머리글, 바닥글 또는 특수 문자와 같은 관련이 없는 정보나 노이즈 정보를 제거합니다. RAG 체인이 처리해야 하는 불필요하거나 형식이 잘못된 정보의 양을 줄이는 것이 중요합니다.
- 오류 및 예외 처리: 오류 처리 및 로깅 메커니즘을 구현하여 구문 분석 프로세스 중에 발생한 문제를 식별하고 해결합니다. 문제를 신속하게 식별하고 해결하는 데 도움이 됩니다. 이렇게 하면 종종 원본 데이터의 품질과 관련된 업스트림 문제를 가리킵니다.
- 구문 분석 논리 사용자 지정: 데이터의 구조 및 형식에 따라 구문 분석 논리를 사용자 지정하여 가장 관련성이 큰 정보를 추출해야 할 수 있습니다. 사전에 추가적인 노력이 필요할 수 있지만 필요한 경우 이 작업을 수행하는 데 시간을 투자하면 많은 다운스트림 품질 문제가 방지할 수 있습니다.
- 구문 분석 품질 평가: 출력 샘플을 수동으로 검토하여 구문 분석된 데이터의 품질을 정기적으로 평가합니다. 이렇게 하면 구문 분석 프로세스의 개선 영역 또는 문제를 식별하는 데 도움이 될 수 있습니다.
청크
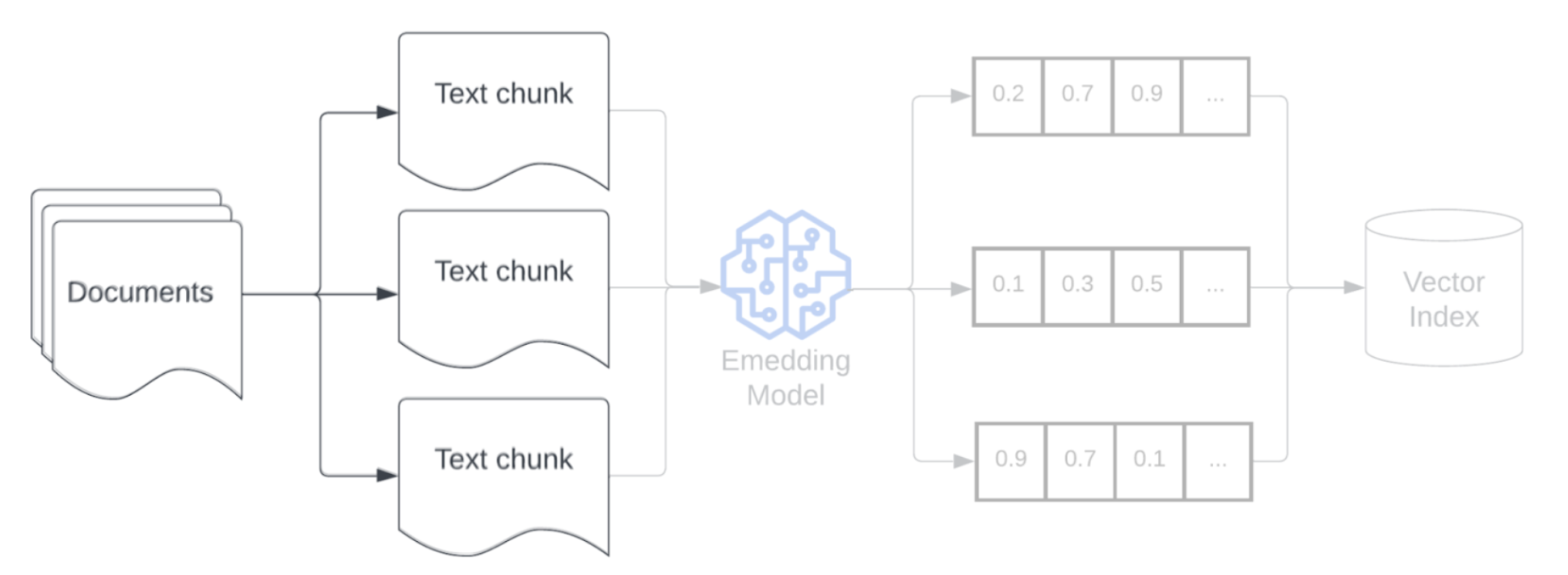
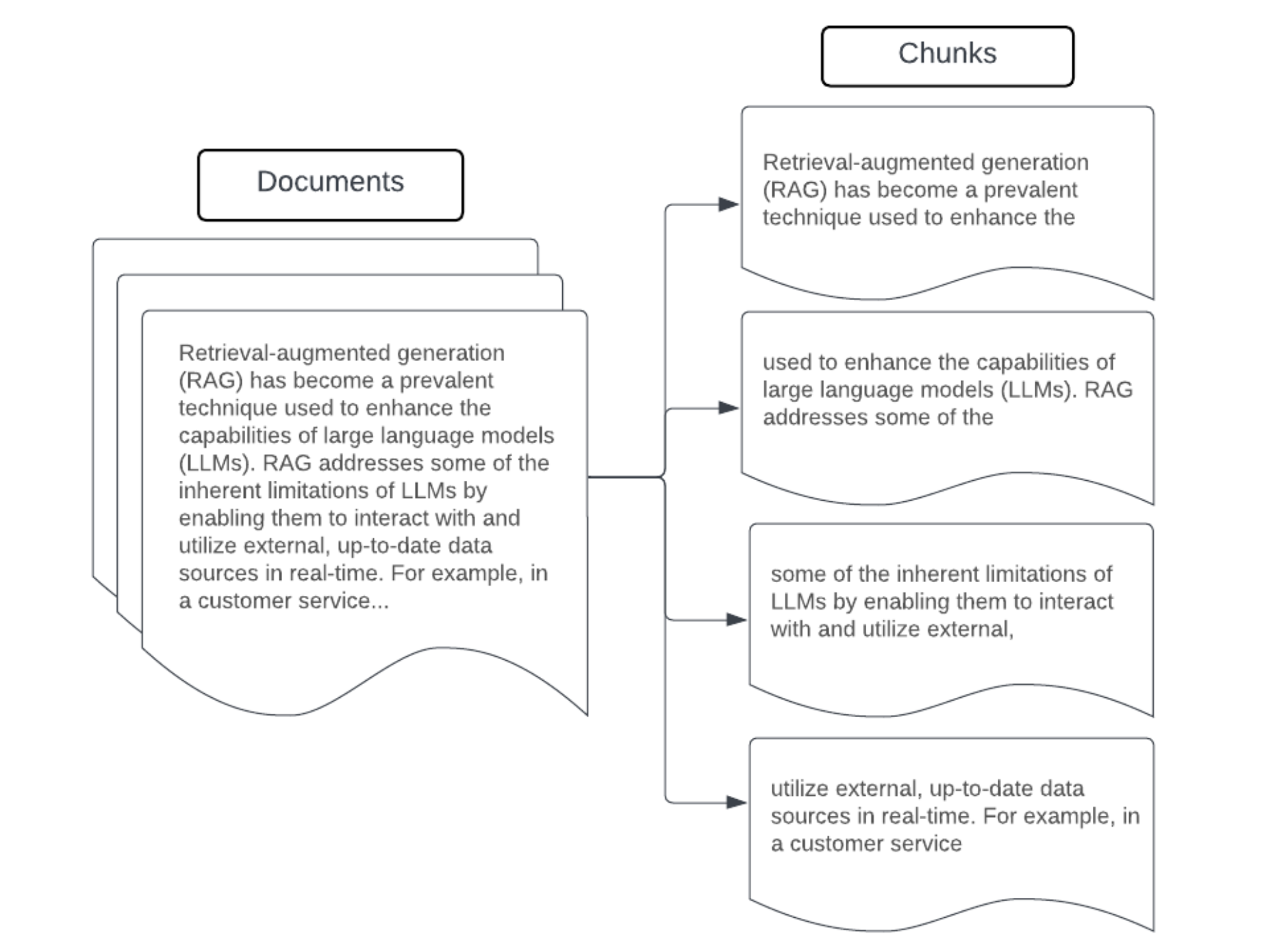
원시 데이터를 강화된 정형 형식으로 구문 분석한 후 다음 단계는 청크라고 하는 관리 가능한 더 작은 단위로 분할하는 것입니다. 큰 문서를 의미 체계적으로 집중된 더 작은 청크로 분할하면 검색된 데이터가 LLM의 컨텍스트에 맞는지 확인하는 동시에 산만하거나 관련 없는 정보가 포함되는 것을 최소화할 수 있습니다. 청크 분할에 대한 선택은 LLM이 제공하는 검색된 데이터에 직접 영향을 미치므로 RAG 애플리케이션의 첫 번째 최적화 계층 중 하나입니다.
데이터를 청크 분할할 때 다음 요소를 고려합니다.
- 청크 분할 전략: 원래 텍스트를 청크로 분할하는 데 사용하는 방법. 여기에는 추가적인 고급 문서별 분할 전략을 통해 문장, 단락 또는 특정 문자/토큰 개수를 기준으로 분할하는 것과 같은 기본 기술이 포함될 수 있습니다.
- 청크 크기: 청크가 작으면 특정 세부 정보에 초점을 맞출 수 있지만 일부 주변 정보를 잃을 수 있습니다. 청크가 크면 더 많은 컨텍스트를 캡처할 수 있지만 관련 없는 정보를 포함할 수도 있습니다.
- 청크 간 겹침: 데이터를 청크로 분할할 때 중요한 정보가 손실되지 않도록 하려면 인접한 청크 간에 일부 겹침을 포함하는 것이 좋습니다. 겹치면 청크 간에 연속성과 컨텍스트를 유지할 수 있습니다.
- 의미 체계 일관성: 가능하면 의미 체계적으로 일관된 청크를 만드는 것을 목표로 합니다. 즉, 관련 정보를 포함하고 의미 있는 텍스트 단위로 자체적으로 존재할 수 있습니다. 단락, 섹션 또는 주제 경계와 같은 원래 데이터의 구조를 고려하여 이 작업을 수행할 수 있습니다.
- 메타데이터: 원본 문서 이름, 섹션 제목 또는 제품 이름과 같은 각 청크 내 관련 메타데이터를 포함하면 검색 프로세스가 향상될 수 있습니다. 청크의 이 추가 정보는 검색 쿼리를 청크에 일치시킬 수 있습니다.
데이터 청크 분할 전략
올바른 청크 분할 방법 찾기는 반복적이고 컨텍스트에 따라 달라집니다. 모든 접근 방식에 맞는 하나의 크기는 존재하지 않습니다. 최적의 청크 크기와 방법은 특정 사용 사례 및 처리 중인 데이터의 특성에 따라 달라집니다. 대체로 청크 분할 전략은 다음과 같이 볼 수 있습니다.
- 고정 크기 청크: 텍스트를 고정된 수의 문자 또는 토큰(예: LangChain CharacterTextSplitter)과 같이 미리 결정된 크기의 청크로 분할합니다. 임의 수의 문자/토큰으로 분할은 빠르고 쉽게 설정할 수 있지만 일반적으로 의미 체계가 일관된 청크가 생성되지 않습니다.
- 단락 기반 청크: 텍스트의 자연 단락 경계를 사용하여 청크를 정의합니다. 이 방법은 단락에 관련 정보(예: LangChain RecursiveCharacterTextSplitter)가 자주 포함되기 때문에 청크의 의미 체계 일관성을 유지하는 데 도움이 될 수 있습니다.
- 형식별 청크: 마크다운 또는 HTML과 같은 형식에는 청크 경계(예: 마크다운 헤더)를 정의하는 데 사용할 수 있는 고유한 구조가 있습니다. 이러한 용도로 LangChain의 MarkdownHeaderTextSplitter 또는 HTML 헤더/섹션 기반 분할자와 같은 도구를 사용할 수 있습니다.
- 의미 체계 청크: 주제 모델링과 같은 기술을 적용하여 텍스트 내에서 의미 체계가 일관된 섹션을 식별할 수 있습니다. 이러한 접근 방법은 각 문서의 콘텐츠 또는 구조를 분석하여 주제의 변화에 따라 가장 적절한 청크 경계를 결정합니다. 보다 기본적인 접근 방법보다 더 관련되었지만 의미 체계 청크는 텍스트의 자연 의미 체계 구분에 더 잘 맞는 청크를 만드는 데 도움이 될 수 있습니다(이에 대한 예제는 LangChain SemanticChunker 참조).
예: 크기가 고정된 청크
LangChain의 RecursiveCharacterTextSplitter와 함께 chunk_size=100 및 chunk_overlap=20을 사용하는 고정 크기 청크 예제. ChunkViz에서는 Langchain의 문자 분할자에서 서로 다른 청크 크기 및 청크 겹침 값이 결과 청크에 미치는 영향을 시각화하는 대화형 방법을 제공합니다.
포함 모델
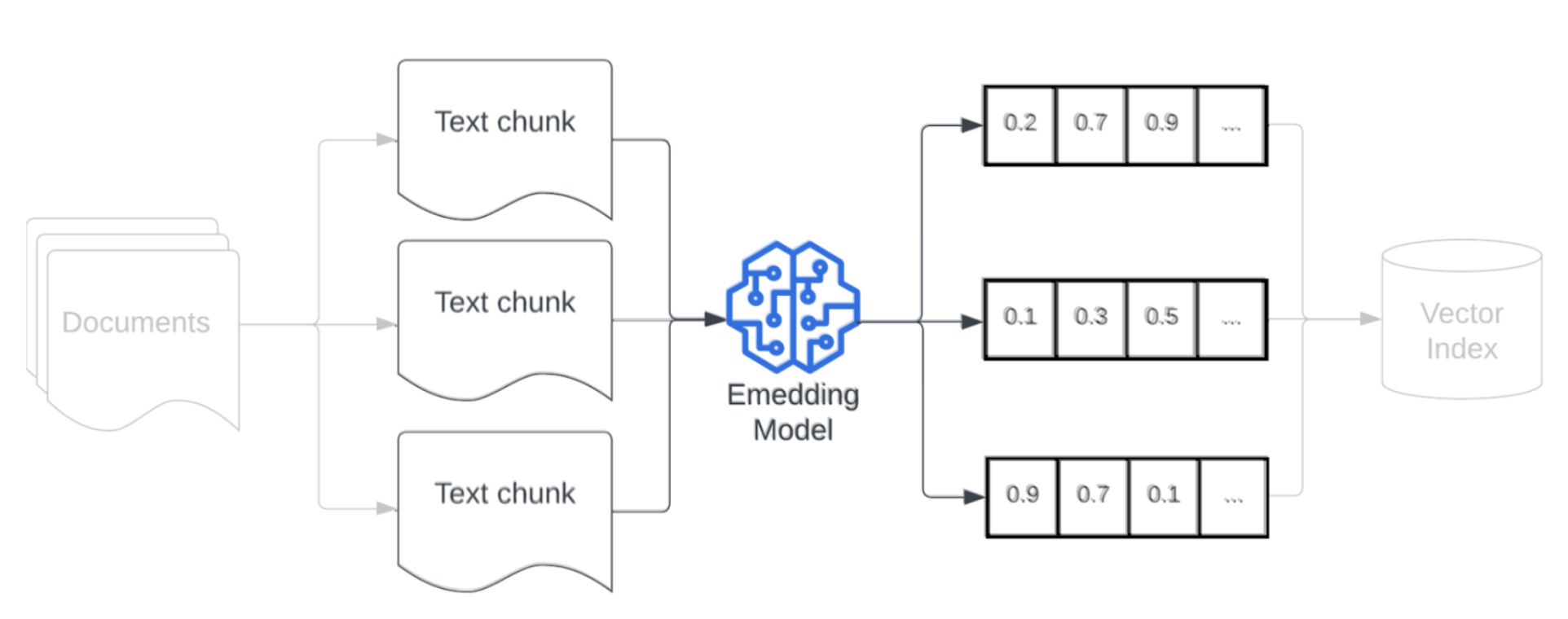
데이터를 청크 분할한 후 다음 단계는 포함 모델을 사용하여 텍스트 청크를 벡터 표현으로 변환하는 것입니다. 포함 모델은 각 텍스트 청크를 의미 체계적 의미를 캡처하는 벡터 표현으로 변환하는 데 사용됩니다. 청크를 조밀한 벡터로 나타내면 포함을 통해 검색 쿼리에 대한 의미 체계 유사성을 기반으로 가장 관련성이 높은 청크를 빠르고 정확하게 검색할 수 있습니다. 쿼리 시 검색 쿼리는 데이터 파이프라인에 청크를 포함하는 데 사용된 것과 동일한 포함 모델을 사용하여 변환됩니다.
포함 모델을 선택할 때 다음 요소를 고려합니다.
- 모델 선택: 각 포함 모델에는 미묘한 차이가 있으며 사용 가능한 벤치마크는 데이터의 특정 특성을 캡처하지 못할 수 있습니다. MTEB와 같은 표준 순위표에서 순위가 낮을 수 있는 모델까지 다양한 기존 포함 모델을 실험합니다. 다음은 고려할 몇 가지 예제입니다.
- 최대 토큰: 선택한 포함 모델의 최대 토큰 한도에 유의하세요. 이 한도를 초과하는 청크를 전달하면 청크가 잘려 중요한 정보가 손실될 수 있습니다. 예를 들어 bge-large-en-v1.5에서 최대 토큰 한도는 512입니다.
- 모델 크기: 더 큰 포함 모델은 일반적으로 더 나은 성능을 제공하지만 계산 리소스가 더 많이 필요합니다. 특정 사용 사례와 사용 가능한 리소스에 따라 성능과 효율성 간의 균형을 조정합니다.
- 미세 조정: RAG 애플리케이션이 분야별 언어(예: 내부 회사 약어 또는 용어)를 처리하는 경우 분야별 데이터에서 포함 모델을 미세 조정하는 것이 좋습니다. 이렇게 하면 모델이 특정 분야의 뉘앙스와 용어를 더 잘 캡처할 수 있으며 종종 검색 성능이 향상될 수도 있습니다.