Medallion 레이크하우스 아키텍처란?
Medallion 아키텍처는 레이크하우스에 저장된 데이터 품질을 나타내는 일련의 데이터 레이어를 설명합니다. Azure Databricks는 엔터프라이즈 데이터 제품에 대한 단일 진리 원본을 빌드하기 위해 다층적인 접근 방식을 사용하는 것이 좋습니다.
이 아키텍처는 효율적인 분석을 위해 최적화된 레이아웃에 저장하기 전 데이터가 여러 유효성 검사 및 변환 레이어를 통과할 때 원자성, 일관성, 격리성 및 내구성을 보장합니다. 브론즈(원시), 실버(유효성 검사됨) 및 골드(보강됨) 용어는 이러한 각 레이어에 있는 데이터 품질을 기술합니다.
데이터 디자인 패턴으로서의 Medallion 아키텍처
medallion 아키텍처는 데이터를 논리적으로 구성하는 데 사용되는 데이터 디자인 패턴입니다. 그 목표는 아키텍처의 각 계층(Bronze ⇒ Silver ⇒ Gold 계층 테이블)을 통해 흐르는 데이터의 구조와 품질을 증분하고 점진적으로 개선하는 것입니다. Medallion 아키텍처를 다중 홉 아키텍처라고 도 합니다.
이러한 계층을 통해 데이터를 진행하면 조직은 데이터 품질과 안정성을 증분 방식으로 개선하여 비즈니스 인텔리전스 및 기계 학습 애플리케이션에 더 적합할 수 있습니다.
medallion 아키텍처를 따르는 것이 권장되는 모범 사례이지만 요구 사항은 아닙니다.
| 질문 | 동 | 은 | 금 |
|---|---|---|---|
| 이 계층에서 어떻게 되나요? | 원시 데이터 수집 | 데이터 정리 및 유효성 검사 | 차원 모델링 및 집계 |
| 의도한 사용자는 누구인가요? | - 데이터 엔지니어 - 데이터 작업 - 규정 준수 및 감사 팀 |
- 데이터 엔지니어 - 데이터 분석가(자세한 분석에 필요한 자세한 정보를 계속 유지하는 보다 구체화된 데이터 세트에 Silver 계층 사용) - 데이터 과학자(모델 빌드 및 고급 분석 수행) |
- 비즈니스 분석가 및 BI 개발자 - 데이터 과학자 및 기계 학습(ML) 엔지니어 - 임원 및 의사 결정권자 - 운영 팀 |
medallion 아키텍처 예제
이 medallion 아키텍처 예제에서는 비즈니스 운영 팀에서 사용할 청동, 은 및 금색 레이어를 보여 줍니다. 각 계층은 ops 카탈로그의 다른 스키마에 저장됩니다.
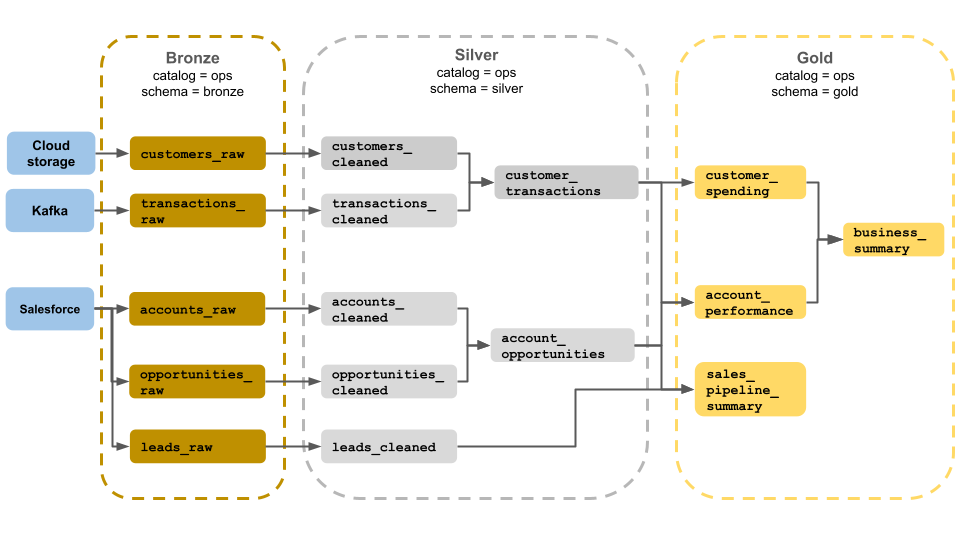
- Bronze 계층 (
ops.bronze): 클라우드 스토리지, Kafka 및 Salesforce에서 원시 데이터를 수집합니다. 여기서는 데이터 정리 또는 유효성 검사가 수행되지 않습니다. - 실버 계층(
ops.silver): 이 계층에서 데이터 정리 및 유효성 검사가 수행됩니다.- 고객 및 트랜잭션에 대한 데이터는 null을 삭제하고 잘못된 레코드를 격리하여 정리됩니다. 이러한 데이터 세트는 라는
customer_transactions새 데이터 세트에 조인됩니다. 데이터 과학자는 예측 분석에 이 데이터 세트를 사용할 수 있습니다. - 마찬가지로 Salesforce의 계정 및 기회 데이터 세트가 가입되어 계정
account_opportunities정보로 향상됩니다. - 라는
leads_raw데이터 세트에서 데이터를 정리합니다leads_cleaned.
- 고객 및 트랜잭션에 대한 데이터는 null을 삭제하고 잘못된 레코드를 격리하여 정리됩니다. 이러한 데이터 세트는 라는
- 골드 레이어 (
ops.gold): 이 계층은 비즈니스 사용자를 위해 설계되었습니다. 실버 및 골드보다 적은 데이터 세트를 포함합니다.customer_spending: 각 고객에 대한 평균 및 총 지출입니다.account_performance: 각 계정에 대한 일일 성능입니다.sales_pipeline_summary: 엔드 투 엔드 판매 파이프라인에 대한 정보입니다.business_summary: 임원진에 대한 고도로 집계된 정보입니다.
원시 데이터를 브론즈 레이어로 수집
브론즈 계층에는 유효성이 검사되지 않은 원시 데이터가 포함됩니다. 브론즈 계층에서 수집되는 데이터에는 일반적으로 다음과 같은 특성이 있습니다.
- 데이터 원본의 원시 상태를 원래 형식으로 포함하고 유지 관리합니다.
- 증분식으로 추가되고 시간이 지남에 따라 증가합니다.
- 분석가와 데이터 과학자의 액세스가 아니라 실버 테이블의 데이터를 보강하는 워크로드에서 사용할 수 있습니다.
- 데이터의 충실도를 유지하면서 진실의 단일 소스 역할을 합니다.
- 모든 기록 데이터를 보존하여 재처리 및 감사를 사용하도록 설정합니다.
- 클라우드 개체 스토리지(예: S3, GCS, ADLS), 메시지 버스(예: Kafka, Kinesis 등) 및 페더레이션된 시스템(예: Lakehouse Federation)을 비롯한 원본의 스트리밍 및 일괄 처리 트랜잭션의 조합일 수 있습니다.
데이터 정리 또는 유효성 검사 제한
최소 데이터 유효성 검사는 브론즈 계층에서 수행됩니다. 삭제된 데이터를 방지하려면 예기치 않은 스키마 변경으로부터 보호하기 위해 대부분의 필드를 문자열, VARIANT 또는 이진 파일로 저장하는 것이 좋습니다. 출처 또는 데이터 원본과 같은 메타데이터 열을 추가할 수 있습니다(예: _metadata.file_name ).
실버 레이어의 데이터 유효성 검사 및 중복 제거
데이터 정리 및 유효성 검사는 실버 계층에서 수행됩니다.
브론즈 계층에서 실버 테이블 빌드
실버 계층을 빌드하려면 하나 이상의 브론즈 또는 실버 테이블에서 데이터를 읽고 실버 테이블에 데이터를 씁니다.
Azure Databricks는 수집에서 직접 실버 테이블에 쓰는 것을 권장하지 않습니다. 수집에서 직접 작성하는 경우 스키마 변경 또는 데이터 원본의 손상된 레코드로 인해 오류가 발생합니다. 모든 원본이 추가 전용이라고 가정하고, 브론즈에서 대부분의 읽기를 스트리밍 읽기로 구성합니다. Batch 읽기는 작은 데이터 세트(예: 작은 차원 테이블)에 대해 예약되어야 합니다.
실버 계층은 데이터의 유효성 검사, 정리 및 보강 버전을 나타냅니다. 실버 계층:
- 각 레코드의 유효성이 검사되고 집계되지 않은 표현을 하나 이상 항상 포함해야 합니다. 집계 표현이 많은 다운스트림 워크로드를 구동하는 경우 이러한 표현은 실버 계층에 있을 수 있지만 일반적으로 골드 계층에 있습니다.
- 데이터 정리, 중복 제거 및 정규화를 수행하는 위치입니다.
- 오류 및 불일치를 수정하여 데이터 품질을 향상시킵니다.
- 다운스트림 처리를 위해 데이터를 더 소모성 있는 형식으로 구성합니다.
데이터 품질 적용
다음 작업은 실버 테이블에서 수행됩니다.
- 스키마 적용
- null 및 누락 값 처리
- 데이터 중복 제거
- 잘못된 순서 및 늦게 도착하는 데이터 문제 해결
- 데이터 품질 검사 및 적용
- 스키마 진화
- 형식 캐스팅
- 조인
데이터 모델링 시작
중첩되거나 반구조화된 데이터를 나타내는 방법을 선택하는 것을 포함하여 실버 계층에서 데이터 모델링을 수행하는 것이 일반적입니다.
- 데이터 형식을 사용합니다
VARIANT. - 문자열을 사용합니다
JSON. - 구조체, 맵 및 배열을 만듭니다.
- 스키마를 평면화하거나 데이터를 여러 테이블로 정규화합니다.
골드 레이어로 분석 강화
골드 계층은 다운스트림 분석, 대시보드, ML 및 애플리케이션을 구동하는 데이터의 고도로 세련된 보기를 나타냅니다. 금색 계층 데이터는 종종 특정 기간 또는 지리적 지역에 대해 고도로 집계되고 필터링됩니다. 여기에는 비즈니스 기능 및 요구 사항에 매핑되는 의미 있는 의미 있는 데이터 세트가 포함되어 있습니다.
골드 레이어:
- 분석 및 보고에 맞게 조정된 집계된 데이터로 구성됩니다.
- 비즈니스 논리 및 요구 사항에 맞춥니다.
- 쿼리 및 대시보드의 성능에 최적화되어 있습니다.
비즈니스 논리 및 요구 사항에 맞게 조정
골드 계층에서는 관계를 설정하고 측정값을 정의하여 차원 모델을 사용하여 보고 및 분석을 위해 데이터를 모델링합니다. 골드 데이터 액세스 권한이 있는 분석가는 도메인별 데이터를 찾고 질문에 대답할 수 있어야 합니다.
골드 계층은 비즈니스 도메인을 모델링하기 때문에 일부 고객은 HR, 재무 및 IT와 같은 다양한 비즈니스 요구 사항을 충족하기 위해 여러 골드 계층을 만듭니다.
분석 및 보고에 맞게 조정된 집계 만들기
조직에서는 평균, 개수, 최대값 및 최소값과 같은 측정값에 대한 집계 함수를 만들어야 하는 경우가 많습니다. 예를 들어 비즈니스에서 총 주간 매출에 대한 질문에 답변해야 하는 경우 분석가 및 다른 사용자가 자주 사용하는 구체화된 뷰를 다시 만들 필요가 없도록 이 데이터를 미리 집계하는 구체화된 뷰 weekly_sales 를 만들 수 있습니다.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
쿼리 및 대시보드의 성능 최적화
이러한 데이터 세트는 자주 쿼리되기 때문에 성능을 위해 골드 계층 테이블을 최적화하는 것이 가장 좋습니다. 대용량 기록 데이터는 일반적으로 조각 계층에서 액세스되며 골드 계층에서 구체화되지 않습니다.
데이터 수집 빈도를 조정하여 비용 제어
데이터를 수집하는 빈도를 결정하여 비용을 제어합니다.
| 데이터 수집 빈도 | 비용 | 대기 시간 | 선언적 예제 | 절차 예제 |
|---|---|---|---|---|
| 연속 증분 수집 | 더 높음 | 더 낮음 | - 클라우드 스토리지 또는 메시지 버스에서 수집하는 데 사용하는 spark.readStream 스트리밍 테이블입니다.- 이 스트리밍 테이블을 업데이트하는 Delta Live Tables 파이프라인은 지속적으로 실행됩니다. - 클라우드 스토리지 또는 메시지 버스에서 델타 테이블로 수집하기 위해 Notebook에서 사용하는 spark.readStream 구조적 스트리밍 코드입니다.- Notebook은 연속 작업 트리거와 함께 Azure Databricks 작업을 사용하여 오케스트레이션됩니다. |
|
| 트리거된 증분 수집 | 더 낮음 | 더 높음 | - 를 사용하여 spark.readStream클라우드 스토리지 또는 메시지 버스에서 수집하는 스트리밍 테이블- 이 스트리밍 테이블을 업데이트하는 파이프라인은 작업의 예약된 트리거 또는 파일 도착 트리거에 의해 트리거됩니다. - 트리거가 있는 Notebook의 구조적 스트리밍 코드입니다 Trigger.Available .- 이 Notebook은 작업의 예약된 트리거 또는 파일 도착 트리거에 의해 트리거됩니다. |
|
| 수동 증분 수집을 사용하여 일괄 처리 수집 | 더 낮음 | 자주 실행하지 않으므로 가장 높습니다. | - .를 사용하여 spark.read클라우드 스토리지에서 스트리밍 테이블 수집- 구조적 스트리밍을 사용하지 않습니다. 대신 파티션 덮어쓰기 같은 기본 형식을 사용하여 한 번에 전체 파티션을 업데이트합니다. - 구조적 스트리밍 읽기/쓰기와 유사한 비용을 허용하는 증분 처리를 설정하려면 광범위한 업스트림 아키텍처가 필요합니다. - 또한 원본 데이터를 필드로 datetime 분할한 다음 해당 파티션의 모든 레코드를 대상으로 처리해야 합니다. |