Foundation Model 미세 조정 API를 사용하여 학습 실행 만들기
이 문서에서는 Foundation Model 미세 조정(현재 Mosaic AI 모델 학습의 일부) API를 사용하여 학습 실행을 만들고 구성하는 방법을 설명하고 API 호출에 사용되는 모든 매개 변수를 설명합니다. UI를 사용하여 실행을 만들 수도 있습니다. 자세한 내용은 Foundation Model 미세 조정 UI를 사용하여 학습 실행 만들기를 참조하세요.
요구 사항
요구 사항을 참조하세요.
학습 실행 만들기
프로그래밍 방식으로 학습 실행을 만들려면 create() 함수를 사용합니다. 이 함수는 제공된 데이터 세트의 모델을 학습하고 마지막 작성기 검사점을 유추를 위해 Hugging Face 형식 검사점으로 변환합니다.
필요한 입력은 학습하려는 모델, 학습 데이터 세트의 위치 및 모델을 등록할 위치입니다. 또한 평가를 수행하고 실행의 하이퍼 매개 변수를 변경할 수 있는 선택적 매개 변수도 있습니다.
실행이 완료되면 완료된 실행 및 최종 검사점이 저장되고, 모델이 복제되며, 해당 복제본이 유추를 위한 모델 버전으로 Unity Catalog에 등록됩니다.
Unity Catalog의 복제된 모델 버전이 아닌 완료된 실행의 모델과 작성기 및 Hugging Face 검사점이 MLflow에 저장됩니다. 작성기 검사점을 지속적 미세 조정 작업에 사용할 수 있습니다.
함수의 인수에 대한 자세한 내용은 create()을 참조하세요.
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-2-7b-chat-hf',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
학습 실행 구성
다음 표에서는 함수에 대한 매개 변수를 요약합니다 foundation_model.create() .
| 매개 변수 | 필수 | Type | Description |
|---|---|---|---|
model |
x | str | 사용할 모델의 이름. 지원되는 모델을 참조하세요. |
train_data_path |
x | str | 학습 데이터의 위치. Unity Catalog(<catalog>.<schema>.<table> 또는 dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl) 또는 HuggingFace 데이터 세트의 위치일 수 있습니다.INSTRUCTION_FINETUNE의 경우 데이터 형식은 각 행에 prompt 및 response 필드가 포함된 형식으로 지정해야 합니다.CONTINUED_PRETRAIN의 경우 .txt 파일의 폴더입니다. 데이터 크기 권장 사항에 대한 모델 학습의 경우 허용되는 데이터 형식 및 권장 데이터 크기에 대한 기초 모델 미세 조정을 위한 데이터 준비를 참조하세요. |
register_to |
x | str | 쉽게 배포할 수 있도록 학습 후에 모델이 등록되는 Unity Catalog 카탈로그 및 스키마(<catalog>.<schema> 또는 <catalog>.<schema>.<custom-name>).
custom-name이 제공되지 않은 경우 기본값은 실행 이름입니다. |
data_prep_cluster_id |
str | Spark 데이터 처리에 사용할 클러스터의 클러스터 ID. 학습 데이터가 Delta 테이블에 있는 감독된 학습 태스크에 필요합니다. 클러스터 ID를 찾는 방법에 대한 자세한 내용은 클러스터 ID 가져오기를 참조하세요. | |
experiment_path |
str | 학습 실행 출력(메트릭 및 검사점)이 저장되는 MLflow 실험의 경로. 기본값은 사용자의 개인 작업 영역 내 실행 이름(예: /Users/<username>/<run_name>)입니다. |
|
task_type |
str | 실행할 작업의 유형입니다.
CHAT_COMPLETION(기본값), CONTINUED_PRETRAIN 또는 INSTRUCTION_FINETUNE일 수 있습니다. |
|
eval_data_path |
str | 평가 데이터의 원격 위치(있는 경우).
train_data_path와 동일한 형식을 따라야 합니다. |
|
eval_prompts |
List[str] | 평가 중에 응답을 생성할 프롬프트 문자열 목록. 기본값은 None(프롬프트를 생성하지 않음)입니다. 결과는 모델에 검사점이 생성될 때마다 실험에 기록됩니다. 생성은 max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true와 같은 생성 매개 변수를 사용하여 모든 모델 검사점에서 수행됩니다. |
|
custom_weights_path |
str | 학습을 위한 사용자 지정 모델 검사점의 원격 위치. 기본값은 None으로, 선택한 모델의 원래 사전 학습된 가중치에서 실행이 시작됨을 의미합니다. 사용자 지정 가중치가 제공되는 경우 이러한 가중치는 모델의 원래 사전 학습된 가중치 대신 사용됩니다. 이러한 가중치는 작성기 검사점이어야 하며 지정된 아키텍처 model 와 일치해야 합니다. 사용자 지정 모델 가중치에 대한 빌드 참조 |
|
training_duration |
str | 실행의 총 기간. 기본값은 하나의 epoch 또는 1ep입니다. epoch(10ep) 또는 토큰(1000000tok)으로 지정할 수 있습니다. |
|
learning_rate |
str | 모델 학습의 학습 속도. Llama 3.1 405B Instruct을 제외한 모든 모델의 경우 기본 학습 속도는 5e-7입니다. Llama 3.1 405B Instruct의 경우 기본 학습 속도는 1.0e-5입니다. 최적화 도구는 DecoupledLionW로, 베타가 0.99 및 0.95이고 가중치가 감소하지 않습니다. 학습 속도 스케줄러는 LinearWithWarmupSchedule로, 전체 학습 기간의 2%가 준비 기간이고 최종 학습 속도 승수가 0입니다. |
|
context_length |
str | 데이터 샘플의 최대 시퀀스 길이. 너무 긴 데이터를 잘라내고 효율성을 위해 더 짧은 시퀀스를 함께 패키지하는 데 사용됩니다. 기본값은 8,192개의 토큰 또는 제공된 모델의 최대 컨텍스트 길이 중 낮은 값입니다. 이 매개 변수를 사용하여 컨텍스트 길이를 구성할 수 있지만 각 모델의 최대 컨텍스트 길이를 초과하는 구성은 지원되지 않습니다. 각 모델의 지원되는 최대 컨텍스트 길이는 지원되는 모델을 참조하세요. |
|
validate_inputs |
Boolean | 학습 작업을 제출하기 전에 입력 경로에 대한 액세스의 유효성을 검사할지 여부. 기본값은 True입니다. |
사용자 지정 모델 가중치에 따라 빌드
파운데이션 모델 미세 조정은 선택적 매개 변수 custom_weights_path 를 사용하여 모델을 학습시키고 사용자 지정하는 사용자 지정 가중치 추가를 지원합니다.
시작하려면 이전 학습 실행에서 custom_weights_path 검사점 경로로 설정합니다. 검사점 경로는 이전 MLflow 실행의 아티팩트 탭에서 찾을 수 있습니다. 검사점 폴더 이름은 와 같은 ep29-ba30/특정 스냅샷의 일괄 처리 및 epoch에 해당합니다.

- 이전 실행의 최신 검사점을 제공하려면 작성기 검사점으로 설정합니다
custom_weights_path. 예들 들어custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink입니다. - 이전 검사점을 제공하려면 원하는 검사점(예: )에 해당하는 파일을 포함하는
custom_weights_path폴더의 경로로.distcp설정합니다custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
다음으로, 전달한 model 검사점의 기본 모델과 일치하도록 매개 변수를 업데이트합니다 custom_weights_path.
다음 예제 ift-meta-llama-3-1-70b-instruct-ohugkq 에서는 미세 조정하는 이전 실행입니다 meta-llama/Meta-Llama-3.1-70B. 최신 검사점을 ift-meta-llama-3-1-70b-instruct-ohugkq미세 조정하려면 다음과 같이 변수 및 model 변수를 설정합니다custom_weights_path.
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
미세 조정 실행에서 다른 매개 변수를 구성하려면 학습 실행 구성을 참조하세요.
클러스터 ID 가져오기
클러스터 ID를 검색하려면 다음을 수행합니다.
Databricks 작업 영역의 왼쪽 탐색 모음에서 컴퓨팅을 클릭합니다.
테이블에서 클러스터의 이름을 클릭합니다.
오른쪽 상단에서
 아이콘을 클릭하고 드롭다운 메뉴에서 JSON 보기를 선택합니다.
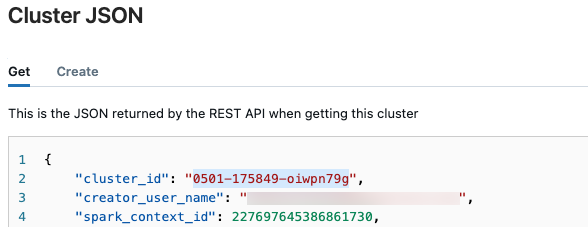
아이콘을 클릭하고 드롭다운 메뉴에서 JSON 보기를 선택합니다.클러스터 JSON 파일이 나타납니다. 파일의 첫 번째 줄인 클러스터 ID를 복사합니다.
실행 상태 가져오기
Databricks UI의 실험 페이지를 사용하거나 get_events() API 명령을 사용하여 실행 진행률을 추적할 수 있습니다. 자세한 내용은 Foundation Model 미세 조정 실행 보기, 관리 및 분석을 참조 하세요.
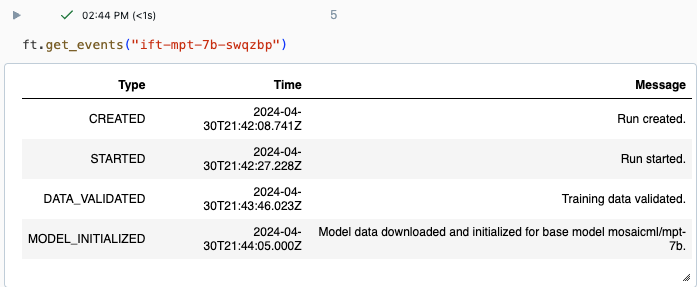
get_events()의 예제 출력:
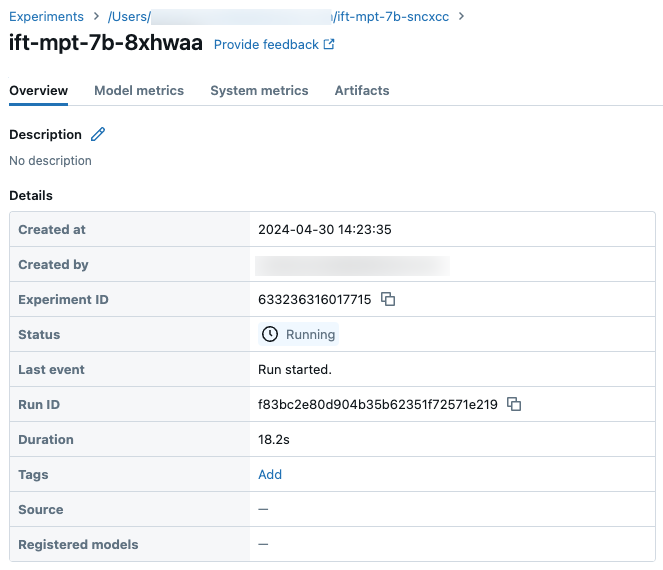
실험 페이지의 샘플 실행 세부 정보:
다음 단계
학습 실행이 완료되면 MLflow에서 메트릭을 검토하고 유추를 위해 모델을 배포할 수 있습니다. 자습서의 5~7단계: 파운데이션 모델 미세 조정 실행 만들기 및 배포를 참조하세요.
데이터 준비, 학습 실행 구성 및 배포를 미세 조정하는 지침 미세 조정 예제는 지침 미세 조정: 명명된 엔터티 인식 데모 Notebook을 참조하세요.
Notebook 예제
다음 Notebook에서는 Meta Llama 3.1 405B 지침 모델을 사용하여 가상 데이터를 생성하고 해당 데이터를 사용하여 모델을 미세 조정하는 방법의 예제를 보여줍니다.