실시간 기능 제공을 위해 온라인 테이블 사용
Important
온라인 테이블은 다음 지역에서 공개 미리 보기로 제공됩니다. westuseastuseastus2northeuropewesteurope 가격 책정 정보는 온라인 테이블 가격 책정을 참조하세요.
온라인 테이블은 온라인 액세스에 최적화된 행 지향 형식으로 저장된 델타 테이블의 읽기 전용 복사본입니다. 온라인 테이블은 요청 로드를 사용하여 처리량 용량을 자동 크기 조정하고 대기 시간이 짧고 모든 규모의 데이터에 높은 처리량 액세스를 제공하는 완전 서버리스 테이블입니다. 온라인 테이블은 빠른 데이터 조회에 사용되는 Mosaic AI 모델 서비스, 기능 제공 및 RAG(검색 보강 세대) 애플리케이션과 함께 작동하도록 설계되었습니다.
Lakehouse Federation을 사용하여 쿼리에서 온라인 테이블을 사용할 수도 있습니다. Lakehouse 페더레이션을 사용하는 경우 서버리스 SQL 웨어하우스를 사용하여 온라인 테이블에 액세스해야 합니다. 읽기 작업(SELECT)만 지원됩니다. 이 기능은 대화형 또는 디버깅 목적으로만 사용되며 프로덕션 또는 중요 업무용 워크로드에 사용하면 안 됩니다.
Databricks UI를 사용하여 온라인 테이블을 만드는 것은 1단계 프로세스입니다. 카탈로그 탐색기에서 델타 테이블을 선택하고 온라인 테이블 만들기를 선택합니다. REST API 또는 Databricks SDK를 사용하여 온라인 테이블을 만들고 관리할 수도 있습니다. API를 사용하여 온라인 테이블 작업을 참조하세요.
요구 사항
- Unity 카탈로그에 대해 작업 영역을 사용하도록 설정해야 합니다. 설명서에 따라 Unity 카탈로그 메타스토어를 만들고, 작업 영역에서 사용하도록 설정하고, 카탈로그를 만듭니다.
- 온라인 테이블에 액세스하려면 모델을 Unity 카탈로그에 등록해야 합니다.
UI를 사용하여 온라인 테이블 작업
이 섹션에서는 온라인 테이블을 만들고 삭제하는 방법과 온라인 테이블의 상태를 확인하고 업데이트를 트리거하는 방법을 설명합니다.
UI를 사용하여 온라인 테이블 만들기
카탈로그 탐색기를 사용하여 온라인 테이블을 만듭니다. 필요한 권한에 대한 자세한 내용은 사용자 권한을 참조하세요.
온라인 테이블을 만들려면 원본 델타 테이블에 기본 키가 있어야 합니다. 사용하려는 델타 테이블에 기본 키가 없는 경우 다음 지침에 따라 하나를 만듭니다. Unity 카탈로그의 기존 델타 테이블을 기능 테이블로 사용합니다.
카탈로그 탐색기에서 온라인 테이블에 동기화할 원본 테이블로 이동합니다. 만들기 메뉴에서 온라인 테이블을 선택합니다.
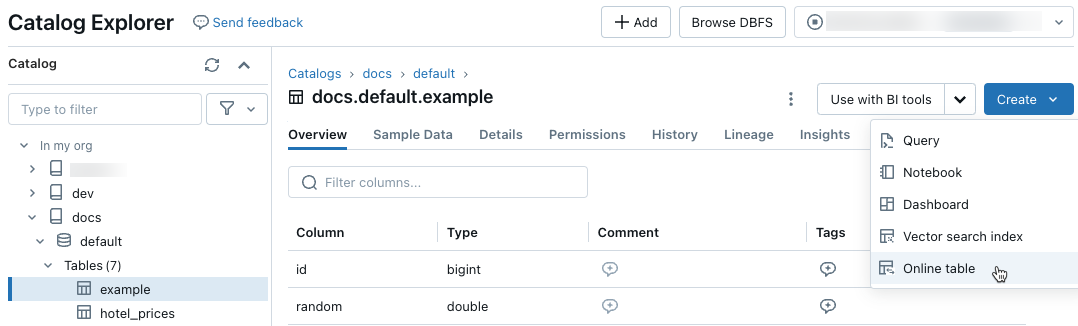
대화 상자의 선택기를 사용하여 온라인 테이블을 구성합니다.
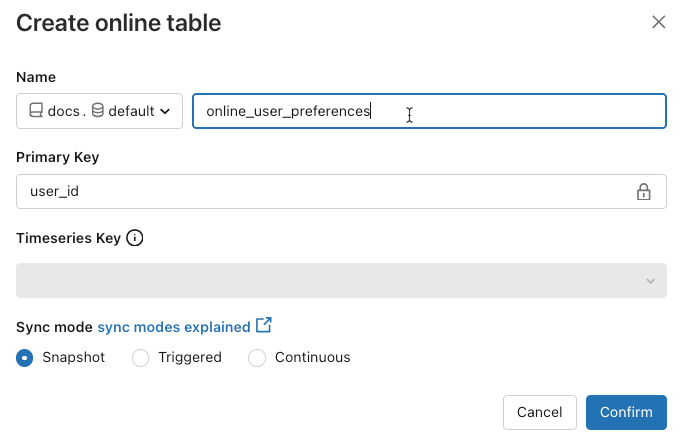
이름: Unity 카탈로그의 온라인 테이블에 사용할 이름입니다.
기본 키: 온라인 테이블에서 기본 키로 사용할 원본 테이블의 열입니다.
시계열 키: (선택 사항). 시간 키로 사용할 원본 테이블의 열입니다. 지정한 경우 온라인 테이블에는 각 기본 키에 대한 최신 시간 표시 키 값이 있는 행만 포함됩니다.
동기화 모드: 동기화 파이프라인이 온라인 테이블을 업데이트하는 방법을 지정합니다. 스냅샷, 트리거됨 또는 연속 중 하나를 선택합니다.
정책 설명 Snapshot 파이프라인은 한 번 실행하여 원본 테이블의 스냅샷을 만들고 온라인 테이블에 복사합니다. 원본 테이블의 후속 변경 내용은 원본의 새 스냅샷을 만들고 새 복사본을 만들어 온라인 테이블에 자동으로 반영됩니다. 온라인 테이블의 콘텐츠는 원자성으로 업데이트됩니다. 트리거됨 파이프라인은 한 번 실행되어 온라인 테이블에서 원본 테이블의 초기 스냅샷 복사본을 만듭니다. 스냅샷 동기화 모드와 달리 온라인 테이블을 새로 고치면 마지막 파이프라인 실행 이후 변경 내용만 검색되어 온라인 테이블에 적용됩니다. 증분 새로 고침은 일정에 따라 수동으로 트리거되거나 자동으로 트리거될 수 있습니다. 연속 파이프라인은 지속적으로 실행됩니다. 원본 테이블에 대한 후속 변경 내용은 실시간 스트리밍 모드에서 온라인 테이블에 증분 방식으로 적용됩니다. 수동 새로 고침이 필요하지 않습니다.
참고 항목
트리거 또는 연속 동기화 모드를 지원하려면 원본 테이블에 변경 데이터 피드가 활성화되어 있어야 합니다.
- 완료되면 확인을 클릭합니다. 온라인 테이블 페이지가 나타납니다.
- 새 온라인 테이블은 만들기 대화 상자에 지정된 카탈로그, 스키마 및 이름 아래에 만들어집니다. 카탈로그 탐색기에서 온라인 테이블은
 로 표시됩니다.
로 표시됩니다.
UI를 사용하여 상태 가져오기 및 업데이트 트리거
온라인 테이블의 상태를 확인하려면 카탈로그에서 테이블의 이름을 클릭하여 엽니다. 개요 탭이 열려 있는 온라인 테이블 페이지가 나타납니다. 데이터 수집 섹션에는 최신 업데이트의 상태가 표시됩니다. 업데이트를 트리거하려면 지금 동기화를 클릭합니다. 데이터 수집 섹션에는 테이블을 업데이트하는 Delta Live Tables 파이프라인에 대한 링크도 포함되어 있습니다.
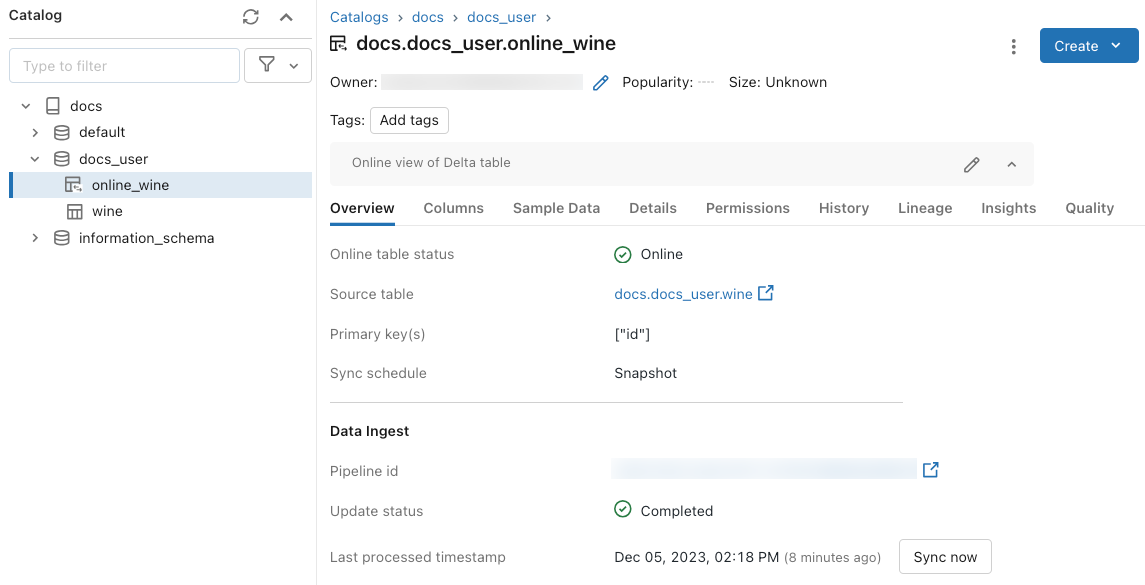
정기 업데이트 예약
스냅샷 또는 트리거된 동기화 모드를 사용하는 온라인 테이블의 경우 자동 정기 업데이트를 예약할 수 있습니다. 업데이트 일정은 테이블을 업데이트하는 Delta Live Tables 파이프라인에 의해 관리됩니다.
- 카탈로그 탐색기에서 온라인 테이블로 이동합니다.
- 데이터 수집 섹션에서 파이프라인에 대한 링크를 클릭합니다.
- 오른쪽 위 모서리에서 일정을 클릭하고 새 일정을 추가하거나 기존 일정을 업데이트합니다.
UI를 사용하여 온라인 테이블 삭제
온라인 테이블 페이지의 ![]() kebab 메뉴에서 삭제를 선택합니다.
kebab 메뉴에서 삭제를 선택합니다.
API를 사용하여 온라인 테이블 작업
Databricks SDK 또는 REST API를 사용하여 온라인 테이블을 만들고 관리할 수도 있습니다.
참조 정보는 Python용 Databricks SDK 또는 REST API에 대한 참조 설명서를 참조하세요.
요구 사항
Databricks SDK 버전 0.20 이상.
API를 사용하여 온라인 테이블 만들기
Databricks SDK - Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
REST API
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
온라인 테이블이 만들어지면 자동으로 동기화가 시작됩니다.
API를 사용하여 상태 가져오기 및 새로 고침 트리거
아래 예제에 따라 온라인 테이블의 상태 및 사양을 볼 수 있습니다. 온라인 테이블이 연속적이지 않고 데이터의 수동 새로 고침을 트리거하려는 경우 파이프라인 API를 사용하여 이 작업을 수행할 수 있습니다.
온라인 테이블 사양의 온라인 테이블과 연결된 파이프라인 ID를 사용하고 파이프라인에서 새 업데이트를 시작하여 새로 고침을 트리거합니다. 카탈로그 탐색기의 온라인 테이블 UI에서 지금 동기화를 클릭하는 것과 같습니다.
Databricks SDK - Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Delta Live Tables: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
REST API
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Delta Live Tables: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
API를 사용하여 온라인 테이블 삭제
Databricks SDK - Python
w.online_tables.delete('main.default.my_online_table')
REST API
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
온라인 테이블을 삭제하면 진행 중인 데이터 동기화가 중지되고 모든 리소스가 해제됩니다.
엔드포인트를 제공하는 기능을 사용하여 온라인 테이블 데이터 제공
Databricks 외부에서 호스트되는 모델 및 애플리케이션의 경우 온라인 테이블에서 기능을 제공하는 엔드포인트를 제공하는 기능을 만들 수 있습니다. 엔드포인트는 REST API를 사용하여 짧은 대기 시간에 기능을 사용할 수 있도록 합니다.
기능 사양 만들기
기능 사양을 만들 때 원본 델타 테이블을 지정합니다. 이렇게 하면 기능 사양을 오프라인 및 온라인 시나리오에서 모두 사용할 수 있습니다. 온라인 조회의 경우 서비스 엔드포인트는 자동으로 온라인 테이블을 사용하여 짧은 대기 시간 기능 조회를 수행합니다.
원본 델타 테이블과 온라인 테이블은 동일한 기본 키를 사용해야 합니다.
기능 사양은 카탈로그 탐색기의 함수 탭에서 볼 수 있습니다.
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )엔드포인트를 제공하는 기능을 만듭니다.
이 단계에서는 델타 테이블
user_preferences_online_table의 데이터를 동기화하는 이름이user_preferences인 온라인 테이블을 만들었다고 가정합니다. 기능 사양을 사용하여 기능 서비스 엔드포인트를 만듭니다. 엔드포인트는 연결된 온라인 테이블을 사용하여 REST API를 통해 데이터를 사용할 수 있도록 합니다.참고 항목
이 작업을 수행하는 사용자는 오프라인 테이블과 온라인 테이블의 소유자여야 합니다.
Databricks SDK - Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )Python API
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )엔드포인트를 제공하는 기능에서 데이터를 가져옵니다.
API 엔드포인트에 액세스하려면 HTTP GET 요청을 엔드포인트 URL로 보냅니다. 이 예제에서는 Python API를 사용한 방법을 설명합니다. 다른 언어 및 도구는 기능 제공을 참조하세요.
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
RAG 애플리케이션에서 온라인 테이블 사용
RAG 애플리케이션은 온라인 테이블의 일반적인 사용 사례입니다. RAG 애플리케이션에 필요한 구조적 데이터에 대한 온라인 테이블을 만들고 엔드포인트를 제공하는 기능에 호스트합니다. RAG 애플리케이션은 엔드포인트를 제공하는 기능을 사용하여 온라인 테이블에서 관련 데이터를 조회합니다.
일반 절차는 다음과 같습니다.
- 엔드포인트를 제공하는 기능을 만듭니다.
- LangChain 또는 엔드포인트를 사용하여 관련 데이터를 조회하는 유사한 패키지를 사용하여 도구를 만듭니다.
- LangChain 에이전트 또는 유사한 에이전트의 도구를 사용하여 관련 데이터를 검색합니다.
- 애플리케이션을 호스트하는 엔드포인트를 제공하는 모델을 만듭니다.
단계별 지침 및 Notebook 예제는 기능 엔지니어링 예제: 구조적 RAG 애플리케이션을 참조하세요.
Notebook 예제
다음 Notebook에서는 실시간 서비스 및 자동화된 기능 조회를 위해 온라인 테이블에 기능을 게시하는 방법을 보여 줍니다.
온라인 테이블 데모 Notebook
Mosaic AI Model Serving와 함께 온라인 테이블 사용
온라인 테이블을 사용하여 Mosaic AI 모델 서비스 기능을 조회할 수 있습니다. 기능 테이블을 온라인 테이블에 동기화하는 경우 해당 기능 테이블의 기능을 사용하여 학습된 모델은 유추 중에 자동으로 온라인 테이블의 기능 값을 조회합니다. 추가 구성은 필요하지 않습니다.
모델을 학습하는 데
FeatureLookup을 사용합니다.모델 학습의 경우 다음 예제와 같이 모델 학습 집합의 오프라인 기능 테이블의 기능을 사용합니다.
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Mosaic AI 모델 서비스로 모델을 제공합니다. 모델은 온라인 테이블에서 기능을 자동으로 조회합니다. 자세한 내용은 Databricks 모델 서비스를 사용한 자동 기능 조회를 참조하세요.
사용자 권한
온라인 테이블을 만들려면 다음 권한이 있어야 합니다.
- 원본 테이블의
SELECT권한 - 대상 카탈로그에 대한
USE_CATALOG권한입니다. - 대상 스키마에 대한
USE_SCHEMA및CREATE_TABLE권한입니다.
온라인 테이블의 데이터 동기화 파이프라인을 관리하려면 온라인 테이블의 소유자이거나 온라인 테이블에 대한 REFRESH 권한이 부여되어야 합니다. 카탈로그에 대한 USE_CATALOG 및 USE_SCHEMA 권한이 없는 사용자는 카탈로그 탐색기에 온라인 테이블을 볼 수 없습니다.
Unity 카탈로그 메타스토어에는 권한 모델 버전 1.0이 있어야 합니다.
엔드포인트 사용 모델
온라인 테이블의 데이터를 쿼리하는 데 필요한 권한이 제한된 엔드포인트를 제공하는 기능 또는 모델에 대해 고유한 서비스 주체가 자동으로 만들어집니다. 이 서비스 주체를 사용하면 엔드포인트가 리소스를 만든 사용자와 독립적으로 데이터에 액세스할 수 있으며, 작성자가 작업 영역을 떠날 경우 엔드포인트가 계속 작동할 수 있도록 합니다.
이 서비스 주체의 수명은 엔드포인트의 수명입니다. 감사 로그는 Unity 카탈로그 카탈로그 소유자에게 이 서비스 주체에게 필요한 권한을 부여하는 시스템 생성 레코드를 나타낼 수 있습니다.
제한 사항
- 원본 테이블당 하나의 온라인 테이블만 지원됩니다.
- 온라인 테이블과 원본 테이블에는 최대 1000개의 열이 있을 수 있습니다.
- 데이터 형식 배열, MAP 또는 STRUCT 열은 온라인 테이블에서 기본 키로 사용할 수 없습니다.
- 열이 온라인 테이블에서 기본 키로 사용되는 경우 열에 null 값이 포함된 원본 테이블의 모든 행은 무시됩니다.
- 외부, 시스템 및 내부 테이블은 원본 테이블로 지원되지 않습니다.
- 델타 변경 데이터 피드가 활성화되지 않은 원본 테이블은 스냅샷 동기화 모드만 지원합니다.
- 델타 공유 테이블은 스냅샷 동기화 모드에서만 지원됩니다.
- 온라인 테이블의 카탈로그, 스키마 및 테이블 이름은 영숫자 문자와 밑줄만 포함할 수 있으며 숫자로 시작해서는 안 됩니다. 대시(
-)는 허용되지 않습니다. - 문자열 형식의 열 길이는 64KB로 제한됩니다.
- 열 이름의 길이는 64자로 제한됩니다.
- 최대 행 크기는 2MB입니다.
- 공개 미리 보기 동안 Unity 카탈로그 메타스토어에 있는 모든 온라인 테이블의 결합된 크기는 압축되지 않은 2TB 사용자 데이터입니다.
- QPS(초당 최대 쿼리 수)는 12,000개입니다. 제한을 늘리려면 Databricks 계정 팀에 문의하세요.
문제 해결
온라인 테이블 만들기 옵션이 표시되지 않음
일반적으로 동기화하려는 테이블(원본 테이블)이 지원되는 형식이 아니기 때문에 발생합니다. 원본 테이블의 보안 가능 종류(카탈로그 탐색기 세부 정보 탭에 표시됨)가 아래 지원되는 옵션 중 하나인지 확인합니다.
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
온라인 테이블을 만들 때 트리거됨 또는 연속 동기화 모드를 선택할 수 없습니다.
원본 테이블에 델타 변경 데이터 피드를 사용하도록 설정하지 않았거나 뷰 또는 구체화된 뷰인 경우 이 문제가 발생합니다. 증분 동기화 모드를 사용하려면 원본 테이블에서 변경 데이터 피드를 사용하도록 설정하거나 비 보기 테이블을 사용합니다.
온라인 테이블 업데이트가 실패하거나 상태가 오프라인으로 표시
이 오류 문제를 해결하려면 카탈로그 탐색기에서 온라인 테이블의 개요 탭에 표시되는 파이프라인 ID를 클릭합니다.
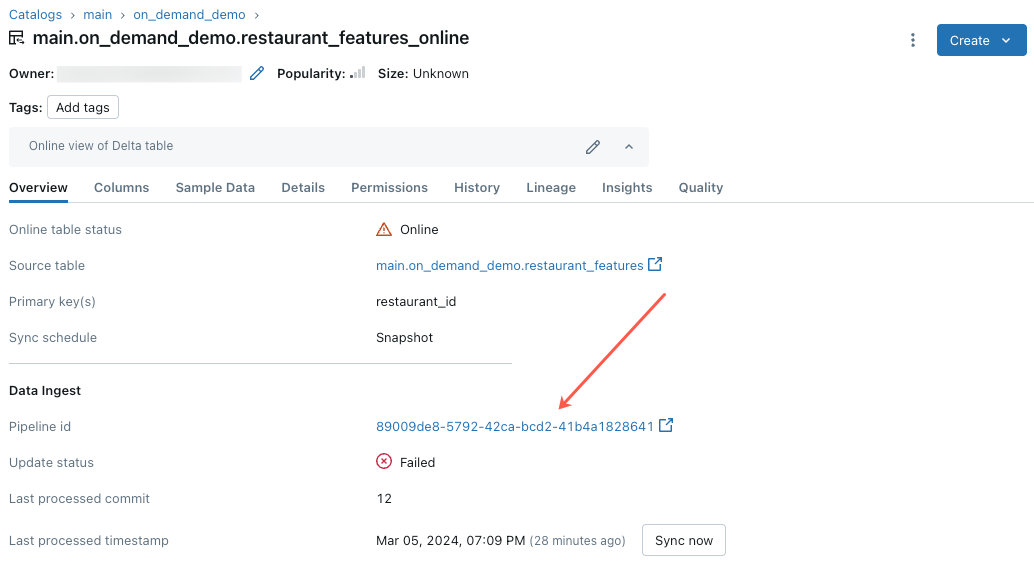
표시되는 파이프라인 UI 페이지에서 "흐름 '__online_table'을(를) 해결하지 못했습니다"라는 항목을 클릭합니다.
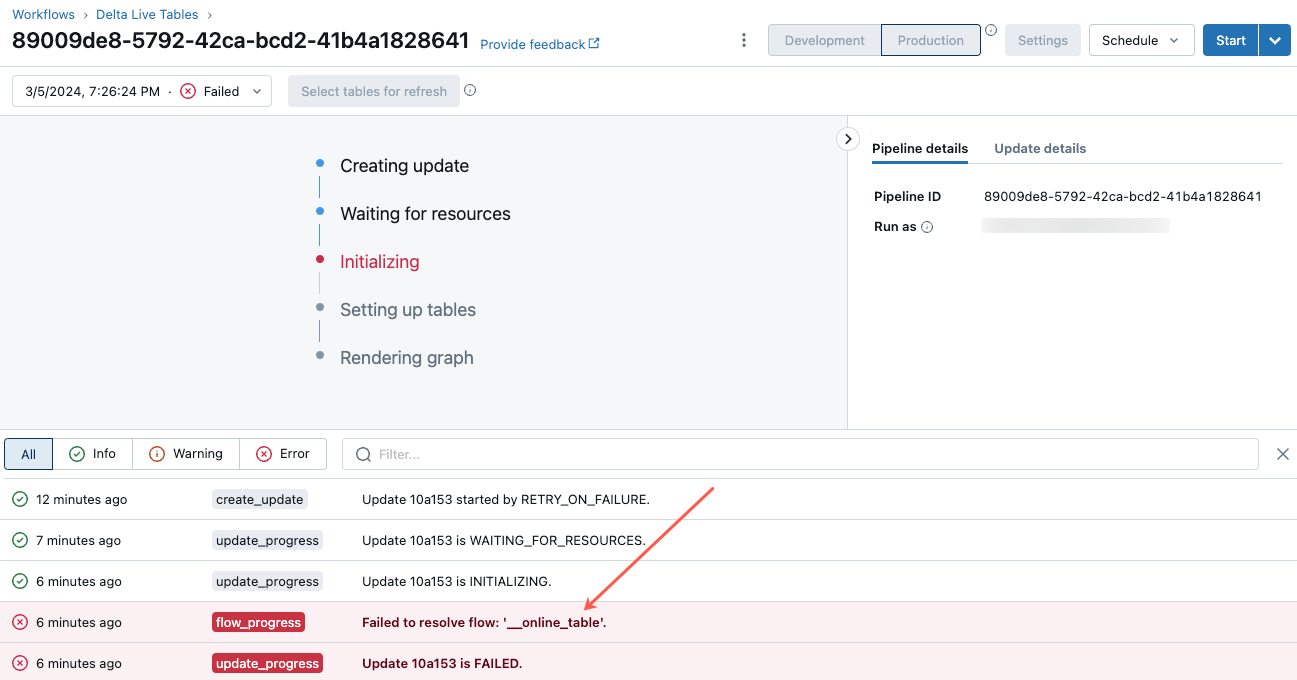
오류 세부 정보 섹션에 세부 정보가 포함된 팝업이 나타납니다.
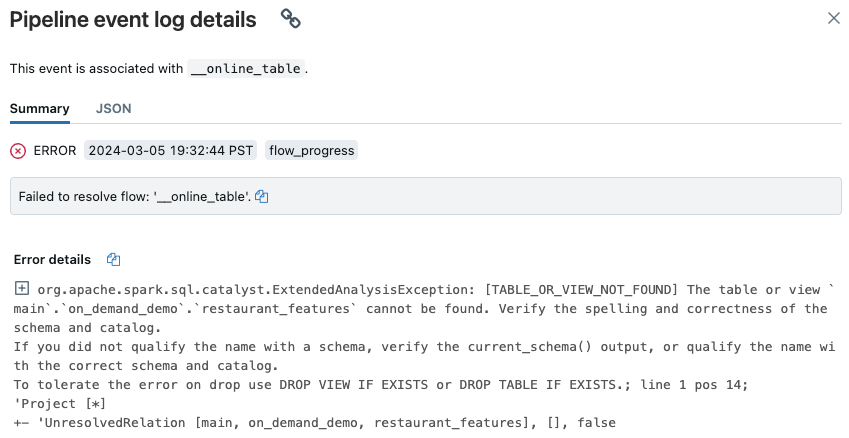
일반적인 오류의 원인은 다음과 같습니다.
온라인 테이블이 동기화되는 동안 원본 테이블이 삭제되었거나 같은 이름으로 삭제되고 다시 생성되었습니다. 이는 연속 온라인 테이블이 지속적으로 동기화되기 때문에 특히 일반적입니다.
방화벽 설정으로 인해 서버리스 컴퓨팅을 통해 원본 테이블에 액세스할 수 없습니다. 이 경우 오류 세부 정보 섹션에 "클러스터 xxx에서 DLT 서비스를 시작하지 못했습니다..."라는 오류 메시지가 표시될 수 있습니다.
온라인 테이블의 집계 크기가 2TB(압축되지 않은 크기) 메타스토어 전체 제한을 초과합니다. 2TB 제한은 델타 테이블을 행 지향 형식으로 확장한 후 압축되지 않은 크기를 나타냅니다. 행 형식의 테이블 크기는 카탈로그 탐색기에 표시된 델타 테이블의 크기보다 훨씬 클 수 있습니다. 이는 열 지향 형식으로 테이블의 압축된 크기를 나타냅니다. 차이는 테이블의 내용에 따라 100배까지 커질 수 있습니다.
델타 테이블의 압축되지 않은 행 확장 크기를 예측하려면 서버리스 SQL Warehouse에서 다음 쿼리를 사용합니다. 쿼리는 예상 확장된 테이블 크기를 바이트 단위로 반환합니다. 또한 이 쿼리를 성공적으로 실행하면 서버리스 컴퓨팅이 원본 테이블에 액세스할 수 있음을 확인합니다.
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;