프로비저닝된 처리량 기반 모델 API
이 문서에서는 Foundation Model API 프로비전된 처리량을 사용하여 모델을 배포하는 방법을 보여줍니다. Databricks는 프로덕션 워크로드에 대해 프로비저닝된 처리량을 권장하며, 성능 보장을 통해 기반 모델에 대한 최적화된 유추를 제공합니다.
프로비전된 처리량이란?
프로비전된 처리량은 동시에 끝점에 제출할 수 있는 요청의 토큰 수를 나타냅니다. 끝점을 제공하는 프로비전된 처리량은 끝점에 보낼 수 있는 초당 토큰 범위 측면에서 구성된 전용 끝점입니다.
자세한 내용은 다음 리소스를 참조하세요.
프로비전된 처리량 기반 모델 API를 참조하여 프로비전된 처리량 엔드포인트에 대해 지원되는 모델 아키텍처의 list를 확인하세요.
요구 사항
요구 사항을 참조하세요. 미세 조정된 기본 모델을 배포하려면 미세 조정된 기본 모델 배포를 참조하세요.
[권장] Unity Catalog 기본 모델 배포
Important
이 기능은 공개 미리 보기 상태입니다.
Databricks는 Unity Catalog에 미리 설치된 기본 모델을 사용하는 것을 권장합니다. 이러한 모델은 schemaai(system.ai)의 catalogsystem 아래에서 찾을 수 있습니다.
기본 모델을 배포하려면 다음을 수행합니다.
-
Catalog 탐색기에서
system.ai으로 이동하세요. - 배포하려는 모델의 이름을 클릭합니다.
- 모델 페이지에서 이 모델 제공 단추를 클릭합니다.
- 서비스 엔드포인트 만들기 페이지가 나타납니다. UI를 사용하여 프로비전된 처리량 엔드포인트 만들기를 참조하세요.
Databricks Marketplace에서 기본 모델 배포
또는 Databricks MarketplaceUnity Catalog 기본 모델을 설치할 수 있습니다.
모델 패밀리를 검색할 수 있으며 모델 페이지에서 액세스하고 로그인
모델이 Unity Catalog에 설치된 후, 서비스 UI를 사용하여 모델 서비스 엔드포인트를 만들 수 있습니다.
DBRX 모델 배포
Databricks는 워크로드에 DBRX Instruct 모델을 제공하는 것이 좋습니다. DBRX Instruct 모델을 프로비전된 처리량으로 제공하려면 Unity에서 기본 모델을 배포하는 [권장] 지침 을 따르세요. Catalog,.
이러한 DBRX 모델을 제공하는 경우 프로비전된 처리량은 최대 16k의 컨텍스트 길이를 지원합니다.
DBRX 모델은 다음 기본 시스템 프롬프트를 사용하여 모델 응답에서 관련성과 정확도를 보장합니다.
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
미세 조정된 기본 모델 배포
system.ai
schema 모델을 사용하거나 Databricks Marketplace에서 모델을 설치할 수 없는 경우 Unity Catalog로깅하여 미세 조정된 기본 모델을 배포할 수 있습니다. 이 섹션과 다음 섹션에서는 코드를 set MLflow 모델을 Unity Catalog 기록하고 UI 또는 REST API를 사용하여 프로비전된 처리량 엔드포인트를 만드는 방법을 보여 줍니다.
지원되는 Meta Llama 3.1, 3.2 및 3.3 미세 조정된 모델 및 해당 지역 가용성에 대한 프로비전된 처리량 제한 참조하세요.
요구 사항
- 미세 조정된 기본 모델 배포는 MLflow 2.11 이상에서만 지원됩니다. Databricks Runtime 15.0 ML 이상은 호환되는 MLflow 버전을 미리 설치합니다.
- Databricks는 대규모 모델의 빠른 업로드 및 다운로드를 위해 Unity Catalog 모델을 사용하는 것이 좋습니다.
catalog, schema 및 모델 이름 정의
미세 조정된 기본 모델을 배포하려면 대상 Unity Catalogcatalog, schema및 선택한 모델 이름을 정의합니다.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
모델 기록
모델 엔드포인트에 프로비전된 처리량을 사용하도록 설정하려면 MLflow transformers 버전을 사용하여 모델을 기록하고 다음 옵션에서 적절한 모델 형식 인터페이스를 사용하여 task 인수를 지정해야 합니다.
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
이러한 인수는 모델 제공 엔드포인트에 사용되는 API 서명을 지정합니다. 이러한 작업 및 해당 입력/출력 스키마에 대한 자세한 내용은 MLflow 설명서
다음은 MLflow를 사용하여 기록된 텍스트 완성 언어 모델을 기록하는 방법의 예입니다.
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
참고 항목
2.12 이전의 MLflow를 사용하는 경우 대신 동일한 metadata 함수의 mlflow.transformer.log_model() 매개 변수 내에서 작업을 지정해야 합니다.
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
프로비저닝된 처리량도 기본 모델과 대규모 GTE 임베딩 모델을 모두 지원합니다. 다음은 프로비전된 처리량과 함께 제공될 수 있도록 Alibaba-NLP/gte-large-en-v1.5 모델을 기록하는 방법의 예입니다.
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
모델이 Unity Catalog에 기록된 후, 로 계속 진행하여 UI를 사용해 프로비전된 처리량 엔드포인트를 만들어, 프로비전된 처리량으로 모델 서빙 엔드포인트를 생성합니다.
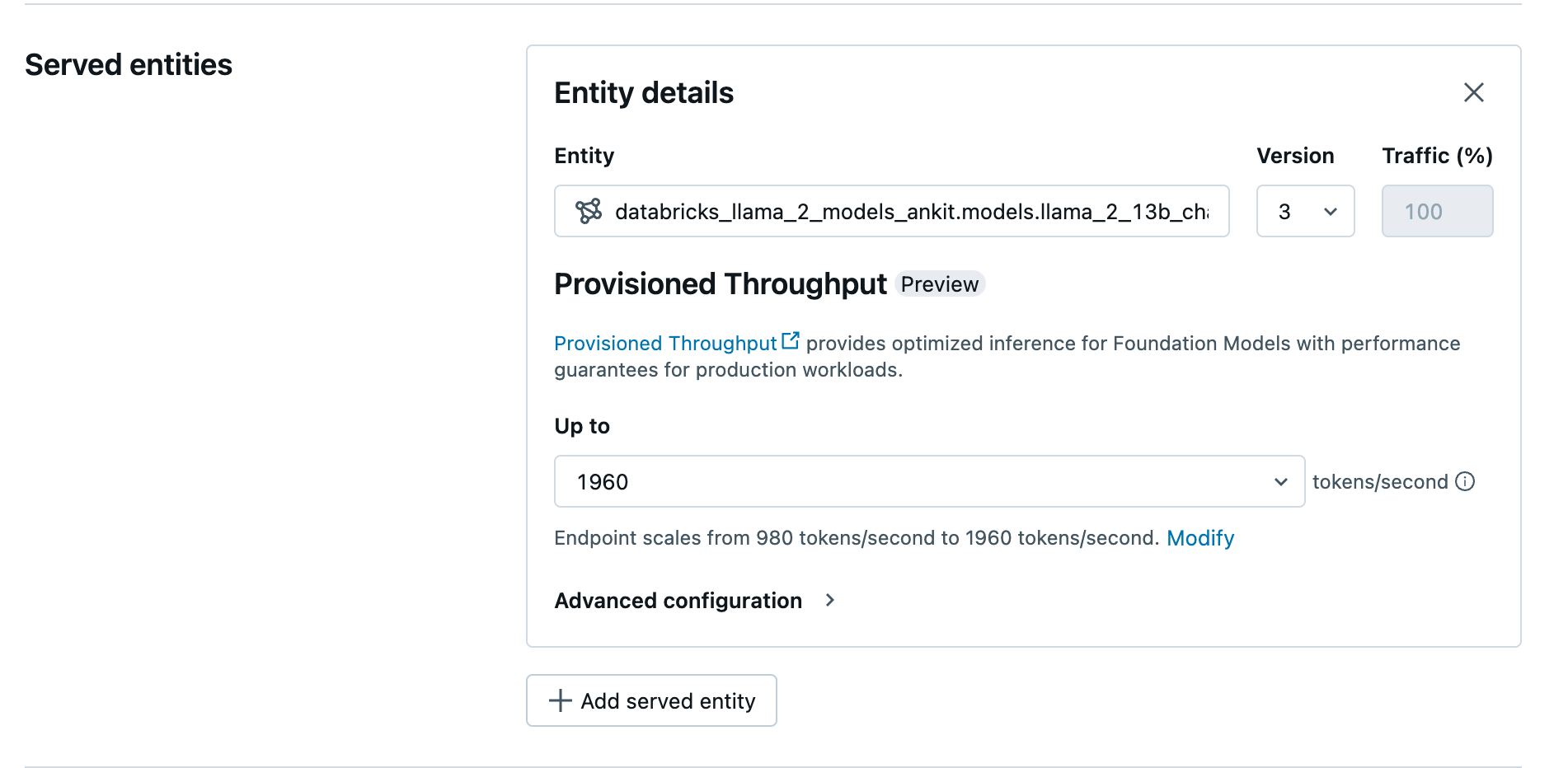
UI를 사용하여 프로비전된 처리량 엔드포인트 만들기
Unity Catalog에 기록된 모델이 준비되면 다음 단계를 통해 프로비전된 처리량 서비스 엔드포인트를 만듭니다.
- 작업 영역에서 서비스 제공 UI로 이동합니다.
- Select 서비스 엔드포인트만듭니다.
- 엔터티 필드에서 Unity Catalog모델을 select. 적격 모델의 경우 제공된 엔터티의 UI에 프로비전된 처리량 화면이 표시됩니다.
-
최대 드롭다운에서 엔드포인트에 대한 초당 최대 토큰 처리량을 구성할 수 있습니다.
- 프로비전된 처리량 엔드포인트는 자동으로 크기 조정되므로 수정을
엔드포인트를 축소할 수 있는 초당 최소 토큰을 볼 수 있습니다.
- 프로비전된 처리량 엔드포인트는 자동으로 크기 조정되므로 수정을
REST API를 사용하여 프로비전된 처리량 엔드포인트 만들기
REST API를 사용하여 프로비전된 처리량 모드로 모델을 배포하려면 요청에 min_provisioned_throughput 또는 max_provisioned_throughput 필드를 지정해야 합니다. Python을 선호하는 경우 MLflow 배포 SDK를 사용하여 엔드포인트를 만들 수도 있습니다.
모델에 적합한 프로비전된 처리량 범위를 식별하려면 프로비전된 처리량의 Get 증분참조하세요.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
채팅 완료 작업에 대한 로그 확률
채팅 완료 작업의 경우 logprobs 매개 변수를 사용하여 대규모 언어 모델 생성 프로세스의 일부로 샘플링되는 토큰의 로그 확률을 제공할 수 있습니다. 분류, 모델 불확실성 평가 및 평가 메트릭 실행을 비롯한 다양한 시나리오에 logprobs를 사용할 수 있습니다. 매개 변수 세부 정보는 채팅 작업을 참조하세요.
프로비전된 처리량을 증분 단위로 Get
프로비전된 처리량은 모델에 따라 달라지는 특정 증분을 사용하여 초당 토큰 증분으로 사용할 수 있습니다. 요구에 적합한 범위를 식별하기 위해 Databricks는 플랫폼 내에서 모델 최적화 정보 API를 사용하는 것이 좋습니다.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
다음은 API 응답의 예제입니다.
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Notebook 예제
다음 Notebooks에서는 프로비전된 처리량 Foundation Model API를 만드는 방법의 예를 보여 줍니다.
GTE 모델 Notebook에 대한 프로비전된 처리량 서비스
BGE 모델 Notebook에 대한 프로비전된 처리량 서비스
Mistral 모델 Notebook에 대한 프로비전된 처리량 서비스
제한 사항
GPU 용량 문제로 인해 모델 배포가 실패할 수 있으며, 결과적으로 엔드포인트를 생성하거나 update에서 타임아웃이 발생할 수 있습니다. 문제를 해결하려면 Databricks 계정 팀에 문의하세요.
Foundation 모델 API에 대한 자동 크기 조정은 CPU 모델 서비스보다 느립니다. Databricks는 요청 시간 제한을 방지하기 위해 오버 프로비저닝을 권장합니다.
GTE v1.5(영어) 및 BGE v1.5(영어) 모델 아키텍처만 지원됩니다.
GTE v1.5(영어)는 정규화된 포함을 generate 않습니다.