자습서: 사용자 지정 모델 배포 및 쿼리
이 문서에서는 Mosaic AI Model Serving를 사용하여 기존 ML 모델인 사용자 지정 모델을 배포하고 쿼리하기 위한 기본 단계를 제공합니다. 모델은 Unity 카탈로그 또는 작업 영역 모델 레지스트리에 등록해야 합니다.
대신 생성 AI 모델을 제공하고 배포하는 방법을 알아보려면 다음 문서를 참조하세요.
1단계: 모델 레지스트리에 모델 로그
모델 제공을 위해 모델을 기록하는 방법에는 여러 가지가 있습니다.
| 로깅 기술 | 설명 |
|---|---|
| 자동 로깅 | 기계 학습에 Databricks 런타임을 사용할 때 자동으로 설정됩니다. 그것은 가장 쉬운 방법이지만 사용자에게 컨트롤을 적게 제공합니다. |
| MLflow의 기본 제공 버전을 사용하여 로깅 | MLflow의 기본 제공 모델 버전을 사용하여 모델을 수동으로 기록할 수 있습니다. |
pyfunc를 사용하여 사용자 지정 로깅합니다. |
사용자 지정 모델이 있거나 유추 전후에 추가 단계가 필요한 경우 이를 사용합니다. |
다음 예제에서는 transformer 버전을 사용하여 MLflow 모델을 기록하고 모델에 필요한 매개 변수를 지정하는 방법을 보여줍니다.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
모델이 기록된 후에는 모델이 MLflow Unity 카탈로그 또는 모델 레지스트리에 등록되어 있는지 확인해야 합니다.
2단계: 서비스 UI를 사용하여 엔드포인트 만들기
등록된 모델이 기록되고 서비스를 제공할 준비가 되면 서비스 UI를 사용하여 엔드포인트를 제공하는 모델을 만들 수 있습니다.
사이드바에서 서비스를 클릭하여 서비스 UI를 표시합니다.
엔드포인트 만들기를 클릭합니다.
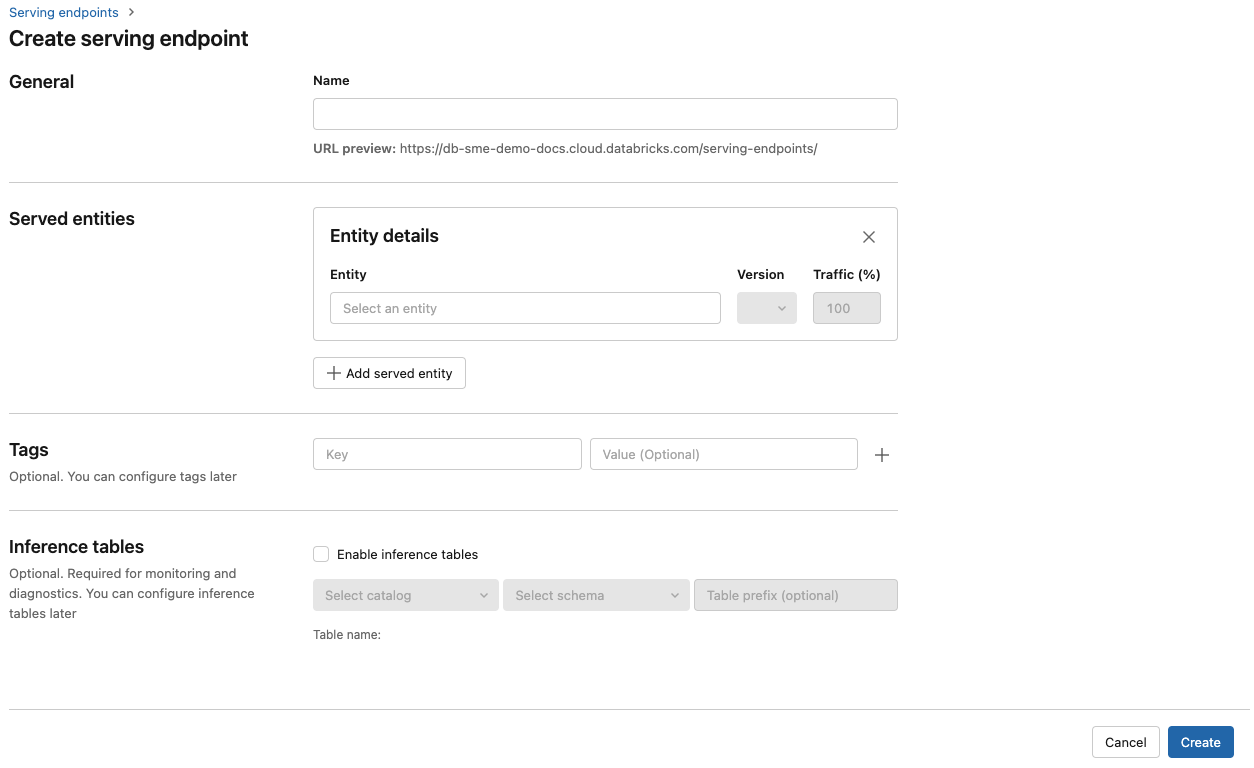
이름 필드에 엔드포인트의 이름을 입력합니다.
제공된 엔터티 섹션에서
- 엔터티 필드를 클릭하여 제공된 엔터티 선택 양식을 엽니다.
- 제공하려는 모델 유형을 선택합니다. 선택한 항목에 따라 양식이 동적으로 업데이트됩니다.
- 제공하려는 모델 및 모델 버전을 선택합니다.
- 제공된 모델로 라우팅할 트래픽의 비율을 선택합니다.
- 사용할 크기 컴퓨팅을 선택합니다. 워크로드에 CPU 또는 GPU 컴퓨팅을 사용할 수 있습니다. GPU에서의 모델 서비스 지원은 공개 미리 보기로 제공됩니다. 사용 가능한 GPU 컴퓨팅에 대한 자세한 내용은 GPU 워크로드 유형을 참조하세요.
- 컴퓨팅 스케일 아웃에서 이렇게 제공된 모델이 동시에 처리할 수 있는 요청 수에 해당하는 컴퓨팅 스케일 아웃의 크기를 선택합니다. 이 숫자는 QPS x 모델 실행 시간과 거의 같아야 합니다.
- 사용 가능한 크기는 0-4개 요청이 작음, 8-16개 요청이 중간, 16-64개 요청이 큼입니다.
- 사용하지 않을 때 엔드포인트의 크기를 0으로 조정할지 지정합니다.
만들기를 클릭합니다. 서비스 엔드포인트 페이지는 준비되지 않음으로 표시된 서비스 엔드포인트 상태로 표시됩니다.
Databricks 서비스 API를 사용하여 프로그래밍 방식으로 엔드포인트를 만들려는 경우 엔드포인트를 제공하는 사용자 지정 모델 만들기를 참조하세요.
3단계: 엔드포인트 쿼리
제공된 모델에 점수 매기기 요청을 테스트하고 보내는 가장 쉽고 빠른 방법은 서비스 UI를 사용하는 것입니다.
서비스 엔드포인트 페이지에서 쿼리 엔드포인트를 선택합니다.
모델 입력 데이터를 JSON 형식으로 삽입하고 요청 보내기를 클릭합니다. 모델이 입력 예제와 함께 로깅되면 Show Example(예제 표시)을 클릭하여 입력 예제를 로드합니다.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
점수 매기기 요청을 보내려면 지원되는 키 중 하나와 입력 형식에 해당하는 JSON 객체를 사용하여 JSON을 구성합니다. 지원되는 형식과 API를 사용하여 스코어링 요청을 보내는 방법에 대한 지침은 사용자 지정 모델에 대한 서비스 엔드포인트 쿼리를 참조하세요.
Azure Databricks 서비스 UI 외부에서 서비스 엔드포인트에 액세스하려는 경우 DATABRICKS_API_TOKEN이 필요합니다.
Important
프로덕션 시나리오에 대한 보안 모범 사례로 Databricks는 프로덕션 중에 인증을 위해 컴퓨터-컴퓨터 OAuth 토큰을 사용하는 것이 좋습니다.
테스트 및 개발을 위해 Databricks는 작업 영역 사용자 대신 서비스 주체에 속하는 개인용 액세스 토큰을 사용하는 것이 좋습니다. 서비스 주체에 대한 토큰을 만들려면 서비스 주체에 대한 토큰 관리를 참조하세요.
예제 Notebook
모델 서비스를 사용하여 MLflow transformers 모델을 제공하는 방법은 다음 Notebook을 참조하세요.
Hugging Face transformers 모델 Notebook 배포
모델 서비스를 사용하여 MLflow pyfunc 모델을 제공하는 방법은 다음 Notebook을 참조하세요. 모델 배포 사용자 지정에 대한 자세한 내용은 모델 서비스를 사용하여 Python 코드 배포를 참조하세요.