추천 모델 학습
이 문서에는 Azure Databricks에 대한 딥 러닝 기반 권장 사항 모델의 두 가지 예제가 포함되어 있습니다. 기존 권장 사항 모델에 비해, 딥 러닝 모델은 더 높은 품질의 결과를 달성하고 더 많은 양의 데이터로 확장할 수 있습니다. 이러한 모델이 계속 발전함에 따라, Databricks는 수억 명의 사용자를 처리할 수 있는 대규모 권장 사항 모델을 효과적으로 학습하기 위한 프레임워크를 제공합니다.
일반 권장 사항 시스템은 다이어그램에 표시된 단계를 사용하여 깔때기로 볼 수 있습니다.
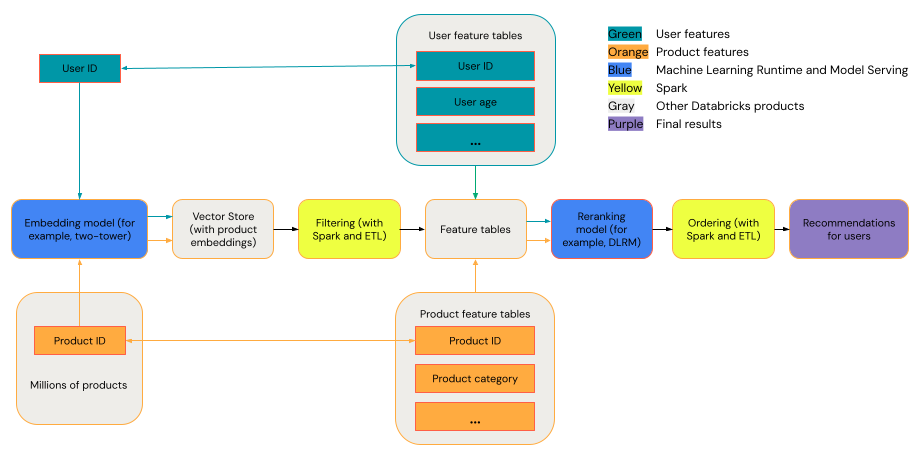
두개 타워 모델과 같은 일부 모델은 검색 모델로 더 나은 성능을 발휘합니다. 이러한 모델은 더 작고 수백만 개의 데이터 포인트에서 효과적으로 작동할 수 있습니다. DLRM 또는 DeepFM과 같은 다른 모델은 모델을 재배치할 때 더 나은 성능을 발휘합니다. 이러한 모델은 더 많은 데이터를 가져오고, 더 크고, 세분화된 권장 사항을 제공할 수 있습니다.
요구 사항
Databricks Runtime 14.3 LTS ML
도구
이 문서의 예제에서는 다음 도구를 사용합니다:
- TorchDistributor: TorchDistributor는 Databricks에서 대규모 PyTorch 모델 학습을 실행할 수 있는 프레임워크입니다. 오케스트레이션에 Spark를 사용하고 클러스터에서 사용할 수 있는 만큼 많은 GPU로 확장할 수 있습니다.
- Mosaic StreamingDataset: StreamingDataset는 프리페치 및 인터리빙과 같은 기능을 사용하여 Databricks의 큰 데이터 세트에 대한 학습의 성능과 확장성을 향상시킵니다.
- MLflow: Mlflow를 사용하면 매개 변수, 메트릭 및 모델 검사점을 추적할 수 있습니다.
- TorchRec: 최신 추천 시스템은 탑재 룩업 테이블을 사용하여 수백만 명의 사용자 및 항목을 처리하여 고품질 권장 사항을 생성합니다. 탑재 크기가 클수록 모델 성능이 향상되지만 상당한 GPU 메모리 및 다중 GPU 설정이 필요합니다. TorchRec는 여러 GPU에서 권장 사항 모델 및 룩업 테이블의 크기를 조정하는 프레임워크를 제공하므로 큰 포함에 이상적입니다.
예: 두개 타워 모델 아키텍처를 사용하는 영화 권장 사항
두개 타워 모델은 사용자 및 항목 데이터를 결합하기 전에 별도로 처리하여 대규모 개인 설정 작업을 처리하도록 설계되었습니다. 수백 또는 수천 개의 괜찮은 품질 권장 사항을 효율적으로 생성할 수 있습니다. 모델은 일반적으로 세 가지 입력이 필요합니다: user_id 기능, product_id 기능 및 사용자, 제품 상호 작용이 긍정적인지 <(사용자가 제품>을 구매했는지) 또는 부정적인(사용자가 제품에 별 1점을 부여했는지 여부)를 정의하는 이진 레이블. 모델의 출력은 사용자와 항목 모두에 대한 포함이며, 일반적으로 결합되어(종종 점 제품 또는 코사인 유사성 사용) 사용자-항목 상호 작용을 예측합니다.
두개 타워 모델은 사용자와 제품 모두에 포함을 제공하므로, Databricks Vector Store와 같은 벡터 데이터베이스에 이러한 포함을 배치하고 사용자 및 항목에 대해 유사성 검색과 유사한 작업을 수행할 수 있습니다. 예를 들어 모든 항목을 벡터 저장소에 배치할 수 있으며, 각 사용자에 대해 벡터 저장소를 쿼리하여 포함 항목이 사용자와 비슷한 상위 100개 항목을 찾을 수 있습니다.
다음 예제 Notebook은 "항목 집합에서 학습" 데이터 세트를 사용하여 두개 타워 모델 학습을 구현하여 사용자가 특정 영화를 높게 평가할 가능성을 예측합니다. 분산 데이터 로드에 Mosaic StreamingDataset, 분산 모델 학습을 위한 TorchDistributor, 모델 추적 및 로깅을 위한 Mlflow를 사용합니다.
두개 타워 추천 모델 노트북
이 Notebook은 Databricks Marketplace: 두개 타워 모델 Notebook에서도 사용할 수 있습니다
참고 항목
- 두개 타워 모델에 대한 입력은 가장 자주 user_id 및 product_id 범주 기능입니다. 사용자와 제품 모두에 대해 여러 기능 벡터를 지원하도록 모델을 수정할 수 있습니다.
- 두개 타워 모델의 출력은 일반적으로 사용자가 제품과 긍정적 또는 부정적 상호 작용을 하는지 여부를 나타내는 이진 값입니다. 회귀, 다중 클래스 분류 및 여러 사용자 작업(예: 해제 또는 구매)에 대한 확률과 같은 다른 애플리케이션에 대해 모델을 수정할 수 있습니다. 경쟁 목표가 모델에서 생성된 포함의 품질을 저하시킬 수 있으므로, 복잡한 출력을 신중하게 구현해야 합니다.
예: 가상 데이터 세트를 사용하여 DLRM 아키텍처 학습
DLRM은 개인 설정 및 권장 시스템을 위해 특별히 설계된 최신 신경망 아키텍처입니다. 범주 및 숫자 입력을 결합하여 사용자 항목 상호 작용을 효과적으로 모델링하고 사용자 기본 설정을 예측합니다. DLRM에는 일반적으로 희소 특성 (예: 사용자 ID, 항목 ID, 지리적 위치 또는 제품 범주)과 조밀한 기능(예: 사용자 연령 또는 항목 가격)이 모두 포함된 입력이 필요합니다. DLRM의 출력은 일반적으로 클릭률 또는 구매 가능성과 같은 사용자 참여 예측입니다.
DLRM은 대규모 데이터를 처리할 수 있는 고도로 사용자 지정 가능한 프레임워크를 제공하므로, 다양한 도메인에서 복잡한 권장 작업에 적합합니다. 두개 타워 아키텍처보다 큰 모델이므로 이 모델은 재배치 단계에서 자주 사용됩니다.
다음 예제 Notebook은 조밀한(숫자) 기능과 희소 특성(범주) 기능을 사용하여 이진 레이블을 예측하는 DLRM 모델을 만듭니다. 가상 데이터 세트를 사용하여 모델을 학습시키고, 분산 데이터 로드를 위한 Mosaic StreamingDataset, 분산 모델 학습을 위한 TorchDistributor, 모델 추적 및 로깅을 위한 Mlflow를 사용합니다.
DLRM Notebook
이 Notebook은 Databricks Marketplace: DLRM Notebook에서도 사용할 수 있습니다.
두개 타워 및 DLRM 모델 비교
표에는 사용할 추천 모델을 선택하기 위한 몇 가지 지침이 표시됩니다.
| 모델 유형 | 학습에 필요한 데이터 세트 크기 | 모델 크기 | 지원되는 입력 유형 | 지원되는 출력 형식 | 사용 사례 |
|---|---|---|---|---|---|
| 두개 타워 | 작게 | 작게 | 일반적으로 두 가지 기능(user_id, product_id) | 주로 이진 분류 및 포함 생성 | 수백 또는 수천 개의 가능한 권장 사항 생성 |
| DLRM | 큼 | 큼 | 다양한 범주 및 조밀 한 기능 (user_id, 성별, geographic_location, product_id, product_category, ...) | 다중 클래스 분류, 회귀, 기타 | 세분화된 검색(관련성이 높은 수십 개 항목 권장) |
요약하자면, 두개 타워 모델은 수천 개의 좋은 품질의 권장 사항을 매우 효율적으로 생성하는 데 가장 적합합니다. 예를 들어 케이블 공급자의 영화 권장 사항이 있을 수 있습니다. DLRM 모델은 더 많은 데이터를 기반으로 매우 구체적인 권장 사항을 생성하는 데 가장 적합합니다. 예를 들어 고객에게 구매할 가능성이 높은 더 적은 수의 항목을 고객에게 제공하려는 소매점이 있습니다.