학습 결과를 MLflow 실행을 통해 보기
이 문서에서는 MLflow 실행을 사용하여 모델 학습 실험의 결과를 보고 분석하는 방법과 실행을 관리하고 구성하는 방법을 설명합니다. MLflow 실험에 대한 자세한 내용은 MLflow 실험을 사용한 학습 실행 관리를 참조하세요.
MLflow 실행은 모델 코드의 단일 실행에 해당합니다. 각 실행은 실행을 시작한 노트북, 실행에서 생성된 모델, 키-값 쌍으로 저장된 모델 매개변수와 메트릭, 실행 메타데이터에 대한 태그, 그리고 실행 중 생성된 아티팩트나 출력 파일 등의 정보를 기록합니다.
모든 MLflow 실행은 활성 실험에 기록됩니다. 실험을 활성 실험으로 명시적으로 설정하지 않은 경우 실행이 Notebook 실험에 기록됩니다.
실행 세부 정보 보기
실행은 실험 세부 정보 페이지에서 또는 실행을 생성한 노트북에서 직접 액세스할 수 있습니다.
실험 세부 정보 페이지의 실행 테이블에서 실행 이름을 클릭합니다.
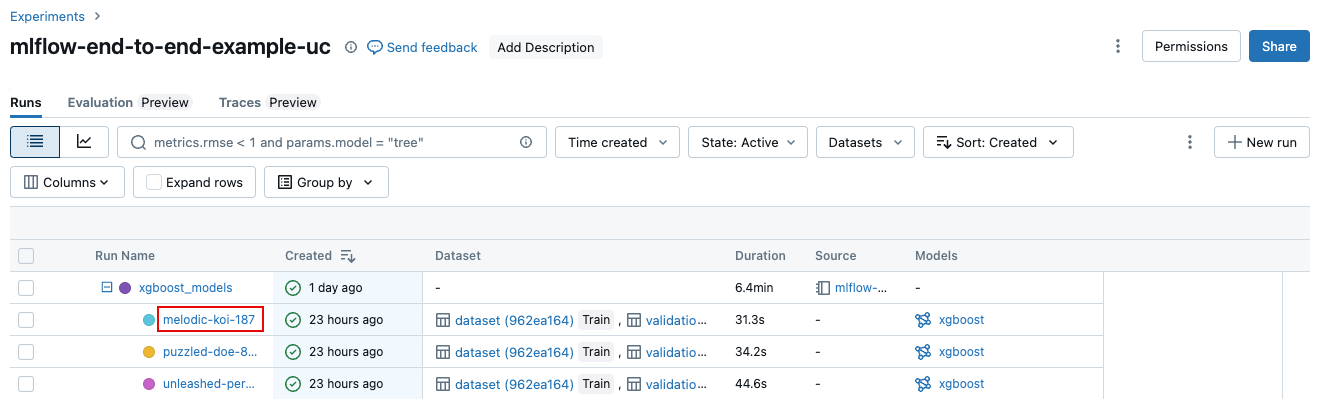
노트북에서 실험 실행 사이드바의 실행 이름을 클릭합니다.

실행 화면은 실행에 사용된 매개변수, 실행 결과로 나타난 메트릭, 그리고 원본 노트북에 대한 링크를 포함한 실행 세부 정보를 표시합니다. 실행에서 저장된 아티팩트가 아티팩트 탭에서 사용할 수 있습니다.
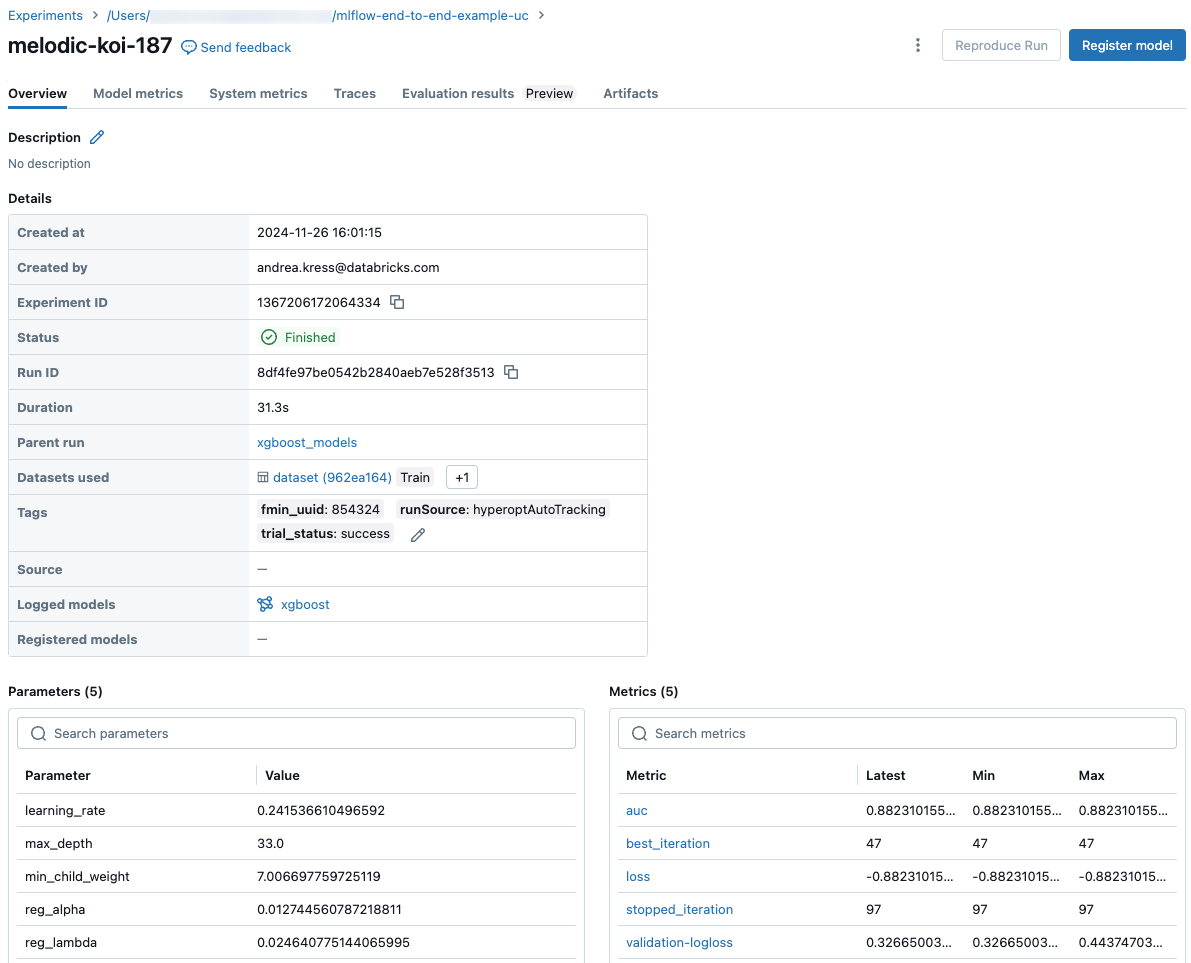
예측을 위한 코드 조각
실행에서 모델을 기록하면 모델을 로드하고 사용하여 Spark 및 Pandas DataFrames에 대한 예측을 만드는 방법을 보여 주는 코드 조각과 함께 아티팩트 탭에 모델이 표시됩니다.
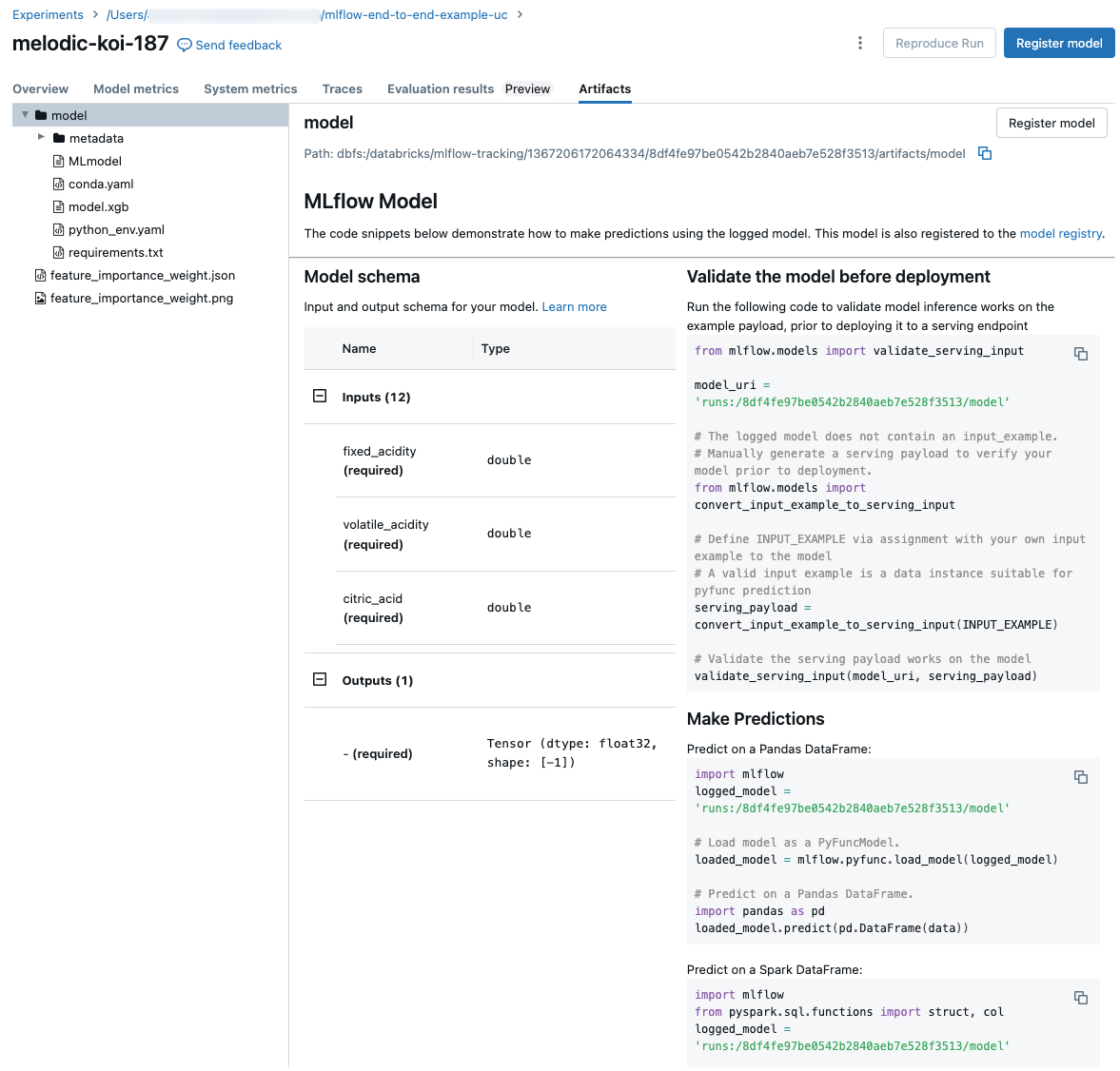
실행에 사용된 노트북 보기
실행을 만든 Notebook 버전을 보려면 다음 단계를 따릅니다.
- 실험 세부 정보 페이지에서 원본 열의 링크를 클릭합니다.
- 실행 페이지에서 원본 옆에 있는 링크를 클릭합니다.
- Notebook의 실험 실행 사이드바에서 해당 실험 실행 상자의 Notebook 아이콘(
 )을 클릭합니다.
)을 클릭합니다.
실행과 관련된 Notebook 버전이 실행 날짜와 시간을 표시하는 강조 표시줄과 함께 주 창에 나타납니다.
실행에 태그 추가
태그는 나중에 실행을 검색하기 위해 만들고 사용할 수 있는 키-값 쌍입니다.
세부 정보 테이블이 있는 실행 페이지에서 태그옆에 있는 추가를 클릭합니다.

태그 추가/편집 대화 상자가 열립니다.
키 필드에 키의 이름을 입력하고,태그 추가를 클릭합니다. 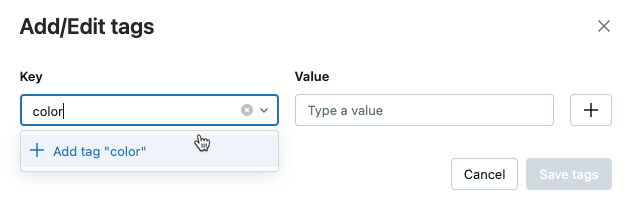
값 필드에 태그의 값을 입력합니다.
더하기 기호를 클릭하여 방금 입력한 키-값 쌍을 저장합니다.
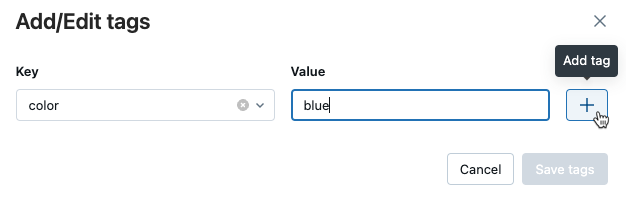
태그를 추가하려면 2~4단계를 반복합니다.
완료되면 태그 저장
클릭합니다.
실행에 대한 태그 편집 또는 삭제
실행 페이지세부 정보 테이블에서, 기존 태그 옆에 있는
.

태그 추가/편집 대화 상자가 열립니다.
태그를 삭제하려면 해당 태그에서 X를 클릭합니다.
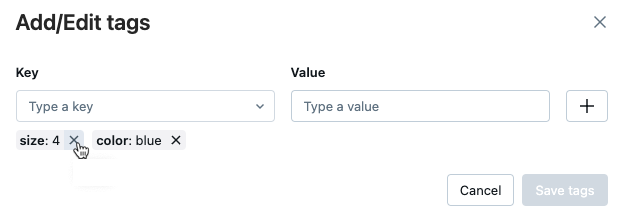
태그를 편집하려면 드롭다운 메뉴에서 키를 선택하고 값 필드에서 값을 편집합니다. 더하기 기호를 클릭하여 변경 내용을 저장합니다.
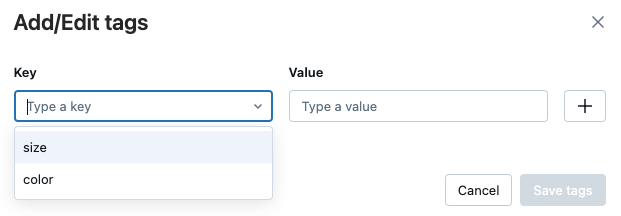
완료되면 태그 저장을 클릭합니다.
실행의 소프트웨어 환경을 재현
실행 페이지 오른쪽 위에 있는 실행 재현을 클릭하면 실행의 정확한 소프트웨어 환경을 재현할 수 있습니다. 다음과 같은 대화 상자가 나타납니다.
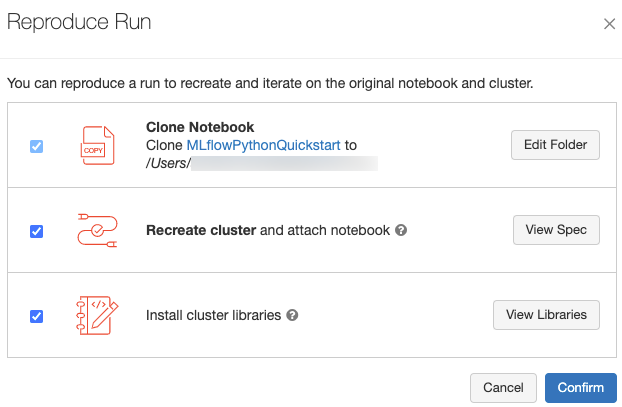
기본 설정에서 확인을 클릭하면:
- Notebook이 대화 상자에 표시된 위치에 복제됩니다.
- 원래 클러스터가 여전히 존재하는 경우 복제된 Notebook이 원래 클러스터에 연결되고 클러스터가 시작됩니다.
- 원래 클러스터가 더 이상 존재하지 않으면 설치된 라이브러리를 포함하여 동일한 구성의 새 클러스터가 만들어지고 시작됩니다. Notebook이 새 클러스터에 연결됩니다.
복제된 Notebook에 대해 다른 위치를 선택하고 클러스터 구성 및 설치된 라이브러리를 검사할 수 있습니다.
- 복제된 Notebook을 저장할 다른 폴더를 선택하려면 폴더 편집을 클릭합니다.
- 클러스터 사양을 보려면 사양 보기를 클릭합니다. 클러스터가 아닌 Notebook만 복제하려면 이 옵션을 선택 취소합니다.
- 원래 클러스터가 더 이상 존재하지 않는 경우 라이브러리 보기
클릭하여 원래 클러스터에 설치된 라이브러리를 볼 수 있습니다. 원래 클러스터가 여전히 있는 경우 이 섹션은 회색으로 표시됩니다.
실행 이름 바꾸기
실행 이름을 바꾸려면 실행 페이지의 오른쪽 위 모서리(
표시할 열 선택
실험 세부 정보 페이지의 실행 테이블에 표시되는 열을 제어하려면 열 클릭하고 드롭다운 메뉴에서 선택합니다.
필터 실행
매개 변수 또는 메트릭 값을 기반으로 실험 세부 정보 페이지의 테이블에서 실행을 검색할 수 있습니다. 태그로 실행을 검색할 수도 있습니다.
매개 변수 및 메트릭 값이 포함된 식과 일치하는 실행을 검색하려면 검색 필드에 쿼리를 입력하고 Enter 키를 누릅니다. 몇 가지 쿼리 구문 예는 다음과 같습니다.
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1기본적으로 메트릭 값은 마지막으로 로깅된 값을 기준으로 필터링됩니다.
MIN또는MAX를 사용하면 각각 최소 또는 최대 메트릭 값을 기준으로 실행을 검색할 수 있습니다. 2024년 8월 이후에 로깅된 실행에만 최소 및 최대 메트릭 값이 있습니다.태그로 실행을 검색하려면
tags.<key>="<value>"형식으로 태그를 입력합니다. 문자열 값은 표시된 대로 따옴표로 묶어야 합니다.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5키와 값 모두 공백을 포함할 수 있습니다. 키에 공백이 포함된 경우 그림과 같이 백틱으로 묶어야 합니다.
tags.`my custom tag` = "my value"
또한 해당 상태(활성 또는 삭제됨), 실행이 만들어진 시기 및 사용된 데이터 세트를 기준으로 실행을 필터링할 수 있습니다. 이렇게 하려면 각각 시간 생성, 상태, 또는 데이터 세트의 드롭다운 메뉴에서 선택합니다.
다운로드 실행
다음과 같이 실험 세부 정보 페이지에서 실행을 다운로드할 수 있습니다.
 클릭하여 케밥 메뉴를 엽니다.
클릭하여 케밥 메뉴를 엽니다.
표시된 실행(최대 100개)을 모두 포함하는 CSV 형식의 파일을 다운로드하려면 다운로드
<n>실행을(를) 선택하세요. MLflow는 각 실행에 대해 다음 필드를 포함하는 행당 하나의 실행이 있는 파일을 만들고 다운로드합니다.Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ...100개 이상의 실행을 다운로드하거나 프로그래밍 방식으로 실행을 다운로드하려면 모든 실행 다운로드선택합니다. 전자 필기장에서 복사하거나 열 수 있는 코드 조각을 보여 주는 대화 상자가 열립니다. Notebook 셀에서 이 코드를 실행한 후 셀 출력에서 모든 행 다운로드를 선택합니다.
실행 삭제
다음 단계에 따라 실험 세부 정보 페이지에서 실행을 삭제할 수 있습니다.
- 실험에서 실행 왼쪽에 있는 확인란을 클릭하여 하나 이상의 실행을 선택합니다.
- 삭제를 클릭합니다.
- 실행이 부모 실행인 경우 하위 실행도 삭제할지 여부를 결정합니다. 이 옵션은 기본적으로 선택되어 있습니다.
- 삭제를 클릭하여 확인합니다. 삭제된 실행은 30일 동안 저장됩니다. 삭제된 실행을 표시하려면 상태 필드에서 삭제됨을 선택합니다.
생성 시간에 따라 대량 삭제 실행
Python을 사용하여 UNIX 타임스탬프 이전에 또는 UNIX 타임스탬프에 만든 실험의 실행을 대량 삭제할 수 있습니다.
Databricks Runtime 14.1 이상을 사용하여 API를 mlflow.delete_runs 호출하면 실행을 삭제하고 삭제된 실행 수를 반환할 수 있습니다.
mlflow.delete_runs 매개 변수는 다음과 같습니다.
-
experiment_id: 삭제할 실행을 포함하는 실험의 ID입니다. -
max_timestamp_millis: 삭제를 위한 UNIX Epoch 이후의 최대 생성 타임스탬프(밀리초)입니다. 이 타임스탬프 이전 또는 시간에 만든 실행만 삭제됩니다. -
max_runs:선택적. 삭제할 최대 실행 수를 나타내는 양의 정수입니다. max_runs의 허용되는 최대값은 10000입니다. 지정하지 않으면max_runs의 기본값은 10000입니다.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Databricks Runtime 13.3 LTS 이하를 사용하여 Azure Databricks Notebook에서 다음 클라이언트 코드를 실행할 수 있습니다.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
생성 시간에 따라 실행을 삭제하기 위한 매개 변수 및 반환 값 사양은 Azure Databricks 실험 API 설명서를 참조하세요.
복원 실행
다음과 같이 이전에 삭제된 실행을 UI에서 복원할 수 있습니다.
- 실험 페이지의 상태 필드에서 삭제된을 선택하여 삭제된 실행을 표시합니다.
- 실행 왼쪽에 있는 확인란을 클릭하여 하나 이상의 실행을 선택합니다.
- 복원을 클릭합니다.
- 복원을 클릭하여 확인합니다. 이제 상태 필드에서 활성 선택하면 복원된 실행이 표시됩니다.
삭제 시간에 따라 대량 복원 실행
Python을 사용하여 UNIX 타임스탬프 또는 그 이후에 삭제된 실험의 실행을 대량 복원할 수도 있습니다.
Databricks Runtime 14.1 이상을 사용하여 mlflow.restore_runs API를 호출하여 실행을 복원하고 복원된 실행 수를 반환할 수 있습니다.
mlflow.restore_runs 매개 변수는 다음과 같습니다.
-
experiment_id: 복원할 실행을 포함하는 실험의 ID입니다. -
min_timestamp_millis: 실행 복원을 위한 UNIX Epoch 이후 최소 삭제 타임스탬프(밀리초)입니다. 이 타임스탬프가 복원된 후 삭제된 실행만 있습니다. -
max_runs:선택적. 복원할 최대 실행 수를 나타내는 양의 정수입니다. max_runs의 허용되는 최대값은 10000입니다. 지정하지 않으면 max_runs의 기본값은 10000입니다.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Databricks Runtime 13.3 LTS 이하를 사용하여 Azure Databricks Notebook에서 다음 클라이언트 코드를 실행할 수 있습니다.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
삭제 시간에 따라 실행을 복원하기 위한 매개 변수 및 반환 값 사양은 Azure Databricks 실험 API 설명서를 참조하세요.
실행 비교
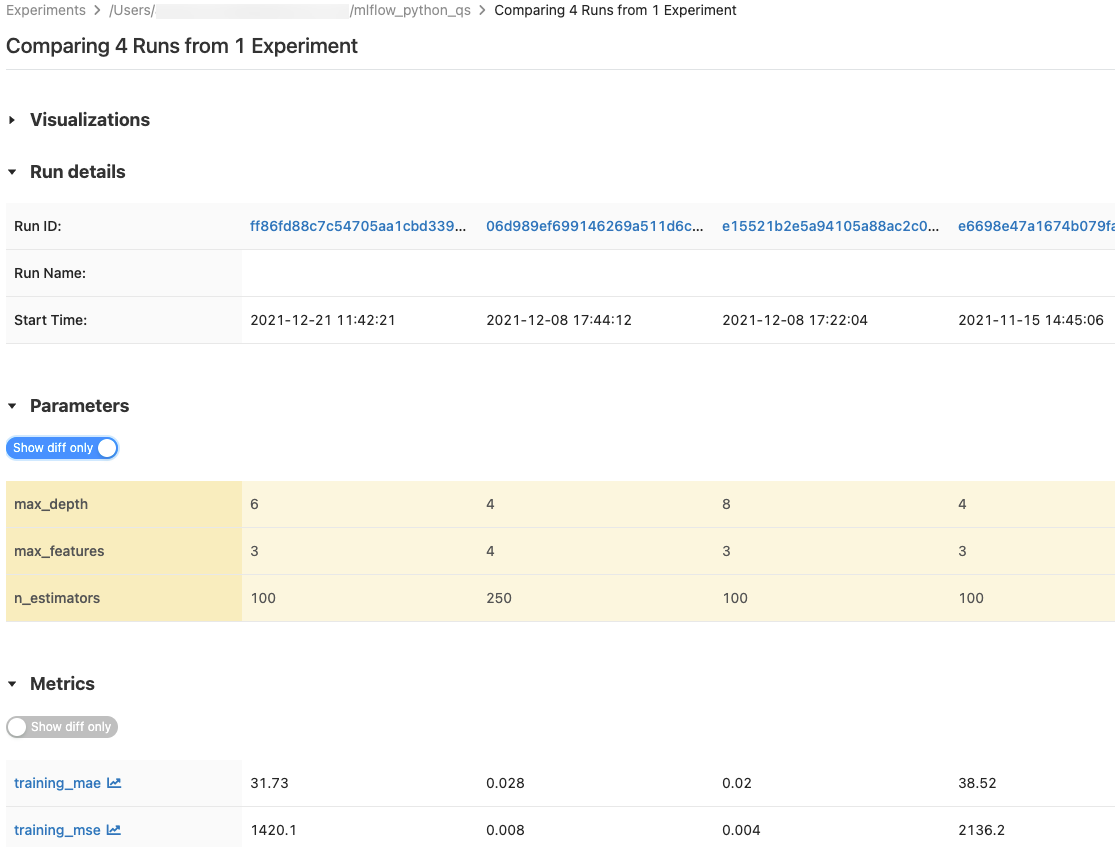
단일 실험 또는 여러 실험에서 실행을 비교할 수 있습니다. 실행 비교 페이지에는 선택한 실행에 대한 정보가 그래픽 및 테이블 형식으로 표시됩니다. 실행 결과 및 실행 정보 테이블, 실행 매개 변수 및 메트릭의 시각화를 생성할 수도 있습니다.
시각화를 만들려면:
- 플롯 형식(병렬 좌표 플롯, 산점도 또는 윤곽선 그림)을 선택합니다.
병렬 좌표 플롯의 경우 그릴 매개 변수 및 메트릭을 선택합니다. 여기에서 선택한 매개 변수와 메트릭 간의 관계를 식별할 수 있으므로 모델의 하이퍼 매개 변수 튜닝 공간을 더 잘 정의할 수 있습니다.
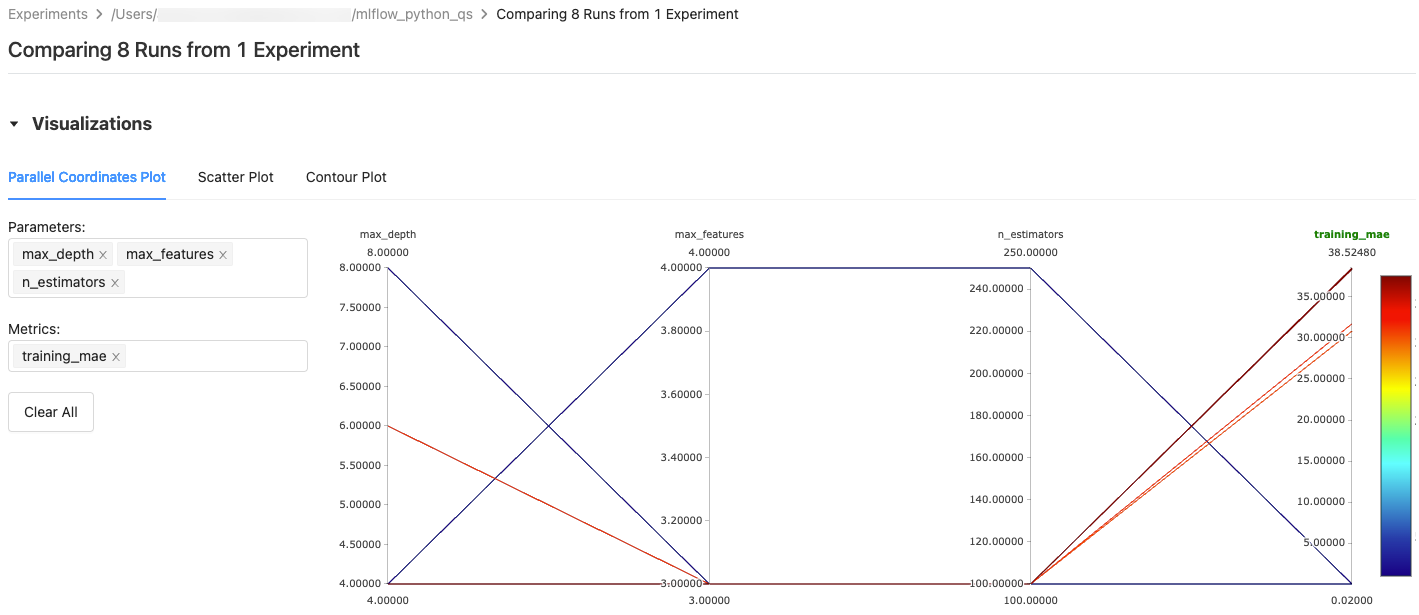
산점도 또는 윤곽선 그림의 경우 각 축에 표시할 매개 변수 또는 메트릭을 선택합니다.
매개 변수 및 메트릭 테이블에는 선택한 모든 실행의 실행 매개 변수 및 메트릭이 표시됩니다. 이러한 테이블의 열은 바로 위의 실행 세부 정보 테이블에 의해 식별됩니다. 간단히 하기 위해  를 토글하여 선택한 모든 실행에서 동일한 매개 변수 및 메트릭을 숨길 수 있습니다.
를 토글하여 선택한 모든 실행에서 동일한 매개 변수 및 메트릭을 숨길 수 있습니다.
단일 실험에서 실행 비교
- 실험 세부 정보 페이지에서, 실행의 왼쪽에 있는 확인란을 클릭하여 두 개 이상의 실행을 선택하거나, 열 맨 위에 있는 확인란을 선택하여 모든 실행을 선택합니다.
-
비교를 클릭합니다.
<N>실행 비교 화면이 표시됩니다.
여러 실험에서 실행 비교
- 실험 페이지에서 실험 이름 왼쪽에 있는 상자를 클릭하여 비교할 실험을 선택합니다.
- 비교(n)를 클릭합니다(n은 선택한 실험 수). 선택한 실험의 모든 실행을 보여 주는 화면이 나타납니다.
- 실행 왼쪽의 확인란을 클릭하여 두 개 이상의 실행을 선택하거나 열 맨 위에 있는 확인란을 선택하여 모든 실행을 선택합니다.
-
비교를 클릭합니다.
<N>실행 비교 화면이 표시됩니다.
작업 영역 간에 실행 복사
Databricks 작업 영역으로 또는 Databricks 작업 영역에서 MLflow 실행을 가져오거나 내보내려면 커뮤니티 기반 오픈 소스 프로젝트 MLflow Export-Import를 사용하면 됩니다.