적응 쿼리 실행
AQE(적응 쿼리 실행)는 쿼리 실행 중에 발생하는 쿼리 다시 최적화입니다.
런타임 다시 최적화가 수행된 계기는 Azure Databricks에서 순서 섞기 및 브로드캐스트 교환(AQE에서는 쿼리 단계라고 함)이 끝날 때 통계가 가장 정확하고 최신 상태이기 때문입니다. 따라서 Azure Databricks는 더 나은 물리적 전략을 선택하거나, 최적의 순서 섞기 후 파티션 크기 및 수를 선택하거나, 힌트를 요구하는 데 사용되는 최적화(예: 기울이기 조인 처리)를 수행할 수 있습니다.
이는 통계 수집이 켜져 있지 않거나 통계가 부실한 경우 매우 유용할 수 있습니다. 또한 복잡한 쿼리 도중 또는 데이터 기울이기 발생 후와 같이 정적으로 파생된 통계가 부정확한 경우에도 유용합니다.
기능
AQE는 기본적으로 사용하도록 설정됩니다. 다음과 같은 4가지 주요 기능이 있습니다.
- 정렬 병합 조인을 브로드캐스트 해시 조인으로 동적으로 변경합니다.
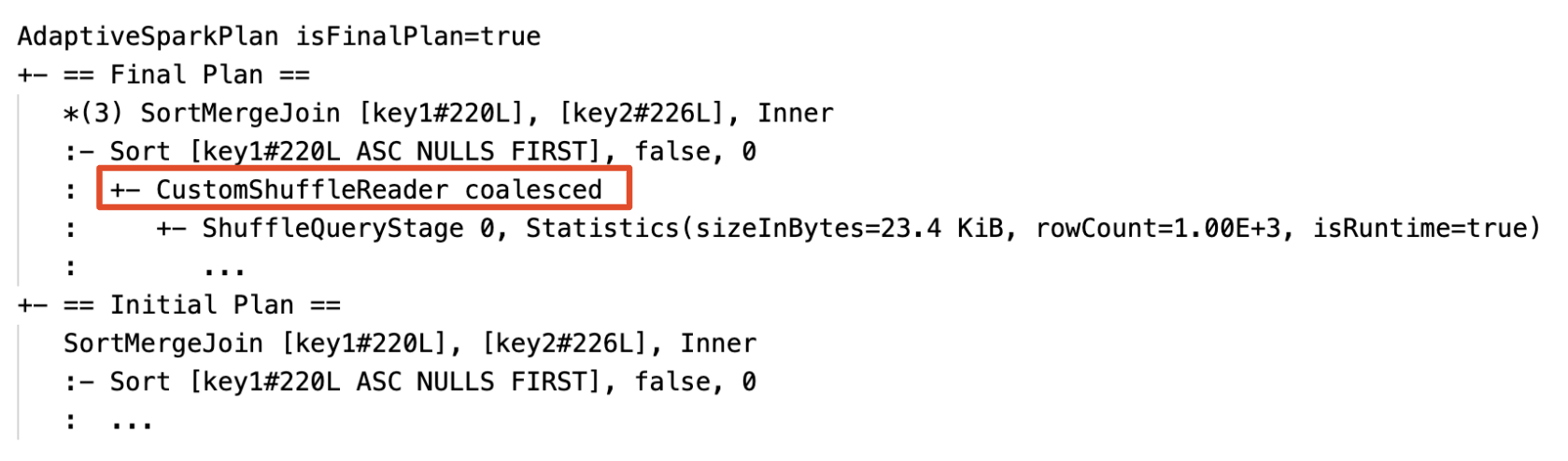
- 순서 섞기 교환 후 파티션을 동적으로 병합합니다(작은 파티션을 적절한 크기의 파티션으로 결합). 매우 작은 작업은 I/O 처리량을 악화시키고 예약 오버헤드 및 작업 설정 오버헤드로 인한 부담이 더 큰 경향이 있습니다. 작은 작업을 결합하면 리소스가 절약되고 클러스터 처리량이 향상됩니다.
- 정렬 병합 조인 및 순서 섞기 해시 조인에서 기울어진 작업을 대략 균등하게 크기가 조정된 작업으로 분할(필요한 경우 복제)하여 기울이기를 동적으로 처리합니다.
- 빈 관계를 동적으로 감지하고 전파합니다.
애플리케이션
AQE는 다음과 같은 모든 쿼리에 적용됩니다.
- 비스트리밍
- 하나 이상의 교환(일반적으로 조인, 집계 또는 창이 있는 경우), 하나의 하위 쿼리 또는 둘 다를 포함합니다.
모든 AQE 적용 쿼리가 반드시 다시 최적화되는 것은 아닙니다. 다시 최적화는 정적으로 컴파일된 쿼리 계획과 다른 쿼리 계획을 만들 수도 있고 그렇지 않을 수도 있습니다. AQE에서 쿼리 계획을 변경했는지 여부를 확인하려면 다음 섹션 쿼리 계획을 참조하세요.
쿼리 계획
이 섹션에서는 다양한 방법으로 쿼리 계획을 살펴보는 방법을 설명합니다.
이 섹션의 내용:
Spark UI
AdaptiveSparkPlan 노드
AQE 적용 쿼리에는 일반적으로 각 주 쿼리 또는 하위 쿼리의 루트 노드로 하나 이상의 AdaptiveSparkPlan 노드가 포함됩니다.
쿼리가 실행되기 전 또는 실행 중일 때는 해당 AdaptiveSparkPlan 노드의 isFinalPlan 플래그가 false로 표시됩니다. 쿼리 실행이 완료되면 isFinalPlan 플래그가 true.로 변경됩니다.
진화하는 계획
쿼리 계획 다이어그램은 실행이 진행됨에 따라 진화하고 실행 중인 최신 계획을 반영합니다. 이미 실행된 노드(메트릭을 사용할 수 있음)는 변경되지 않지만 다시 최적화의 결과로 시간이 지남에 따라 변경할 수 없는 노드는 변경되지 않습니다.
다음은 쿼리 계획 다이어그램 예제입니다.
DataFrame.explain()
AdaptiveSparkPlan 노드
AQE 적용 쿼리에는 일반적으로 각 주 쿼리 또는 하위 쿼리의 루트 노드로 하나 이상의 AdaptiveSparkPlan 노드가 포함됩니다. 쿼리가 실행되기 전 또는 실행 중일 때는 해당 AdaptiveSparkPlan 노드의 isFinalPlan 플래그가 false로 표시됩니다. 쿼리 실행이 완료되면 isFinalPlan 플래그가 true로 변경됩니다.
현재 및 초기 계획
각 AdaptiveSparkPlan 노드에는 실행이 완료되었는지 여부에 따라 초기 계획(AQE 최적화를 적용하기 전의 계획)과 현재 또는 최종 계획이 모두 있습니다. 현재 계획은 실행이 진행됨에 따라 진화합니다.
런타임 통계
각 순서 섞기 및 브로드캐스트 단계에는 데이터 통계가 포함됩니다.
스테이지가 실행되기 전이나 스테이지가 실행 중일 때 통계는 컴파일 시간 추정치이며 플래그 isRuntime은 false입니다(예: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);).
스테이지 실행이 완료된 후 통계는 런타임에 수집된 통계이며 플래그 isRuntime은 true가 됩니다(예: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)).
다음은 DataFrame.explain 예제입니다.
실행 전
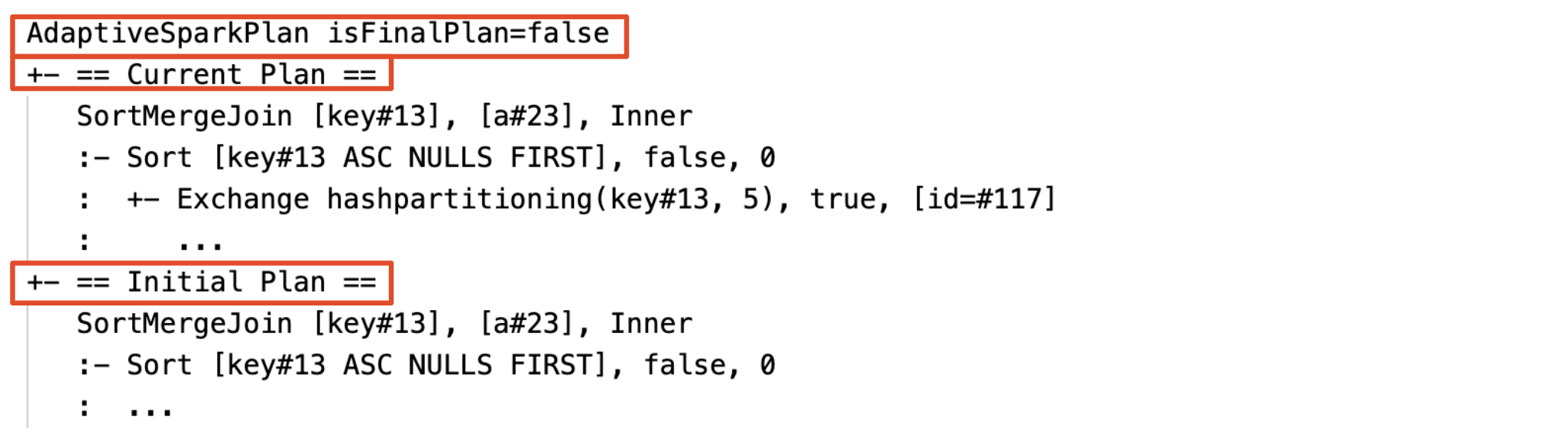
실행 중
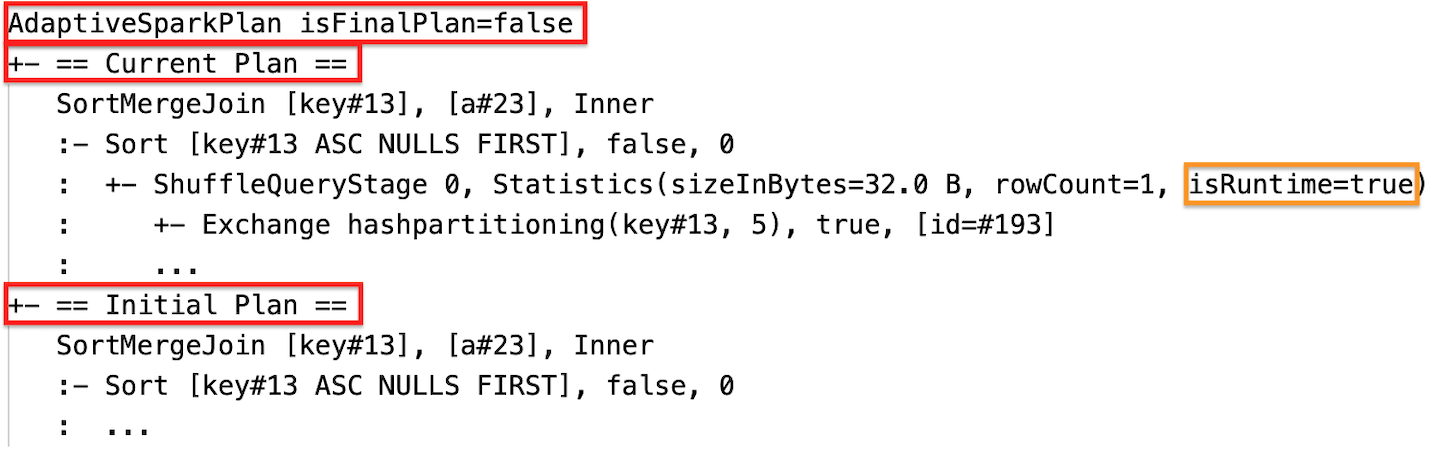
실행 후
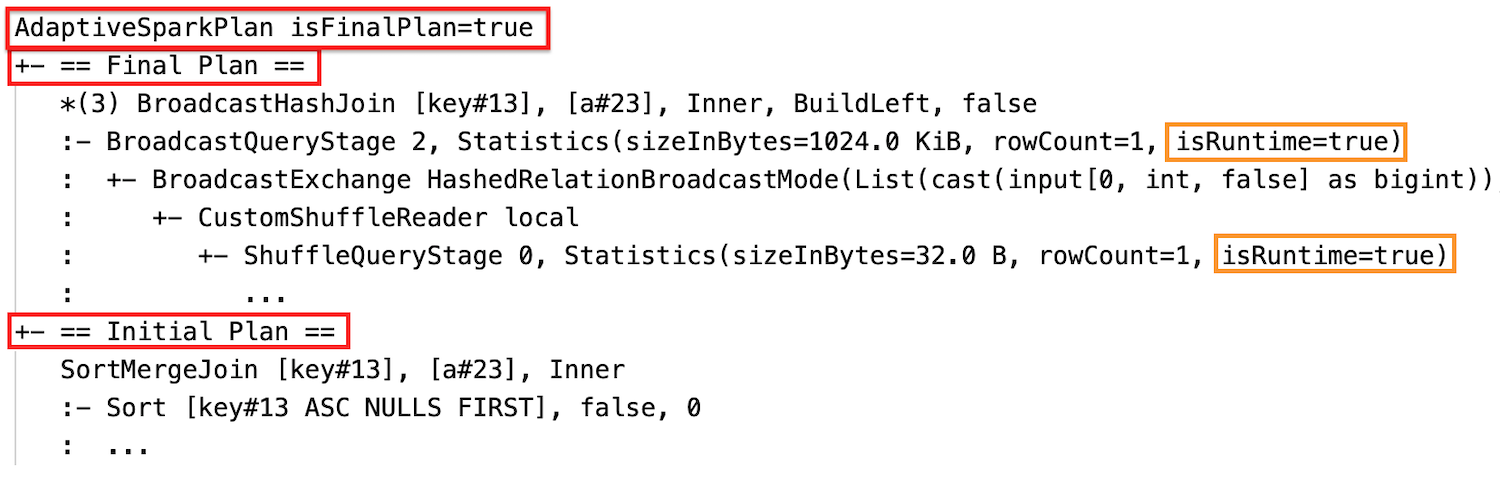
SQL EXPLAIN
AdaptiveSparkPlan 노드
AQE 적용 쿼리에는 일반적으로 각 주 쿼리 또는 하위 쿼리의 루트 노드로 하나 이상의 AdaptiveSparkPlan 노드가 포함됩니다.
현재 계획 없음
SQL EXPLAIN에서 쿼리를 실행하지 않으므로 현재 계획은 항상 초기 계획과 동일하며 AQE에서 결과적으로 실행하는 것을 반영하지 않습니다.
다음은 SQL explain 예제입니다.

효과
하나 이상의 AQE 최적화가 적용되는 경우 쿼리 계획이 변경됩니다. 이러한 AQE 최적화의 효과는 현재 및 최종 계획과 초기 계획 그리고 현재 계획과 최종 계획의 초기 계획 노드와 특정 계획 노드 간의 차이로 입증됩니다.
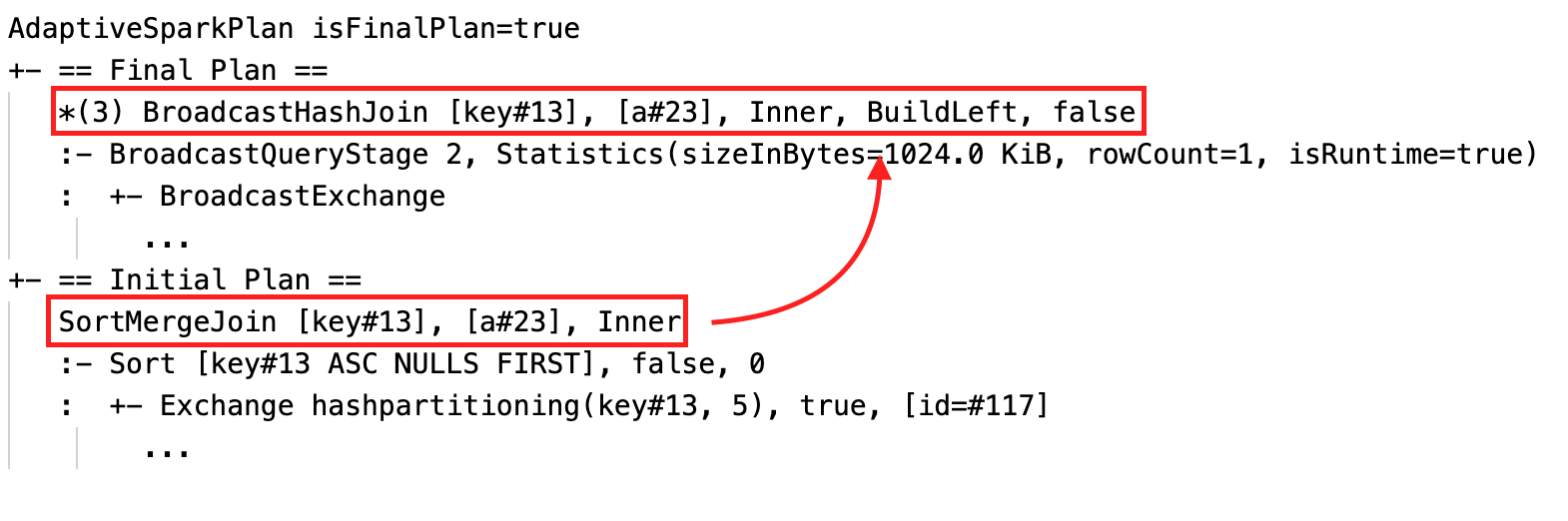
정렬 병합 조인을 브로드캐스트 해시 조인으로 동적으로 변경: 현재/최종 계획과 초기 계획 간의 서로 다른 물리적 조인 노드
동적으로 파티션 병합:
Coalesced속성을 가진 노드CustomShuffleReader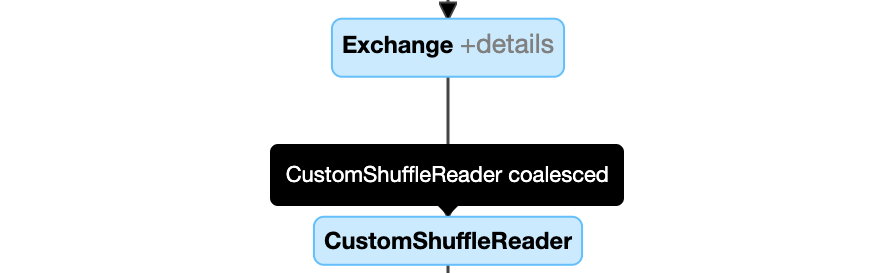
기울이기 조인을 동적으로 처리: 필드
isSkew가 true인 노드SortMergeJoin.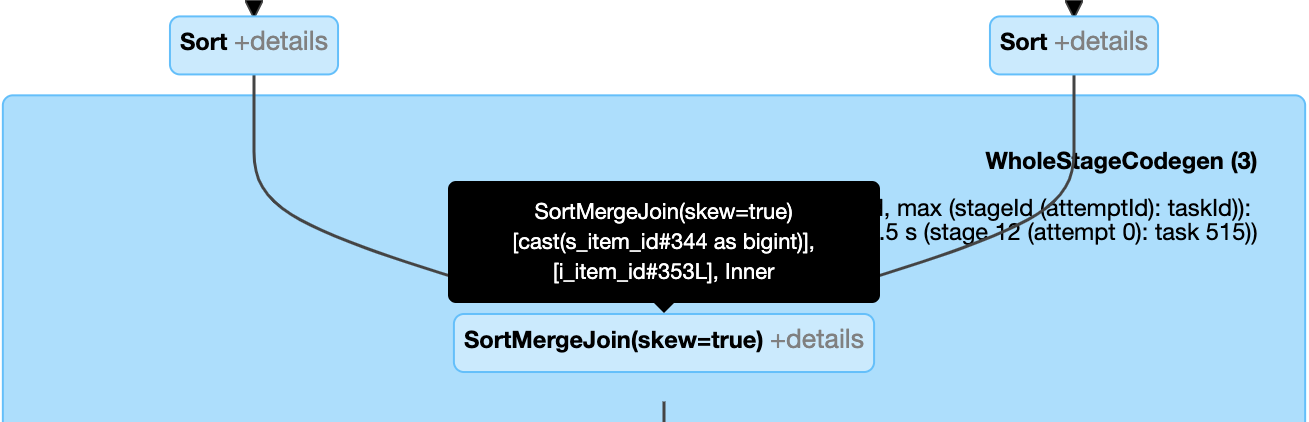
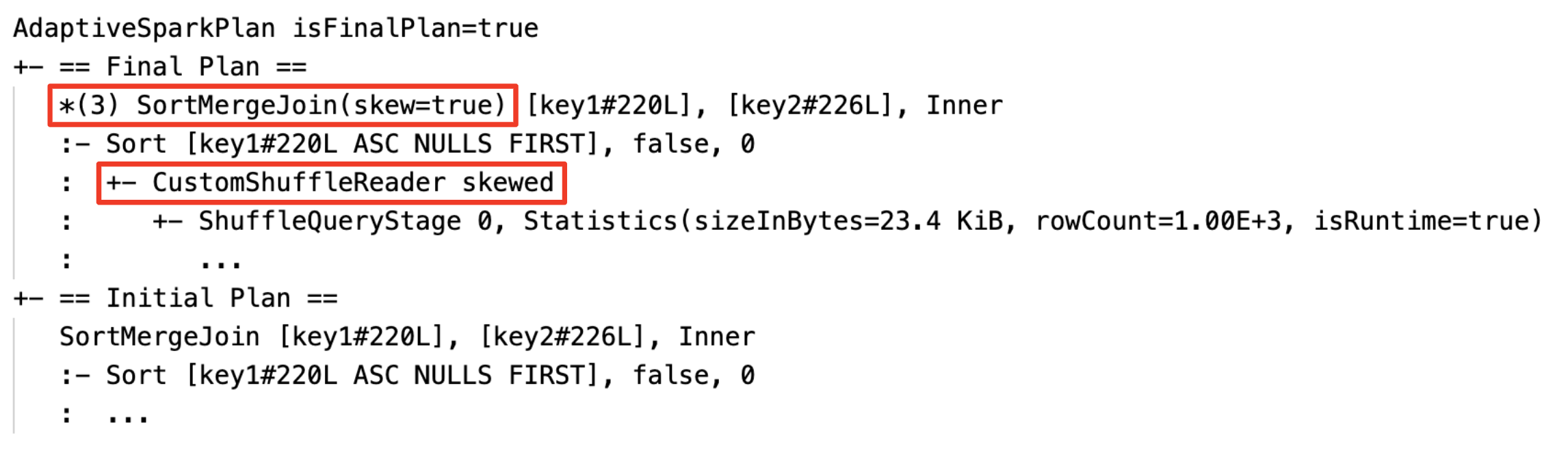
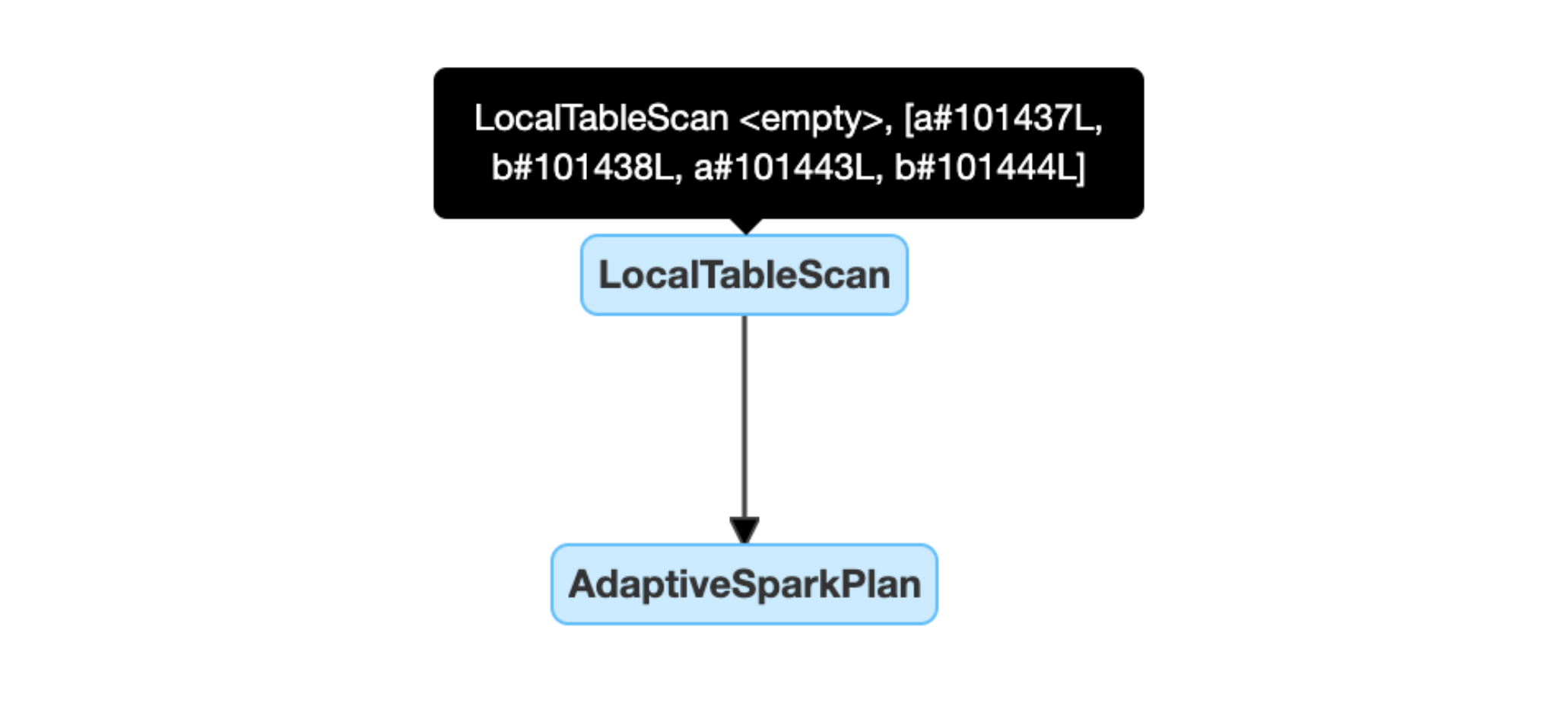
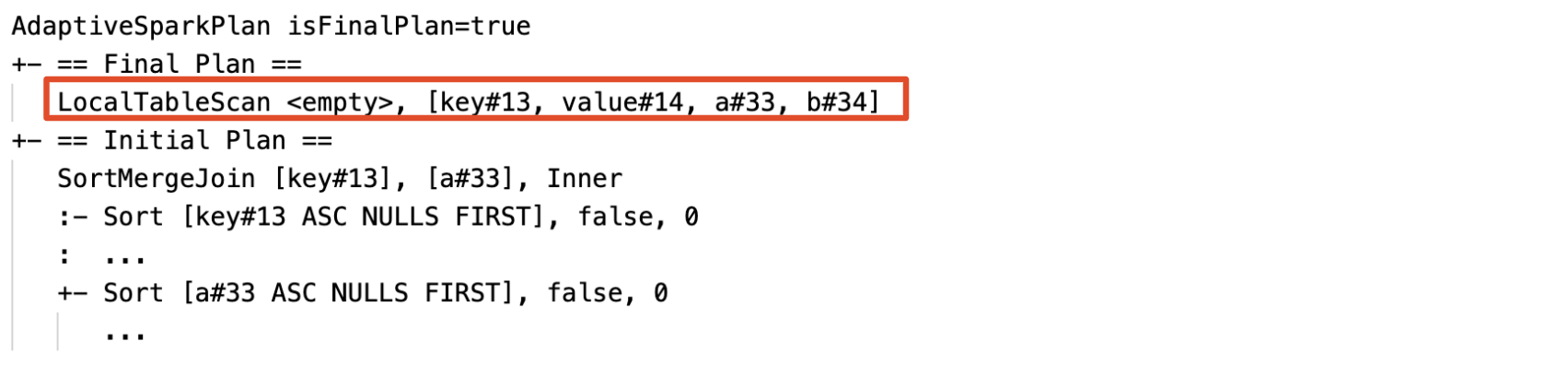
빈 관계를 동적으로 검색하고 전파: 계획의 일부(또는 전체)가 LocalTableScan 노드(관계 필드가 비어 있음)로 대체됩니다.
구성
이 섹션의 내용:
- 적응 쿼리 실행 사용 및 사용 안 함
- 자동 최적화 순서 섞기 사용
- 정렬 병합 조인을 브로드캐스트 해시 조인으로 동적으로 변경
- 동적으로 파티션 병합
- 동적으로 기울이기 조인 처리
- 빈 관계를 동적으로 검색 및 전파
적응 쿼리 실행 사용 및 사용 안 함
| 속성 |
|---|
| spark.databricks.optimizer.adaptive.enabled 유형: Boolean적응 쿼리 실행을 사용하거나 사용하지 않도록 설정할지 여부입니다. 기본값: true |
자동 최적화 순서 섞기 사용
| 속성 |
|---|
| spark.sql.shuffle.partitions 유형: Integer조인 또는 집계에 대한 데이터를 섞을 때 사용할 기본 파티션 수입니다. 값을 auto 설정하면 자동 최적화 순서 섞기가 가능하며, 쿼리 계획 및 쿼리 입력 데이터 크기에 따라 이 숫자가 자동으로 결정됩니다.참고: 구조적 스트리밍의 경우 동일한 검사 지점 위치에서 쿼리를 다시 시작하는 사이에 이 구성을 변경할 수 없습니다. 기본값: 200 |
정렬 병합 조인을 브로드캐스트 해시 조인으로 동적으로 변경
| 속성 |
|---|
| spark.databricks.adaptive.autoBroadcastJoinThreshold 유형: Byte String런타임에 브로드캐스트 조인으로의 전환을 트리거하는 임계값입니다. 기본값: 30MB |
동적으로 파티션 병합
| 속성 |
|---|
| spark.sql.adaptive.coalescePartitions.enabled 유형: Boolean파티션 병합을 사용하거나 사용하지 않도록 설정할지 여부입니다. 기본값: true |
| spark.sql.adaptive.advisoryPartitionSizeInBytes 유형: Byte String병합 후의 대상 크기입니다. 병합된 파티션 크기는 이 대상 크기에 가깝지만 더 크지는 않습니다. 기본값: 64MB |
| spark.sql.adaptive.coalescePartitions.minPartitionSize 유형: Byte String병합 후 파티션의 최소 크기입니다. 병합된 파티션 크기는 이 크기보다 작지 않습니다. 기본값: 1MB |
| spark.sql.adaptive.coalescePartitions.minPartitionNum 유형: Integer병합 후 파티션의 최소 수입니다. 명시적으로 설정하면 재정의되므로 권장되지 않습니다. spark.sql.adaptive.coalescePartitions.minPartitionSize.기본값: 클러스터 코어 수의 2배 |
동적으로 기울이기 조인 처리
| 속성 |
|---|
| spark.sql.adaptive.skewJoin.enabled 유형: Boolean기울이기 조인 처리를 사용하거나 사용하지 않도록 설정할지 여부입니다. 기본값: true |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor 유형: Integer중앙값 파티션 크기를 곱할 경우 파티션이 기울어지는지 여부를 결정하는 데 기여하는 인자입니다. 기본값: 5 |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 유형: Byte String파티션이 기울어지는지 여부를 결정하는 데 기여하는 임계값입니다. 기본값: 256MB |
파티션은 (partition size > skewedPartitionFactor * median partition size) 및 (partition size > skewedPartitionThresholdInBytes)가 둘 다 true일 때 기울어진 것으로 간주됩니다.
빈 관계를 동적으로 검색 및 전파
| 속성 |
|---|
| spark.databricks.adaptive.emptyRelationPropagation.enabled 유형: Boolean동적 빈 관계 전파를 사용하거나 사용하지 않도록 설정할지 여부입니다. 기본값: true |
질문과 대답(FAQ)
이 섹션의 내용:
- AQE가 작은 조인 테이블을 브로드캐스트하지 않은 이유는 무엇인가요?
- AQE가 사용하도록 설정된 브로드캐스트 조인 전략 힌트를 계속 사용해야 하나요?
- 기울이기 조인 힌트와 AQE 기울이기 조인 최적화의 차이점은 무엇인가요? 어떤 것을 사용해야 하나요?
- AQE에서 조인 순서를 자동으로 조정하지 않은 이유는 무엇인가요?
- AQE에서 내 데이터 기울이기를 감지하지 못한 이유는 무엇인가요?
AQE가 작은 조인 테이블을 브로드캐스트하지 않은 이유는 무엇인가요?
브로드캐스트되어야 하는 관계의 크기가 이 임계값에 미치지 못하지만 여전히 브로드캐스트되지 않는 경우:
- 조인 유형을 확인하세요. 특정 조인 유형에는 브로드캐스트가 지원되지 않습니다. 예를 들어
LEFT OUTER JOIN의 왼쪽 관계는 브로드캐스트할 수 없습니다. - 또한 관계에 많은 빈 파티션이 포함되어 있을 수 있습니다. 이 경우 대부분의 작업이 정렬 병합 조인으로 빠르게 완료되거나 기울이기 조인 처리로 최적화될 수 있습니다. 비어 있지 않은 파티션의 비율이
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin보다 낮은 경우 AQE는 이러한 정렬 병합 조인을 브로드캐스트 해시 조인으로 변경하지 않습니다.
AQE가 사용하도록 설정된 브로드캐스트 조인 전략 힌트를 계속 사용해야 하나요?
예. 정적으로 계획된 브로드캐스트 조인은 일반적으로 AQE에서 동적으로 계획한 브로드캐스트 조인보다 성능이 더 높습니다. AQE는 조인의 양쪽에 대해 순서 섞기를 완료할 때까지(실제 관계 크기를 얻을 때까지) 브로드캐스트 조인으로 전환되지 않을 수 있습니다. 따라서 쿼리를 잘 알고 있는 경우에도 브로드캐스트 힌트를 사용하는 것이 좋습니다. AQE는 정적 최적화와 동일한 방식으로 쿼리 힌트를 반영하지만 힌트의 영향을 받지 않는 동적 최적화를 적용할 수 있습니다.
기울이기 조인 힌트와 AQE 기울이기 조인 최적화의 차이점은 무엇인가요? 어떤 것을 사용해야 하나요?
AQE 기울이기 조인은 완전히 자동이며 일반적으로 기울이기 조인 힌트보다 성능이 더 높으므로 기울이기 조인 힌트를 사용하는 대신 AQE 기울이기 조인 처리를 사용하는 것이 좋습니다.
AQE에서 조인 순서를 자동으로 조정하지 않은 이유는 무엇인가요?
동적 조인 다시 정렬은 AQE의 일부가 아닙니다.
AQE에서 내 데이터 기울이기를 감지하지 못한 이유는 무엇인가요?
AQE에서 파티션이 기울어진 파티션으로 감지되려면 두 가지 크기 조건을 충족해야 합니다.
- 파티션 크기가
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(기본값 256MB)보다 커야 합니다. - 파티션 크기가 모든 파티션의 중앙값 크기에 기울어진 파티션 계수
spark.sql.adaptive.skewJoin.skewedPartitionFactor(기본값 5)를 곱한 값보다 커야 합니다.
또한 특정 조인 유형에는 기울이기 처리 지원이 제한됩니다. 예를 들어 LEFT OUTER JOIN에서는 왼쪽의 기울이기만 최적화할 수 있습니다.
레거시
"적응 실행"이라는 용어는 Spark 1.6 이후로 존재했지만 Spark 3.0의 새 AQE는 근본적으로 다릅니다. 기능 측면에서 Spark 1.6은 "동적으로 파티션 병합" 부분만 수행합니다. 기술 아키텍처 측면에서 새로운 AQE는 런타임 통계를 기반으로 하는 쿼리를 동적으로 계획하고 계획하는 프레임워크로, 이 문서에서 설명한 것과 같은 다양한 최적화를 지원하며, 더 많은 잠재적 최적화를 지원하도록 확장될 수 있습니다.