Azure Databricks의 Shiny
Shiny는 CRAN에서 제공되는 R 패키지로, 대화형 R 애플리케이션과 대시보드를 빌드하는 데 사용됩니다. Azure Databricks 클러스터에서 호스트된 RStudio Server 내에서 Shiny를 사용할 수 있습니다. Azure Databricks Notebook에서 직접 Shiny 애플리케이션을 개발, 호스트, 공유할 수도 있습니다.
get Shiny를 시작하려면 자습서를 참조하세요. Azure Databricks Notebooks에서 이러한 자습서를 실행할 수 있습니다.
이 문서에서는 Azure Databricks에서 Shiny 애플리케이션을 실행하고 Shiny 애플리케이션 내에서 Apache Spark를 사용하는 방법을 설명합니다.
R Notebooks 내 Shiny
Shiny를 사용하여 R 노트북에서 시작한 Get
Shiny 패키지는 Databricks Runtime에 포함되어 있습니다. 호스트된 RStudio와 유사하게 Azure Databricks R Notebook 내에서 Shiny 애플리케이션을 대화형으로 개발하고 테스트할 수 있습니다.
get 시작하려면 다음 단계를 수행합니다.
R Notebook을 만듭니다.
Shiny 패키지를 가져오고 다음과 같이 예제 앱
01_hello를 실행합니다.library(shiny) runExample("01_hello")앱이 준비되면 출력에 Shiny 앱 URL이 새 탭을 여는 클릭 가능한 링크로 포함됩니다. 다른 사용자와 이 앱을 공유하려면 Shiny 앱 URL 공유를 참조하세요.

참고 항목
- 로그 메시지는 예제에 표시된 기본 로그 메시지(
Listening on http://0.0.0.0:5150)와 유사하게 명령 결과에 표시됩니다. - Shiny 애플리케이션을 중지하려면 취소를 클릭합니다.
- Shiny 애플리케이션은 Notebook R 프로세스를 사용합니다. 클러스터에서 Notebook을 분리하거나 애플리케이션을 실행하는 셀을 취소하면 Shiny 애플리케이션이 종료됩니다. Shiny 애플리케이션이 실행되는 동안에는 다른 셀을 실행할 수 없습니다.
Databricks Git 폴더에서 Shiny 앱 실행
Databricks Git 폴더에 체크 인 된 Shiny 앱을 실행할 수 있습니다.
애플리케이션을 실행합니다.
library(shiny) runApp("006-tabsets")
파일에서 Shiny 앱 실행
Shiny 애플리케이션 코드가 버전 제어로 관리되는 프로젝트의 일부인 경우 Notebook 내에서 실행할 수 있습니다.
참고 항목
절대 경로나 set 작업 디렉터리와 함께 setwd()을 사용해야 합니다.
다음과 유사한 코드를 사용하여 리포지토리에서 코드를 확인합니다.
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...애플리케이션을 실행하려면 다른 셀에서 다음과 유사한 코드를 입력합니다.
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Shiny 앱 URL 공유
앱을 시작할 때 생성된 Shiny 앱 URL은 다른 사용자와 공유할 수 있습니다. 클러스터에 대한 CAN ATTACH TO 권한을 가진 모든 Azure Databricks 사용자는 앱과 클러스터가 모두 실행되는 한 앱을 보고 상호 작용할 수 있습니다.
앱이 실행되는 클러스터가 종료되면 앱에 더 이상 액세스할 수 없습니다. 클러스터 설정에서 자동 종료를 사용하지 않도록 설정할 수 있습니다.
다른 클러스터에서 Shiny 앱을 호스트하는 Notebook을 연결하고 실행하면 Shiny URL이 변경됩니다. 또한 동일한 클러스터에서 앱을 다시 시작하는 경우 Shiny는 다른 임의의 포트를 선택할 수 있습니다. 안정적인 URL을 보장하려면 set 옵션을 shiny.port 사용할 수 있으며, 동일한 클러스터에서 앱을 다시 시작할 때는 port 인수를 지정할 수 있습니다.
호스트된 RStudio Server의 Shiny
요구 사항
Important
RStudio Server Pro에서 프록시 인증을 사용하지 않도록 설정해야 합니다.
auth-proxy=1 내부에 /etc/rstudio/rserver.conf이 없는지 확인합니다.
RStudio Server가 호스팅된 환경에서 Shiny와 함께 시작한 Get
Azure Databricks의 RStudio를 엽니다.
RStudio에서 Shiny 패키지를 가져오고 다음과 같이 예제 앱
01_hello를 실행합니다.> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203새로운 window이 나타나며 Shiny 애플리케이션을 표시합니다.
R 스크립트에서 Shiny 앱 실행
R 스크립트에서 Shiny 앱을 실행하려면 RStudio 편집기에서 R 스크립트를 열고 오른쪽 위에 있는 앱 실행 단추를 클릭합니다.
Shiny 앱 내에서 Apache Spark 사용
SparkR 또는 sparklyr을 사용하여 Shiny 애플리케이션 내에서 Apache Spark를 사용할 수 있습니다.
Notebook에서 Shiny와 함께 SparkR 사용
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Notebook에서 Shiny와 함께 sparklyr 사용
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
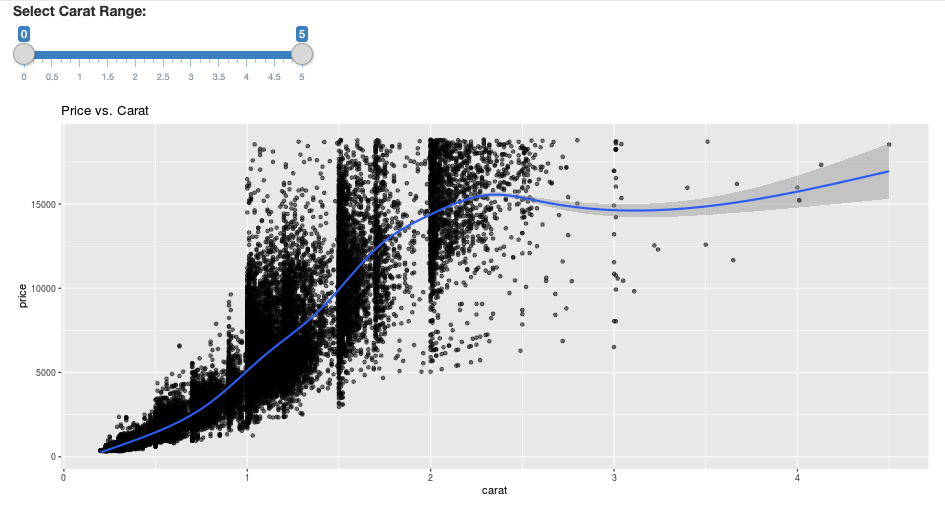
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
질문과 대답(FAQ)
- 일정 시간이 지난 후 Shiny 앱이 회색으로 표시되는 이유는 무엇인가요?
- 왜 내 Shiny 뷰어는 잠시 후에 사라지는 이유는 무엇인가요? window
- 긴 Spark 작업이 반환되지 않는 이유는 무엇인가요?
- 시간 초과를 방지하려면 어떻게 해야 하나요?
- 코드는 올바른 것 같은데 시작 직후에 앱이 작동 중단됩니다. 어떻게 된 것일까요?
- 개발하는 동안 하나의 Shiny 앱 링크에 대해 얼마나 많은 connections 수락할 수 있나요?
- Databricks Runtime에 설치된 버전과 다른 버전의 Shiny 패키지를 사용할 수 있나요?
- Shiny 서버에 게시되고 Azure Databricks의 데이터에 액세스할 수 있는 Shiny 애플리케이션을 개발하려면 어떻게 해야 하나요?
- Azure Databricks Notebook 내에서 Shiny 애플리케이션을 개발할 수 있나요?
- 호스트된 RStudio Server에서 개발한 Shiny 애플리케이션을 저장하려면 어떻게 해야 하나요?
일정 시간이 지난 후 Shiny 앱이 회색으로 표시되는 이유는 무엇인가요?
Shiny 앱을 조작하지 않으면 약 4분 후에 앱 연결이 닫힙니다.
Shiny 앱 페이지를 다시 연결하려면 refresh하십시오. 대시보드 상태가 초기화됩니다.
내 window Shiny 뷰어가 잠시 후에 사라지는 이유는 무엇인가요?
몇 분 동안 유휴 상태가 되면 Shiny 뷰어 window가 사라지는 것은 "회색 아웃" 시나리오와 동일한 시간 초과 때문입니다.
긴 Spark 작업이 반환되지 않는 이유는 무엇인가요?
이 문제도 유휴 시간 제한 때문입니다. 이전에 언급한 시간 제한보다 오래 실행되는 Spark 작업은 작업이 반환되기 전에 연결이 닫히므로 결과를 렌더링할 수 없습니다.
시간 초과를 방지하려면 어떻게 해야 하나요?
기능 요청에 권장되는 해결 방법이 있습니다. Github의 일부 부하 분산 장치에서 TCP 시간 제한을 방지하기 위해 클라이언트가 keep alive 메시지를 보내도록 합니다. 해결 방법은 하트비트를 전송하여 앱이 유휴 상태일 때 WebSocket 연결을 활성 상태로 유지하는 것입니다. 그러나 앱이 장기 실행 계산 때문에 차단된 경우 이 해결 방법은 효과가 없습니다.
Shiny는 장기 실행 작업을 지원하지 않습니다. Shiny 블로그 게시물에서는 promises 및 future를 사용하여 긴 작업을 비동기적으로 실행하고 앱을 차단 해제된 상태로 유지하도록 권장합니다. 다음은 하트비트를 사용하여 Shiny 앱 연결을 유지하고
future구문에서 장기 실행 Spark 작업을 실행하는 예제입니다.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages(‘future’) install.packages(‘promises’) library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)초기 페이지 로드 이후 12시간의 하드 limit 있으며, 활성 상태인 경우에도 연결이 종료됩니다. 이러한 경우 다시 연결하려면 Shiny 앱을 refresh 합니다. 그러나 기본 WebSocket 연결은 네트워크 불안정성 또는 컴퓨터 절전 모드를 비롯한 다양한 요인에 의해 언제든지 닫을 수 있습니다. Databricks는 수명이 긴 연결이 필요하지 않고 세션 상태에 지나치게 의존하지 않도록 Shiny 앱을 다시 작성할 것을 권장합니다.
코드는 올바른 것 같은데 시작 직후에 앱이 작동 중단됩니다. 어떻게 된 것일까요?
Azure Databricks의 Shiny 앱에 표시할 수 있는 총 데이터 양에는 50MB limit 있습니다. 애플리케이션의 총 데이터 크기가 이 limit초과하면 시작 직후 크래시가 발생합니다. 이 문제를 방지하려면 표시되는 데이터를 다운샘플링하거나 이미지 해상도를 줄이는 등 데이터 크기를 줄이는 것이 좋습니다.
개발 중에 하나의 Shiny 앱 링크에는 얼마나 많은 connections가 허용될 수 있나요?
Databricks에서 권장하는 연결 수는 최대 20개입니다.
Databricks Runtime에 설치된 버전과 다른 버전의 Shiny 패키지를 사용할 수 있나요?
예. R 패키지 버전 수정을 참조하세요.
Shiny 서버에 게시되고 Azure Databricks의 데이터에 액세스할 수 있는 Shiny 애플리케이션을 개발하려면 어떻게 해야 하나요?
Azure Databricks에서 개발 및 테스트하는 동안 SparkR 또는 sparklyr을 사용하여 데이터에 자연스럽게 액세스할 수 있지만, Shiny 애플리케이션이 독립 실행형 호스팅 서비스에 게시된 후에는 Azure Databricks의 데이터와 tables에 직접 액세스할 수 없습니다.
애플리케이션이 Azure Databricks 외부에서 작동할 수 있도록 하려면 데이터에 액세스하는 방법을 다시 작성해야 합니다. 다음과 같은 몇 가지 옵션이 있습니다.
- JDBC/ODBC를 사용하여 Azure Databricks 클러스터에 쿼리를 제출합니다.
- Databricks Connect를 사용합니다.
- 개체 스토리지의 데이터에 직접 액세스합니다.
Azure Databricks 솔루션 팀과 협력하여 기존 데이터 및 분석 아키텍처에 가장 적합한 방법을 찾는 것이 좋습니다.
Azure Databricks Notebook 내에서 Shiny 애플리케이션을 개발할 수 있나요?
예, Azure Databricks Notebook 내에서 Shiny 애플리케이션을 개발할 수 있습니다.
호스트된 RStudio Server에서 개발한 Shiny 애플리케이션을 저장하려면 어떻게 해야 하나요?
애플리케이션 코드를 DBFS에 저장하거나 코드를 버전 제어에 체크 인할 수 있습니다.