sparklyr
Azure Databricks는 Notebooks, 작업 및 RStudio Desktop에서 sparklyr를 지원합니다. 이 문서에서는 sparklyr를 사용하는 방법을 설명하고 실행할 수 있는 예제 스크립트를 제공합니다. 자세한 내용은 Apache Spark에 대한 R 인터페이스를 참조하세요.
요구 사항
Azure Databricks는 모든 Databricks 런타임 릴리스와 함께 최신 안정 버전의 sparklyr를 배포합니다. 설치된 버전의 sparklyr를 가져와 Azure Databricks R Notebooks 또는 Azure Databricks에서 호스팅되는 RStudio Server 내부에서 sparklyr를 사용할 수 있습니다.
RStudio Desktop에서 Databricks Connect를 사용하면 로컬 컴퓨터의 sparklyr를 Azure Databricks 클러스터에 연결하고 Apache Spark 코드를 실행할 수 있습니다. Databricks Connect와 함께 sparklyr 및 RStudio Desktop 사용을 참조하세요.
Sparklyr를 Azure Databricks 클러스터에 연결
sparklyr 연결을 설정하려면 "databricks"를 spark_connect()의 연결 방법으로 사용할 수 있습니다.
Spark가 이미 Azure Databricks 클러스터에 설치되어 있으므로 spark_connect()에 대한 추가 매개 변수가 필요하지 않으며 spark_install()을 호출할 필요도 없습니다.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
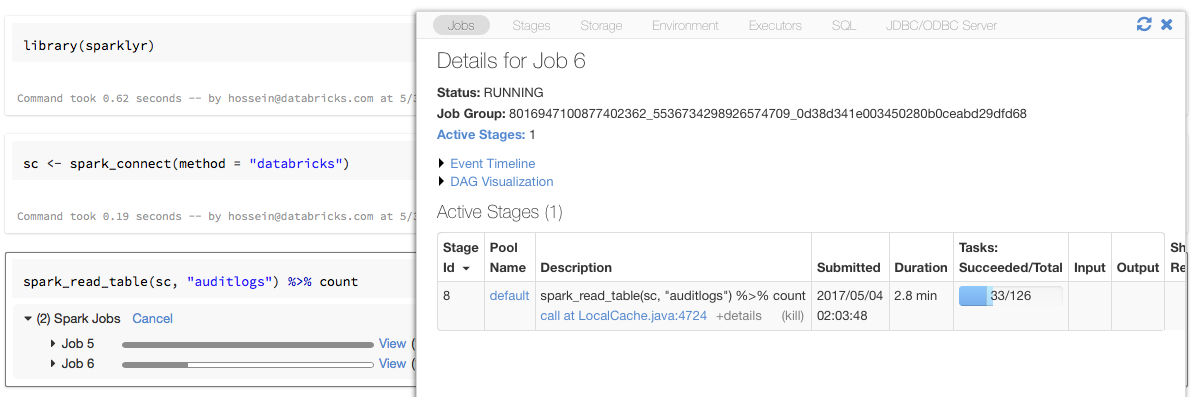
sparklyr가 포함된 진행률 표시줄 및 Spark UI
위의 예와 같이 sparklyr 연결 개체를 sc라는 변수에 할당하면 Spark 작업을 트리거하는 각 명령 뒤에 Notebook에 Spark 진행률 표시줄이 표시됩니다.
또한 진행률 표시줄 옆에 있는 링크를 클릭하여 지정된 Spark 작업과 연결된 Spark UI를 볼 수 있습니다.
sparklyr 사용
sparklyr를 설치하고 연결을 설정하면 다른 모든 sparklyr API가 정상적으로 작동합니다. 몇 가지 예는 예시 Notebook을 참조하세요.
sparklyr는 일반적으로 dplyr과 같은 다른 tidyverse 패키지와 함께 사용됩니다. 이러한 패키지의 대부분은 사용자의 편의를 위해 Databricks에 사전 설치되어 있습니다. 간단히 가져와서 API 사용을 시작할 수 있습니다.
sparklyr와 SparkR을 함께 사용
SparkR과 sparklyr는 하나의 Notebook이나 작업에서 함께 사용할 수 있습니다. sparklyr와 함께 SparkR을 가져와서 해당 함수를 사용할 수 있습니다. Azure Databricks Notebooks에서 SparkR 연결은 미리 구성되어 있습니다.
SparkR의 일부 함수는 dplyr의 여러 함수를 마스킹합니다.
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
dplyr을 가져온 후 SparkR을 가져오면 정규화된 이름(예: dplyr::arrange())을 사용하여 dplyr의 함수를 참조할 수 있습니다.
마찬가지로 SparkR 다음에 dplyr을 가져오면 SparkR의 함수는 dplyr에 의해 마스킹됩니다.
또는 필요하지 않을 때 두 패키지 중 하나를 선택적으로 분리할 수 있습니다.
detach("package:dplyr")
SparkR과 sparklyr 비교도 참조하세요.
spark-submit 작업에서 sparklyr 사용
Azure Databricks에서 sparklyr를 사용하는 스크립트를 약간의 코드 수정으로 spark-submit 작업으로 실행할 수 있습니다. 위의 지침 중 일부는 Azure Databricks의 spark-submit 작업에서 sparklyr를 사용하는 데 적용되지 않습니다. 특히 spark_connect에 Spark 마스터 URL을 제공해야 합니다. 예시:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
지원되지 않는 기능
Azure Databricks는 로컬 브라우저가 필요한 spark_web() 및 spark_log()와 같은 sparklyr 메서드를 지원하지 않습니다. 그러나 Spark UI는 Azure Databricks에 기본 제공되므로 Spark 작업 및 로그를 쉽게 검사할 수 있습니다.
컴퓨터 드라이버 및 작업자 로그를 참조하세요.
예제 Notebook: Sparklyr 데모
Sparklyr Notebook
추가 예는 R에서 DataFrame 및 테이블 작업을 참조하세요.