빠른 시작: Azure Storage에서 Event Hubs 데이터 캡처 및 Python을 사용하여 데이터 읽기(azure-eventhub)
이벤트 허브로 전송된 데이터가 Azure 스토리지 계정 또는 Azure Data Lake Storage Gen 1 또는 Gen 2에서 캡처되도록 이벤트 허브를 구성할 수 있습니다. 이 문서에서는 이벤트 허브로 데이터를 보내고 Azure Blob 스토리지에서 캡처한 데이터를 읽는 Python 코드를 작성하는 방법을 보여줍니다. 이 기능에 대한 자세한 내용은 Event Hubs 캡처 기능 개요를 참조하세요.
이 빠른 시작에서는 Azure Python SDK를 사용하여 캡처 기능을 보여줍니다. sender.py 앱은 JSON 형식으로 이벤트 허브에 시뮬레이션된 환경 원격 분석을 보냅니다. Event Hub는 캡처 기능을 사용하여 이 데이터를 Blob Storage에 일괄적으로 쓰도록 구성되어 있습니다. capturereader.py 앱은 이러한 BLOB을 읽고 각 디바이스에 대한 추가 파일을 만듭니다. 그런 다음, CSV 파일에 데이터를 씁니다.
이 빠른 시작에서 관련 정보는 다음과 같습니다.
- Azure Portal에서 Azure Blob 스토리지 계정 및 컨테이너 만들기
- Azure Portal을 사용하여 Event Hubs 네임스페이스 만들기
- 캡처 기능이 활성화된 이벤트 허브를 만들고 스토리지 계정에 연결합니다.
- Python 스크립트를 사용하여 이벤트 허브에 데이터 보내기
- 다른 Python 스크립트를 사용하여 Event Hubs 캡처에서 파일 읽기 및 처리
필수 조건
pip가 설치되고 업데이트된 Python 3.8 이상.
Azure 구독 구독이 없으면 시작하기 전에 계정을 만드세요.
활성 Event Hubs 네임스페이스 및 이벤트 허브 Event Hubs 네임스페이스를 만들고 이 네임스페이스에 이벤트 허브를 만듭니다. Event Hubs 네임스페이스의 이름, 이벤트 허브의 이름, 네임스페이스의 기본 액세스 키를 기록해 둡니다. 액세스 키를 얻는 방법은 Event Hubs 연결 문자열 가져오기를 참조하세요. 기본 키 이름은 RootManageSharedAccessKey입니다. 이 빠른 시작에서는 기본 키만 필요합니다. 연결 문자열은 필요 없습니다.
Azure 스토리지 계정, 스토리지 계정의 BLOB 컨테이너, 스토리지 계정에 대한 연결 문자열. 이러한 항목이 없으면 다음 단계를 수행합니다.
이 빠른 시작의 뒷부분에서 사용할 수 있도록 연결 문자열과 컨테이너 이름을 기록해 두어야 합니다.
이벤트 허브에 캡처 기능 사용
이벤트 허브에 캡처 기능을 사용하도록 설정합니다. 이렇게 하려면 Azure Portal을 사용하여 Event Hubs 캡처를 사용하도록 설정의 지침을 따릅니다. 이전 단계에서 만든 스토리지 계정과 BLOB 컨테이너를 선택합니다. 출력 이벤트 직렬화 형식으로 Avro를 선택합니다.
이벤트 허브로 이벤트를 보내는 Python 스크립트 만들기
이 섹션에서는 이벤트 허브로 200개 이벤트(디바이스 10대 * 이벤트 20개)를 전송하는 Python 스크립트를 만듭니다. 이러한 이벤트는 JSON 형식으로 전송되는 샘플 환경 판독값입니다.
선호하는 Python 편집기(예: Visual Studio Code)를 엽니다.
sender.py라는 스크립트를 만듭니다.
다음 코드를 sender.py에 붙여넣습니다.
import time import os import uuid import datetime import random import json from azure.eventhub import EventHubProducerClient, EventData # This script simulates the production of events for 10 devices. devices = [] for x in range(0, 10): devices.append(str(uuid.uuid4())) # Create a producer client to produce and publish events to the event hub. producer = EventHubProducerClient.from_connection_string(conn_str="EVENT HUBS NAMESAPCE CONNECTION STRING", eventhub_name="EVENT HUB NAME") for y in range(0,20): # For each device, produce 20 events. event_data_batch = producer.create_batch() # Create a batch. You will add events to the batch later. for dev in devices: # Create a dummy reading. reading = { 'id': dev, 'timestamp': str(datetime.datetime.utcnow()), 'uv': random.random(), 'temperature': random.randint(70, 100), 'humidity': random.randint(70, 100) } s = json.dumps(reading) # Convert the reading into a JSON string. event_data_batch.add(EventData(s)) # Add event data to the batch. producer.send_batch(event_data_batch) # Send the batch of events to the event hub. # Close the producer. producer.close()스크립트에서 다음 값을 바꿉니다.
EVENT HUBS NAMESPACE CONNECTION STRING을 Event Hubs 네임스페이스의 연결 문자열로 바꿉니다.EVENT HUB NAME을 이벤트 허브 이름으로 바꿉니다.
스크립트를 실행하여 이벤트 허브에 이벤트를 보냅니다.
Azure Portal에서 이벤트 허브가 메시지를 받았는지 확인할 수 있습니다. 메트릭 섹션에서 메시지 보기로 전환합니다. 페이지를 새로 고쳐 차트를 업데이트합니다. 메시지가 수신되었음을 표시하는 페이지가 표시될 때까지 몇 초 정도 걸릴 수 있습니다.
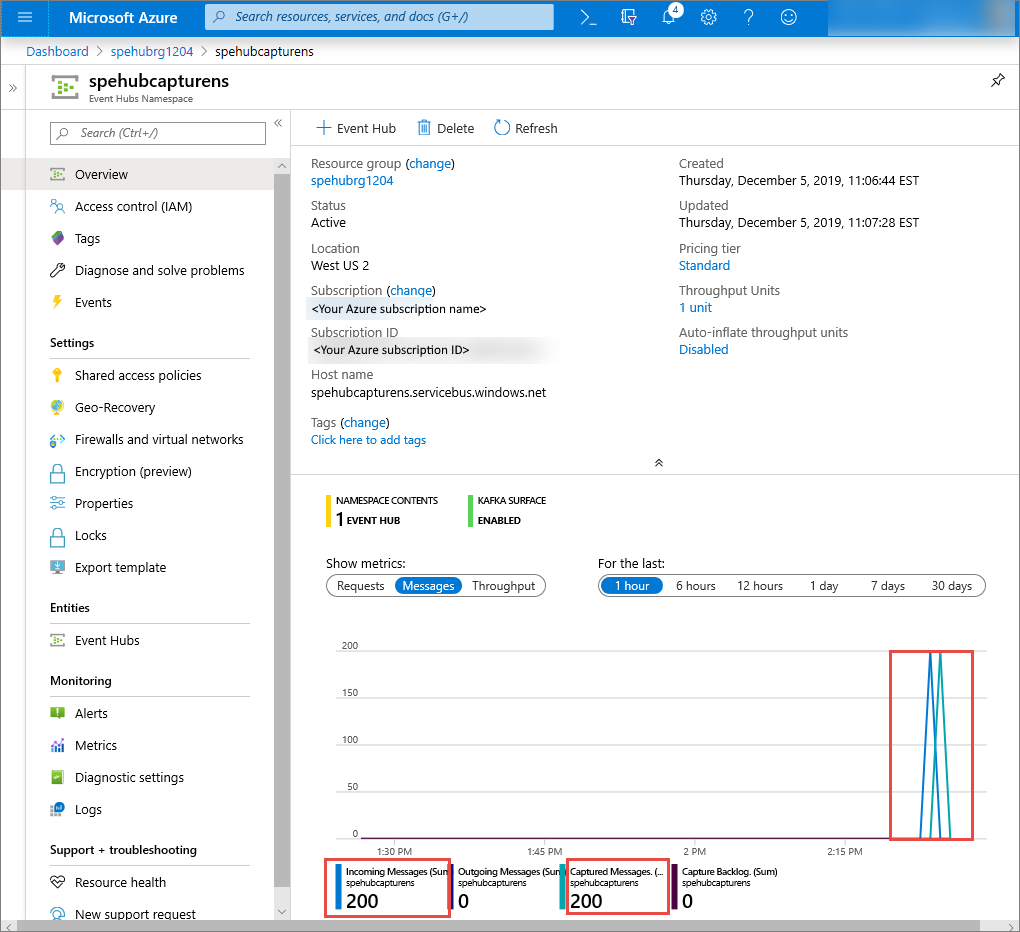

캡처 파일을 읽는 Python 스크립트 만들기
이 예제에서는 캡처된 데이터가 Azure Blob 스토리지에 저장됩니다. 이 섹션의 스크립트는 Azure 스토리지 계정에서 캡처된 데이터 파일을 읽은 후, 개발자가 쉽게 열어서 볼 수 있도록 CSV 파일을 생성합니다. 애플리케이션의 현재 작업 디렉터리에 10개의 파일이 있습니다. 이러한 파일에는 10개 디바이스의 환경 판독값이 포함됩니다.
Python 편집기에서 capturereader.py라는 새 스크립트를 만듭니다. 이 스크립트는 캡처된 파일을 읽고, 디바이스마다 파일을 만들어 해당 디바이스에 대한 데이터만 씁니다.
capturereader.py에 다음 코드를 붙여넣습니다.
import os import string import json import uuid import avro.schema from azure.storage.blob import ContainerClient, BlobClient from avro.datafile import DataFileReader, DataFileWriter from avro.io import DatumReader, DatumWriter def processBlob2(filename): reader = DataFileReader(open(filename, 'rb'), DatumReader()) dict = {} for reading in reader: parsed_json = json.loads(reading["Body"]) if not 'id' in parsed_json: return if not parsed_json['id'] in dict: list = [] dict[parsed_json['id']] = list else: list = dict[parsed_json['id']] list.append(parsed_json) reader.close() for device in dict.keys(): filename = os.getcwd() + '\\' + str(device) + '.csv' deviceFile = open(filename, "a") for r in dict[device]: deviceFile.write(", ".join([str(r[x]) for x in r.keys()])+'\n') def startProcessing(): print('Processor started using path: ' + os.getcwd()) # Create a blob container client. container = ContainerClient.from_connection_string("AZURE STORAGE CONNECTION STRING", container_name="BLOB CONTAINER NAME") blob_list = container.list_blobs() # List all the blobs in the container. for blob in blob_list: # Content_length == 508 is an empty file, so process only content_length > 508 (skip empty files). if blob.size > 508: print('Downloaded a non empty blob: ' + blob.name) # Create a blob client for the blob. blob_client = ContainerClient.get_blob_client(container, blob=blob.name) # Construct a file name based on the blob name. cleanName = str.replace(blob.name, '/', '_') cleanName = os.getcwd() + '\\' + cleanName with open(cleanName, "wb+") as my_file: # Open the file to write. Create it if it doesn't exist. my_file.write(blob_client.download_blob().readall()) # Write blob contents into the file. processBlob2(cleanName) # Convert the file into a CSV file. os.remove(cleanName) # Remove the original downloaded file. # Delete the blob from the container after it's read. container.delete_blob(blob.name) startProcessing()AZURE STORAGE CONNECTION STRING을 Azure 스토리지 계정의 연결 문자열로 바꿉니다. 이 빠른 시작에서 만든 컨테이너의 이름은 capture입니다. 컨테이너에 다른 이름을 사용한 경우 capture를 스토리지 계정의 컨테이너 이름으로 바꿉니다.
스크립트 실행
해당 경로에 Python을 포함하는 명령 프롬프트를 열고 다음 명령을 실행하여 Python 필수 구성 요소 패키지를 설치합니다.
pip install azure-storage-blob pip install azure-eventhub pip install avro-python3디렉터리를 sender.py 및 capturereader.py를 저장한 디렉터리로 변경하고, 다음 명령을 실행합니다.
python sender.py이 명령은 발신자를 실행하는 새 Python 프로세스를 시작합니다.
캡처가 실행될 때까지 몇 분 정도 기다렸다가 원래 명령 창에 다음 명령을 입력합니다.
python capturereader.py이 캡처 프로세서는 로컬 디렉터리를 사용하여 스토리지 계정 및 컨테이너의 모든 BLOB을 다운로드합니다. 비어 있지 않은 파일을 처리하고 그 결과를 로컬 디렉터리에 CSV 파일로 작성합니다.
다음 단계
GitHub의 Python 샘플을 살펴보세요.