HDInsight on AKS에서 Apache Flink®에 Apache Kafka® 테이블 만들기
참고 항목
2025년 1월 31일에 Azure HDInsight on AKS가 사용 중지됩니다. 2025년 1월 31일 이전에 워크로드가 갑자기 종료되지 않도록 워크로드를 Microsoft Fabric 또는 동등한 Azure 제품으로 마이그레이션해야 합니다. 구독의 나머지 클러스터는 호스트에서 중지되고 제거됩니다.
사용 중지 날짜까지 기본 지원만 사용할 수 있습니다.
Important
이 기능은 현지 미리 보기로 제공됩니다. Microsoft Azure 미리 보기에 대한 보충 사용 약관에는 베타 또는 미리 보기로 제공되거나 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 더 많은 약관이 포함되어 있습니다. 이 특정 미리 보기에 대한 자세한 내용은 Azure HDInsight on AKS 미리 보기 정보를 참조하세요. 질문이나 기능 제안이 있는 경우 세부 정보와 함께 AskHDInsight에 요청을 제출하고 Azure HDInsight 커뮤니티에서 추가 업데이트를 보려면 팔로우하세요.
이 예제를 사용하여 Apache FlinkSQL에서 Kafka 테이블을 만드는 방법을 알아봅니다.
필수 조건
Apache Flink의 Kafka SQL 커넥터
Kafka 커넥터를 사용하면 Kafka 항목에서 데이터를 읽고 쓸 수 있습니다. 자세한 내용은 Apache Kafka SQL 커넥터를 참조하세요.
Flink SQL에서 Kafka 테이블 만들기
HDInsight Kafka에서 항목 및 데이터 준비
weblog.py를 사용하여 메시지 준비
import random
import json
import time
from datetime import datetime
user_set = [
'John',
'XiaoMing',
'Mike',
'Tom',
'Machael',
'Zheng Hu',
'Zark',
'Tim',
'Andrew',
'Pick',
'Sean',
'Luke',
'Chunck'
]
web_set = [
'https://google.com',
'https://facebook.com?id=1',
'https://tmall.com',
'https://baidu.com',
'https://taobao.com',
'https://aliyun.com',
'https://apache.com',
'https://flink.apache.com',
'https://hbase.apache.com',
'https://github.com',
'https://gmail.com',
'https://stackoverflow.com',
'https://python.org'
]
def main():
while True:
if random.randrange(10) < 4:
url = random.choice(web_set[:3])
else:
url = random.choice(web_set)
log_entry = {
'userName': random.choice(user_set),
'visitURL': url,
'ts': datetime.now().strftime("%m/%d/%Y %H:%M:%S")
}
print(json.dumps(log_entry))
time.sleep(0.05)
if __name__ == "__main__":
main()
Kafka 항목에 대한 파이프라인
sshuser@hn0-contsk:~$ python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
기타 명령:
-- create topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 3 --topic click_events --bootstrap-server wn0-contsk:9092
-- delete topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic click_events --bootstrap-server wn0-contsk:9092
-- consume topic
sshuser@hn0-contsk:~$ /usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server wn0-contsk:9092 --topic click_events --from-beginning
{"userName": "Luke", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Tom", "visitURL": "https://stackoverflow.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Chunck", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Chunck", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Andrew", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Pick", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Mike", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Zheng Hu", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Luke", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:44"}
Apache Flink SQL 클라이언트
Flink SQL 클라이언트용 Secure Shell을 사용하는 방법에 대한 자세한 지침이 제공됩니다.
Kafka SQL 커넥터 및 종속성을 SSH에 다운로드
아래 단계에서는 Kafka 3.2.0 종속성을 사용하고 있습니다. HDInsight 클러스터의 Kafka 버전에 따라 명령을 업데이트해야 합니다.
wget https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/3.2.0/kafka-clients-3.2.0.jar
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka/1.17.0/flink-connector-kafka-1.17.0.jar
Apache Flink SQL 클라이언트에 연결
이제 Kafka SQL 클라이언트 jar를 사용하여 Flink SQL 클라이언트에 연결해 보겠습니다.
msdata@pod-0 [ /opt/flink-webssh ]$ bin/sql-client.sh -j flink-connector-kafka-1.17.0.jar -j kafka-clients-3.2.0.jar
Apache Flink SQL에서 Kafka 테이블 만들기
Flink SQL에서 Kafka 테이블을 만들고 Flink SQL에서 Kafka 테이블을 선택해 보겠습니다.
아래 코드 조각에서 Kafka 부트스트랩 서버 IP를 업데이트해야 합니다.
CREATE TABLE KafkaTable (
`userName` STRING,
`visitURL` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'click_events',
'properties.bootstrap.servers' = '<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092',
'properties.group.id' = 'my_group',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
select * from KafkaTable;
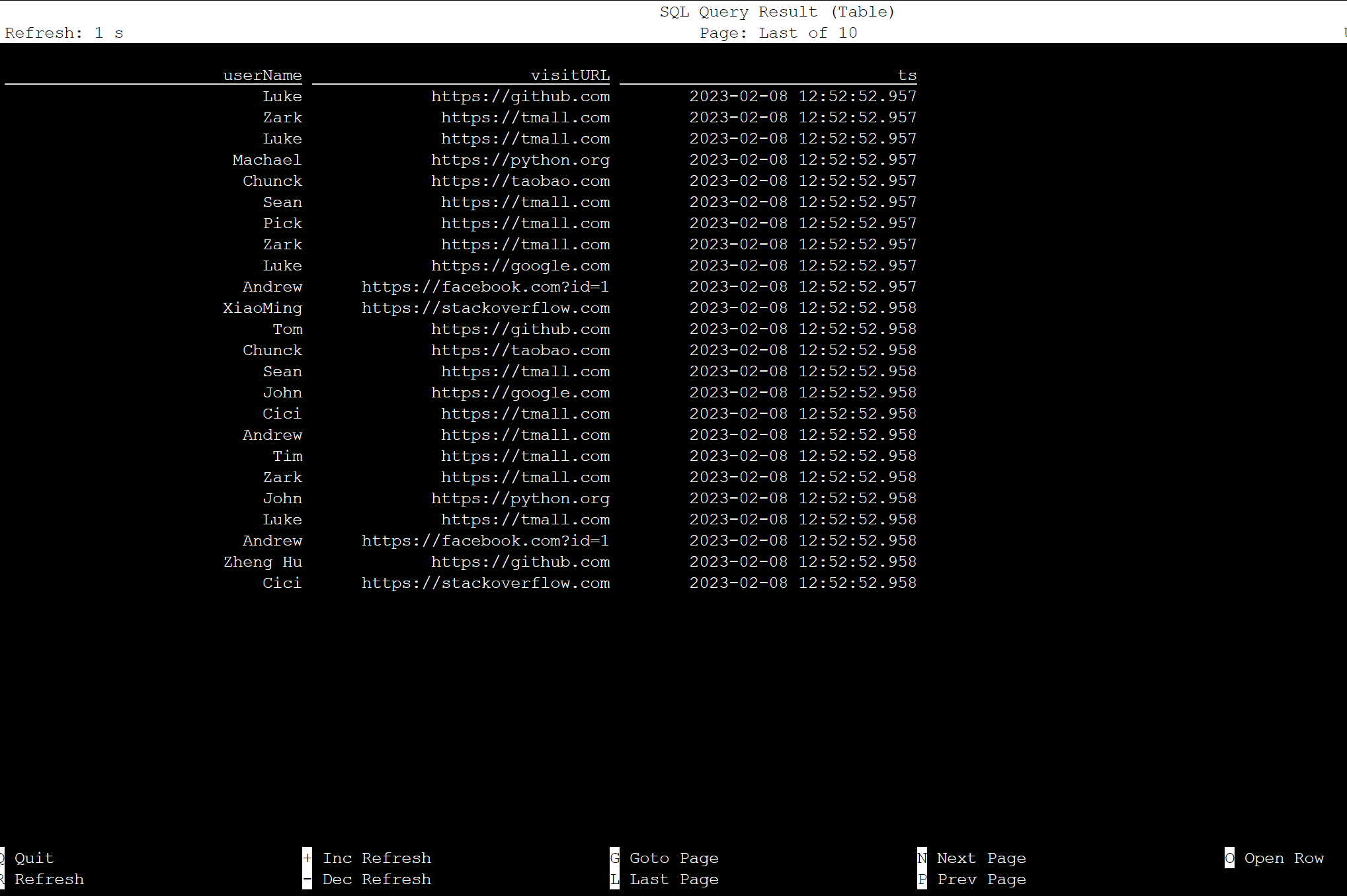
Kafka 메시지 생성
이제 HDInsight Kafka를 사용하여 동일한 항목에 Kafka 메시지를 생성해 보겠습니다.
python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
Apache Flink SQL의 테이블
Flink SQL에서 테이블을 모니터링할 수 있습니다.
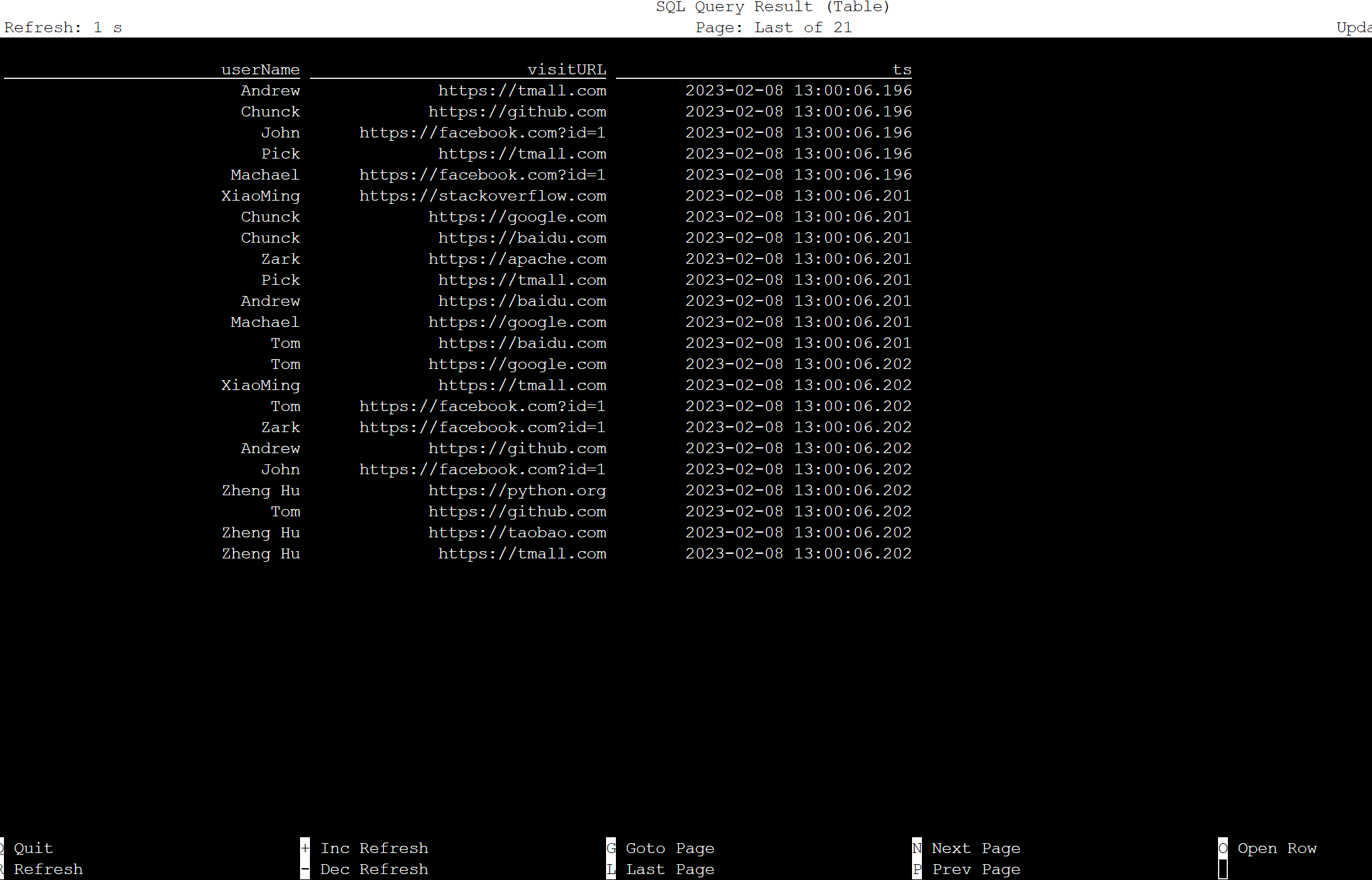
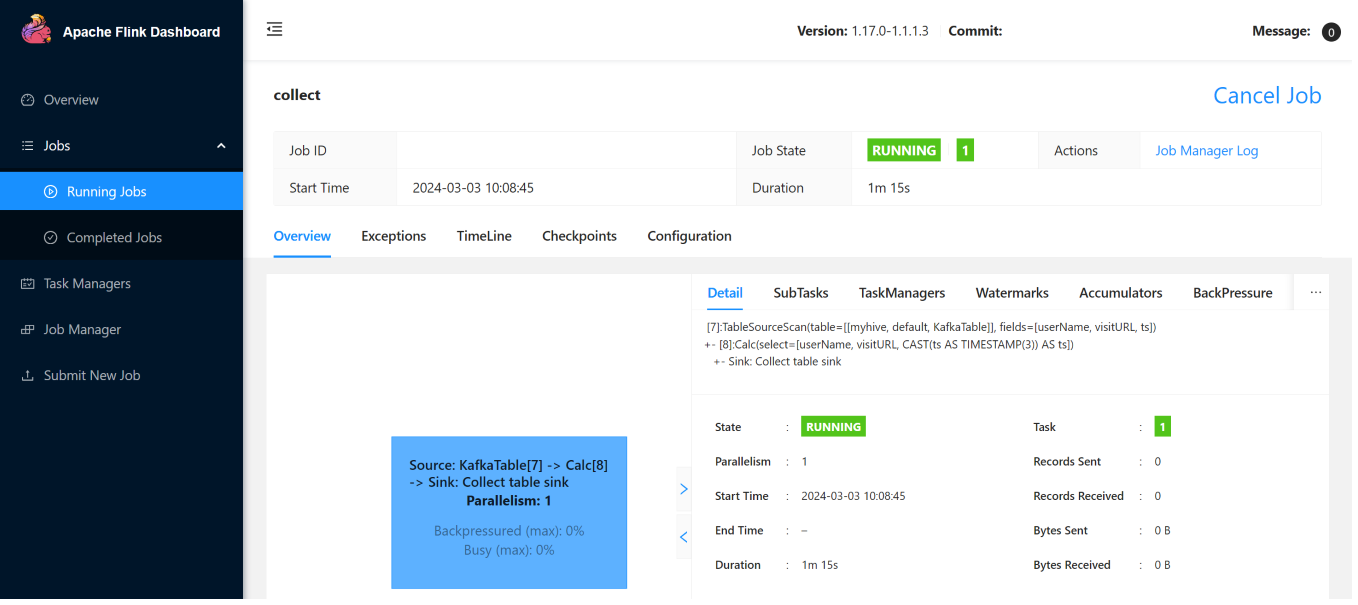
Flink Web UI의 스트리밍 작업은 다음과 같습니다.
참조
- Apache Kafka SQL 커넥터
- Apache, Apache Kafka, Kafka, Apache Flink, Flink, 관련 오픈 소스 프로젝트 이름은 ASF(Apache Software Foundation)의 상표입니다.