캐싱 구성
참고 항목
2025년 1월 31일에 Azure HDInsight on AKS가 사용 중지됩니다. 2025년 1월 31일 이전에 워크로드가 갑자기 종료되지 않도록 워크로드를 Microsoft Fabric 또는 동등한 Azure 제품으로 마이그레이션해야 합니다. 구독의 나머지 클러스터는 호스트에서 중지되고 제거됩니다.
사용 중지 날짜까지 기본 지원만 사용할 수 있습니다.
Important
이 기능은 현지 미리 보기로 제공됩니다. Microsoft Azure 미리 보기에 대한 보충 사용 약관에는 베타 또는 미리 보기로 제공되거나 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 더 많은 약관이 포함되어 있습니다. 이 특정 미리 보기에 대한 자세한 내용은 Azure HDInsight on AKS 미리 보기 정보를 참조하세요. 질문이나 기능 제안이 있는 경우 AskHDInsight에서 세부 정보와 함께 요청을 제출하고 Azure HDInsight 커뮤니티에서 더 많은 업데이트를 확인하세요.
Hive 커넥터를 사용하여 개체 스토리지를 쿼리하는 것은 Trino의 일반적인 사용 사례입니다. 이 프로세스에는 대량의 데이터 전송이 포함되는 경우가 많습니다. 개체는 여러 작업자에 의해 HDFS 또는 지원되는 다른 개체 저장소에서 검색되고 해당 작업자에 의해 처리됩니다. 다른 매개 변수를 사용한 반복 쿼리 또는 다른 사용자의 다른 쿼리는 종종 동일한 개체에 액세스하고 전송합니다.
AKS의 HDInsight에는 다음과 같은 이점을 제공하는 Trino용 최종 결과 캐싱 기능이 추가되었습니다.
- 개체 스토리지의 부하를 줄입니다.
- 쿼리 성능을 개선시킵니다.
- 쿼리 비용을 줄입니다.
캐싱 옵션
다양한 캐싱 옵션:
- 최종 결과 캐싱: 사용하도록 설정되면(코디네이터 구성 요소 구성 섹션에서) 코디네이터 VM의 모든 카탈로그 캐시에 대한 쿼리 결과입니다.
- Hive/Iceberg/Delta Lake 카탈로그 캐싱: 사용하도록 설정하면(해당 형식의 특정 카탈로그에 대해) 각 쿼리에 대한 분할 데이터가 작업자 VM의 클러스터 내에서 캐시됩니다.
최종 결과 캐싱
최종 결과 캐싱은 두 가지 방법으로 구성할 수 있습니다.
사용 가능한 구성 매개 변수는 다음과 같습니다.
| 속성 | 기본값 | 설명 |
|---|---|---|
query.cache.enabled |
false | true인 경우 최종 결과 캐싱을 사용하도록 설정합니다. |
query.cache.ttl |
- | 제거 전에 캐시 데이터가 보관될 때까지의 시간을 정의합니다. 예: "10분", "1시간" |
query.cache.disk-usage-percentage |
80 | 캐시된 데이터에 사용되는 디스크 공간의 비율입니다. |
query.cache.max-result-data-size |
0 | 결과의 최대 데이터 크기입니다. 이 값을 초과하면 결과가 캐시되지 않습니다. |
참고 항목
최종 결과 캐싱은 쿼리 계획과 ttl을 캐시 키로 사용합니다.
최종 결과 캐싱은 다음 세션 매개 변수를 통해 제어할 수도 있습니다.
| 세션 매개 변수 | 기본값 | 설명 |
|---|---|---|
query_cache_enabled |
원래 구성 값 | 쿼리/세션에 대한 최종 결과 캐싱을 사용하거나 사용하지 않도록 설정합니다. |
query_cache_ttl |
원래 구성 값 | 제거 전에 캐시 데이터가 보관될 때까지의 시간을 정의합니다. |
query_cache_max_result_data_size |
원래 구성 값 | 결과의 최대 데이터 크기입니다. 이 값을 초과하면 결과가 캐시되지 않습니다. |
query_cache_forced_refresh |
false | true로 설정하면 쿼리 실행 결과가 강제로 캐시됩니다. 즉, 캐시된 기존 데이터가 있는 경우 해당 결과가 바뀝니다. |
참고 항목
세션 매개 변수는 세션에 대해 설정하거나(예: Trino CLI를 사용하는 경우) 쿼리 텍스트 이전에 다중 문으로 설정할 수 있습니다. 예를 들면 다음과 같습니다.
set session query_cache_enabled=true;
select cust.name, *
from tpch.tiny.orders
join tpch.tiny.customer as cust on cust.custkey = orders.custkey
order by cust.name
limit 10;
최종 결과 캐싱은 관리되는 Prometheus 및 Grafana를 사용하여 볼 수 있는 JMX 메트릭을 생성합니다. 다음 메트릭을 사용할 수 있습니다.
| 메트릭 | 설명 |
|---|---|
trino_cache_cachestats_requestcount |
캐시 계층을 통과하는 총 쿼리 수입니다. 이 숫자에는 캐시가 꺼진 상태에서 실행된 쿼리가 포함되지 않습니다. |
trino_cache_cachestats_hitcount |
캐시 적중 수, 즉 데이터가 사용 가능하고 캐시에서 반환되었을 때의 쿼리 수입니다. |
trino_cache_cachestats_misscount |
캐시 누락 수, 즉 데이터를 사용할 수 없어 캐시해야 했던 경우의 쿼리 수입니다. |
trino_cache_cachestats_hitrate |
총 쿼리 수에 대한 캐시 적중률을 백분율로 나타냅니다. |
trino_cache_cachestats_totalevictedcount |
캐시에서 제거된 캐시된 쿼리 수입니다. |
trino_cache_cachestats_totalbytesfromsource |
원본에서 읽은 바이트 수입니다. |
trino_cache_cachestats_totalbytesfromcache |
캐시에서 읽은 바이트 수입니다. |
trino_cache_cachestats_totalcachedbytes |
캐시된 총 바이트 수입니다. |
trino_cache_cachestats_totalevictedbytes |
제거된 총 바이트 수입니다. |
trino_cache_cachestats_spaceused |
캐시의 현재 크기입니다. |
trino_cache_cachestats_cachereadfailures |
오류로 인해 캐시에서 데이터를 읽을 수 없는 횟수입니다. |
trino_cache_cachestats_cachewritefailures |
오류로 인해 데이터를 캐시에 쓸 수 없는 횟수입니다. |
Azure Portal 사용
Azure 포털에 로그인합니다.
Azure Portal 검색 창에 "HDInsight on AKS 클러스터"를 입력하고 드롭다운 목록에서 "Azure HDInsight on AKS 클러스터"를 선택합니다.

목록 페이지에서 클러스터 이름을 선택합니다.
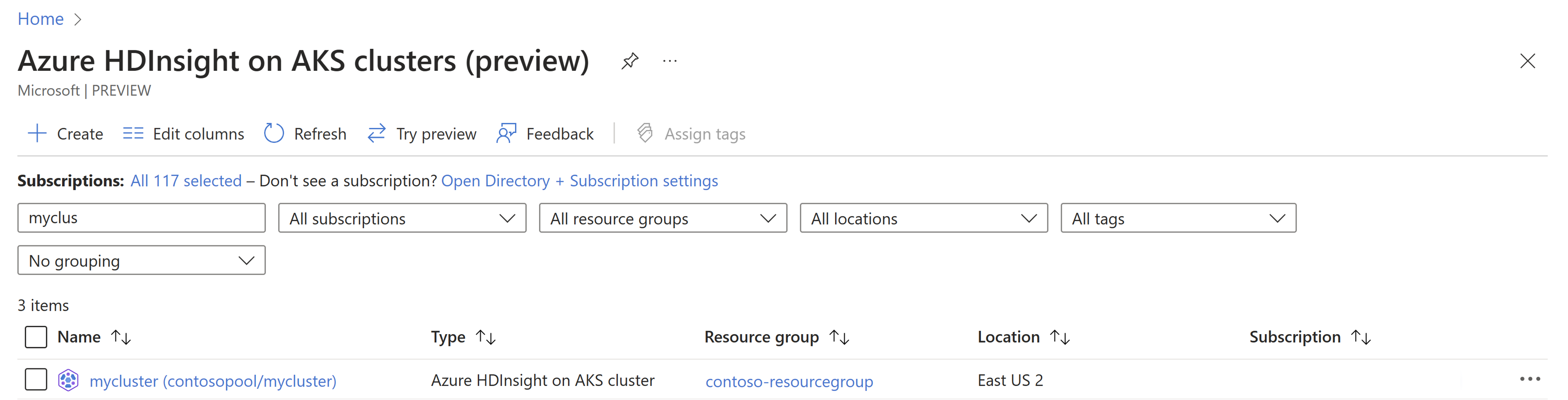
구성 관리 블레이드로 이동합니다.
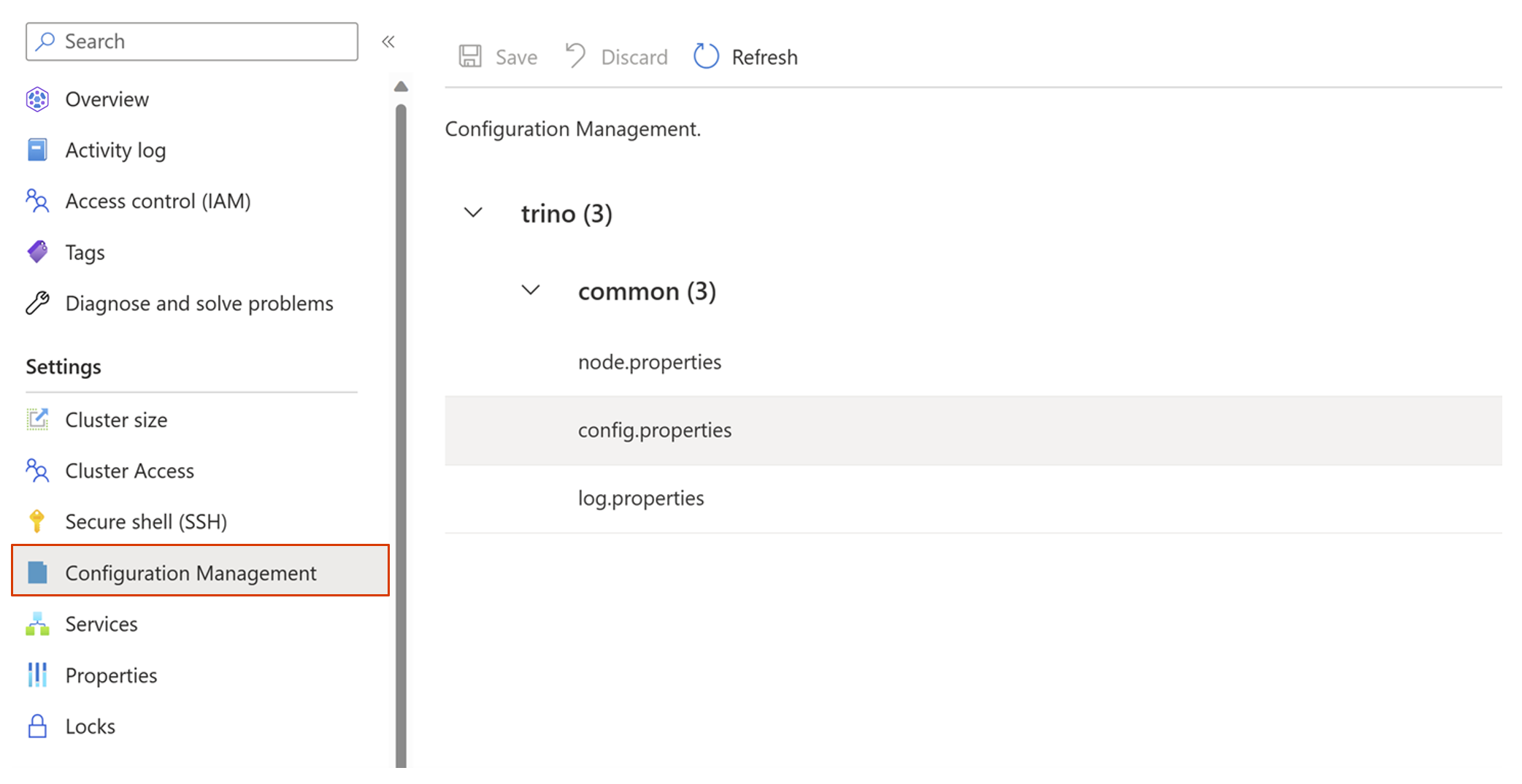
config.properties -> 사용자 지정 구성으로 이동한 다음 추가를 클릭합니다.
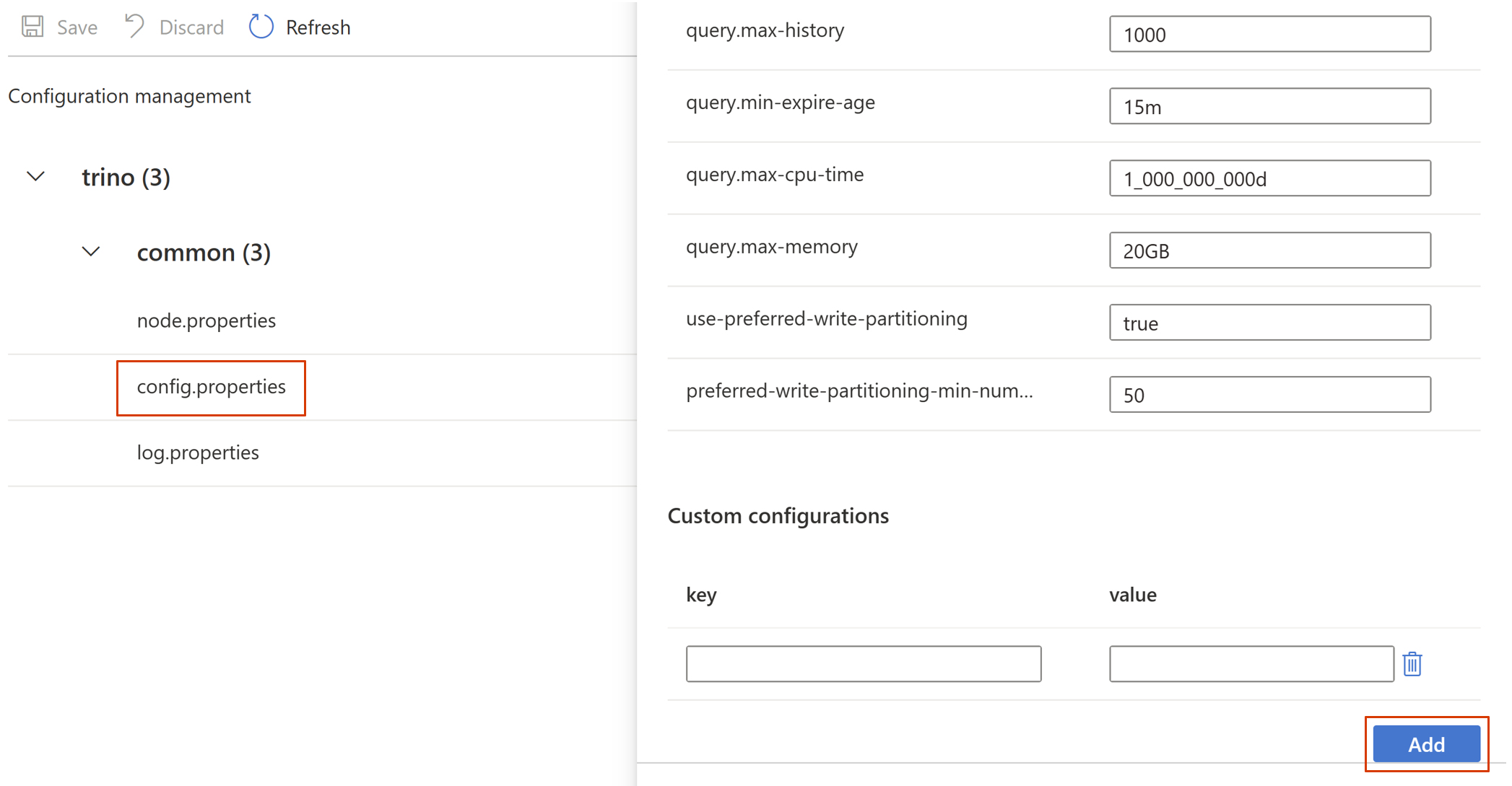
필수 속성을 설정하고 확인을 클릭합니다.
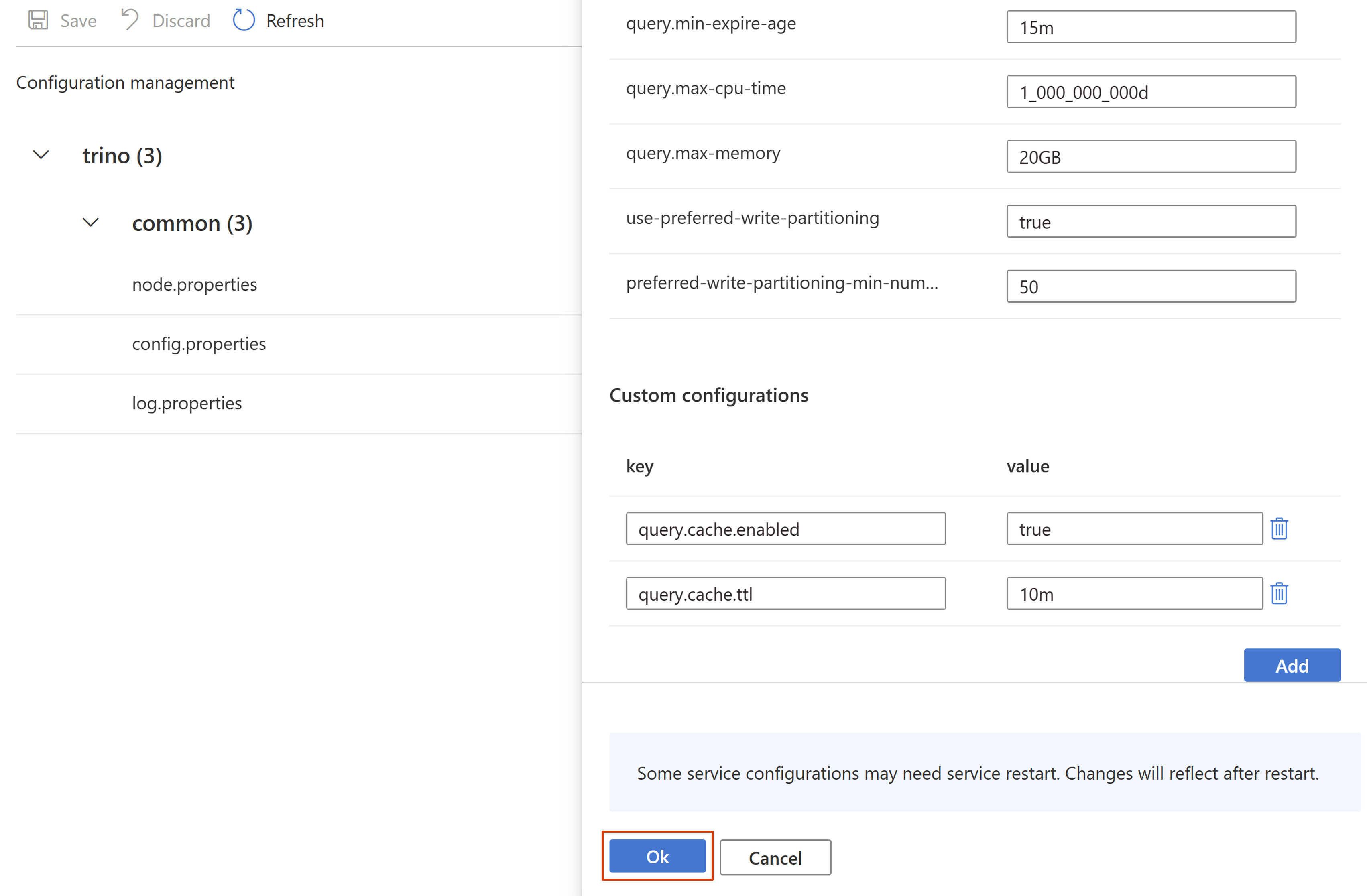
구성을 저장합니다.
ARM 템플릿 사용
필수 조건
- HDInsight on AKS를 사용하는 운영 Trino 클러스터.
- 클러스터에 대한 ARM 템플릿을 만듭니다.
- 전체 클러스터 ARM 템플릿 샘플을 검토합니다.
- ARM 템플릿 작성 및 배포에 대한 지식
ARM 템플릿의 properties.clusterProfile.serviceConfigsProfiles 섹션에 있는 코디네이터 구성 요소의 속성을 정의해야 합니다.
다음 예에서는 속성을 추가할 위치를 보여 줍니다.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "coordinator",
"files": [
{
"fileName": "config.properties",
"values": {
"query.cache.enabled": "true",
"query.cache.ttl": "10m"
}
}
]
}
]
}
]
}
}
}
]
}
Hive/Iceberg/Delta Lake 캐싱
세 커넥터 모두 Hive 캐싱에 설명된 것과 동일한 매개 변수 집합을 공유합니다.
참고 항목
특정 매개 변수는 구성할 수 없으며 항상 기본값으로 설정됩니다.
hive.cache.data-transfer-port=8898,
hive.cache.bookkeeper-port=8899,
hive.cache.location=/etc/trino/cache,
hive.cache.disk-usage-percentage=80
다음 예에서는 ARM 템플릿을 사용하여 Hive 캐싱을 사용하도록 설정하기 위해 속성을 추가하는 위치를 보여 줍니다.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "catalogs",
"files": [
{
"fileName": "hive1.properties",
"values": {
"connector.name": "hive"
"hive.cache.enabled": "true",
"hive.cache.ttl": "5d"
}
}
]
}
]
}
]
}
}
}
]
}
클러스터의 변경 내용을 반영하도록 업데이트된 ARM 템플릿을 배포합니다. ARM 템플릿을 배포하는 방법을 알아봅니다.