Azure HDInsight에서 Apache Hive 메모리 부족 오류 수정
Hive 메모리 설정을 구성하여 큰 테이블을 처리할 때 Apache Hive OOM(메모리 부족) 오류를 수정하는 방법에 대해 알아봅니다.
큰 테이블에서 Apache Hive 쿼리 실행
고객은 Hive 쿼리를 실행했습니다.
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
이 쿼리의 미묘한 차이는 다음과 같습니다.
- T1은 큰 테이블 TABLE1에 대한 별칭이고 여기에는 많은 STRING 열 형식이 있습니다.
- 다른 테이블은 크지 않지만 많은 열을 포함하고 있습니다.
- 모든 테이블은 서로 조인되며 TABLE1 및 기타 테이블의 여러 열과 조인되기도 합니다.
Hive 쿼리를 완료하는 데는 24 노드 A3 HDInsight 클러스터에서 26분이 소요되었습니다. 고객은 다음과 같은 경고 메시지를 보게 됩니다.
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Apache Tez 실행 엔진을 사용하여: 동일한 쿼리가 15분만에 실행되었고 다음과 같은 오류가 발생합니다.
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
이 오류는 보다 큰 가상 컴퓨터를 사용할 때 유지됩니다(예: D12).
메모리 부족 오류 디버깅
당사의 지원 및 엔지니어링 팀은 메모리 부족 오류를 발생시킨 문제 중 하나가 Apache JIRA에 설명된 알려진 문제라는 것을 발견했습니다.
“hive.auto.convert.join.noconditionaltask = true인 경우 noconditionaltask.size를 확인하고 Map Join의 테이블 크기 합계가 noconditionaltask.size보다 작을 경우 계획에서 Map Join을 생성합니다. 문제는 입력 크기의 합계가 noconditionaltask 크기보다 작을 경우 작은 여백 쿼리가 OOM에 도달하고 계산은 서로 다른 HashTable 구현으로 인해 발생하는 오버헤드를 고려하지 않는다는 것입니다."
hive-site.xml 파일을 살펴보면 hive.auto.convert.join.noconditionaltask가 true로 설정되어 있습니다.
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Map Join이 Java 힙 공간 메모리 부족 오류의 원인일 가능성이 있습니다. HDInsight의 블로그 게시물 Hadoop Yarn 메모리 설정에 설명된 대로 Tez 실행 엔진에서 사용된 힙 공간을 사용한 경우 실제로 Tez 컨테이너에 속합니다. Tez 컨테이너 메모리를 설명하는 다음 이미지를 참조하세요.
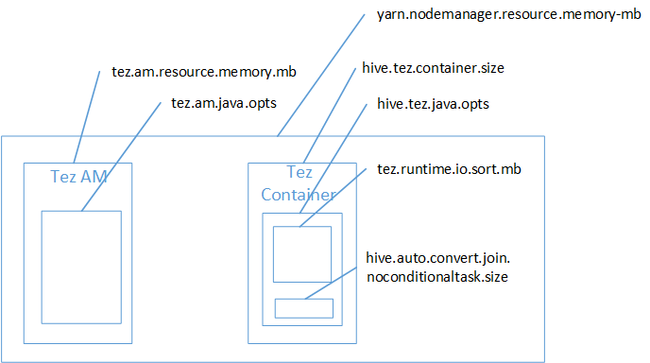
블로그 게시물에서 알 수 있듯이 hive.tez.container.size 및 hive.tez.java.opts의 두 가지 메모리 설정이 힙의 컨테이너 메모리를 정의합니다. 경험에 따르면 메모리 부족 예외가 발생했다고 해서 컨테이너 크기가 너무 작은 것은 아닙니다. Java 힙 크기(hive.tez.java.opts)가 너무 작은 것입니다. 메모리 부족이 표시될 때마다 hive.tez.java.opts를 늘려볼 수 있습니다. 필요한 경우 hive.tez.container.size를 늘려야 할 수도 있습니다. java.opts 설정은 container.size의 80% 정도여야 합니다.
참고 항목
hive.tez.java.opts 설정은 항상 hive.tez.container.size보다 작아야 합니다.
D12 컴퓨터에 28GB 메모리가 있으므로 10GB(10240MB)의 컨테이너 크기를 사용하고 java.opts에 80%를 할당하기로 했습니다.
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
새로운 설정에 따라 쿼리는 10분 이내에 성공적으로 실행됩니다.
다음 단계
OOM 오류가 발생했다고 해서 반드시 컨테이너 크기가 너무 작은 것은 아닙니다. 대신, 힙 크기가 컨테이너 메모리 크기의 80% 이상이 되도록 늘려서 메모리 설정을 구성해야 합니다. Hive 쿼리 최적화는 HDInsight에서 Apache Hadoop에 대한 Apache Hive 쿼리 최적화를 참조하세요.