자습서: ODBC와 PowerShell로 Apache Hive 쿼리
Microsoft ODBC 드라이버는 Apache Hive를 비롯한 여러 종류의 데이터 원본과 상호 작용할 수 있는 유연한 방법을 제공합니다. PowerShell과 같은 스크립팅 언어로 ODBC 드라이버를 사용하여 Hive 클러스터에 대한 연결을 열고 선택한 쿼리를 전달하고 결과를 표시하는 코드를 작성할 수 있습니다.
이 자습서에서는 다음 작업을 수행합니다.
- Microsoft Hive ODBC 드라이버 다운로드 및 설치
- 클러스터에 연결된 Apache Hive ODBC 데이터 원본 만들기
- PowerShell을 사용하여 클러스터의 샘플 정보 쿼리
Azure 구독이 아직 없는 경우 시작하기 전에 무료 계정을 만듭니다.
필수 조건
이 자습서를 시작하기 전에 다음 항목이 있어야 합니다.
- HDInsight의 대화형 쿼리 클러스터. 만들려면 Azure HDInsight 시작을 참조하세요. 클러스터 유형으로 대화형 쿼리를 선택합니다.
Microsoft Hive ODBC 드라이버 설치
Microsoft Hive ODBC 드라이버를 다운로드하고 설치합니다.
Apache Hive ODBC 데이터 원본 만들기
다음 단계는 Apache Hive ODBC 데이터 원본을 만드는 방법을 보여줍니다.
Windows에서 시작>Windows 관리 도구>ODBC 데이터 원본(32비트)/(64비트)으로 이동합니다. ODBC 데이터 원본 관리자 창이 열립니다.
사용자 DSN 탭에서 추가를 선택하여 새 데이터 원본 만들기 창을 엽니다.
Microsoft Hive ODBC 드라이버를 선택한 다음, 마침을 선택하여 Microsoft Hive ODBC 드라이버 DSN 설정 창을 엽니다.
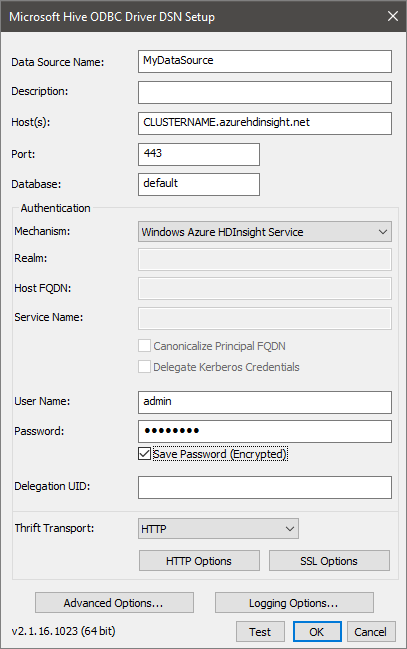
다음 값을 입력하거나 선택합니다.
속성 설명 데이터 원본 이름 데이터 원본에 이름 지정 호스트 CLUSTERNAME.azurehdinsight.net를 입력합니다. 예를 들어myHDICluster.azurehdinsight.net포트 443을 사용합니다. 데이터베이스 기본값을 사용합니다. 메커니즘 Windows Azure HDInsight Service를 선택합니다. 사용자 이름 HDInsight 클러스터 HTTP 사용자의 사용자 이름을 입력합니다. 기본 사용자 이름은 admin입니다.암호 HDInsight 클러스터 사용자 암호 입력 암호 저장(암호화됨) 확인란을 선택합니다. 선택 사항: 고급 옵션을 선택합니다.
매개 변수 설명 Use Native Query 선택하면 ODBC 드라이버가 TSQL을 HiveQL로 변환하지 않습니다. 이 옵션은 순수 HiveQL 문을 제출한다고 100% 확신하는 경우에만 사용합니다. SQL Server 또는 Azure SQL Database에 연결하는 경우에는 이 옵션을 선택 취소한 상태로 둬야 합니다. Rows fetched per block 많은 수의 레코드를 가져오는 경우 최적의 성능을 위해 이 매개 변수를 조정해야 할 수 있습니다. Default string column length, Binary column length, Decimal column scale 데이터 형식 길이 및 정밀도는 데이터가 반환되는 방식에 영향을 줄 수 있습니다. 정밀도 손실 및 잘림으로 인해 잘못된 정보가 반환될 수 있습니다. 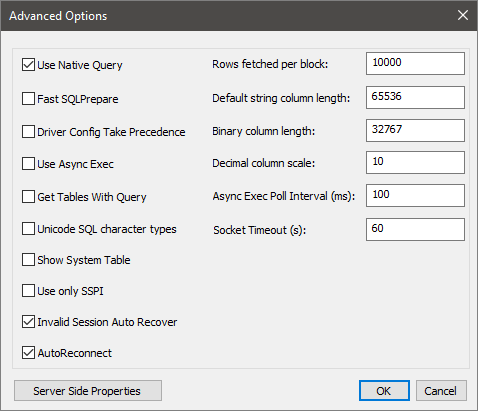
테스트를 선택하여 데이터 원본을 테스트합니다. 데이터 원본이 올바르게 구성된 경우 테스트 결과가 성공으로 표시됩니다.
확인을 선택하여 테스트 창을 닫습니다.
확인을 선택하여 Microsoft Hive ODBC Driver DSN 설정 창을 닫습니다.
확인을 선택하여 ODBC 데이터 원본 관리자 창을 닫습니다.
PowerShell로 데이터 쿼리
다음 PowerShell 스크립트는 ODBC가 Hive 클러스터를 쿼리하는 함수입니다.
function Get-ODBC-Data {
param(
[string]$query=$(throw 'query is required.'),
[string]$dsn,
[PSCredential] $cred = (Get-Credential)
)
$conn = New-Object System.Data.Odbc.OdbcConnection
$uname = $cred.UserName
$pswd = (New-Object System.Net.NetworkCredential -ArgumentList "", $cred.Password).Password
$conn.ConnectionString = "DSN=$dsn;Uid=$uname;Pwd=$pswd;"
$conn.open()
$cmd = New-object System.Data.Odbc.OdbcCommand($query,$conn)
$ds = New-Object system.Data.DataSet
(New-Object system.Data.odbc.odbcDataAdapter($cmd)).fill($ds) #| out-null
$conn.close()
$ds.Tables
}
다음 코드 조각은 위의 함수를 사용하여 자습서의 시작 부분에서 만든 대화형 쿼리 클러스터에서 쿼리를 실행합니다. DATASOURCENAME을 Microsoft Hive ODBC 드라이버 DSN 설정 화면에서 지정한 데이터 원본 이름으로 바꿉니다. 자격 증명을 입력하라는 메시지가 표시되면 클러스터를 만들 때 클러스터 로그인 사용자 이름과 클러스터 로그인 암호에 입력한 사용자 이름과 암호를 입력합니다.
$dsn = "DATASOURCENAME"
$query = "select count(distinct clientid) AS total_clients from hivesampletable"
Get-ODBC-Data -query $query -dsn $dsn
리소스 정리
더 이상 필요하지 않으면 리소스 그룹, HDInsight 클러스터 및 스토리지 계정을 삭제합니다. 이렇게 하려면 클러스터를 만든 리소스 그룹을 선택하고 삭제를 클릭합니다.
다음 단계
이 자습서에서는 Microsoft Hive ODBC 드라이버와 PowerShell을 사용하여 Azure HDInsight 대화형 쿼리 클러스터에서 데이터를 검색하는 방법을 알아보았습니다.